Comment published in Nature Astronomy about The ecological impact of computing with Python

Hi, I recently took a bit of time to study the comment "The ecological impact of high-performance computing in astrophysics" published in Nature Astronomy (Zwart, 2020, https://www.nature.com/articles/s41550-020-1208-y, https://arxiv.org/pdf/2009.11295.pdf), where it is stated that "Best however, for the environment is to abandon Python for a more environmentally friendly (compiled) programming language.". I wrote a simple Python-Numpy implementation of the problem used for this study (https://www.nbabel.org) and, accelerated by Transonic-Pythran, it's very efficient. Here are some numbers (elapsed times in s, smaller is better): | # particles | Py | C++ | Fortran | Julia | |-------------|-----|-----|---------|-------| | 1024 | 29 | 55 | 41 | 45 | | 2048 | 123 | 231 | 166 | 173 | The code and a modified figure are here: https://github.com/paugier/nbabel (There is no check on the results for https://www.nbabel.org, so one still has to be very careful.) I think that the Numpy community should spend a bit of energy to show what can be done with the existing tools to get very high performance (and low CO2 production) with Python. This work could be the basis of a serious reply to the comment by Zwart (2020). Unfortunately the Python solution in https://www.nbabel.org is very bad in terms of performance (and therefore CO2 production). It is also true for most of the Python solutions for the Computer Language Benchmarks Game in https://benchmarksgame-team.pages.debian.net/benchmarksgame/ (codes here https://salsa.debian.org/benchmarksgame-team/benchmarksgame#what-else). We could try to fix this so that people see that in many cases, it is not necessary to "abandon Python for a more environmentally friendly (compiled) programming language". One of the longest and hardest task would be to implement the different cases of the Computer Language Benchmarks Game in standard and modern Python-Numpy. Then, optimizing and accelerating such code should be doable and we should be able to get very good performance at least for some cases. Good news for this project, (i) the first point can be done by anyone with good knowledge in Python-Numpy (many potential workers), (ii) for some cases, there are already good Python implementations and (iii) the work can easily be parallelized. It is not a criticism, but the (beautiful and very nice) new Numpy website https://numpy.org/ is not very convincing in terms of performance. It's written "Performant The core of NumPy is well-optimized C code. Enjoy the flexibility of Python with the speed of compiled code." It's true that the core of Numpy is well-optimized C code but to seriously compete with C++, Fortran or Julia in terms of numerical performance, one needs to use other tools to move the compiled-interpreted boundary outside the hot loops. So it could be reasonable to mention such tools (in particular Numba, Pythran, Cython and Transonic). Is there already something planned to answer to Zwart (2020)? Any opinions or suggestions on this potential project? Pierre PS: Of course, alternative Python interpreters (PyPy, GraalPython, Pyjion, Pyston, etc.) could also be used, especially if HPy (https://github.com/hpyproject/hpy) is successful (C core of Numpy written in HPy, Cython able to produce HPy code, etc.). However, I tend to be a bit skeptical in the ability of such technologies to reach very high performance for low-level Numpy code (performance that can be reached by replacing whole Python functions with optimized compiled code). Of course, I hope I'm wrong! IMHO, it does not remove the need for a successful HPy! -- Pierre Augier - CR CNRS http://www.legi.grenoble-inp.fr LEGI (UMR 5519) Laboratoire des Ecoulements Geophysiques et Industriels BP53, 38041 Grenoble Cedex, France tel:+33.4.56.52.86.16

I think we, the community, does have to take it seriously. NumPy and the rest of the ecosystem is trying to raise money to hire developers. This sentiment, which is much wider than a single paper, is a prevalent roadblock. -- Andy On Tue, Nov 24, 2020 at 11:12 AM Ilhan Polat <ilhanpolat@gmail.com> wrote:
I changed the email subject because I'd like to focus less on CO2 (a very interesting subject, but not my focus here) and more on computing... ----- Mail original -----
I agree. I don't know if it is a matter of scientific field, but I tend to hear more and more people explaining that they don't use Python because of performance. Or telling that they don't have performance problems because they don't use Python. Some communities (I won't give names 🙂) communicate a lot on the bad performances of Python-Numpy. I am well aware that performance is in many cases not so important but it is not a good thing to have such bad reputation. I think we have to show what is doable with Python-Numpy code to get very good performance. ----- Mail original -----
I'm not a fan of this focus neither. But we have to realize that many people think like that and are sensible to such arguments. Being so bad in all benchmark games does not help the scientific Python community (especially in the long terms).
I'm really not sure. Or at least that depends on the type of performance critical code. I see many students or scientists who sometimes need to write few functions that are not super inefficient. For many people, I don't see why they would need to learn and use another language. I did my PhD (in turbulence) with Fortran (and Matlab) and I have really nothing against Fortran. However, I'm really happy that we code in my group nearly everything in Python (+ a bit of C++ for the fun). For example, Fluidsim (https://foss.heptapod.net/fluiddyn/fluidsim) is ~100% Python and I know that it is very efficient (more efficient than many alternatives written with a lot of C++/Fortran). I realize that it wouldn't be possible for all kinds of code (and fluidsim uses fluidfft, written in C++ / Cython / Python), but being 100% Python has a lot of advantages (I won't list them here). For a N-Body simulation, why not using Python? Using Python, you get a very readable, clear and efficient implementation (see https://github.com/paugier/nbabel), even faster than what you can get with easy C++/Fortran/Julia. IMHO, it is just what one needs for most PhD in astronomy. Of course, for many things, one needs native languages! Have a look at Pythran C++ code, it's beautiful 🙂 ! But I don't think every scientist that writes critical code has to become an expert in C++ or Fortran (or Julia). I also sometimes have to read and use C++ and Fortran codes written by scientists. Sometimes (often), I tend to think that they would be more productive with other tools to reach the same performance. I think it is only a matter of education and not of tooling, but using serious tools does not make you a serious developer, and reaching the level in C++/Fortran to write efficient, clean, readable and maintainable codes in not so easy for a PhD or scientist that has other things to do. Python-Numpy is so slow for some algorithms that many Python-Numpy users would benefit to know how to accelerate it. Just an example, with some elapsed times (in s) for the N-Body problem (see https://github.com/paugier/nbabel#smaller-benchmarks-between-different-pytho...): | Transonic-Pythran | Transonic-Numba | High-level Numpy | PyPy OOP | PyPy lists | |-------------------|-----------------|------------------|----------|------------| | 0.48 | 3.91 | 686 | 87 | 15 | For comparison, we have for this case `{"c++": 0.85, "Fortran": 0.62, "Julia": 2.57}`. Note that just adding `from transonic import jit` to the simple high-level Numpy code and then decorating the function `compute_accelerations` with `@jit`, the elapsed time decreases to 8 s (a x85 speedup!, with Pythran 0.9.8). I conclude from these types of results that we need to tell Python users how to accelerate their Python-Numpy codes when they feel the need of it. I think acceleration tools should be mentioned in Numpy website. I also think we should spend a bit of energy to play some benchmark games. It would be much better if we can change the widespread idea on Python performance for numerical problems from "Python is very slow and ineffective for most algorithms" to "interpreted Python can be very slow but with the existing Python accelerators, one can be extremely efficient with Python". Pierre

On Thu, Nov 26, 2020 at 9:15 PM PIERRE AUGIER < pierre.augier@univ-grenoble-alpes.fr> wrote:
Good point, added an issue for it on the website repo: https://github.com/numpy/numpy.org/issues/370 Cheers, Ralf

On Thu, 26 Nov 2020 22:14:40 +0100 (CET) PIERRE AUGIER <pierre.augier@univ-grenoble-alpes.fr> wrote:
I changed the email subject because I'd like to focus less on CO2 (a very interesting subject, but not my focus here) and more on computing...
Hi Pierre, We may turn the problem in another way around: one should more focus on the algorithm than on the programming language. I would like to share with you one example, where we published how to speed-up crystallographic computation written in Python. https://onlinelibrary.wiley.com/iucr/doi/10.1107/S1600576719008471 One referee asked us to validate vs C and Fortran equivalent code. C code was as fast as Pythran or Cython and Fortran was still faster (the std of the Fortran-compiled runtime was much smaller which allows Fortran to be faster by 3 std !) But I consider the difference to be marginal at this level ! If one considers the "Moore law", i.e. the time needed for "performance" to double in different aspects of computing, one gets 18 to 24 month for the number of transistor in a processor, 18 years for the compilers and 2 years (in average) for the development of new algorithms. In this sense one should more focus on the algorithm used. The Table 1 of the article is especially interesting: Pure Python is 10x slower than proper Numpy code, and parallel Pythran is 50x faster than Numpy (on the given computer) but using the proper algorithm, i.e. FFT in this case, is 13000x faster ! So I believe that Python, with its expressivity, helps much in understanding the algorithm and hence to design faster code. Cheers, Jerome

On Tue, 2020-11-24 at 16:47 +0100, PIERRE AUGIER wrote:
I don't think there is any need for rebuttal. The author is right right, you should not write the core of an N-Body simulation in Python :). I completely disagree with the focus on programming languages/tooling, quite honestly. A PhD who writes performance critical code, must get the education necessary to do it well. That may mean learning something beyond Python, but not replacing Python entirely. In one point the opinion notes: NumPy, for example, is mostly used for its advanced array handling and support functions. Using these will reduce runtime and, therefore, also carbon emission, but optimization is generally stopped as soon as the calculation runs within an unconsciously determined reasonable amount of time, such as the coffee-refill timescale or a holiday weekend. IMO, this applies to any other programming language just as much. If your correlation is fast enough, you will not invest time in implementing an fft based algorithm. If you iterate your array in Fortran instead of C-order in your C++ program (which new users may just do randomly), you are likely to waste more(!) cpu cycles then if you were using NumPy :). Personally, I am always curious how much of that "GPUs are faster" factor is actually due to the effort spend on making it faster... My angle is that in the end, it is far more about technical knowledge than about using the "right" language. An example: At an old workplace we had had some simulations running five times slower, because years earlier someone forgot to set `RELEASE=True` in the default config, always compiling in debug mode! But honestly, if it was 5 times faster, we probably would probably have done at least 3 times as many simulations :). Aside from that, most complex C/C++ programs can probably be sped up significantly just as well. In the end, my main reading is that code running on power-hungry machines (clusters, workstations) should maybe be audited for performance. Yes! (Although even then, reduces tend to get used, no matter how much you have!) As for actually doing something to reduce the carbon footprint, I think the vast majority of our users would have more impact if they throttle their CPUs a bit rather than worry about what tool they use to do their job :). Cheers, Sebastian
Hi Pierre, I agree with your point of view: the author wants to demonstrate C++ and Fortran are better than Python... and environmentally speaking he has some evidences. We develop with Python, Cython, Numpy, and OpenCL and what annoys me most is the compilation time needed for the development of those statically typed ahead of time extensions (C++, C, Fortran). Clearly the author wants to get his article viral and in a sense he managed :). But he did not mention Julia / Numba and other JIT compiled languages (including matlab ?) that are probably outperforming the C++ / Fortran when considering the development time and test-time. Beside this the OpenMP parallelism (implicitly advertized) is far from scaling well on multi-socket systems and other programming paradigms are needed to extract the best performances from spercomputers. Cheers, Jerome
On Tue, 2020-11-24 at 18:41 +0100, Jerome Kieffer wrote:
As an interesting aside: Algorithms may have actually improved *more* than computational speed when it comes to performance [1]. That shows the impressive scale and complexity of efficient code. So, I could possibly argue that the most important thing may well be accessibility of algorithms. And I think that is what a large chunk of Scientific Python packages are all about. Whether or not that has an impact on the environment... Cheers, Sebastian [1] This was the first resource I found, I am sure there are plenty: https://www.lanl.gov/conferences/salishan/salishan2004/womble.pdf

Given that AWS and Azure have both made commitments to have their data centers be carbon neutral, and given that electricity and heat production make up ~25% of GHG pollution, I find these sorts of power-usage-analysis-for-the-sake-of-the-environment to be a bit disingenuous. Especially since GHG pollution from power generation is forecasted to shrink as more power is generated by alternative means. I am fine with improving python performance, but let's not fool ourselves into thinking that it is going to have any meaningful impact on the environment. Ben Root https://sustainability.aboutamazon.com/environment/the-cloud?energyType=true https://azure.microsoft.com/en-au/global-infrastructure/sustainability/#ener... https://www.epa.gov/ghgemissions/global-greenhouse-gas-emissions-data On Tue, Nov 24, 2020 at 1:25 PM Sebastian Berg <sebastian@sipsolutions.net> wrote:

On Tue, Nov 24, 2020 at 11:54 AM Benjamin Root <ben.v.root@gmail.com> wrote:
Bingo. I lived through the Freon ozone panic that lasted for 20 years even after the key reaction rate was remeasured and found to be 75-100 times slower than that used in the research that started the panic. The models never recovered, but the panic persisted until it magically disappeared in 1994. There are still ozone holes over the Antarctic, last time I looked they were explained as due to an influx of cold air. If you want to deal with GHG, push nuclear power. <snip> Chuck
Digressing here, but the ozone hole over the antarctic was always going to take time to recover because of the approximately 50 year residence time of the CFCs in the upper atmosphere. Cold temperatures can actually speed up depletion because of certain ice crystal formations that give a boost in the CFC+sunlight+O3 reaction rate. Note that it doesn't mean that 50 years are needed to get rid of all CFCs in the atmosphere, it is just a measure of the amount of time it is expected to take for half of the gas that is already there to be removed. That doesn't account for the amount of time it has taken for CFC usage to drop in the first place, and the fact that there are still CFC pollution occurring (albeit far less than in the 80's). Ben Root https://ozone.unep.org/nasa-provides-first-direct-evidence-ozone-hole-recove... https://csl.noaa.gov/assessments/ozone/1998/faq11.html On Tue, Nov 24, 2020 at 2:07 PM Charles R Harris <charlesr.harris@gmail.com> wrote:
On Tue, Nov 24, 2020 at 12:28 PM Benjamin Root <ben.v.root@gmail.com> wrote:
Out of curiosity, has the ice crystal acceleration been established in the lab? I recall it being proposed to help save the models, but that was a long time ago. IIRC, another reaction rate was remeasured in 2005 and found to be 10X lower than thought, but don't recall which one. I've been looking for a good recent review article to see what the current status is. The funding mostly disappeared after 1994 along with several careers. Freon is still used -- off the books -- in several countries, a phenomenon now seen with increasing coal generation. Chuck

On 11/24/2020 2:06 PM, Charles R Harris wrote:
There are still ozone holes over the Antarctic, last time I looked they were explained as due to an influx of cold air.
I believe industrial CFC usage, which has fallen since the Montreal Protocol, is still considered the primary culprit in ozone layer thinning. Is there a particular model you have in mind? (Ideally one with publicly available source code and some data.) On 11/24/2020 2:06 PM, Charles R Harris wrote:
If you want to deal with GHG, push nuclear power.
Yes. However, solar is becoming competitive is some regions for cost per watt, and avoids the worst waste disposal issues. fwiw, Alan Isaac

I'm imagining a study on programmer and maintainer's time spent on a given problem, tackled in different programming languages, maybe Python can be shown to reduce GHG on the contrary. It goes like this: Many human programmers/administrators/managers eat beef or likes as they grow up, as cattle produces great amount of GHG, and optimization experts need more years to graduate ... So Numpy actually used less emission to gain greater yields in works demanding optimization, i.e. the ecosystem scales up to more people not being optimization experts themselves, yet get serious work done.
Is there some community interest to develop fusion based high-performance array programming? Something like https://github.com/AccelerateHS/accelerate#an-embedded-language-for-accelera... <https://github.com/AccelerateHS/accelerate#an-embedded-language-for-accelera...> , but that embedded DSL is far less pleasing compared to Python as the surface language for optimized Numpy code in C. I imagine that we might be able to transpile a Numpy program into fused LLVM IR, then deploy part as host code on CPUs and part as CUDA code on GPUs? I know Numba is already doing the array part, but it is too limited in addressing more complex non-array data structures. I had been approaching ~20K separate data series with some intermediate variables for each, then it took up to 30+GB RAM keep compiling yet gave no result after 10+hours. Compl

Hello, We’re trying to do a part of this in the TACO team, and with a Python wrapper in the form of PyData/Sparse. It will allow an abstract array/scheduling to take place, but there are a bunch of constraints, the most important one being that a C compiler cannot be required at runtime. However, this may take a while to materialize, as we need an LLVM backend, and a Python wrapper (matching the NumPy API), and support for arbitrary functions (like universal functions). https://github.com/tensor-compiler/taco http://fredrikbk.com/publications/kjolstad-thesis.pdf -- Sent from Canary (https://canarymail.io)

Measuring running time of a program in arbitrary programming language is not an objective metric. Otherwise force everyone code in Assembler and we would be done as quick as possible. Hire 5 people to come to the workplace for 6 months to optimize it and we will be done with their transportation. There is a reason for not doing so. Alternatively, any time that will be shaved off from this will be spent on extremely inefficient i9 laptops that developers have while debugging the type issues. As the author themselves admit, the development speed would justify the loss encountered from the actual code running. So this study is suggestive at the very least just; like my rebuttal, very difficult to verify. I do Industrial IoT for a living, and while I wholeheartedly agree with the intentions, I would seriously question the power metrics given here because similarly I can easily show a steel factory to be very efficient if I am not careful. Especially tying the code quality to the programming language is a very slippery slope that I have been listening to in the last 20 years from Fortran people.
I don't get this sentence. On Tue, Nov 24, 2020 at 7:29 PM Hameer Abbasi <einstein.edison@gmail.com> wrote:
Great to know. Skimmed through the project readme, so TACO currently generating C code as intermediate language, if the purpose is about tensors, why not Numba's llvmlite for it? I'm aware that the scheduling code tend not to be array programs, and llvmlite may have tailored too much to optimize more general programs well. How is TACO going in this regard? Compl
Hello, TACO consists of three things: An array API A scheduling language A language for describing sparse modes of the tensor So it combines arrays with scheduling, and also sparse tensors for a lot of different applications. It also includes an auto-scheduler. The code thus generated is on par or faster than, e.g. MKL and other equivalent libraries, with the ability to do fusion for arbitrary expressions. This is, for more complicated expressions involving sparse operands, big-O superior to composing the operations. The limitations are: Right now, it can only compute Einstein-summation type expressions, we’re (along with Rawn, another member of the TACO team) trying to extend that to any kind of point-wise expressions and reductions (such as exp(tensor), sum(tensor), ...). It requires a C compiler at runtime. We’re writing an LLVM backend for it that will hopefully remove that requirement. It can’t do arbitrary non-pointwise functions, e.g. SVD, inverse. This is a long way from being completely solved. As for why not Numba/llvmlite: Re-writing TACO is a large task that would be hard to do, wrapping/extending it is much easier. Best regards, Hameer Abbasi -- Sent from Canary (https://canarymail.io)

This always seems like such a ridiculous argument. If CO2 emissions are directly proportional to the time it takes for a program to run, then there's no real need to concern ourselves with it. People already have a direct reason to avoid programs that take a long time to run, namely, that they take a long time to run. If I have two codes that compute the same thing and one takes a week and the other takes a few minutes, then obviously I will choose the one that takes a few minutes, and my decision will have nothing to do with ecological impact. The real issue with CO2 emissions are instances where the agency is completely removed and the people damaging the environment don't suffer any ill effects from it. It would be more intellectually honest to try to determine why it is that people choose Python, an apparently very slow language, to do high performance computing. If one spends even a moment thinking about this, and actually looking at what the real scientific Python community does, one would realize that simply having a fast core in Python is enough for the majority of performance. NumPy array expressions are fast because the core loops are fast, and those dominate the runtime for the majority of uses. And for instances where it isn't fast enough, e.g., when writing a looping algorithm directly, there are multiple tools that allow writing fast Python or Python-like code, such as Numba, Cython, Pythran, PyPy, and so on. Aaron Meurer On Tue, Nov 24, 2020 at 8:57 AM PIERRE AUGIER <pierre.augier@univ-grenoble-alpes.fr> wrote:
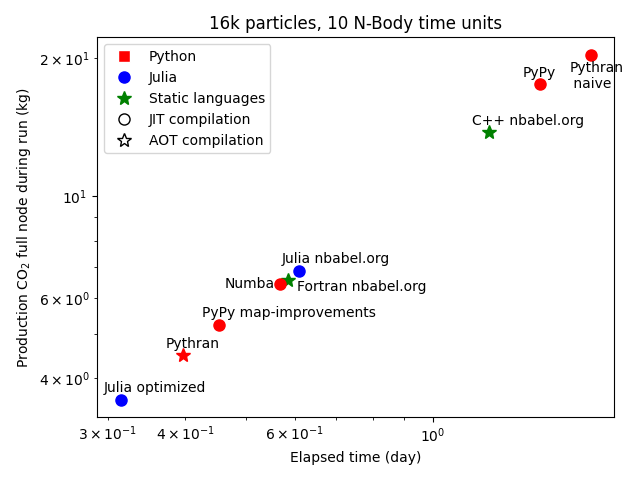
Hi, Here are some preliminary results of an experiment on energy consumption measurement at Grid'5000 (https://www.grid5000.fr/w/Energy_consumption_monitoring_tutorial). The goal is to have enough to be able to submit a serious comment to a recent article published in Nature Astronomy (Zwart, 2020) which recommends to stop using and teaching Python because of the ecological impact of computing. On the attached figure: it represents the CO2 production as a function of elapsed time for different implementations (https://github.com/paugier/nbabel). It can be compared with https://raw.githubusercontent.com/paugier/nbabel/master/py/fig/fig_ecolo_imp... taken from Zwart (2020). The implementations labeled "nbabel.org" have been found on https://www.nbabel.org/ and have recently been used in the article by Zwart (2020). Note that these C++, Fortran and Julia implementations are not well optimized. However, I think they are representative of many C++, Fortran and Julia codes written by scientists. There is one simple Pythran implementation which is really fast (slightly slower than the fastest implementation in Julia but it is not a big deal). Note that of course these results do not show that Python is faster that C++!! We just show here that it's easy to write in Python **very** efficient implementations of numerically intensive problems. I think soon I'm going to have enough materials to contact the editors to ask how we can publicly answer to this comment published in their journal. With this work https://github.com/paugier/nbabel (proper energy consumption measurements), I clearly demonstrate that the basis of Zwart's comment is factually wrong (its benchmark and Figure 3), so that most of its conclusions are also wrong. I'd like to know if some people involved in the community are willing to be co-authors of this potential reply. Cheers, Pierre -- Pierre Augier - CR CNRS http://www.legi.grenoble-inp.fr LEGI (UMR 5519) Laboratoire des Ecoulements Geophysiques et Industriels BP53, 38041 Grenoble Cedex, France tel:+33.4.56.52.86.16 ----- Mail original -----
{kind=link}
participants (12)
-
 Aaron Meurer
Aaron Meurer -
 Alan G. Isaac
Alan G. Isaac -
 Andy Ray Terrel
Andy Ray Terrel -
 Benjamin Root
Benjamin Root -
 Charles R Harris
Charles R Harris -
 Hameer Abbasi
Hameer Abbasi -
 Ilhan Polat
Ilhan Polat -
 Jerome Kieffer
Jerome Kieffer -
 PIERRE AUGIER
PIERRE AUGIER -
 Ralf Gommers
Ralf Gommers -
 Sebastian Berg
Sebastian Berg -
 YueCompl
YueCompl