Exporting numpy arrays to binary JSON (BJData) for better portability

To avoid derailing the other thread <https://mail.python.org/archives/list/numpy-discussion@python.org/thread/A4C...> on extending .npy files, I am going to start a new thread on alternative array storage file formats using binary JSON - in case there is such a need and interest among numpy users specifically, i want to first follow up with Bill's question below regarding loading time On 8/25/22 11:02, Bill Ross wrote:
|Can you give load times for these?|
as I mentioned in the earlier reply to Robert, the most memory-efficient (i.e. fast loading, disk-mmap-able) but not necessarily disk-efficient (i.e. may result in the largest data file sizes) BJData construct to store an ND array using BJData's ND-array container. I have to admit that both jdata and bjdata modules have not been extensively optimized for speed. with the current implementation, here are the loading time for a larger diagonal matrix (eye(10000)) a BJData file storing a single eye(10000) array using the ND-array container can be downloaded from here <http://neurojson.org/wiki/upload/eye1e4_bjd_raw_ndsyntax.jdb.zip>(file size: 1MB with zip, if decompressed, it is ~800MB, as the npy file) - this file was generated from a matlab encoder, but can be loaded using Python (see below Re Robert). |800000128 eye1e4.npy|| ||800000014 eye1e4_bjd_raw_ndsyntax.jdb|| || 813721 eye1e4_bjd_zlib.jdb|| || 113067 eye1e4_bjd_lzma.jdb| the loading time (from an nvme drive, Ubuntu 18.04, python 3.6.9, numpy 1.19.5) for each file is listed below: |0.179s eye1e4.npy (mmap_mode=None)|| ||0.001s eye1e4.npy (mmap_mode=r)|| ||0.718s eye1e4_bjd_raw_ndsyntax.jdb|| ||1.474s eye1e4_bjd_zlib.jdb|| ||0.635s eye1e4_bjd_lzma.jdb| clearly, mmapped loading is the fastest option without a surprise; it is true that the raw bjdata file is about 5x slower than npy loading, but given the main chunk of the data are stored identically (as contiguous buffer), I suppose with some optimization of the decoder, the gap between the two can be substantially shortened. The longer loading time of zlib/lzma (and similarly saving times) reflects a trade-off between smaller file sizes and time for compression/decompression/disk-IO. by no means I am saying the binary JSON format is readily available to deliver better speed with its current non-optimized implementation. I just want to bright the attention to this class of formats, and highlight that it's flexibility gives abundant mechanisms to create fast, disk-mapped IO, while allowing additional benefits such as compression, unlimited metadata for future extensions etc.
|> 8000128 eye5chunk.npy|| ||> 5004297 eye5chunk_bjd_raw.jdb|| ||> 10338 eye5chunk_bjd_zlib.jdb|| ||> 2206 eye5chunk_bjd_lzma.jdb|
For my case, I'd be curious about the time to add one 1T-entries file to another.
as I mentioned in the previous reply, bjdata is appendable <https://github.com/NeuroJSON/bjdata/blob/master/images/BJData_Diagram.pdf>, so you can simply append another array (or a slice) to the end of the file.
Thanks, Bill
also related, Re @Robert's question below
Are any of them supported by a Python BJData implementation? I didn't see any option to get that done in the `bjdata` package you recommended, for example. https://github.com/NeuroJSON/pybj/blob/a46355a0b0df0bec1817b04368a5a57335864...
the bjdata module currently only support nd-array in the decoder <https://github.com/NeuroJSON/pybj/blob/a46355a0b0df0bec1817b04368a5a57335864...> (i.e. map such buffer to a numpy.ndarray) - should be relatively trivial to add it to the encoder though. on the other side, the annotated format is currently supported. one can call jdata module (responsible for annotation-level encoding/decoding) as shown in my sample code, then call bjdata internally for data serialization.
Okay. Given your wording, it looked like you were claiming that the binary JSON was supported by the whole ecosystem. Rather, it seems like you can either get binary encoding OR the ecosystem support, but not both at the same time.
all in relative terms of course - json has ~100 listed parsers on it's website <https://www.json.org/json-en.html>, MessagePack - another flavor of binary JSON - listed <https://msgpack.org/index.html> ~50/60 parsers, and UBJSON listed <https://ubjson.org/libraries/> ~20 parsers. I am not familiar with npy parsers, but googling it returns only a few. also, most binary JSON implementations provided tools to convert to JSON and back, so, in that sense, whatever JSON has in its ecosystem can be "potentially" used for binary JSON files if one wants to. There are also recent publications comparing differences between various binary JSON formats in case anyone is interested https://github.com/ubjson/universal-binary-json/issues/115

For my case, I'd be curious about the time to add one 1T-entries file to another.
as I mentioned in the previous reply, bjdata is appendable [3], so you can simply append another array (or a slice) to the end of the file.
I'm thinking of numerical ops here, e.g. adding an array to itself would double the values but not the size. --- -- Phobrain.com On 2022-08-25 14:41, Qianqian Fang wrote:
To avoid derailing the other thread [1] on extending .npy files, I am going to start a new thread on alternative array storage file formats using binary JSON - in case there is such a need and interest among numpy users
specifically, i want to first follow up with Bill's question below regarding loading time
On 8/25/22 11:02, Bill Ross wrote:
Can you give load times for these?
as I mentioned in the earlier reply to Robert, the most memory-efficient (i.e. fast loading, disk-mmap-able) but not necessarily disk-efficient (i.e. may result in the largest data file sizes) BJData construct to store an ND array using BJData's ND-array container.
I have to admit that both jdata and bjdata modules have not been extensively optimized for speed. with the current implementation, here are the loading time for a larger diagonal matrix (eye(10000))
a BJData file storing a single eye(10000) array using the ND-array container can be downloaded from here [2](file size: 1MB with zip, if decompressed, it is ~800MB, as the npy file) - this file was generated from a matlab encoder, but can be loaded using Python (see below Re Robert).
800000128 eye1e4.npy 800000014 eye1e4_bjd_raw_ndsyntax.jdb 813721 eye1e4_bjd_zlib.jdb 113067 eye1e4_bjd_lzma.jdb
the loading time (from an nvme drive, Ubuntu 18.04, python 3.6.9, numpy 1.19.5) for each file is listed below:
0.179s eye1e4.npy (mmap_mode=None) 0.001s eye1e4.npy (mmap_mode=r) 0.718s eye1e4_bjd_raw_ndsyntax.jdb 1.474s eye1e4_bjd_zlib.jdb 0.635s eye1e4_bjd_lzma.jdb
clearly, mmapped loading is the fastest option without a surprise; it is true that the raw bjdata file is about 5x slower than npy loading, but given the main chunk of the data are stored identically (as contiguous buffer), I suppose with some optimization of the decoder, the gap between the two can be substantially shortened. The longer loading time of zlib/lzma (and similarly saving times) reflects a trade-off between smaller file sizes and time for compression/decompression/disk-IO.
by no means I am saying the binary JSON format is readily available to deliver better speed with its current non-optimized implementation. I just want to bright the attention to this class of formats, and highlight that it's flexibility gives abundant mechanisms to create fast, disk-mapped IO, while allowing additional benefits such as compression, unlimited metadata for future extensions etc.
8000128 eye5chunk.npy 5004297 eye5chunk_bjd_raw.jdb 10338 eye5chunk_bjd_zlib.jdb 2206 eye5chunk_bjd_lzma.jdb
For my case, I'd be curious about the time to add one 1T-entries file to another.
as I mentioned in the previous reply, bjdata is appendable [3], so you can simply append another array (or a slice) to the end of the file.
Thanks, Bill
also related, Re @Robert's question below
Are any of them supported by a Python BJData implementation? I didn't see any option to get that done in the `bjdata` package you recommended, for example. https://github.com/NeuroJSON/pybj/blob/a46355a0b0df0bec1817b04368a5a57335864...
the bjdata module currently only support nd-array in the decoder [4] (i.e. map such buffer to a numpy.ndarray) - should be relatively trivial to add it to the encoder though.
on the other side, the annotated format is currently supported. one can call jdata module (responsible for annotation-level encoding/decoding) as shown in my sample code, then call bjdata internally for data serialization.
Okay. Given your wording, it looked like you were claiming that the binary JSON was supported by the whole ecosystem. Rather, it seems like you can either get binary encoding OR the ecosystem support, but not both at the same time.
all in relative terms of course - json has ~100 listed parsers on it's website [5], MessagePack - another flavor of binary JSON - listed [6] ~50/60 parsers, and UBJSON listed [7] ~20 parsers. I am not familiar with npy parsers, but googling it returns only a few.
also, most binary JSON implementations provided tools to convert to JSON and back, so, in that sense, whatever JSON has in its ecosystem can be "potentially" used for binary JSON files if one wants to. There are also recent publications comparing differences between various binary JSON formats in case anyone is interested
https://github.com/ubjson/universal-binary-json/issues/115
_______________________________________________ NumPy-Discussion mailing list -- numpy-discussion@python.org To unsubscribe send an email to numpy-discussion-leave@python.org https://mail.python.org/mailman3/lists/numpy-discussion.python.org/ Member address: bross_phobrain@sonic.net
Links: ------ [1] https://mail.python.org/archives/list/numpy-discussion@python.org/thread/A4C... [2] http://neurojson.org/wiki/upload/eye1e4_bjd_raw_ndsyntax.jdb.zip [3] https://github.com/NeuroJSON/bjdata/blob/master/images/BJData_Diagram.pdf [4] https://github.com/NeuroJSON/pybj/blob/a46355a0b0df0bec1817b04368a5a57335864... [5] https://www.json.org/json-en.html [6] https://msgpack.org/index.html [7] https://ubjson.org/libraries/

the loading time (from an nvme drive, Ubuntu 18.04, python 3.6.9, numpy 1.19.5) for each file is listed below:
0.179s eye1e4.npy (mmap_mode=None) 0.001s eye1e4.npy (mmap_mode=r) 0.718s eye1e4_bjd_raw_ndsyntax.jdb 1.474s eye1e4_bjd_zlib.jdb 0.635s eye1e4_bjd_lzma.jdb
clearly, mmapped loading is the fastest option without a surprise; it is true that the raw bjdata file is about 5x slower than npy loading, but given the main chunk of the data are stored identically (as contiguous buffer), I suppose with some optimization of the decoder, the gap between the two can be substantially shortened. The longer loading time of zlib/lzma (and similarly saving times) reflects a trade-off between smaller file sizes and time for compression/decompression/disk-IO.
I think the load time for mmap may be deceptive, it isn't actually loading anything, just mapping to memory. Maybe a better benchmark is to actually process the data, e.g., find the mean which would require reading the values.
On 8/25/22 18:33, Neal Becker wrote:
the loading time (from an nvme drive, Ubuntu 18.04, python 3.6.9, numpy 1.19.5) for each file is listed below:
|0.179s eye1e4.npy (mmap_mode=None)|| ||0.001s eye1e4.npy (mmap_mode=r)|| ||0.718s eye1e4_bjd_raw_ndsyntax.jdb|| ||1.474s eye1e4_bjd_zlib.jdb|| ||0.635s eye1e4_bjd_lzma.jdb|
clearly, mmapped loading is the fastest option without a surprise; it is true that the raw bjdata file is about 5x slower than npy loading, but given the main chunk of the data are stored identically (as contiguous buffer), I suppose with some optimization of the decoder, the gap between the two can be substantially shortened. The longer loading time of zlib/lzma (and similarly saving times) reflects a trade-off between smaller file sizes and time for compression/decompression/disk-IO.
I think the load time for mmap may be deceptive, it isn't actually loading anything, just mapping to memory. Maybe a better benchmark is to actually process the data, e.g., find the mean which would require reading the values.
yes, that is correct, I meant to metion it wasn't an apple-to-apple comparison. the loading times for fully-loading the data and printing the mean, by running the below line |t=time.time(); newy=jd.load('eye1e4_bjd_raw_ndsyntax.jdb'); print(np.mean(newy)); t1=time.time() - t; print(t1)| are summarized below (I also added lz4 compressed BJData/.jdb file via |jd.save(..., {'compression':'lz4'})|) |0.236s eye1e4.npy (mmap_mode=None)||- size: 800000128 bytes ||0.120s eye1e4.npy (mmap_mode=r)|| ||0.764s eye1e4_bjd_raw_ndsyntax.jdb||(with C extension _bjdata in sys.path) - size: 800000014 bytes| ||0.599s eye1e4_bjd_raw_ndsyntax.jdb||(without C extension _bjdata)| ||1.533s eye1e4_bjd_zlib.jdb|||(without C extension _bjdata)||| - size: 813721 ||0.697s eye1e4_bjd_lzma.jdb|||(without C extension _bjdata) - size: 113067 |||||0.918s eye1e4_bjd_lz4.jdb|||(without C extension _bjdata) - size: 3371487 bytes|| |||| the mmapped loading remains to be the fastest, but the run-time is more realistic. I thought the lz4 compression would offer much faster decompression, but in this special workload, it isn't the case. It is also interesting to see that the bjdata's C extension <https://github.com/NeuroJSON/pybj/tree/master/src> did not help when parsing a single large array compared to the native python parser, suggesting rooms for further optimization|.||| || || || ||Qianqian|| || ||

Hi Qianqian, Your work in bjdata's is very interesting. Our team (Blosc) has been working on something along these lines, and I was curious on how the different approaches compares. In particular, Blosc2 uses the msgpack format to store binary data in a flexible way, but in my experience, using binary JSON or msgpack is not that important; the real thing is to be able to compress data in chunks that fits in CPU caches, and then trust in fast codecs and filters for speed. I have setup a small benchmark ( https://gist.github.com/FrancescAlted/e4d186404f4c87d9620cb6f89a03ba0d) based on your setup and here are my numbers (using an AMD 5950X processor, and a fast SSD here): (python-blosc2) faltet2@ryzen16:~/blosc/python-blosc2/bench$ PYTHONPATH=.. python read-binary-data.py save time for creating big array (and splits): 0.009s (86.5 GB/s) ** Saving data ** time for saving with npy: 0.450s (1.65 GB/s) time for saving with np.memmap: 0.689s (1.08 GB/s) time for saving with npz: 1.021s (0.73 GB/s) time for saving with jdb (zlib): 4.614s (0.161 GB/s) time for saving with jdb (lzma): 11.294s (0.066 GB/s) time for saving with blosc2 (blosclz): 0.020s (37.8 GB/s) time for saving with blosc2 (zstd): 0.153s (4.87 GB/s) ** Load and operate ** time for reducing with plain numpy (memory): 0.016s (47.4 GB/s) time for reducing with npy (np.load, no mmap): 0.144s (5.18 GB/s) time for reducing with np.memmap: 0.055s (13.6 GB/s) time for reducing with npz: 1.808s (0.412 GB/s) time for reducing with jdb (zlib): 1.624s (0.459 GB/s) time for reducing with jdb (lzma): 0.255s (2.92 GB/s) time for reducing with blosc2 (blosclz): 0.042s (17.7 GB/s) time for reducing with blosc2 (zstd): 0.070s (10.7 GB/s) Total sum: 10000.0 So, it is evident that in this scenario compression can accelerate things a lot, specially for compression. Here are the sizes: (python-blosc2) faltet2@ryzen16:~/blosc/python-blosc2/bench$ ll -h eye5* -rw-rw-r-- 1 faltet2 faltet2 989K ago 27 09:51 eye5_blosc2_blosclz.b2frame -rw-rw-r-- 1 faltet2 faltet2 188K ago 27 09:51 eye5_blosc2_zstd.b2frame -rw-rw-r-- 1 faltet2 faltet2 121K ago 27 09:51 eye5chunk_bjd_lzma.jdb -rw-rw-r-- 1 faltet2 faltet2 795K ago 27 09:51 eye5chunk_bjd_zlib.jdb -rw-rw-r-- 1 faltet2 faltet2 763M ago 27 09:51 eye5chunk-memmap.npy -rw-rw-r-- 1 faltet2 faltet2 763M ago 27 09:51 eye5chunk.npy -rw-rw-r-- 1 faltet2 faltet2 785K ago 27 09:51 eye5chunk.npz Regarding decompression, I am quite pleased on how jdb+lzma performs (specially with the compression ratio). But in order to provide a better idea on the actual read performance, it is better to evict the files from the OS cache. Also, the benchmark performs some operation on data (in this case a reduction) to make sure that all the data is processed. So, let's evict the files: (python-blosc2) faltet2@ryzen16:~/blosc/python-blosc2/bench$ vmtouch -ev eye5* Evicting eye5_blosc2_blosclz.b2frame Evicting eye5_blosc2_zstd.b2frame Evicting eye5chunk_bjd_lzma.jdb Evicting eye5chunk_bjd_zlib.jdb Evicting eye5chunk-memmap.npy Evicting eye5chunk.npy Evicting eye5chunk.npz Files: 7 Directories: 0 Evicted Pages: 391348 (1G) Elapsed: 0.084441 seconds And then re-run the benchmark (without re-creating the files indeed): (python-blosc2) faltet2@ryzen16:~/blosc/python-blosc2/bench$ PYTHONPATH=.. python read-binary-data.py time for creating big array (and splits): 0.009s (80.4 GB/s) ** Load and operate ** time for reducing with plain numpy (memory): 0.065s (11.5 GB/s) time for reducing with npy (np.load, no mmap): 0.413s (1.81 GB/s) time for reducing with np.memmap: 0.547s (1.36 GB/s) time for reducing with npz: 1.881s (0.396 GB/s) time for reducing with jdb (zlib): 1.845s (0.404 GB/s) time for reducing with jdb (lzma): 0.204s (3.66 GB/s) time for reducing with blosc2 (blosclz): 0.043s (17.2 GB/s) time for reducing with blosc2 (zstd): 0.072s (10.4 GB/s) Total sum: 10000.0 In this case we can notice that the combination of blosc2+blosclz achieves speeds that are faster than using a plain numpy array. Having disk I/O going faster than memory is strange enough, but if we take into account that these arrays compress extremely well (more than 1000x in this case), then the I/O overhead is really low compared with the cost of computation (all the decompression takes place in CPU cache, not memory), so in the end, this is not that surprising. Cheers! On Fri, Aug 26, 2022 at 4:26 AM Qianqian Fang <fangqq@gmail.com> wrote:
On 8/25/22 18:33, Neal Becker wrote:
the loading time (from an nvme drive, Ubuntu 18.04, python 3.6.9, numpy 1.19.5) for each file is listed below:
0.179s eye1e4.npy (mmap_mode=None) 0.001s eye1e4.npy (mmap_mode=r) 0.718s eye1e4_bjd_raw_ndsyntax.jdb 1.474s eye1e4_bjd_zlib.jdb 0.635s eye1e4_bjd_lzma.jdb
clearly, mmapped loading is the fastest option without a surprise; it is true that the raw bjdata file is about 5x slower than npy loading, but given the main chunk of the data are stored identically (as contiguous buffer), I suppose with some optimization of the decoder, the gap between the two can be substantially shortened. The longer loading time of zlib/lzma (and similarly saving times) reflects a trade-off between smaller file sizes and time for compression/decompression/disk-IO.
I think the load time for mmap may be deceptive, it isn't actually loading anything, just mapping to memory. Maybe a better benchmark is to actually process the data, e.g., find the mean which would require reading the values.
yes, that is correct, I meant to metion it wasn't an apple-to-apple comparison.
the loading times for fully-loading the data and printing the mean, by running the below line
t=time.time(); newy=jd.load('eye1e4_bjd_raw_ndsyntax.jdb'); print(np.mean(newy)); t1=time.time() - t; print(t1)
are summarized below (I also added lz4 compressed BJData/.jdb file via jd.save(..., {'compression':'lz4'}))
0.236s eye1e4.npy (mmap_mode=None) - size: 800000128 bytes 0.120s eye1e4.npy (mmap_mode=r) 0.764s eye1e4_bjd_raw_ndsyntax.jdb (with C extension _bjdata in sys.path) - size: 800000014 bytes 0.599s eye1e4_bjd_raw_ndsyntax.jdb (without C extension _bjdata) 1.533s eye1e4_bjd_zlib.jdb (without C extension _bjdata) - size: 813721 0.697s eye1e4_bjd_lzma.jdb (without C extension _bjdata) - size: 113067 0.918s eye1e4_bjd_lz4.jdb (without C extension _bjdata) - size: 3371487 bytes
the mmapped loading remains to be the fastest, but the run-time is more realistic. I thought the lz4 compression would offer much faster decompression, but in this special workload, it isn't the case.
It is also interesting to see that the bjdata's C extension <https://github.com/NeuroJSON/pybj/tree/master/src> did not help when parsing a single large array compared to the native python parser, suggesting rooms for further optimization.
Qianqian
_______________________________________________ NumPy-Discussion mailing list -- numpy-discussion@python.org To unsubscribe send an email to numpy-discussion-leave@python.org https://mail.python.org/mailman3/lists/numpy-discussion.python.org/ Member address: faltet@gmail.com
-- Francesc Alted
hi Francesc, wonderful works on blosc2! congrats! this is exactly the direction that I would hope more data creators/data users would pay attention to. clearly blosc2 is a well positioned for high performance - msgpack is one of the most proliferated binary JSON formats out there, with many extensively optimized libraries; zstd is also a rapidly emerging compression class that has a well developed multi-threading support. this combination likely has the best that the current toolchain can offer to deliver good performance and robustness. The added SIMD and data chunking features further push the performance bar. I am aware that msgpack does not currently support packed ND-array data type (see my PR to add this syntax at https://github.com/msgpack/msgpack/pull/267), I suppose blosc2 must have been using customized buffers warped under an ext32 container, is that the case? or you implemented your own unofficial ext64 type? I am not surprised to see blosc2 outperforms npz/jdb in compression benchmarks because zstd supports multi-threading, that makes a huge difference, as shown clearly in this 2017 benchmark that I found online https://community.centminmod.com/threads/compression-comparison-benchmarks-z... using the multi-threaded versions of zlib (pigz) and lzma (pxz, pixz, or plzip) would be a more apple-to-apple comparison, but I do believe zstd may still hold an edge in speed (but may trade for less compression ratio). I also noticed that lbzip2 also gives relatively good speed and high compression ratio. Nothing beats lzma (lzma/zip/xz) in compression ratio, even with the highest setting in zstd. I absolutely agree with you that different flavors of binary JSON formats (Msgpack vs CBOR vs BSON vs UBJSON vs BJData) matters little because they are all JSON-convertible and follow the same design principles as JSON - namely simplicity, generality and lightweight. I did make some deliberations when deciding whether to use Msgpack vs UBJSON/BJData as the main binary format for NeuroJSON, there were two things had steered my decision: 1. there is *no official packed ND array support* in both Msgpack and UBJSON. ND-array is such a fundamental data structure for scientific data storage and it has to be the first-class citizen in data serialization formats - storing an ND array in nested 1D list, as done in standard msgpack/ubjson, not only lose the dimensional regularity but also adds overheads and breaks the continuous binary buffer. That was the main reason that I had to extend UBJSON <https://groups.google.com/g/universal-binary-json/c/tgMCEbOmhes/m/s7JlCl58hv...> as BJData to natively support ND-array syntax 2. a key belief <https://pbs.twimg.com/media/FCD_JNtWQAgLq6N?format=png&name=4096x4096> of the NeuroJSON project is that "human readability" is the single most important factor to decide the longevity of both codes and data. The human-readability of codes have been well addressed and reinforced by open-source/free/libre software licenses (specifically, Freedom 1 <https://www.gnu.org/philosophy/free-sw.en.html#make-changes>). but not many people have been paying attention to the "readability" of data. Admittedly, it is a harder problem. storing data in text files results in much larger size and slow speed, so storing binary data in application-defined binary files, just like npy, is extremely common. However, these binary files in most cases are not directly readable; they depend on a marching parser, which carrys the format spec/schema separately from the data themselves, to correctly read/write. Because the data files are not self-contained, usually not self-documenting, their utility heavily depends on the parser writers - when a parser phase out an older format, or does not implement the format rigorously, the data ultimately will no longer able to be opened and become useless. One feature that really drew my attention to UBJSON/BJData is that they are "quasi-human-readable <https://github.com/NeuroJSON/bjdata/blob/Draft_2/Binary_JData_Specification....>". This is rather *unique* among all binary formats. This is because the "semantic" elements (data type markers, field names and strings) in UBJSON/BJData are all human-readable. Essentially one can open such binary file with a text editor and figure out what's inside - if the data file is well self-documented (which it permits), then such data can be quickly understood without depending on a parser. you can try this command on the lzma.jdb file *|$ strings -n2 eye5chunk_bjd_lzma.jdb | astyle | sed '/_ArrayZipData_/q'|*| ||[ {U|| || _ArrayType_SU|| || doubleU|| || _ArraySize_[U|| || ]U|| || _ArrayZipType_SU|| || lzmaU|| || _ArrayZipSize_[U|| || m@|| || ]U|| || _ArrayZipData_[$U#uE|| | as you can see, the subfields of the data (|_ArraySize_, _ArrayType_|, ...), as well as the data markers (|[,{,U, S, ...|) and string values (|"double","lzma"|, ...) are all directly readable. There are garbled text in the binary stream that may also be printed to make it hard to read, but it's readability is still way better than most other binary files where the datafield's meaning/format are completely decoupled to the parser or the semantic markers are not human readable (such as in msgpack). again, I applaud the wonderful works from the blosc2 team and have no doubt it has many advantages to offer to sharing array data, on the other side, I do want to advocate for considering readability and portability to the data files. Essentially the NeuroJSON specs <http://neurojson.org/#specs> (JData <https://github.com/NeuroJSON/jdata/blob/Draft_2/JData_specification.md>, BJData <https://github.com/NeuroJSON/bjdata/blob/Draft_2/Binary_JData_Specification....>, etc) are taking the mission of building a "source-code language" for scientific data storage. Qianqian On 8/27/22 04:32, Francesc Alted wrote:
Hi Qianqian,
Your work in bjdata's is very interesting. Our team (Blosc) has been working on something along these lines, and I was curious on how the different approaches compares. In particular, Blosc2 uses the msgpack format to store binary data in a flexible way, but in my experience, using binary JSON or msgpack is not that important; the real thing is to be able to compress data in chunks that fits in CPU caches, and then trust in fast codecs and filters for speed.
I have setup a small benchmark (https://gist.github.com/FrancescAlted/e4d186404f4c87d9620cb6f89a03ba0d) based on your setup and here are my numbers (using an AMD 5950X processor, and a fast SSD here):
(python-blosc2) faltet2@ryzen16:~/blosc/python-blosc2/bench$ PYTHONPATH=.. python read-binary-data.py save time for creating big array (and splits): 0.009s (86.5 GB/s)
** Saving data ** time for saving with npy: 0.450s (1.65 GB/s) time for saving with np.memmap: 0.689s (1.08 GB/s) time for saving with npz: 1.021s (0.73 GB/s) time for saving with jdb (zlib): 4.614s (0.161 GB/s) time for saving with jdb (lzma): 11.294s (0.066 GB/s) time for saving with blosc2 (blosclz): 0.020s (37.8 GB/s) time for saving with blosc2 (zstd): 0.153s (4.87 GB/s)
** Load and operate ** time for reducing with plain numpy (memory): 0.016s (47.4 GB/s) time for reducing with npy (np.load, no mmap): 0.144s (5.18 GB/s) time for reducing with np.memmap: 0.055s (13.6 GB/s) time for reducing with npz: 1.808s (0.412 GB/s) time for reducing with jdb (zlib): 1.624s (0.459 GB/s) time for reducing with jdb (lzma): 0.255s (2.92 GB/s) time for reducing with blosc2 (blosclz): 0.042s (17.7 GB/s) time for reducing with blosc2 (zstd): 0.070s (10.7 GB/s) Total sum: 10000.0
So, it is evident that in this scenario compression can accelerate things a lot, specially for compression. Here are the sizes:
(python-blosc2) faltet2@ryzen16:~/blosc/python-blosc2/bench$ ll -h eye5* -rw-rw-r-- 1 faltet2 faltet2 989K ago 27 09:51 eye5_blosc2_blosclz.b2frame -rw-rw-r-- 1 faltet2 faltet2 188K ago 27 09:51 eye5_blosc2_zstd.b2frame -rw-rw-r-- 1 faltet2 faltet2 121K ago 27 09:51 eye5chunk_bjd_lzma.jdb -rw-rw-r-- 1 faltet2 faltet2 795K ago 27 09:51 eye5chunk_bjd_zlib.jdb -rw-rw-r-- 1 faltet2 faltet2 763M ago 27 09:51 eye5chunk-memmap.npy -rw-rw-r-- 1 faltet2 faltet2 763M ago 27 09:51 eye5chunk.npy -rw-rw-r-- 1 faltet2 faltet2 785K ago 27 09:51 eye5chunk.npz
Regarding decompression, I am quite pleased on how jdb+lzma performs (specially with the compression ratio). But in order to provide a better idea on the actual read performance, it is better to evict the files from the OS cache. Also, the benchmark performs some operation on data (in this case a reduction) to make sure that all the data is processed.
So, let's evict the files:
(python-blosc2) faltet2@ryzen16:~/blosc/python-blosc2/bench$ vmtouch -ev eye5* Evicting eye5_blosc2_blosclz.b2frame Evicting eye5_blosc2_zstd.b2frame Evicting eye5chunk_bjd_lzma.jdb Evicting eye5chunk_bjd_zlib.jdb Evicting eye5chunk-memmap.npy Evicting eye5chunk.npy Evicting eye5chunk.npz
Files: 7 Directories: 0 Evicted Pages: 391348 (1G) Elapsed: 0.084441 seconds
And then re-run the benchmark (without re-creating the files indeed):
(python-blosc2) faltet2@ryzen16:~/blosc/python-blosc2/bench$ PYTHONPATH=.. python read-binary-data.py time for creating big array (and splits): 0.009s (80.4 GB/s)
** Load and operate ** time for reducing with plain numpy (memory): 0.065s (11.5 GB/s) time for reducing with npy (np.load, no mmap): 0.413s (1.81 GB/s) time for reducing with np.memmap: 0.547s (1.36 GB/s) time for reducing with npz: 1.881s (0.396 GB/s) time for reducing with jdb (zlib): 1.845s (0.404 GB/s) time for reducing with jdb (lzma): 0.204s (3.66 GB/s) time for reducing with blosc2 (blosclz): 0.043s (17.2 GB/s) time for reducing with blosc2 (zstd): 0.072s (10.4 GB/s) Total sum: 10000.0
In this case we can notice that the combination of blosc2+blosclz achieves speeds that are faster than using a plain numpy array. Having disk I/O going faster than memory is strange enough, but if we take into account that these arrays compress extremely well (more than 1000x in this case), then the I/O overhead is really low compared with the cost of computation (all the decompression takes place in CPU cache, not memory), so in the end, this is not that surprising.
Cheers!
On Fri, Aug 26, 2022 at 4:26 AM Qianqian Fang <fangqq@gmail.com> wrote:
On 8/25/22 18:33, Neal Becker wrote:
the loading time (from an nvme drive, Ubuntu 18.04, python 3.6.9, numpy 1.19.5) for each file is listed below:
|0.179s eye1e4.npy (mmap_mode=None)|| ||0.001s eye1e4.npy (mmap_mode=r)|| ||0.718s eye1e4_bjd_raw_ndsyntax.jdb|| ||1.474s eye1e4_bjd_zlib.jdb|| ||0.635s eye1e4_bjd_lzma.jdb|
clearly, mmapped loading is the fastest option without a surprise; it is true that the raw bjdata file is about 5x slower than npy loading, but given the main chunk of the data are stored identically (as contiguous buffer), I suppose with some optimization of the decoder, the gap between the two can be substantially shortened. The longer loading time of zlib/lzma (and similarly saving times) reflects a trade-off between smaller file sizes and time for compression/decompression/disk-IO.
I think the load time for mmap may be deceptive, it isn't actually loading anything, just mapping to memory. Maybe a better benchmark is to actually process the data, e.g., find the mean which would require reading the values.
yes, that is correct, I meant to metion it wasn't an apple-to-apple comparison.
the loading times for fully-loading the data and printing the mean, by running the below line
|t=time.time(); newy=jd.load('eye1e4_bjd_raw_ndsyntax.jdb'); print(np.mean(newy)); t1=time.time() - t; print(t1)|
are summarized below (I also added lz4 compressed BJData/.jdb file via |jd.save(..., {'compression':'lz4'})|)
|0.236s eye1e4.npy (mmap_mode=None)||- size: 800000128 bytes ||0.120s eye1e4.npy (mmap_mode=r)|| ||0.764s eye1e4_bjd_raw_ndsyntax.jdb||(with C extension _bjdata in sys.path) - size: 800000014 bytes| ||0.599s eye1e4_bjd_raw_ndsyntax.jdb||(without C extension _bjdata)| ||1.533s eye1e4_bjd_zlib.jdb|||(without C extension _bjdata)||| - size: 813721 ||0.697s eye1e4_bjd_lzma.jdb|||(without C extension _bjdata) - size: 113067 |||||0.918s eye1e4_bjd_lz4.jdb|||(without C extension _bjdata) - size: 3371487 bytes|| ||||
the mmapped loading remains to be the fastest, but the run-time is more realistic. I thought the lz4 compression would offer much faster decompression, but in this special workload, it isn't the case.
It is also interesting to see that the bjdata's C extension <https://github.com/NeuroJSON/pybj/tree/master/src> did not help when parsing a single large array compared to the native python parser, suggesting rooms for further optimization|.||| ||
|| ||
||Qianqian||
|| ||
_______________________________________________ NumPy-Discussion mailing list -- numpy-discussion@python.org To unsubscribe send an email to numpy-discussion-leave@python.org https://mail.python.org/mailman3/lists/numpy-discussion.python.org/ Member address: faltet@gmail.com
-- Francesc Alted
_______________________________________________ NumPy-Discussion mailing list --numpy-discussion@python.org To unsubscribe send an email tonumpy-discussion-leave@python.org https://mail.python.org/mailman3/lists/numpy-discussion.python.org/ Member address:fangqq@gmail.com

On Sat, Aug 27, 2022 at 9:17 AM Qianqian Fang <fangqq@gmail.com> wrote:
2. a key belief <https://pbs.twimg.com/media/FCD_JNtWQAgLq6N?format=png&name=4096x4096> of the NeuroJSON project is that "human readability" is the single most important factor to decide the longevity of both codes and data. The human-readability of codes have been well addressed and reinforced by open-source/free/libre software licenses (specifically, Freedom 1 <https://www.gnu.org/philosophy/free-sw.en.html#make-changes>). but not many people have been paying attention to the "readability" of data.
Hi Qianqian, I think you might be interested in the Zarr storage format, for exactly this same reason: https://zarr.dev/ Zarr is focused more on "big data" but one of its fundamental strengths is that the format is extremely simple. All the metadata is in JSON, with arrays divided up into smaller "chunks" stored as files on disk or in cloud object stores. Cheers, Stephan
On 8/27/22 15:18, Stephan Hoyer wrote:
Hi Qianqian,
I think you might be interested in the Zarr storage format, for exactly this same reason: https://zarr.dev/
Zarr is focused more on "big data" but one of its fundamental strengths is that the format is extremely simple. All the metadata is in JSON, with arrays divided up into smaller "chunks" stored as files on disk or in cloud object stores.
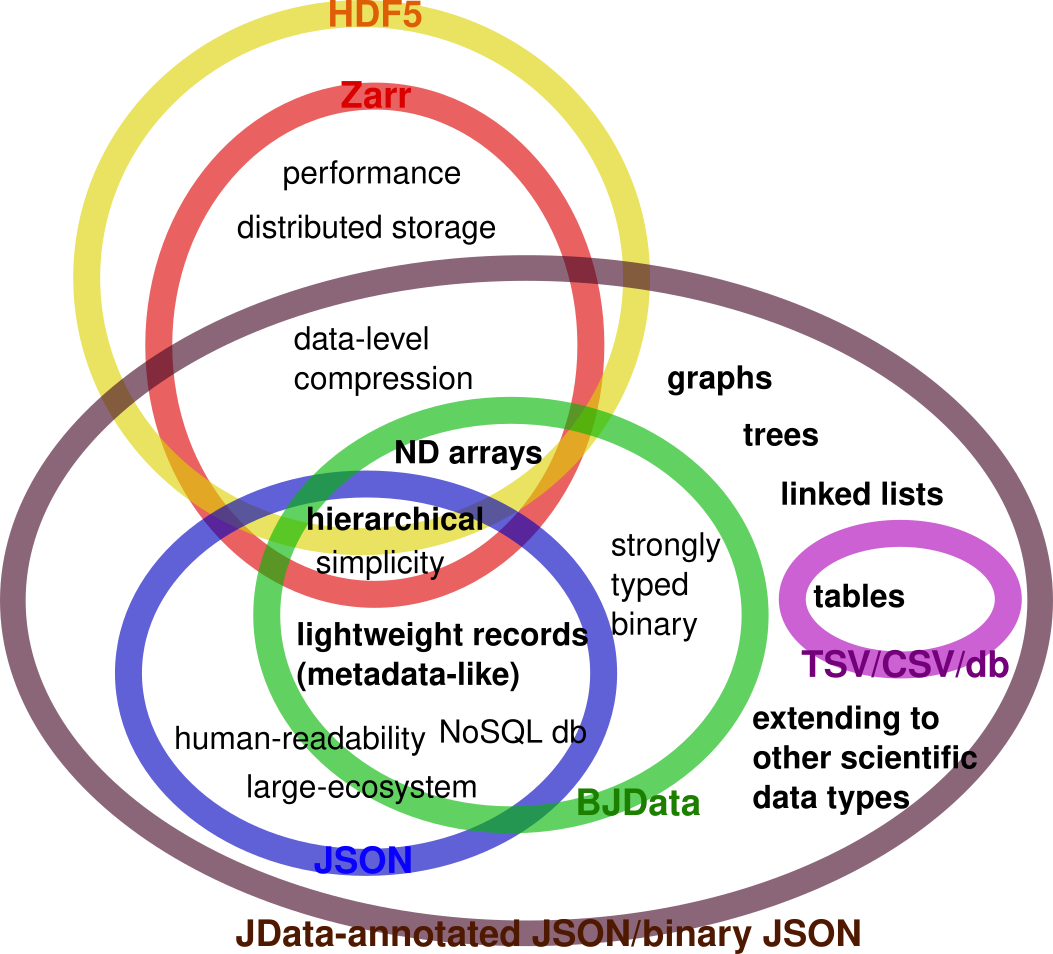
hi Stephan, yes, I am aware of Zarr and Zarr developers have also make appearances in various neuroimaging data storage discussions. Zarr and typical binary JSON (msgpack/ubjson) are focusing on different applications and are attacking different types of challenges. Zarr is python-focused and large-sized ND-array/parallel array processing focused. ideologically, it makes a great mix between the simplicity of JSON and performance/hierarchical data support from HDF5, attracting HDF5 users as a simpler alternative. Both Zarr and HDF5 datasets are heavily oriented around ND-arrays (if not exclusively). JSON/binary JSON came entirely from the other side of the data spectrum - where heterogeneous, lightweight (scalars or short vectors) hierarchical data, such as metadata/web app data packets had been the primary focus. They are also language- and platform-neutral (like HDF5). Although JSON supports nested arrays, it doesn't really care much about the regularity of the dimensions (i.e. whether it is an ND array). So, previously, the two types of formats did not have any common denominators between targeted data types and applications. but clearly, if you really want, either of them are syntactically capable of representing data from the other side of the spectrum (just a matter of efficiency). I want to mention that ND numerical arrays and lightweight heterogeneous data do not cover everything scientific data storage/exchange needed - an area that both are missing contains other common data structures such as tables, graphs, lists etc. CSV/TSV or databases often fill in the table data storage needs, but introduces additional format to handle in the pipeline. I drew a Venn diagram, can be found in the attachment, just to illustrate the scopes/strengths of various formats. Zarr or HDF5 developers are absolutely entitled (and welcomed) to "invade" the other side of the data type spectrum. However, I decided to go the other way around, i.e., extending JSON and binary JSON to be able to store strongly-typed <https://github.com/NeuroJSON/jdata/blob/master/JData_specification.md#compre...> binary data, ND-arrays <https://github.com/NeuroJSON/jdata/blob/master/JData_specification.md#n-dime...>, even the middle-ground data types such as tables/graphs <https://github.com/NeuroJSON/jdata/blob/master/images/JData_Diagram.pdf> via the JData spec <https://github.com/NeuroJSON/jdata/blob/master/JData_specification.md>, is largely based on the consideration of taking advantage of the existing ecosystem benefit of JSON. Regardless whether Zarr uses standard JSON to store metadata or something else, one still need to write a Zarr parser (in each needed programming language) to be able to read/write it. There is no existing parser that can automatically open it or knows how to handle it. In comparison, the data type extension JData spec made are purely in the semantic layer and does not alter the serialization syntax (UBJSON-to-BJData upgrade was an exception because UBJSON does not support NDarray, that makes it necessary). Therefore, .jdt or .jdb files with JData annotations are backward (and forward) compatible to all existing JSON or BJData parsers. So these files not only are directly readable by an editor, they are also readily parsable without specialized reader. The closest mirror I can find in the Python world is JSON tricks (https://github.com/mverleg/pyjson_tricks), but again, JSON tricks is python focused and JData spec focuses on language independent data exchange (say between Python and MATLAB or C - it started in MATLAB when I wrote JSONLab <https://github.com/fangq/jsonlab>). Zarr and HDF5 will likely hold their edges in high-performance binary array data storage/access. However, the types of the data I was tasked to find ways to encode/share/integrate are *extremely heterogeneous* - containing mixtures of volumetric data (ND arrays as in MRI scans), tables (.csv,.tsv), and metadata (.json) sorted in a file/folder tree, as currently standardized by the BIDS project (https://bids.neuroimaging.io/), see example datasets here https://github.com/bids-standard/bids-examples In such case, I found that JData-annotated JSON/binary JSON in combination with NoSQL databases (MongoDB/CouchDB) offers the most intuitive and scalable way, and requires the least amount of work, to both store such data locally as human-readable files or search in the cloud as document-based databases. Qianqian
Cheers, Stephan
_______________________________________________ NumPy-Discussion mailing list --numpy-discussion@python.org To unsubscribe send an email tonumpy-discussion-leave@python.org https://mail.python.org/mailman3/lists/numpy-discussion.python.org/ Member address:fangqq@gmail.com
{kind=link}
Hi, Thanks for the detailed description on what you are pursuing. Find my comments below. On Sat, Aug 27, 2022 at 6:17 PM Qianqian Fang <fangqq@gmail.com> wrote:
hi Francesc,
wonderful works on blosc2! congrats! this is exactly the direction that I would hope more data creators/data users would pay attention to.
clearly blosc2 is a well positioned for high performance - msgpack is one of the most proliferated binary JSON formats out there, with many extensively optimized libraries; zstd is also a rapidly emerging compression class that has a well developed multi-threading support. this combination likely has the best that the current toolchain can offer to deliver good performance and robustness. The added SIMD and data chunking features further push the performance bar.
I am aware that msgpack does not currently support packed ND-array data type (see my PR to add this syntax at https://github.com/msgpack/msgpack/pull/267), I suppose blosc2 must have been using customized buffers warped under an ext32 container, is that the case? or you implemented your own unofficial ext64 type?
Not exactly. What we've done is to encode the header and the trailer (i.e. where the metadata is) of the frame with msgpack. The chunks section <https://github.com/Blosc/c-blosc2/blob/main/README_CFRAME_FORMAT.rst#chunks> is where the actual data is; this section does not follow a msgpack structure as such, but it is rather a sequence of data chunks and an index (for quickly locating the chunks). You can easily access the header or trailer sections reading from the start or the end of the frame. This way you don't need to update the indexes of chunks in msgpack, which can be expensive during data updates. This indeed prevents data to be dumped by using typical msgpack tools, but our sense is that users should care mostly about metainfo, and let the libraries to deal with the actual data in the most efficient way.
I am not surprised to see blosc2 outperforms npz/jdb in compression benchmarks because zstd supports multi-threading, that makes a huge difference, as shown clearly in this 2017 benchmark that I found online
https://community.centminmod.com/threads/compression-comparison-benchmarks-z...
using the multi-threaded versions of zlib (pigz) and lzma (pxz, pixz, or plzip) would be a more apple-to-apple comparison, but I do believe zstd may still hold an edge in speed (but may trade for less compression ratio). I also noticed that lbzip2 also gives relatively good speed and high compression ratio. Nothing beats lzma (lzma/zip/xz) in compression ratio, even with the highest setting in zstd.
Not quite. Blosc2 does not use the multi-threaded version of zstd; it rather implements its own internal multi-threading engine and hence all the codecs (and filters) benefit from it, so no need to trust on a multi-threaded codec for speed. Also, as filters execute prior to codecs, they can reuse the same internal buffers, avoiding copies (which is critical for achieving high I/O performance). I absolutely agree with you that different flavors of binary JSON formats
(Msgpack vs CBOR vs BSON vs UBJSON vs BJData) matters little because they are all JSON-convertible and follow the same design principles as JSON - namely simplicity, generality and lightweight.
I did make some deliberations when deciding whether to use Msgpack vs UBJSON/BJData as the main binary format for NeuroJSON, there were two things had steered my decision:
1. there is *no official packed ND array support* in both Msgpack and UBJSON. ND-array is such a fundamental data structure for scientific data storage and it has to be the first-class citizen in data serialization formats - storing an ND array in nested 1D list, as done in standard msgpack/ubjson, not only lose the dimensional regularity but also adds overheads and breaks the continuous binary buffer. That was the main reason that I had to extend UBJSON <https://groups.google.com/g/universal-binary-json/c/tgMCEbOmhes/m/s7JlCl58hv...> as BJData to natively support ND-array syntax
As said, we are not using packed ND array in msgpack, but rather, using our own schema. Blosc2 supports the concept of metalayers for adding new meaning to the stored data (see https://www.blosc.org/docs/Caterva-Blosc2-SciPy2019.pdf, slide 17). One of these layers is Caterva, where we have added support for MD arrays <https://github.com/Blosc/caterva/blob/master/CATERVA_METALAYER.rst>. Note that our implementation for supporting ND arrays uses two levels of partitioning (chunks and blocks) for: 1. Allow finer granularity <https://www.blosc.org/posts/caterva-slicing-perf/> in retrieving data. 2. Better adapt to the memory hierarchies (i.e. main memory and cache levels in CPU) for efficiency <https://www.blosc.org/posts/breaking-memory-walls/>. OTOH, I have noticed that your patch for msgpack <https://github.com/msgpack/msgpack/pull/267/files#diff-bc6661da34ecae62fbe72...> only suggest to use uint32 as the type for array shape. This would prevent to use creating arrays where some dim is larger than 2^32. Is that intended? 2. a key belief
<https://pbs.twimg.com/media/FCD_JNtWQAgLq6N?format=png&name=4096x4096> of the NeuroJSON project is that "human readability" is the single most important factor to decide the longevity of both codes and data. The human-readability of codes have been well addressed and reinforced by open-source/free/libre software licenses (specifically, Freedom 1 <https://www.gnu.org/philosophy/free-sw.en.html#make-changes>). but not many people have been paying attention to the "readability" of data. Admittedly, it is a harder problem. storing data in text files results in much larger size and slow speed, so storing binary data in application-defined binary files, just like npy, is extremely common. However, these binary files in most cases are not directly readable; they depend on a marching parser, which carrys the format spec/schema separately from the data themselves, to correctly read/write. Because the data files are not self-contained, usually not self-documenting, their utility heavily depends on the parser writers - when a parser phase out an older format, or does not implement the format rigorously, the data ultimately will no longer able to be opened and become useless.
One feature that really drew my attention to UBJSON/BJData is that they are "quasi-human-readable <https://github.com/NeuroJSON/bjdata/blob/Draft_2/Binary_JData_Specification....>". This is rather *unique* among all binary formats. This is because the "semantic" elements (data type markers, field names and strings) in UBJSON/BJData are all human-readable. Essentially one can open such binary file with a text editor and figure out what's inside - if the data file is well self-documented (which it permits), then such data can be quickly understood without depending on a parser.
you can try this command on the lzma.jdb file
*$ strings -n2 eye5chunk_bjd_lzma.jdb | astyle | sed '/_ArrayZipData_/q'* [ {U _ArrayType_SU doubleU _ArraySize_[U ]U _ArrayZipType_SU lzmaU _ArrayZipSize_[U m@ ]U _ArrayZipData_[$U#uE
as you can see, the subfields of the data (_ArraySize_, _ArrayType_, ...), as well as the data markers ([,{,U, S, ...) and string values ( "double","lzma", ...) are all directly readable. There are garbled text in the binary stream that may also be printed to make it hard to read, but it's readability is still way better than most other binary files where the datafield's meaning/format are completely decoupled to the parser or the semantic markers are not human readable (such as in msgpack).
I see your point, and your intent is really appreciated. It is just in the 10's GB and up domain that I see BJData a bit lacking in that text handling tools (strings, sed, not to mention editors, where you can run out of memory very soon) can become unnecessarily slow for retrieving the metainfo. We really feel that such metainfo should go either at the beginning or at the end of the frame, where it can be found and processed way more efficiently. OTOH, I agree in that msgpack is not human readable directly, but the format is becoming so ubiquitous that you can find standard tools for introspecting metadata quite easily: $ msgpack2json -di eye5_blosc2_blosclz.b2frame [ "b2frame\u0000", 97, 1012063, "\u0012\u0000P\u0000", 800000000, 1011729, 8, 0, 16000000, 8, 1, false, <ext type:6 size:16 0000000000010000...>, [ 7, {}, [] ] ] And, as there are msgpack libraries for almost all of the currently used languages, I think that formats based on it are as open and transparent as we can get.
again, I applaud the wonderful works from the blosc2 team and have no doubt it has many advantages to offer to sharing array data, on the other side, I do want to advocate for considering readability and portability to the data files. Essentially the NeuroJSON specs <http://neurojson.org/#specs> (JData <https://github.com/NeuroJSON/jdata/blob/Draft_2/JData_specification.md>, BJData <https://github.com/NeuroJSON/bjdata/blob/Draft_2/Binary_JData_Specification....>, etc) are taking the mission of building a "source-code language" for scientific data storage.
Thanks, I concur with your work too! It is always nice to discuss with people that has put a lot of thought in how to pack data efficiently, and as simply as possible (but not any simpler!). Actually, we might be adopting some aspects of JData <https://github.com/fangq/jdata> to be able to store different objects (arrays, tables, graphs, trees...) in the same frame in a future possible extension of Blosc2. Or, maybe using JData as the external container for existing Blosc2 frames. Very interesting discussion indeed; many possibilities are open now! Cheers, Francesc On Sat, Aug 27, 2022 at 6:17 PM Qianqian Fang <fangqq@gmail.com> wrote:
hi Francesc,
wonderful works on blosc2! congrats! this is exactly the direction that I would hope more data creators/data users would pay attention to.
clearly blosc2 is a well positioned for high performance - msgpack is one of the most proliferated binary JSON formats out there, with many extensively optimized libraries; zstd is also a rapidly emerging compression class that has a well developed multi-threading support. this combination likely has the best that the current toolchain can offer to deliver good performance and robustness. The added SIMD and data chunking features further push the performance bar.
I am aware that msgpack does not currently support packed ND-array data type (see my PR to add this syntax at https://github.com/msgpack/msgpack/pull/267), I suppose blosc2 must have been using customized buffers warped under an ext32 container, is that the case? or you implemented your own unofficial ext64 type?
I am not surprised to see blosc2 outperforms npz/jdb in compression benchmarks because zstd supports multi-threading, that makes a huge difference, as shown clearly in this 2017 benchmark that I found online
https://community.centminmod.com/threads/compression-comparison-benchmarks-z...
using the multi-threaded versions of zlib (pigz) and lzma (pxz, pixz, or plzip) would be a more apple-to-apple comparison, but I do believe zstd may still hold an edge in speed (but may trade for less compression ratio). I also noticed that lbzip2 also gives relatively good speed and high compression ratio. Nothing beats lzma (lzma/zip/xz) in compression ratio, even with the highest setting in zstd.
I absolutely agree with you that different flavors of binary JSON formats (Msgpack vs CBOR vs BSON vs UBJSON vs BJData) matters little because they are all JSON-convertible and follow the same design principles as JSON - namely simplicity, generality and lightweight.
I did make some deliberations when deciding whether to use Msgpack vs UBJSON/BJData as the main binary format for NeuroJSON, there were two things had steered my decision:
1. there is *no official packed ND array support* in both Msgpack and UBJSON. ND-array is such a fundamental data structure for scientific data storage and it has to be the first-class citizen in data serialization formats - storing an ND array in nested 1D list, as done in standard msgpack/ubjson, not only lose the dimensional regularity but also adds overheads and breaks the continuous binary buffer. That was the main reason that I had to extend UBJSON <https://groups.google.com/g/universal-binary-json/c/tgMCEbOmhes/m/s7JlCl58hv...> as BJData to natively support ND-array syntax
2. a key belief <https://pbs.twimg.com/media/FCD_JNtWQAgLq6N?format=png&name=4096x4096> of the NeuroJSON project is that "human readability" is the single most important factor to decide the longevity of both codes and data. The human-readability of codes have been well addressed and reinforced by open-source/free/libre software licenses (specifically, Freedom 1 <https://www.gnu.org/philosophy/free-sw.en.html#make-changes>). but not many people have been paying attention to the "readability" of data. Admittedly, it is a harder problem. storing data in text files results in much larger size and slow speed, so storing binary data in application-defined binary files, just like npy, is extremely common. However, these binary files in most cases are not directly readable; they depend on a marching parser, which carrys the format spec/schema separately from the data themselves, to correctly read/write. Because the data files are not self-contained, usually not self-documenting, their utility heavily depends on the parser writers - when a parser phase out an older format, or does not implement the format rigorously, the data ultimately will no longer able to be opened and become useless.
One feature that really drew my attention to UBJSON/BJData is that they are "quasi-human-readable <https://github.com/NeuroJSON/bjdata/blob/Draft_2/Binary_JData_Specification....>". This is rather *unique* among all binary formats. This is because the "semantic" elements (data type markers, field names and strings) in UBJSON/BJData are all human-readable. Essentially one can open such binary file with a text editor and figure out what's inside - if the data file is well self-documented (which it permits), then such data can be quickly understood without depending on a parser.
you can try this command on the lzma.jdb file
*$ strings -n2 eye5chunk_bjd_lzma.jdb | astyle | sed '/_ArrayZipData_/q'* [ {U _ArrayType_SU doubleU _ArraySize_[U ]U _ArrayZipType_SU lzmaU _ArrayZipSize_[U m@ ]U _ArrayZipData_[$U#uE
as you can see, the subfields of the data (_ArraySize_, _ArrayType_, ...), as well as the data markers ([,{,U, S, ...) and string values ( "double","lzma", ...) are all directly readable. There are garbled text in the binary stream that may also be printed to make it hard to read, but it's readability is still way better than most other binary files where the datafield's meaning/format are completely decoupled to the parser or the semantic markers are not human readable (such as in msgpack).
again, I applaud the wonderful works from the blosc2 team and have no doubt it has many advantages to offer to sharing array data, on the other side, I do want to advocate for considering readability and portability to the data files. Essentially the NeuroJSON specs <http://neurojson.org/#specs> (JData <https://github.com/NeuroJSON/jdata/blob/Draft_2/JData_specification.md>, BJData <https://github.com/NeuroJSON/bjdata/blob/Draft_2/Binary_JData_Specification....>, etc) are taking the mission of building a "source-code language" for scientific data storage.
Qianqian
On 8/27/22 04:32, Francesc Alted wrote:
Hi Qianqian,
Your work in bjdata's is very interesting. Our team (Blosc) has been working on something along these lines, and I was curious on how the different approaches compares. In particular, Blosc2 uses the msgpack format to store binary data in a flexible way, but in my experience, using binary JSON or msgpack is not that important; the real thing is to be able to compress data in chunks that fits in CPU caches, and then trust in fast codecs and filters for speed.
I have setup a small benchmark ( https://gist.github.com/FrancescAlted/e4d186404f4c87d9620cb6f89a03ba0d) based on your setup and here are my numbers (using an AMD 5950X processor, and a fast SSD here):
(python-blosc2) faltet2@ryzen16:~/blosc/python-blosc2/bench$ PYTHONPATH=.. python read-binary-data.py save time for creating big array (and splits): 0.009s (86.5 GB/s)
** Saving data ** time for saving with npy: 0.450s (1.65 GB/s) time for saving with np.memmap: 0.689s (1.08 GB/s) time for saving with npz: 1.021s (0.73 GB/s) time for saving with jdb (zlib): 4.614s (0.161 GB/s) time for saving with jdb (lzma): 11.294s (0.066 GB/s) time for saving with blosc2 (blosclz): 0.020s (37.8 GB/s) time for saving with blosc2 (zstd): 0.153s (4.87 GB/s)
** Load and operate ** time for reducing with plain numpy (memory): 0.016s (47.4 GB/s) time for reducing with npy (np.load, no mmap): 0.144s (5.18 GB/s) time for reducing with np.memmap: 0.055s (13.6 GB/s) time for reducing with npz: 1.808s (0.412 GB/s) time for reducing with jdb (zlib): 1.624s (0.459 GB/s) time for reducing with jdb (lzma): 0.255s (2.92 GB/s) time for reducing with blosc2 (blosclz): 0.042s (17.7 GB/s) time for reducing with blosc2 (zstd): 0.070s (10.7 GB/s) Total sum: 10000.0
So, it is evident that in this scenario compression can accelerate things a lot, specially for compression. Here are the sizes:
(python-blosc2) faltet2@ryzen16:~/blosc/python-blosc2/bench$ ll -h eye5* -rw-rw-r-- 1 faltet2 faltet2 989K ago 27 09:51 eye5_blosc2_blosclz.b2frame -rw-rw-r-- 1 faltet2 faltet2 188K ago 27 09:51 eye5_blosc2_zstd.b2frame -rw-rw-r-- 1 faltet2 faltet2 121K ago 27 09:51 eye5chunk_bjd_lzma.jdb -rw-rw-r-- 1 faltet2 faltet2 795K ago 27 09:51 eye5chunk_bjd_zlib.jdb -rw-rw-r-- 1 faltet2 faltet2 763M ago 27 09:51 eye5chunk-memmap.npy -rw-rw-r-- 1 faltet2 faltet2 763M ago 27 09:51 eye5chunk.npy -rw-rw-r-- 1 faltet2 faltet2 785K ago 27 09:51 eye5chunk.npz
Regarding decompression, I am quite pleased on how jdb+lzma performs (specially with the compression ratio). But in order to provide a better idea on the actual read performance, it is better to evict the files from the OS cache. Also, the benchmark performs some operation on data (in this case a reduction) to make sure that all the data is processed.
So, let's evict the files:
(python-blosc2) faltet2@ryzen16:~/blosc/python-blosc2/bench$ vmtouch -ev eye5* Evicting eye5_blosc2_blosclz.b2frame Evicting eye5_blosc2_zstd.b2frame Evicting eye5chunk_bjd_lzma.jdb Evicting eye5chunk_bjd_zlib.jdb Evicting eye5chunk-memmap.npy Evicting eye5chunk.npy Evicting eye5chunk.npz
Files: 7 Directories: 0 Evicted Pages: 391348 (1G) Elapsed: 0.084441 seconds
And then re-run the benchmark (without re-creating the files indeed):
(python-blosc2) faltet2@ryzen16:~/blosc/python-blosc2/bench$ PYTHONPATH=.. python read-binary-data.py time for creating big array (and splits): 0.009s (80.4 GB/s)
** Load and operate ** time for reducing with plain numpy (memory): 0.065s (11.5 GB/s) time for reducing with npy (np.load, no mmap): 0.413s (1.81 GB/s) time for reducing with np.memmap: 0.547s (1.36 GB/s) time for reducing with npz: 1.881s (0.396 GB/s) time for reducing with jdb (zlib): 1.845s (0.404 GB/s) time for reducing with jdb (lzma): 0.204s (3.66 GB/s) time for reducing with blosc2 (blosclz): 0.043s (17.2 GB/s) time for reducing with blosc2 (zstd): 0.072s (10.4 GB/s) Total sum: 10000.0
In this case we can notice that the combination of blosc2+blosclz achieves speeds that are faster than using a plain numpy array. Having disk I/O going faster than memory is strange enough, but if we take into account that these arrays compress extremely well (more than 1000x in this case), then the I/O overhead is really low compared with the cost of computation (all the decompression takes place in CPU cache, not memory), so in the end, this is not that surprising.
Cheers!
On Fri, Aug 26, 2022 at 4:26 AM Qianqian Fang <fangqq@gmail.com> wrote:
On 8/25/22 18:33, Neal Becker wrote:
the loading time (from an nvme drive, Ubuntu 18.04, python 3.6.9, numpy 1.19.5) for each file is listed below:
0.179s eye1e4.npy (mmap_mode=None) 0.001s eye1e4.npy (mmap_mode=r) 0.718s eye1e4_bjd_raw_ndsyntax.jdb 1.474s eye1e4_bjd_zlib.jdb 0.635s eye1e4_bjd_lzma.jdb
clearly, mmapped loading is the fastest option without a surprise; it is true that the raw bjdata file is about 5x slower than npy loading, but given the main chunk of the data are stored identically (as contiguous buffer), I suppose with some optimization of the decoder, the gap between the two can be substantially shortened. The longer loading time of zlib/lzma (and similarly saving times) reflects a trade-off between smaller file sizes and time for compression/decompression/disk-IO.
I think the load time for mmap may be deceptive, it isn't actually loading anything, just mapping to memory. Maybe a better benchmark is to actually process the data, e.g., find the mean which would require reading the values.
yes, that is correct, I meant to metion it wasn't an apple-to-apple comparison.
the loading times for fully-loading the data and printing the mean, by running the below line
t=time.time(); newy=jd.load('eye1e4_bjd_raw_ndsyntax.jdb'); print(np.mean(newy)); t1=time.time() - t; print(t1)
are summarized below (I also added lz4 compressed BJData/.jdb file via jd.save(..., {'compression':'lz4'}))
0.236s eye1e4.npy (mmap_mode=None) - size: 800000128 bytes 0.120s eye1e4.npy (mmap_mode=r) 0.764s eye1e4_bjd_raw_ndsyntax.jdb (with C extension _bjdata in sys.path) - size: 800000014 bytes 0.599s eye1e4_bjd_raw_ndsyntax.jdb (without C extension _bjdata) 1.533s eye1e4_bjd_zlib.jdb (without C extension _bjdata) - size: 813721 0.697s eye1e4_bjd_lzma.jdb (without C extension _bjdata) - size: 113067 0.918s eye1e4_bjd_lz4.jdb (without C extension _bjdata) - size: 3371487 bytes
the mmapped loading remains to be the fastest, but the run-time is more realistic. I thought the lz4 compression would offer much faster decompression, but in this special workload, it isn't the case.
It is also interesting to see that the bjdata's C extension <https://github.com/NeuroJSON/pybj/tree/master/src> did not help when parsing a single large array compared to the native python parser, suggesting rooms for further optimization.
Qianqian
_______________________________________________ NumPy-Discussion mailing list -- numpy-discussion@python.org To unsubscribe send an email to numpy-discussion-leave@python.org https://mail.python.org/mailman3/lists/numpy-discussion.python.org/ Member address: faltet@gmail.com
-- Francesc Alted
_______________________________________________ NumPy-Discussion mailing list -- numpy-discussion@python.org To unsubscribe send an email to numpy-discussion-leave@python.orghttps://mail.python.org/mailman3/lists/numpy-discussion.python.org/ Member address: fangqq@gmail.com
-- Francesc Alted
On 8/30/22 06:29, Francesc Alted wrote:
Not exactly. What we've done is to encode the header and the trailer (i.e. where the metadata is) of the frame with msgpack. Thechunks section <https://github.com/Blosc/c-blosc2/blob/main/README_CFRAME_FORMAT.rst#chunks>is where the actual data is; this section does not follow a msgpack structure as such, but it is rather a sequence of data chunks and an index (for quickly locating the chunks). You can easily access the header or trailer sections reading from the start or the end of the frame. This way you don't need to update the indexes of chunks in msgpack, which can be expensive during data updates.
This indeed prevents data to be dumped by using typical msgpack tools, but our sense is that users should care mostly about metainfo, and let the libraries to deal with the actual data in the most efficient way.
thanks for your detailed reply. I spent the past few days reading the links/documentations, as well as experimenting the blosc2 meta-compressors, I was quite impressed by the performance of blosc2. I was also happy to see great alignments behind the drives for Caterva those of NeuroJSON. I have a few quick updates 1. I added blosc2 as a codec in my jdata module, as an alternative compressor to zlib/lzma/lz4 https://github.com/NeuroJSON/pyjdata/commit/ce25fa53ce73bf4cbe2cff9799b5a616... 2. as I mentioned, jdata/bjdata were not optimized for speed, they contain many inefficient handling of numpy arrays (as I discovered); after some profiling, I was able to remove most of those, the run-time is now nearly entirely spent in compression/decompression (see attached profiler outputs for the `zlib` compressor benchmark) 3. the new jdata that supports blosc2, v0.5.0, has been tagged and uploaded (https://pypi.org/project/jdata) 4. I wrote a script and compared the run times of various codecs (using BJData and JSON as containers) , the code can be found here https://github.com/NeuroJSON/pyjdata/blob/master/test/benchcodecs.py the save/load times tested on a Ryzen 9 3950X/Ubuntu 18.04 box (at various threads) are listed below (similar to your posted before) *|- Testing npy/npz|*| || 'npy', 'save' 0.2914195 'load' 0.1963226 'size' 800000128|| || 'npz', 'save' 2.8617918 'load' 1.9550347 'size' 813846||||| *|- Testing text-based JSON files (.jdt)|**|*|(nthread=8)|*...|*| || 'zlib', 'save' 2.5132861 'load' 1.7221164 'size' 1084942|| || 'lzma', 'save' 9.5481696 'load' 0.3865211 'size' 150738|| || 'lz4', 'save' 0.3467197 'load' 0.5019965 'size' 4495297|| || 'blosc2blosclz'save' 0.0165646 'load' 0.1143934 'size' 1092747|| || 'blosc2lz4', 'save' 0.0175058 'load' 0.1015181 'size' 1090159|| || 'blosc2lz4hc','save' 0.2102167 'load' 0.1053235 'size' 4315421|| || 'blosc2zlib', 'save' 0.1002635 'load' 0.1188845 'size' 1270252|| || 'blosc2zstd', 'save' 0.0463817 'load' 0.1017909 'size' 253176| || *||**|- Testing binary JSON (BJData) files (.jdb) (nthread=8)...|*| || 'zlib', 'save' 2.4401443 'load' 1.6316463 'size' 813721|| || 'lzma', 'save' 9.3782029 'load' 0.3728334 'size' 113067|| || 'lz4', 'save' 0.3389360 'load' 0.5017435 'size' 3371487|| || 'blosc2blosclz'save' 0.0173912 'load' 0.1042985 'size' 819576|| || 'blosc2lz4', 'save' 0.0133688 'load' 0.1030941 'size' 817635|| || 'blosc2lz4hc','save' 0.1968047 'load' 0.0950071 'size' 3236580|| || 'blosc2zlib', 'save' 0.1023218 'load' 0.1083922 'size' 952705|| || 'blosc2zstd', 'save' 0.0468430 'load' 0.1019175 'size' 189897|||| ||| *||||- Testing binary JSON (BJData) files (.jdb) ||*|*||(nthread=1)|...|*| | 'blosc2blosclz'save' 0.0883078 'load' 0.2432985 'size' 819576 'blosc2lz4', 'save' 0.0867996 'load' 0.2394990 'size' 817635 'blosc2lz4hc','save' 2.4794559 'load' 0.2498981 'size' 3236580 'blosc2zlib', 'save' 0.7477457 'load' 0.4873921 'size' 952705 'blosc2zstd', 'save' 0.3435547 'load' 0.3754863 'size' 189897 | |*||||- Testing binary JSON (BJData) files (.jdb) ||*|*||(nthread=32)|...|*| || 'blosc2blosclz'save' 0.0197186 'load' 0.1410989 'size' 819576 'blosc2lz4', 'save' 0.0168068 'load' 0.1414074 'size' 817635 'blosc2lz4hc','save' 0.0790011 'load' 0.0935394 'size' 3236580 'blosc2zlib', 'save' 0.0608818 'load' 0.0985531 'size' 952705 'blosc2zstd', 'save' 0.0370790 'load' 0.0945577 'size' 189897 | a few observations: 1. single-threaded zlib/lzma are relatively slow, reflected by npz, zlib and lzma results 2. for simple data structure like this one, using JSON/text-based wrapper vs a binary wrapper has a marginal difference in speed; the only penalty is that text/JSON is ~33% larger than binary in size due to base64 3. blosc2 overall delivered very impressive speed - even in single thread, it can be than faster than uncompressed npz or other standard compression methods 4. several blosc2 compressors scaled well with more threads 5. it is a bit strange that blosc2lz4hc yielded larger file size, similar to that from a standard lz4, but blosc2lz4 produces a size comparable to zlib; I expected reverted findings, because lz4hc is supposed to give "higher-compression" one question I have is: how stable is your format spec? do you see the buffers compressed by your current blosc2 library be still opened/parsed by your future releases (at least with an intent to)? | | ||
Not quite. Blosc2 does not use the multi-threaded version of zstd; it rather implements its own internal multi-threading engine and hence all the codecs (and filters) benefit from it, so no need to trust on a multi-threaded codec for speed. Also, as filters execute prior to codecs, they can reuse the same internal buffers, avoiding copies (which is critical for achieving high I/O performance).
As said, we are not using packed ND array in msgpack, but rather, using our own schema. Blosc2 supports the concept of metalayers for adding new meaning to the stored data (seehttps://www.blosc.org/docs/Caterva-Blosc2-SciPy2019.pdf, slide 17). One of these layers is Caterva, where we have added support forMD arrays <https://github.com/Blosc/caterva/blob/master/CATERVA_METALAYER.rst>. Note that our implementation for supporting ND arrays uses two levels of partitioning (chunks and blocks) for:
1. Allowfiner granularity <https://www.blosc.org/posts/caterva-slicing-perf/>in retrieving data.
2. Better adapt to the memory hierarchies (i.e. main memory and cache levels in CPU)for efficiency <https://www.blosc.org/posts/breaking-memory-walls/>.
OTOH, I have noticed thatyour patch for msgpack <https://github.com/msgpack/msgpack/pull/267/files#diff-bc6661da34ecae62fbe724bb93fd69b91a7f81143f2683a81163231de7e3b545R334>only suggest to use uint32 as the type for array shape. This would prevent to use creating arrays where some dim is larger than 2^32. Is that intended?
see the last part of this post https://github.com/msgpack/msgpack/issues/268#issuecomment-495050845 in BJData, the ND-array dimensional vector supports different integer types <https://github.com/NeuroJSON/bjdata/blob/Draft_2/Binary_JData_Specification....>
I see your point, and your intent is really appreciated. It is just in the 10's GB and up domain that I see BJData a bit lacking in that text handling tools (strings, sed, not to mention editors, where you can run out of memory very soon) can become unnecessarily slow for retrieving the metainfo. We really feel that such metainfo should go either at the beginning or at the end of the frame, where it can be found and processed way more efficiently.
regardless which serialization format is chosen, I think both projects see the needs to store hierarchical metadata along-side with the data. I agree with you that if reading/searching metadata is desired, header&trailer are the best places. For efficient search of metadata while accommodating large amount of binary data in scales, CouchDB/MongoDB use "attachments" to hold large binary data. The metadata tree and the attachment can be linked using a simple UUID or JSON-reference string
OTOH, I agree in that msgpack is not human readable directly, but the format is becoming so ubiquitous that you can find standard tools for introspecting metadata quite easily
it would be nice to store the header data in a map so it can be self-explanatory (with just a small cost of size). I am even willing go as far as adding non-essential metadata that can help make the data file as self-explained as possible, such as spec, schemas and parsers, just because the format can and it costs almost nothing https://github.com/rordenlab/dcm2niix/blob/v1.0.20220720/console/nii_dicom_b...
:
$ msgpack2json -di eye5_blosc2_blosclz.b2frame [ ... ]
And, as there are msgpack libraries for almost all of the currently used languages, I think that formats based on it are as open and transparent as we can get.
again, I applaud the wonderful works from the blosc2 team and have no doubt it has many advantages to offer to sharing array data, on the other side, I do want to advocate for considering readability and portability to the data files. Essentially theNeuroJSON specs <http://neurojson.org/#specs>(JData <https://github.com/NeuroJSON/jdata/blob/Draft_2/JData_specification.md>,BJData <https://github.com/NeuroJSON/bjdata/blob/Draft_2/Binary_JData_Specification....>, etc) are taking the mission of building a "source-code language" for scientific data storage.
Thanks, I concur with your work too! It is always nice to discuss with people that has put a lot of thought in how to pack data efficiently, and as simply as possible (but not any simpler!). Actually, we might be adopting some aspects ofJData <https://github.com/fangq/jdata>to be able to store different objects (arrays, tables, graphs, trees...) in the same frame in a future possible extension of Blosc2. Or, maybe using JData as the external container for existing Blosc2 frames. Very interesting discussion indeed; many possibilities are open now!
will be absolutely happy to explore collaboration possibilities. will reach out offline. Qianqian
Cheers, Francesc
{kind=link}
Hi, On Thu, Sep 1, 2022 at 6:18 AM Qianqian Fang <fangqq@gmail.com> wrote:
On 8/30/22 06:29, Francesc Alted wrote:
Not exactly. What we've done is to encode the header and the trailer (i.e. where the metadata is) of the frame with msgpack. The chunks section <https://github.com/Blosc/c-blosc2/blob/main/README_CFRAME_FORMAT.rst#chunks> is where the actual data is; this section does not follow a msgpack structure as such, but it is rather a sequence of data chunks and an index (for quickly locating the chunks). You can easily access the header or trailer sections reading from the start or the end of the frame. This way you don't need to update the indexes of chunks in msgpack, which can be expensive during data updates.
This indeed prevents data to be dumped by using typical msgpack tools, but our sense is that users should care mostly about metainfo, and let the libraries to deal with the actual data in the most efficient way.
thanks for your detailed reply. I spent the past few days reading the links/documentations, as well as experimenting the blosc2 meta-compressors, I was quite impressed by the performance of blosc2. I was also happy to see great alignments behind the drives for Caterva those of NeuroJSON.
I have a few quick updates
1. I added blosc2 as a codec in my jdata module, as an alternative compressor to zlib/lzma/lz4
https://github.com/NeuroJSON/pyjdata/commit/ce25fa53ce73bf4cbe2cff9799b5a616...
Looks good! Although if you want to support arrays larger than 2 GB, you'd better use a frame (as I was doing in my example; see also https://github.com/Blosc/python-blosc2/blob/082db1d2d2ec9afac653903775e2dcca...). Also, the frame is the one using the msgpack for storing the metainfo.
2. as I mentioned, jdata/bjdata were not optimized for speed, they contain many inefficient handling of numpy arrays (as I discovered); after some profiling, I was able to remove most of those, the run-time is now nearly entirely spent in compression/decompression (see attached profiler outputs for the `zlib` compressor benchmark)
Looks good.
3. the new jdata that supports blosc2, v0.5.0, has been tagged and uploaded (https://pypi.org/project/jdata)
That's great. Although as said, switching from a single chunk into a frame would allow you to store data > 2 GB. Whether or not this a goal for you, I don't know.
4. I wrote a script and compared the run times of various codecs (using BJData and JSON as containers) , the code can be found here
https://github.com/NeuroJSON/pyjdata/blob/master/test/benchcodecs.py
the save/load times tested on a Ryzen 9 3950X/Ubuntu 18.04 box (at various threads) are listed below (similar to your posted before)
*- Testing npy/npz* 'npy', 'save' 0.2914195 'load' 0.1963226 'size' 800000128 'npz', 'save' 2.8617918 'load' 1.9550347 'size' 813846
*- Testing text-based JSON files (.jdt)** (nthread=8)...* 'zlib', 'save' 2.5132861 'load' 1.7221164 'size' 1084942 'lzma', 'save' 9.5481696 'load' 0.3865211 'size' 150738 'lz4', 'save' 0.3467197 'load' 0.5019965 'size' 4495297 'blosc2blosclz'save' 0.0165646 'load' 0.1143934 'size' 1092747 'blosc2lz4', 'save' 0.0175058 'load' 0.1015181 'size' 1090159 'blosc2lz4hc','save' 0.2102167 'load' 0.1053235 'size' 4315421 'blosc2zlib', 'save' 0.1002635 'load' 0.1188845 'size' 1270252 'blosc2zstd', 'save' 0.0463817 'load' 0.1017909 'size' 253176
*- Testing binary JSON (BJData) files (.jdb) (nthread=8)...* 'zlib', 'save' 2.4401443 'load' 1.6316463 'size' 813721 'lzma', 'save' 9.3782029 'load' 0.3728334 'size' 113067 'lz4', 'save' 0.3389360 'load' 0.5017435 'size' 3371487 'blosc2blosclz'save' 0.0173912 'load' 0.1042985 'size' 819576 'blosc2lz4', 'save' 0.0133688 'load' 0.1030941 'size' 817635 'blosc2lz4hc','save' 0.1968047 'load' 0.0950071 'size' 3236580 'blosc2zlib', 'save' 0.1023218 'load' 0.1083922 'size' 952705 'blosc2zstd', 'save' 0.0468430 'load' 0.1019175 'size' 189897
*- Testing binary JSON (BJData) files (.jdb) **(nthread=1)...* 'blosc2blosclz'save' 0.0883078 'load' 0.2432985 'size' 819576 'blosc2lz4', 'save' 0.0867996 'load' 0.2394990 'size' 817635 'blosc2lz4hc','save' 2.4794559 'load' 0.2498981 'size' 3236580 'blosc2zlib', 'save' 0.7477457 'load' 0.4873921 'size' 952705 'blosc2zstd', 'save' 0.3435547 'load' 0.3754863 'size' 189897
*- Testing binary JSON (BJData) files (.jdb) **(nthread=32)...* 'blosc2blosclz'save' 0.0197186 'load' 0.1410989 'size' 819576 'blosc2lz4', 'save' 0.0168068 'load' 0.1414074 'size' 817635 'blosc2lz4hc','save' 0.0790011 'load' 0.0935394 'size' 3236580 'blosc2zlib', 'save' 0.0608818 'load' 0.0985531 'size' 952705 'blosc2zstd', 'save' 0.0370790 'load' 0.0945577 'size' 189897
a few observations:
1. single-threaded zlib/lzma are relatively slow, reflected by npz, zlib and lzma results
2. for simple data structure like this one, using JSON/text-based wrapper vs a binary wrapper has a marginal difference in speed; the only penalty is that text/JSON is ~33% larger than binary in size due to base64
Hmm, base64 almost not adding overhead is quite surprising to me actually, because this is adding at least a copy. What could be happening here is that the compressed size is so small that this doesn't affect performance too much; but in a general case, I'd really expect converting to/from base64 to have a noticeable impact indeed.
3. blosc2 overall delivered very impressive speed - even in single thread, it can be than faster than uncompressed npz or other standard compression methods
4. several blosc2 compressors scaled well with more threads
5. it is a bit strange that blosc2lz4hc yielded larger file size, similar to that from a standard lz4, but blosc2lz4 produces a size comparable to zlib; I expected reverted findings, because lz4hc is supposed to give "higher-compression"
True. The fact is that this is the first time I'm seeing this behavior in lz4hc. The normal situation is more similar to this: https://github.com/Blosc/python-blosc2/blob/main/README.rst#benchmarking. Why lz4hc is not behaving 'well' in terms of compression ratio here escapes to me. Could you come with a small reproducible example and open a ticket in the C-Blosc2 project? We will look into this.
one question I have is: how stable is your format spec? do you see the buffers compressed by your current blosc2 library be still opened/parsed by your future releases (at least with an intent to)?
The Blosc2 format (both chunk <https://github.com/Blosc/c-blosc2/blob/main/README_CHUNK_FORMAT.rst> and frame <https://github.com/Blosc/c-blosc2/blob/main/README_CFRAME_FORMAT.rst>) has been declared stable since May 2021 <https://www.blosc.org/posts/blosc2-ready-general-review/>. You should expect future versions of Blosc2 to be able to read the data stored in that format since then.
Not quite. Blosc2 does not use the multi-threaded version of zstd; it rather implements its own internal multi-threading engine and hence all the codecs (and filters) benefit from it, so no need to trust on a multi-threaded codec for speed. Also, as filters execute prior to codecs, they can reuse the same internal buffers, avoiding copies (which is critical for achieving high I/O performance).
As said, we are not using packed ND array in msgpack, but rather, using our own schema. Blosc2 supports the concept of metalayers for adding new meaning to the stored data (see https://www.blosc.org/docs/Caterva-Blosc2-SciPy2019.pdf, slide 17). One of these layers is Caterva, where we have added support for MD arrays <https://github.com/Blosc/caterva/blob/master/CATERVA_METALAYER.rst>. Note that our implementation for supporting ND arrays uses two levels of partitioning (chunks and blocks) for:
1. Allow finer granularity <https://www.blosc.org/posts/caterva-slicing-perf/> in retrieving data.
2. Better adapt to the memory hierarchies (i.e. main memory and cache levels in CPU) for efficiency <https://www.blosc.org/posts/breaking-memory-walls/>.
OTOH, I have noticed that your patch for msgpack <https://github.com/msgpack/msgpack/pull/267/files#diff-bc6661da34ecae62fbe72...> only suggest to use uint32 as the type for array shape. This would prevent to use creating arrays where some dim is larger than 2^32. Is that intended?
see the last part of this post
https://github.com/msgpack/msgpack/issues/268#issuecomment-495050845
in BJData, the ND-array dimensional vector supports different integer types <https://github.com/NeuroJSON/bjdata/blob/Draft_2/Binary_JData_Specification....>
Ok. A lot of details escaped to me. Thanks.
I see your point, and your intent is really appreciated. It is just in the 10's GB and up domain that I see BJData a bit lacking in that text handling tools (strings, sed, not to mention editors, where you can run out of memory very soon) can become unnecessarily slow for retrieving the metainfo. We really feel that such metainfo should go either at the beginning or at the end of the frame, where it can be found and processed way more efficiently.
regardless which serialization format is chosen, I think both projects see the needs to store hierarchical metadata along-side with the data. I agree with you that if reading/searching metadata is desired, header&trailer are the best places. For efficient search of metadata while accommodating large amount of binary data in scales, CouchDB/MongoDB use "attachments" to hold large binary data. The metadata tree and the attachment can be linked using a simple UUID or JSON-reference string
Yes, using separate storage is fine for not contiguous storage (aka frames), but unfortunately not possible for our case.
OTOH, I agree in that msgpack is not human readable directly, but the format is becoming so ubiquitous that you can find standard tools for introspecting metadata quite easily
it would be nice to store the header data in a map so it can be self-explanatory (with just a small cost of size). I am even willing go as far as adding non-essential metadata that can help make the data file as self-explained as possible, such as spec, schemas and parsers, just because the format can and it costs almost nothing
https://github.com/rordenlab/dcm2niix/blob/v1.0.20220720/console/nii_dicom_b...
Agreed that using maps would add more readability, but they consume also more space. Right now the minimum header size in Blosc2 is around 120 bytes, which, with some metainfo could go around 200 bytes. Having more than that would be an unnecessary waste when you are storing small data or highly compressible data.
:
$ msgpack2json -di eye5_blosc2_blosclz.b2frame [ ... ]
And, as there are msgpack libraries for almost all of the currently used languages, I think that formats based on it are as open and transparent as we can get.
again, I applaud the wonderful works from the blosc2 team and have no doubt it has many advantages to offer to sharing array data, on the other side, I do want to advocate for considering readability and portability to the data files. Essentially the NeuroJSON specs <http://neurojson.org/#specs> (JData <https://github.com/NeuroJSON/jdata/blob/Draft_2/JData_specification.md>, BJData <https://github.com/NeuroJSON/bjdata/blob/Draft_2/Binary_JData_Specification....>, etc) are taking the mission of building a "source-code language" for scientific data storage.
Thanks, I concur with your work too! It is always nice to discuss with people that has put a lot of thought in how to pack data efficiently, and as simply as possible (but not any simpler!). Actually, we might be adopting some aspects of JData <https://github.com/fangq/jdata> to be able to store different objects (arrays, tables, graphs, trees...) in the same frame in a future possible extension of Blosc2. Or, maybe using JData as the external container for existing Blosc2 frames. Very interesting discussion indeed; many possibilities are open now!
will be absolutely happy to explore collaboration possibilities. will reach out offline.
Cool. Let's keep in touch. -- Francesc Alted
participants (5)
-
 Bill Ross
Bill Ross -
 Francesc Alted
Francesc Alted -
 Neal Becker
Neal Becker -
 Qianqian Fang
Qianqian Fang -
 Stephan Hoyer
Stephan Hoyer