Performance benchmarks for 3.9

Hi!
I have updated the branch benchmarks in the pyperformance server and now they include 3.9. There are some benchmarks that are faster but on the other hand some benchmarks are substantially slower, pointing at a possible performance regression in 3.9 in some aspects. In particular some tests like "unpack sequence" are almost 20% slower. As there are some other tests were 3.9 is faster, is not fair to conclude that 3.9 is slower, but this is something we should look into in my opinion.
You can check these benchmarks I am talking about by:
- Go here: https://speed.python.org/comparison/
- In the left bar, select "lto-pgo latest in branch '3.9'" and "lto-pgo latest in branch '3.8'"
- To better read the plot, I would recommend to select a "Normalization" to the 3.8 branch (this is in the top part of the page) and to check the "horizontal" checkbox.
These benchmarks are very stable: I have executed them several times over the weekend yielding the same results and, more importantly, they are being executed on a server specially prepared to running reproducible benchmarks: CPU affinity, CPU isolation, CPU pinning for NUMA nodes, CPU frequency is fixed, CPU governor set to performance mode, IRQ affinity is disabled for the benchmarking CPU nodes...etc so you can trust these numbers.
I kindly suggest for everyone interested in trying to improve the 3.9 (and master) performance, to review these benchmarks and try to identify the problems and fix them or to find what changes introduced the regressions in the first place. All benchmarks are the ones being executed by the pyperformance suite ( https://github.com/python/pyperformance) so you can execute them locally if you need to.
On a related note, I am also working on the speed.python.org server to provide more automation and ideally some integrations with GitHub to detect performance regressions. For now, I have done the following:
- Recompute benchmarks for all branches using the same version of pyperformance (except master) so they can be compared with each other. This can only be seen in the "Comparison" tab: https://speed.python.org/comparison/
- I am setting daily builds of the master branch so we can detect performance regressions with daily granularity. These daily builds will be located in the "Changes" and "Timeline" tabs ( https://speed.python.org/timeline/).
- Once the daily builds are working as expected, I plan to work on trying to automatically comment or PRs or on bpo if we detect that a commit has introduced some notable performance regression.
Regards from sunny London, Pablo Galindo Salgado.

The performance figures in the Python 3.9 "What's New" (here - https://docs.python.org/3/whatsnew/3.9.html#optimizations) did look oddly like a lot of things went slower, to me. I assumed I'd misread the figures, and moved on, but maybe I was wrong to do so...
Paul
On Wed, 14 Oct 2020 at 14:17, Pablo Galindo Salgado <pablogsal@gmail.com> wrote:
Hi!
I have updated the branch benchmarks in the pyperformance server and now they include 3.9. There are some benchmarks that are faster but on the other hand some benchmarks are substantially slower, pointing at a possible performance regression in 3.9 in some aspects. In particular some tests like "unpack sequence" are almost 20% slower. As there are some other tests were 3.9 is faster, is not fair to conclude that 3.9 is slower, but this is something we should look into in my opinion.
You can check these benchmarks I am talking about by:
- Go here: https://speed.python.org/comparison/
- In the left bar, select "lto-pgo latest in branch '3.9'" and "lto-pgo latest in branch '3.8'"
- To better read the plot, I would recommend to select a "Normalization" to the 3.8 branch (this is in the top part of the page) and to check the "horizontal" checkbox.
These benchmarks are very stable: I have executed them several times over the weekend yielding the same results and, more importantly, they are being executed on a server specially prepared to running reproducible benchmarks: CPU affinity, CPU isolation, CPU pinning for NUMA nodes, CPU frequency is fixed, CPU governor set to performance mode, IRQ affinity is disabled for the benchmarking CPU nodes...etc so you can trust these numbers.
I kindly suggest for everyone interested in trying to improve the 3.9 (and master) performance, to review these benchmarks and try to identify the problems and fix them or to find what changes introduced the regressions in the first place. All benchmarks are the ones being executed by the pyperformance suite (https://github.com/python/pyperformance) so you can execute them locally if you need to.
On a related note, I am also working on the speed.python.org server to provide more automation and ideally some integrations with GitHub to detect performance regressions. For now, I have done the following:
- Recompute benchmarks for all branches using the same version of pyperformance (except master) so they can be compared with each other. This can only be seen in the "Comparison" tab: https://speed.python.org/comparison/
- I am setting daily builds of the master branch so we can detect performance regressions with daily granularity. These daily builds will be located in the "Changes" and "Timeline" tabs (https://speed.python.org/timeline/).
- Once the daily builds are working as expected, I plan to work on trying to automatically comment or PRs or on bpo if we detect that a commit has introduced some notable performance regression.
Regards from sunny London, Pablo Galindo Salgado.
python-committers mailing list -- python-committers@python.org To unsubscribe send an email to python-committers-leave@python.org https://mail.python.org/mailman3/lists/python-committers.python.org/ Message archived at https://mail.python.org/archives/list/python-committers@python.org/message/G... Code of Conduct: https://www.python.org/psf/codeofconduct/
The performance figures in the Python 3.9 "What's New"
Those are also micro-benchmarks, which can have no effect at all on macro-benchmarks. The ones I am linking are almost all macro-benchmarks, so, unfortunately, the ones in Python 3.9 "What's New" are not lying and they seem to be correlated to the same issue.
Also although they are not incorrect, those benchmarks in the Python 3.9 "What's New" were not executed with LTO/PGO/CPU isolation...etc so I would kindly suggest taking the ones in the speed.python.org as the canonical ones if they start to differ in any way.
Pablo
On Wed, 14 Oct 2020 at 14:25, Paul Moore <p.f.moore@gmail.com> wrote:
The performance figures in the Python 3.9 "What's New" (here - https://docs.python.org/3/whatsnew/3.9.html#optimizations) did look oddly like a lot of things went slower, to me. I assumed I'd misread the figures, and moved on, but maybe I was wrong to do so...
Paul
On Wed, 14 Oct 2020 at 14:17, Pablo Galindo Salgado <pablogsal@gmail.com> wrote:
Hi!
I have updated the branch benchmarks in the pyperformance server and now
some benchmarks that are faster but on the other hand some benchmarks are substantially slower, pointing at a possible performance regression in 3.9 in some aspects. In
almost 20% slower. As there are some other tests were 3.9 is faster, is not fair to conclude that 3.9 is slower, but this is something we should look into in my opinion.
You can check these benchmarks I am talking about by:
- Go here: https://speed.python.org/comparison/
- In the left bar, select "lto-pgo latest in branch '3.9'" and "lto-pgo latest in branch '3.8'"
- To better read the plot, I would recommend to select a "Normalization" to the 3.8 branch (this is in the top part of the page) and to check the "horizontal" checkbox.
These benchmarks are very stable: I have executed them several times over the weekend yielding the same results and, more importantly, they are being executed on a server specially prepared to running reproducible benchmarks: CPU affinity, CPU isolation, CPU pinning for NUMA nodes, CPU frequency is fixed, CPU governor set to performance mode, IRQ affinity is disabled for the benchmarking CPU nodes...etc so you can trust these numbers.
I kindly suggest for everyone interested in trying to improve the 3.9 (and master) performance, to review these benchmarks and try to identify the problems and fix them or to find what changes introduced the regressions in the first place. All benchmarks are the ones being executed by the pyperformance suite ( https://github.com/python/pyperformance) so you can execute them locally if you need to.
On a related note, I am also working on the speed.python.org server to
ideally some integrations with GitHub to detect performance regressions. For now, I have done the following:
- Recompute benchmarks for all branches using the same version of
be compared with each other. This can only be seen in the "Comparison" tab: https://speed.python.org/comparison/
- I am setting daily builds of the master branch so we can detect
daily builds will be located in the "Changes" and "Timeline" tabs ( https://speed.python.org/timeline/).
- Once the daily builds are working as expected, I plan to work on
they include 3.9. There are particular some tests like "unpack sequence" are provide more automation and pyperformance (except master) so they can performance regressions with daily granularity. These trying to automatically comment or PRs or on bpo if
we detect that a commit has introduced some notable performance regression.
Regards from sunny London, Pablo Galindo Salgado.
python-committers mailing list -- python-committers@python.org To unsubscribe send an email to python-committers-leave@python.org https://mail.python.org/mailman3/lists/python-committers.python.org/ Message archived at https://mail.python.org/archives/list/python-committers@python.org/message/G... Code of Conduct: https://www.python.org/psf/codeofconduct/

Hi Pablo,
thanks for pointing this out.
Would it be possible to get the data for older runs back, so that it's easier to find the changes which caused the slowdown ?
Going to the timeline, it seems that the system only has data for Oct 14 (today):
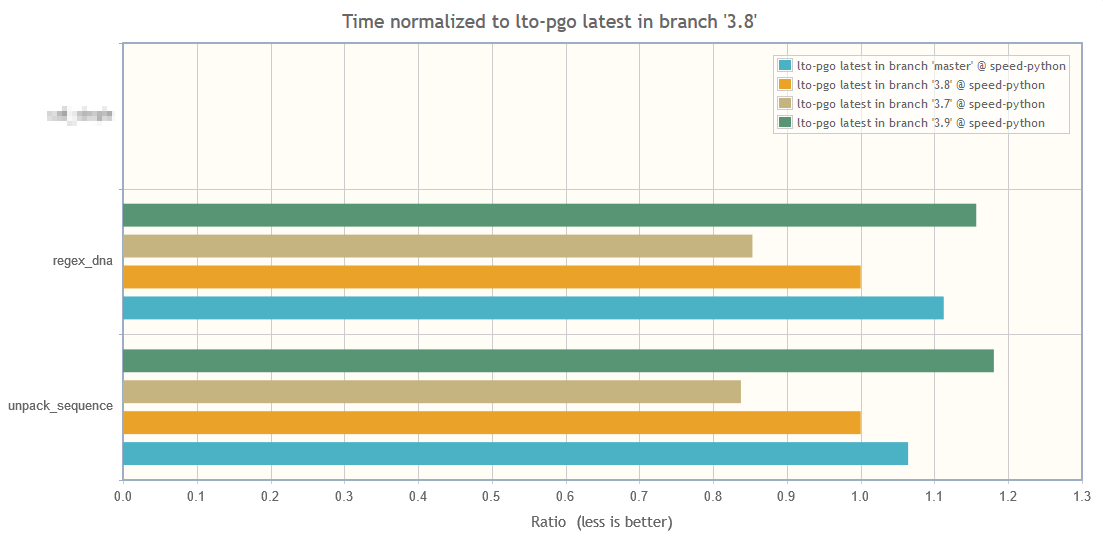
In addition to unpack_sequence, the regex_dna test has slowed down a lot compared to Py3.8.
https://github.com/python/pyperformance/blob/master/pyperformance/benchmarks... https://github.com/python/pyperformance/blob/master/pyperformance/benchmarks...
Thanks.
On 14.10.2020 15:16, Pablo Galindo Salgado wrote:
Hi!
I have updated the branch benchmarks in the pyperformance server and now they include 3.9. There are some benchmarks that are faster but on the other hand some benchmarks are substantially slower, pointing at a possible performance regression in 3.9 in some aspects. In particular some tests like "unpack sequence" are almost 20% slower. As there are some other tests were 3.9 is faster, is not fair to conclude that 3.9 is slower, but this is something we should look into in my opinion.
You can check these benchmarks I am talking about by:
- Go here: https://speed.python.org/comparison/
- In the left bar, select "lto-pgo latest in branch '3.9'" and "lto-pgo latest in branch '3.8'"
- To better read the plot, I would recommend to select a "Normalization" to the 3.8 branch (this is in the top part of the page) and to check the "horizontal" checkbox.
These benchmarks are very stable: I have executed them several times over the weekend yielding the same results and, more importantly, they are being executed on a server specially prepared to running reproducible benchmarks: CPU affinity, CPU isolation, CPU pinning for NUMA nodes, CPU frequency is fixed, CPU governor set to performance mode, IRQ affinity is disabled for the benchmarking CPU nodes...etc so you can trust these numbers.
I kindly suggest for everyone interested in trying to improve the 3.9 (and master) performance, to review these benchmarks and try to identify the problems and fix them or to find what changes introduced the regressions in the first place. All benchmarks are the ones being executed by the pyperformance suite (https://github.com/python/pyperformance) so you can execute them locally if you need to.
On a related note, I am also working on the speed.python.org <http://speed.python.org> server to provide more automation and ideally some integrations with GitHub to detect performance regressions. For now, I have done the following:
- Recompute benchmarks for all branches using the same version of pyperformance (except master) so they can be compared with each other. This can only be seen in the "Comparison" tab: https://speed.python.org/comparison/
- I am setting daily builds of the master branch so we can detect performance regressions with daily granularity. These daily builds will be located in the "Changes" and "Timeline" tabs (https://speed.python.org/timeline/).
- Once the daily builds are working as expected, I plan to work on trying to automatically comment or PRs or on bpo if we detect that a commit has introduced some notable performance regression.
Regards from sunny London, Pablo Galindo Salgado.
python-committers mailing list -- python-committers@python.org To unsubscribe send an email to python-committers-leave@python.org https://mail.python.org/mailman3/lists/python-committers.python.org/ Message archived at https://mail.python.org/archives/list/python-committers@python.org/message/G... Code of Conduct: https://www.python.org/psf/codeofconduct/
-- Marc-Andre Lemburg eGenix.com
Professional Python Services directly from the Experts (#1, Oct 14 2020)
Python Projects, Coaching and Support ... https://www.egenix.com/ Python Product Development ... https://consulting.egenix.com/
::: We implement business ideas - efficiently in both time and costs :::
eGenix.com Software, Skills and Services GmbH Pastor-Loeh-Str.48 D-40764 Langenfeld, Germany. CEO Dipl.-Math. Marc-Andre Lemburg Registered at Amtsgericht Duesseldorf: HRB 46611 https://www.egenix.com/company/contact/ https://www.malemburg.com/
Would it be possible to get the data for older runs back, so that it's easier to find the changes which caused the slowdown ?
Unfortunately no. The reasons are that that data was misleading because different points were computed with a different version of pyperformance and therefore with different packages (and therefore different code). So the points could not be compared among themselves.
Also, past data didn't include 3.9 commits because the data gathering was not automated and it didn't run in a long time :(
On Wed, 14 Oct 2020 at 14:57, M.-A. Lemburg <mal@egenix.com> wrote:
Hi Pablo,
thanks for pointing this out.
Would it be possible to get the data for older runs back, so that it's easier to find the changes which caused the slowdown ?
Going to the timeline, it seems that the system only has data for Oct 14 (today):
In addition to unpack_sequence, the regex_dna test has slowed down a lot compared to Py3.8.
https://github.com/python/pyperformance/blob/master/pyperformance/benchmarks...
https://github.com/python/pyperformance/blob/master/pyperformance/benchmarks...
Thanks.
Hi!
I have updated the branch benchmarks in the pyperformance server and now
include 3.9. There are some benchmarks that are faster but on the other hand some benchmarks are substantially slower, pointing at a possible performance regression in 3.9 in some aspects. In
tests like "unpack sequence" are almost 20% slower. As there are some other tests were 3.9 is faster, is not fair to conclude that 3.9 is slower, but this is something we should look into in my opinion.
You can check these benchmarks I am talking about by:
- Go here: https://speed.python.org/comparison/
- In the left bar, select "lto-pgo latest in branch '3.9'" and "lto-pgo latest in branch '3.8'"
- To better read the plot, I would recommend to select a "Normalization" to the 3.8 branch (this is in the top part of the page) and to check the "horizontal" checkbox.
These benchmarks are very stable: I have executed them several times over the weekend yielding the same results and, more importantly, they are being executed on a server specially prepared to running reproducible benchmarks: CPU affinity, CPU isolation, CPU pinning for NUMA nodes, CPU frequency is fixed, CPU governor set to performance mode, IRQ affinity is disabled for the benchmarking CPU nodes...etc so you can trust these numbers.
I kindly suggest for everyone interested in trying to improve the 3.9 (and master) performance, to review these benchmarks and try to identify the problems and fix them or to find what changes introduced the regressions in the first place. All benchmarks are the ones being executed by the pyperformance suite (https://github.com/python/pyperformance) so you can execute them locally if you need to.
On a related note, I am also working on the speed.python.org <http://speed.python.org> server to provide more automation and ideally some integrations with GitHub to detect performance regressions. For now, I have done the following:
- Recompute benchmarks for all branches using the same version of pyperformance (except master) so they can be compared with each other. This can only be seen in the "Comparison" tab: https://speed.python.org/comparison/
- I am setting daily builds of the master branch so we can detect
regressions with daily granularity. These daily builds will be located in the "Changes" and "Timeline" tabs (https://speed.python.org/timeline/).
- Once the daily builds are working as expected, I plan to work on
On 14.10.2020 15:16, Pablo Galindo Salgado wrote: they particular some performance trying to
automatically comment or PRs or on bpo if we detect that a commit has introduced some notable performance regression.
Regards from sunny London, Pablo Galindo Salgado.
python-committers mailing list -- python-committers@python.org To unsubscribe send an email to python-committers-leave@python.org https://mail.python.org/mailman3/lists/python-committers.python.org/ Message archived at https://mail.python.org/archives/list/python-committers@python.org/message/G... Code of Conduct: https://www.python.org/psf/codeofconduct/
-- Marc-Andre Lemburg eGenix.com
Professional Python Services directly from the Experts (#1, Oct 14 2020)
Python Projects, Coaching and Support ... https://www.egenix.com/ Python Product Development ... https://consulting.egenix.com/
::: We implement business ideas - efficiently in both time and costs :::
eGenix.com Software, Skills and Services GmbH Pastor-Loeh-Str.48 D-40764 Langenfeld, Germany. CEO Dipl.-Math. Marc-Andre Lemburg Registered at Amtsgericht Duesseldorf: HRB 46611 https://www.egenix.com/company/contact/ https://www.malemburg.com/
On 14.10.2020 16:00, Pablo Galindo Salgado wrote:
Would it be possible to get the data for older runs back, so that it's easier to find the changes which caused the slowdown ?
Unfortunately no. The reasons are that that data was misleading because different points were computed with a different version of pyperformance and therefore with different packages (and therefore different code). So the points could not be compared among themselves.
Also, past data didn't include 3.9 commits because the data gathering was not automated and it didn't run in a long time :(
Make sense.
Would it be possible rerun the tests with the current setup for say the last 1000 revisions or perhaps a subset of these (e.g. every 10th revision) to try to binary search for the revision which introduced the change ?
On Wed, 14 Oct 2020 at 14:57, M.-A. Lemburg <mal@egenix.com <mailto:mal@egenix.com>> wrote:
Hi Pablo, thanks for pointing this out. Would it be possible to get the data for older runs back, so that it's easier to find the changes which caused the slowdown ? Going to the timeline, it seems that the system only has data for Oct 14 (today): https://speed.python.org/timeline/#/?exe=12&ben=regex_dna&env=1&revs=1000&equid=off&quarts=on&extr=on&base=none In addition to unpack_sequence, the regex_dna test has slowed down a lot compared to Py3.8. https://github.com/python/pyperformance/blob/master/pyperformance/benchmarks/bm_unpack_sequence.py https://github.com/python/pyperformance/blob/master/pyperformance/benchmarks/bm_regex_dna.py Thanks. On 14.10.2020 15:16, Pablo Galindo Salgado wrote: > Hi! > > I have updated the branch benchmarks in the pyperformance server and now they > include 3.9. There are > some benchmarks that are faster but on the other hand some benchmarks are > substantially slower, pointing > at a possible performance regression in 3.9 in some aspects. In particular some > tests like "unpack sequence" are > almost 20% slower. As there are some other tests were 3.9 is faster, is not fair > to conclude that 3.9 is slower, but > this is something we should look into in my opinion. > > You can check these benchmarks I am talking about by: > > * Go here: https://speed.python.org/comparison/ > * In the left bar, select "lto-pgo latest in branch '3.9'" and "lto-pgo latest > in branch '3.8'" > * To better read the plot, I would recommend to select a "Normalization" to the > 3.8 branch (this is in the top part of the page) > and to check the "horizontal" checkbox. > > These benchmarks are very stable: I have executed them several times over the > weekend yielding the same results and, > more importantly, they are being executed on a server specially prepared to > running reproducible benchmarks: CPU affinity, > CPU isolation, CPU pinning for NUMA nodes, CPU frequency is fixed, CPU governor > set to performance mode, IRQ affinity is > disabled for the benchmarking CPU nodes...etc so you can trust these numbers. > > I kindly suggest for everyone interested in trying to improve the 3.9 (and > master) performance, to review these benchmarks > and try to identify the problems and fix them or to find what changes introduced > the regressions in the first place. All benchmarks > are the ones being executed by the pyperformance suite > (https://github.com/python/pyperformance) so you can execute them > locally if you need to. > > --- > > On a related note, I am also working on the speed.python.org <http://speed.python.org> > <http://speed.python.org> server to provide more automation and > ideally some integrations with GitHub to detect performance regressions. For > now, I have done the following: > > * Recompute benchmarks for all branches using the same version of > pyperformance (except master) so they can > be compared with each other. This can only be seen in the "Comparison" > tab: https://speed.python.org/comparison/ > * I am setting daily builds of the master branch so we can detect performance > regressions with daily granularity. These > daily builds will be located in the "Changes" and "Timeline" tabs > (https://speed.python.org/timeline/). > * Once the daily builds are working as expected, I plan to work on trying to > automatically comment or PRs or on bpo if > we detect that a commit has introduced some notable performance regression. > > Regards from sunny London, > Pablo Galindo Salgado. > > _______________________________________________ > python-committers mailing list -- python-committers@python.org <mailto:python-committers@python.org> > To unsubscribe send an email to python-committers-leave@python.org <mailto:python-committers-leave@python.org> > https://mail.python.org/mailman3/lists/python-committers.python.org/ > Message archived at https://mail.python.org/archives/list/python-committers@python.org/message/G3LB4BCAY7T7WG22YQJNQ64XA4BXBCT4/ > Code of Conduct: https://www.python.org/psf/codeofconduct/ > -- Marc-Andre Lemburg eGenix.com Professional Python Services directly from the Experts (#1, Oct 14 2020) >>> Python Projects, Coaching and Support ... https://www.egenix.com/ >>> Python Product Development ... https://consulting.egenix.com/ ________________________________________________________________________ ::: We implement business ideas - efficiently in both time and costs ::: eGenix.com Software, Skills and Services GmbH Pastor-Loeh-Str.48 D-40764 Langenfeld, Germany. CEO Dipl.-Math. Marc-Andre Lemburg Registered at Amtsgericht Duesseldorf: HRB 46611 https://www.egenix.com/company/contact/ https://www.malemburg.com/
-- Marc-Andre Lemburg eGenix.com
Professional Python Services directly from the Experts (#1, Oct 14 2020)
Python Projects, Coaching and Support ... https://www.egenix.com/ Python Product Development ... https://consulting.egenix.com/
::: We implement business ideas - efficiently in both time and costs :::
eGenix.com Software, Skills and Services GmbH Pastor-Loeh-Str.48 D-40764 Langenfeld, Germany. CEO Dipl.-Math. Marc-Andre Lemburg Registered at Amtsgericht Duesseldorf: HRB 46611 https://www.egenix.com/company/contact/ https://www.malemburg.com/
Would it be possible rerun the tests with the current setup for say the last 1000 revisions or perhaps a subset of these (e.g. every 10th revision) to try to binary search for the revision which introduced the change ?
Every run takes 1-2 h so doing 1000 would be certainly time-consuming :)
That's why from now on I am trying to invest in daily builds for master, so we can answer that exact question if we detect regressions in the future.
On Wed, 14 Oct 2020 at 15:04, M.-A. Lemburg <mal@egenix.com> wrote:
Would it be possible to get the data for older runs back, so that it's easier to find the changes which caused the slowdown ?
Unfortunately no. The reasons are that that data was misleading because different points were computed with a different version of pyperformance and therefore with different packages (and therefore different code). So the
On 14.10.2020 16:00, Pablo Galindo Salgado wrote: points
could not be compared among themselves.
Also, past data didn't include 3.9 commits because the data gathering was not automated and it didn't run in a long time :(
Make sense.
Would it be possible rerun the tests with the current setup for say the last 1000 revisions or perhaps a subset of these (e.g. every 10th revision) to try to binary search for the revision which introduced the change ?
On Wed, 14 Oct 2020 at 14:57, M.-A. Lemburg <mal@egenix.com <mailto:mal@egenix.com>> wrote:
Hi Pablo, thanks for pointing this out. Would it be possible to get the data for older runs back, so that it's easier to find the changes which caused the slowdown ? Going to the timeline, it seems that the system only has data for Oct 14 (today):In addition to unpack_sequence, the regex_dna test has slowed down a lot compared to Py3.8.https://github.com/python/pyperformance/blob/master/pyperformance/benchmarks...
https://github.com/python/pyperformance/blob/master/pyperformance/benchmarks...
Thanks. On 14.10.2020 15:16, Pablo Galindo Salgado wrote: > Hi! > > I have updated the branch benchmarks in the pyperformance serverand now they
> include 3.9. There are > some benchmarks that are faster but on the other hand somebenchmarks are
> substantially slower, pointing > at a possible performance regression in 3.9 in some aspects. Inparticular
some > tests like "unpack sequence" are > almost 20% slower. As there are some other tests were 3.9 isfaster, is
not fair > to conclude that 3.9 is slower, but > this is something we should look into in my opinion. > > You can check these benchmarks I am talking about by: > > * Go here: https://speed.python.org/comparison/ > * In the left bar, select "lto-pgo latest in branch '3.9'" and"lto-pgo latest
> in branch '3.8'" > * To better read the plot, I would recommend to select a"Normalization"
to the > 3.8 branch (this is in the top part of the page) > and to check the "horizontal" checkbox. > > These benchmarks are very stable: I have executed them severaltimes over the
> weekend yielding the same results and, > more importantly, they are being executed on a server speciallyprepared to
> running reproducible benchmarks: CPU affinity, > CPU isolation, CPU pinning for NUMA nodes, CPU frequency is fixed,CPU
governor > set to performance mode, IRQ affinity is > disabled for the benchmarking CPU nodes...etc so you can trustthese numbers.
> > I kindly suggest for everyone interested in trying to improve the3.9 (and
> master) performance, to review these benchmarks > and try to identify the problems and fix them or to find whatchanges
introduced > the regressions in the first place. All benchmarks > are the ones being executed by the pyperformance suite > (https://github.com/python/pyperformance) so you can execute them > locally if you need to. > > --- > > On a related note, I am also working on the speed.python.org <http://speed.python.org> > <http://speed.python.org> server to provide more automation and > ideally some integrations with GitHub to detect performanceregressions. For
> now, I have done the following: > > * Recompute benchmarks for all branches using the same version of > pyperformance (except master) so they can > be compared with each other. This can only be seen in the"Comparison"
> tab: https://speed.python.org/comparison/ > * I am setting daily builds of the master branch so we can detectperformance
> regressions with daily granularity. These > daily builds will be located in the "Changes" and "Timeline"tabs
> (https://speed.python.org/timeline/). > * Once the daily builds are working as expected, I plan to work ontrying to
> automatically comment or PRs or on bpo if > we detect that a commit has introduced some notable performanceregression.
> > Regards from sunny London, > Pablo Galindo Salgado. > > _______________________________________________ > python-committers mailing list -- python-committers@python.org <mailto:python-committers@python.org> > To unsubscribe send an email to python-committers-leave@python.org <mailto:python-committers-leave@python.org> >https://mail.python.org/mailman3/lists/python-committers.python.org/
> Message archived athttps://mail.python.org/archives/list/python-committers@python.org/message/G...
> Code of Conduct: https://www.python.org/psf/codeofconduct/ > -- Marc-Andre Lemburg eGenix.com Professional Python Services directly from the Experts (#1, Oct 14
>>> Python Projects, Coaching and Support ...>>> Python Product Development ...https://consulting.egenix.com/
::: We implement business ideas - efficiently in both time and costs:::
eGenix.com Software, Skills and Services GmbH Pastor-Loeh-Str.48 D-40764 Langenfeld, Germany. CEO Dipl.-Math. Marc-Andre Lemburg Registered at Amtsgericht Duesseldorf: HRB 46611 https://www.egenix.com/company/contact/ https://www.malemburg.com/-- Marc-Andre Lemburg eGenix.com
Professional Python Services directly from the Experts (#1, Oct 14 2020)
Python Projects, Coaching and Support ... https://www.egenix.com/ Python Product Development ... https://consulting.egenix.com/
::: We implement business ideas - efficiently in both time and costs :::
eGenix.com Software, Skills and Services GmbH Pastor-Loeh-Str.48 D-40764 Langenfeld, Germany. CEO Dipl.-Math. Marc-Andre Lemburg Registered at Amtsgericht Duesseldorf: HRB 46611 https://www.egenix.com/company/contact/ https://www.malemburg.com/

I suggest to limit to one "dot" per week, since CodeSpeed (the website to browse the benchmark results) is somehow limited to 50 dots (it can display more if you only display a single benchmark).
Previously, it was closer to one "dot" per month which allowed to display a timeline over 5 years. In my experience, significant performance changes are rare and only happen once every 3 months. So a granularity of 1 day is not needed.
We may consider to use the tool "asv" which has a nice web UI to browse results. It also provides a tool to automatically run a bisect to identify which commit introduced a speedup or slowdown.
Last time I checked, asv has a simpler way to run benchmarks than pyperf. It doesn't spawn multiple processes for example. I don't know if it would be possible to plug pyperf into asv.
Victor
Le mer. 14 oct. 2020 à 17:03, Pablo Galindo Salgado <pablogsal@gmail.com> a écrit :
Would it be possible rerun the tests with the current setup for say the last 1000 revisions or perhaps a subset of these (e.g. every 10th revision) to try to binary search for the revision which introduced the change ?
Every run takes 1-2 h so doing 1000 would be certainly time-consuming :)
That's why from now on I am trying to invest in daily builds for master, so we can answer that exact question if we detect regressions in the future.
On Wed, 14 Oct 2020 at 15:04, M.-A. Lemburg <mal@egenix.com> wrote:
On 14.10.2020 16:00, Pablo Galindo Salgado wrote:
Would it be possible to get the data for older runs back, so that it's easier to find the changes which caused the slowdown ?
Unfortunately no. The reasons are that that data was misleading because different points were computed with a different version of pyperformance and therefore with different packages (and therefore different code). So the points could not be compared among themselves.
Also, past data didn't include 3.9 commits because the data gathering was not automated and it didn't run in a long time :(
Make sense.
Would it be possible rerun the tests with the current setup for say the last 1000 revisions or perhaps a subset of these (e.g. every 10th revision) to try to binary search for the revision which introduced the change ?
On Wed, 14 Oct 2020 at 14:57, M.-A. Lemburg <mal@egenix.com <mailto:mal@egenix.com>> wrote:
Hi Pablo, thanks for pointing this out. Would it be possible to get the data for older runs back, so that it's easier to find the changes which caused the slowdown ? Going to the timeline, it seems that the system only has data for Oct 14 (today): https://speed.python.org/timeline/#/?exe=12&ben=regex_dna&env=1&revs=1000&equid=off&quarts=on&extr=on&base=none In addition to unpack_sequence, the regex_dna test has slowed down a lot compared to Py3.8. https://github.com/python/pyperformance/blob/master/pyperformance/benchmarks/bm_unpack_sequence.py https://github.com/python/pyperformance/blob/master/pyperformance/benchmarks/bm_regex_dna.py Thanks. On 14.10.2020 15:16, Pablo Galindo Salgado wrote: > Hi! > > I have updated the branch benchmarks in the pyperformance server and now they > include 3.9. There are > some benchmarks that are faster but on the other hand some benchmarks are > substantially slower, pointing > at a possible performance regression in 3.9 in some aspects. In particular some > tests like "unpack sequence" are > almost 20% slower. As there are some other tests were 3.9 is faster, is not fair > to conclude that 3.9 is slower, but > this is something we should look into in my opinion. > > You can check these benchmarks I am talking about by: > > * Go here: https://speed.python.org/comparison/ > * In the left bar, select "lto-pgo latest in branch '3.9'" and "lto-pgo latest > in branch '3.8'" > * To better read the plot, I would recommend to select a "Normalization" to the > 3.8 branch (this is in the top part of the page) > and to check the "horizontal" checkbox. > > These benchmarks are very stable: I have executed them several times over the > weekend yielding the same results and, > more importantly, they are being executed on a server specially prepared to > running reproducible benchmarks: CPU affinity, > CPU isolation, CPU pinning for NUMA nodes, CPU frequency is fixed, CPU governor > set to performance mode, IRQ affinity is > disabled for the benchmarking CPU nodes...etc so you can trust these numbers. > > I kindly suggest for everyone interested in trying to improve the 3.9 (and > master) performance, to review these benchmarks > and try to identify the problems and fix them or to find what changes introduced > the regressions in the first place. All benchmarks > are the ones being executed by the pyperformance suite > (https://github.com/python/pyperformance) so you can execute them > locally if you need to. > > --- > > On a related note, I am also working on the speed.python.org <http://speed.python.org> > <http://speed.python.org> server to provide more automation and > ideally some integrations with GitHub to detect performance regressions. For > now, I have done the following: > > * Recompute benchmarks for all branches using the same version of > pyperformance (except master) so they can > be compared with each other. This can only be seen in the "Comparison" > tab: https://speed.python.org/comparison/ > * I am setting daily builds of the master branch so we can detect performance > regressions with daily granularity. These > daily builds will be located in the "Changes" and "Timeline" tabs > (https://speed.python.org/timeline/). > * Once the daily builds are working as expected, I plan to work on trying to > automatically comment or PRs or on bpo if > we detect that a commit has introduced some notable performance regression. > > Regards from sunny London, > Pablo Galindo Salgado. > > _______________________________________________ > python-committers mailing list -- python-committers@python.org <mailto:python-committers@python.org> > To unsubscribe send an email to python-committers-leave@python.org <mailto:python-committers-leave@python.org> > https://mail.python.org/mailman3/lists/python-committers.python.org/ > Message archived at https://mail.python.org/archives/list/python-committers@python.org/message/G3LB4BCAY7T7WG22YQJNQ64XA4BXBCT4/ > Code of Conduct: https://www.python.org/psf/codeofconduct/ > -- Marc-Andre Lemburg eGenix.com Professional Python Services directly from the Experts (#1, Oct 14 2020) >>> Python Projects, Coaching and Support ... https://www.egenix.com/ >>> Python Product Development ... https://consulting.egenix.com/ ________________________________________________________________________ ::: We implement business ideas - efficiently in both time and costs ::: eGenix.com Software, Skills and Services GmbH Pastor-Loeh-Str.48 D-40764 Langenfeld, Germany. CEO Dipl.-Math. Marc-Andre Lemburg Registered at Amtsgericht Duesseldorf: HRB 46611 https://www.egenix.com/company/contact/ https://www.malemburg.com/-- Marc-Andre Lemburg eGenix.com
Professional Python Services directly from the Experts (#1, Oct 14 2020)
Python Projects, Coaching and Support ... https://www.egenix.com/ Python Product Development ... https://consulting.egenix.com/
::: We implement business ideas - efficiently in both time and costs :::
eGenix.com Software, Skills and Services GmbH Pastor-Loeh-Str.48 D-40764 Langenfeld, Germany. CEO Dipl.-Math. Marc-Andre Lemburg Registered at Amtsgericht Duesseldorf: HRB 46611 https://www.egenix.com/company/contact/ https://www.malemburg.com/
python-committers mailing list -- python-committers@python.org To unsubscribe send an email to python-committers-leave@python.org https://mail.python.org/mailman3/lists/python-committers.python.org/ Message archived at https://mail.python.org/archives/list/python-committers@python.org/message/L... Code of Conduct: https://www.python.org/psf/codeofconduct/
-- Night gathers, and now my watch begins. It shall not end until my death.

MOn Wed, Oct 14, 2020 at 8:03 AM Pablo Galindo Salgado <pablogsal@gmail.com> wrote:
Would it be possible rerun the tests with the current setup for say the last 1000 revisions or perhaps a subset of these (e.g. every 10th revision) to try to binary search for the revision which introduced the change ?
Every run takes 1-2 h so doing 1000 would be certainly time-consuming :)
Would it be possible instead to run git-bisect for only a _particular_ benchmark? It seems that may be all that’s needed to track down particular regressions. Also, if e.g. git-bisect is used it wouldn’t be every e.g. 10th revision but rather O(log(n)) revisions.
—Chris
That's why from now on I am trying to invest in daily builds for master,
so we can answer that exact question if we detect regressions in the future.
On Wed, 14 Oct 2020 at 15:04, M.-A. Lemburg <mal@egenix.com> wrote:
Would it be possible to get the data for older runs back, so that it's easier to find the changes which caused the slowdown ?
Unfortunately no. The reasons are that that data was misleading because different points were computed with a different version of
therefore with different packages (and therefore different code). So
On 14.10.2020 16:00, Pablo Galindo Salgado wrote: pyperformance and the points
could not be compared among themselves.
Also, past data didn't include 3.9 commits because the data gathering was not automated and it didn't run in a long time :(
Make sense.
Would it be possible rerun the tests with the current setup for say the last 1000 revisions or perhaps a subset of these (e.g. every 10th revision) to try to binary search for the revision which introduced the change ?
On Wed, 14 Oct 2020 at 14:57, M.-A. Lemburg <mal@egenix.com <mailto:mal@egenix.com>> wrote:
Hi Pablo, thanks for pointing this out. Would it be possible to get the data for older runs back, so that it's easier to find the changes which caused the slowdown ? Going to the timeline, it seems that the system only has data for Oct 14 (today):In addition to unpack_sequence, the regex_dna test has slowed down a lot compared to Py3.8.https://github.com/python/pyperformance/blob/master/pyperformance/benchmarks...
https://github.com/python/pyperformance/blob/master/pyperformance/benchmarks...
Thanks. On 14.10.2020 15:16, Pablo Galindo Salgado wrote: > Hi! > > I have updated the branch benchmarks in the pyperformance serverand now they
> include 3.9. There are > some benchmarks that are faster but on the other hand somebenchmarks are
> substantially slower, pointing > at a possible performance regression in 3.9 in some aspects. Inparticular
some > tests like "unpack sequence" are > almost 20% slower. As there are some other tests were 3.9 isfaster, is
not fair > to conclude that 3.9 is slower, but > this is something we should look into in my opinion. > > You can check these benchmarks I am talking about by: > > * Go here: https://speed.python.org/comparison/ > * In the left bar, select "lto-pgo latest in branch '3.9'" and"lto-pgo latest
> in branch '3.8'" > * To better read the plot, I would recommend to select a"Normalization"
to the > 3.8 branch (this is in the top part of the page) > and to check the "horizontal" checkbox. > > These benchmarks are very stable: I have executed them severaltimes over the
> weekend yielding the same results and, > more importantly, they are being executed on a server speciallyprepared to
> running reproducible benchmarks: CPU affinity, > CPU isolation, CPU pinning for NUMA nodes, CPU frequency isfixed, CPU
governor > set to performance mode, IRQ affinity is > disabled for the benchmarking CPU nodes...etc so you can trustthese numbers.
> > I kindly suggest for everyone interested in trying to improve the3.9 (and
> master) performance, to review these benchmarks > and try to identify the problems and fix them or to find whatchanges
introduced > the regressions in the first place. All benchmarks > are the ones being executed by the pyperformance suite > (https://github.com/python/pyperformance) so you can execute them > locally if you need to. > > --- > > On a related note, I am also working on the speed.python.org <http://speed.python.org> > <http://speed.python.org> server to provide more automation and > ideally some integrations with GitHub to detect performanceregressions. For
> now, I have done the following: > > * Recompute benchmarks for all branches using the same version of > pyperformance (except master) so they can > be compared with each other. This can only be seen in the"Comparison"
> tab: https://speed.python.org/comparison/ > * I am setting daily builds of the master branch so we can detectperformance
> regressions with daily granularity. These > daily builds will be located in the "Changes" and "Timeline"tabs
> (https://speed.python.org/timeline/). > * Once the daily builds are working as expected, I plan to workon trying to
> automatically comment or PRs or on bpo if > we detect that a commit has introduced some notable performanceregression.
> > Regards from sunny London, > Pablo Galindo Salgado. > > _______________________________________________ > python-committers mailing list -- python-committers@python.org <mailto:python-committers@python.org> > To unsubscribe send an email topython-committers-leave@python.org
<mailto:python-committers-leave@python.org> >https://mail.python.org/mailman3/lists/python-committers.python.org/
> Message archived athttps://mail.python.org/archives/list/python-committers@python.org/message/G...
> Code of Conduct: https://www.python.org/psf/codeofconduct/ > -- Marc-Andre Lemburg eGenix.com Professional Python Services directly from the Experts (#1, Oct 14
>>> Python Projects, Coaching and Support ...>>> Python Product Development ...https://consulting.egenix.com/
::: We implement business ideas - efficiently in both time andcosts :::
eGenix.com Software, Skills and Services GmbHPastor-Loeh-Str.48 <https://www.google.com/maps/search/Pastor-Loeh-Str.48+%0D%0A+%C2%A0+%C2%A0+%C2%A0%C2%A0+%C2%A0+D-40764+Langenfeld,+Germany?entry=gmail&source=g>
D-40764 Langenfeld, Germany<https://www.google.com/maps/search/Pastor-Loeh-Str.48+%0D%0A+%C2%A0+%C2%A0+%C2%A0%C2%A0+%C2%A0+D-40764+Langenfeld,+Germany?entry=gmail&source=g>. CEO Dipl.-Math. Marc-Andre Lemburg
Registered at Amtsgericht Duesseldorf: HRB 46611 https://www.egenix.com/company/contact/ https://www.malemburg.com/-- Marc-Andre Lemburg eGenix.com
Professional Python Services directly from the Experts (#1, Oct 14 2020)
Python Projects, Coaching and Support ... https://www.egenix.com/ Python Product Development ... https://consulting.egenix.com/
::: We implement business ideas - efficiently in both time and costs :::
eGenix.com Software, Skills and Services GmbH Pastor-Loeh-Str.48 <https://www.google.com/maps/search/Pastor-Loeh-Str.48+%0D%0A%C2%A0+%C2%A0+D-40764+Langenfeld,+Germany?entry=gmail&source=g> D-40764 Langenfeld, Germany <https://www.google.com/maps/search/Pastor-Loeh-Str.48+%0D%0A%C2%A0+%C2%A0+D-40764+Langenfeld,+Germany?entry=gmail&source=g>. CEO Dipl.-Math. Marc-Andre Lemburg Registered at Amtsgericht Duesseldorf: HRB 46611 https://www.egenix.com/company/contact/ https://www.malemburg.com/
python-committers mailing list -- python-committers@python.org To unsubscribe send an email to python-committers-leave@python.org https://mail.python.org/mailman3/lists/python-committers.python.org/ Message archived at https://mail.python.org/archives/list/python-committers@python.org/message/L... Code of Conduct: https://www.python.org/psf/codeofconduct/
Would it be possible instead to run git-bisect for only a _particular_ benchmark? It seems that may be all that’s needed to track down particular regressions. Also, if e.g. git-bisect is used it wouldn’t be every e.g. 10th revision but rather O(log(n)) revisions.
That only works if there is a single change that produced the issue and not many small changes that have a cumulative effect, which is normally the case. Also, it does not work (is more tricky to make it work) if the issue was introduced, then fixed somehow and then introduced again or in a worse way.
On Wed, 14 Oct 2020 at 18:58, Chris Jerdonek <chris.jerdonek@gmail.com> wrote:
MOn Wed, Oct 14, 2020 at 8:03 AM Pablo Galindo Salgado < pablogsal@gmail.com> wrote:
Would it be possible rerun the tests with the current setup for say the last 1000 revisions or perhaps a subset of these (e.g. every 10th revision) to try to binary search for the revision which introduced the change ?
Every run takes 1-2 h so doing 1000 would be certainly time-consuming :)
Would it be possible instead to run git-bisect for only a _particular_ benchmark? It seems that may be all that’s needed to track down particular regressions. Also, if e.g. git-bisect is used it wouldn’t be every e.g. 10th revision but rather O(log(n)) revisions.
—Chris
That's why from now on I am trying to invest in daily builds for master,
so we can answer that exact question if we detect regressions in the future.
On Wed, 14 Oct 2020 at 15:04, M.-A. Lemburg <mal@egenix.com> wrote:
Would it be possible to get the data for older runs back, so that it's easier to find the changes which caused the slowdown ?
Unfortunately no. The reasons are that that data was misleading because different points were computed with a different version of
therefore with different packages (and therefore different code). So
On 14.10.2020 16:00, Pablo Galindo Salgado wrote: pyperformance and the points
could not be compared among themselves.
Also, past data didn't include 3.9 commits because the data gathering was not automated and it didn't run in a long time :(
Make sense.
Would it be possible rerun the tests with the current setup for say the last 1000 revisions or perhaps a subset of these (e.g. every 10th revision) to try to binary search for the revision which introduced the change ?
On Wed, 14 Oct 2020 at 14:57, M.-A. Lemburg <mal@egenix.com <mailto:mal@egenix.com>> wrote:
Hi Pablo, thanks for pointing this out. Would it be possible to get the data for older runs back, so that it's easier to find the changes which caused the slowdown ? Going to the timeline, it seems that the system only has data for Oct 14 (today):In addition to unpack_sequence, the regex_dna test has slowed down a lot compared to Py3.8.https://github.com/python/pyperformance/blob/master/pyperformance/benchmarks...
https://github.com/python/pyperformance/blob/master/pyperformance/benchmarks...
Thanks. On 14.10.2020 15:16, Pablo Galindo Salgado wrote: > Hi! > > I have updated the branch benchmarks in the pyperformance serverand now they
> include 3.9. There are > some benchmarks that are faster but on the other hand somebenchmarks are
> substantially slower, pointing > at a possible performance regression in 3.9 in some aspects. Inparticular
some > tests like "unpack sequence" are > almost 20% slower. As there are some other tests were 3.9 isfaster, is
not fair > to conclude that 3.9 is slower, but > this is something we should look into in my opinion. > > You can check these benchmarks I am talking about by: > > * Go here: https://speed.python.org/comparison/ > * In the left bar, select "lto-pgo latest in branch '3.9'" and"lto-pgo latest
> in branch '3.8'" > * To better read the plot, I would recommend to select a"Normalization"
to the > 3.8 branch (this is in the top part of the page) > and to check the "horizontal" checkbox. > > These benchmarks are very stable: I have executed them severaltimes over the
> weekend yielding the same results and, > more importantly, they are being executed on a server speciallyprepared to
> running reproducible benchmarks: CPU affinity, > CPU isolation, CPU pinning for NUMA nodes, CPU frequency isfixed, CPU
governor > set to performance mode, IRQ affinity is > disabled for the benchmarking CPU nodes...etc so you can trustthese numbers.
> > I kindly suggest for everyone interested in trying to improvethe 3.9 (and
> master) performance, to review these benchmarks > and try to identify the problems and fix them or to find whatchanges
introduced > the regressions in the first place. All benchmarks > are the ones being executed by the pyperformance suite > (https://github.com/python/pyperformance) so you can executethem
> locally if you need to. > > --- > > On a related note, I am also working on the speed.python.org <http://speed.python.org> > <http://speed.python.org> server to provide more automation and > ideally some integrations with GitHub to detect performanceregressions. For
> now, I have done the following: > > * Recompute benchmarks for all branches using the same version of > pyperformance (except master) so they can > be compared with each other. This can only be seen in the"Comparison"
> tab: https://speed.python.org/comparison/ > * I am setting daily builds of the master branch so we candetect performance
> regressions with daily granularity. These > daily builds will be located in the "Changes" and "Timeline"tabs
> (https://speed.python.org/timeline/). > * Once the daily builds are working as expected, I plan to workon trying to
> automatically comment or PRs or on bpo if > we detect that a commit has introduced some notable performanceregression.
> > Regards from sunny London, > Pablo Galindo Salgado. > > _______________________________________________ > python-committers mailing list -- python-committers@python.org <mailto:python-committers@python.org> > To unsubscribe send an email topython-committers-leave@python.org
<mailto:python-committers-leave@python.org> >https://mail.python.org/mailman3/lists/python-committers.python.org/
> Message archived athttps://mail.python.org/archives/list/python-committers@python.org/message/G...
> Code of Conduct: https://www.python.org/psf/codeofconduct/ > -- Marc-Andre Lemburg eGenix.com Professional Python Services directly from the Experts (#1, Oct 14
>>> Python Projects, Coaching and Support ...>>> Python Product Development ...https://consulting.egenix.com/
::: We implement business ideas - efficiently in both time andcosts :::
eGenix.com Software, Skills and Services GmbHPastor-Loeh-Str.48 <https://www.google.com/maps/search/Pastor-Loeh-Str.48+%0D%0A+%C2%A0+%C2%A0+%C2%A0%C2%A0+%C2%A0+D-40764+Langenfeld,+Germany?entry=gmail&source=g>
D-40764 Langenfeld, Germany<https://www.google.com/maps/search/Pastor-Loeh-Str.48+%0D%0A+%C2%A0+%C2%A0+%C2%A0%C2%A0+%C2%A0+D-40764+Langenfeld,+Germany?entry=gmail&source=g>. CEO Dipl.-Math. Marc-Andre Lemburg
Registered at Amtsgericht Duesseldorf: HRB 46611 https://www.egenix.com/company/contact/ https://www.malemburg.com/-- Marc-Andre Lemburg eGenix.com
Professional Python Services directly from the Experts (#1, Oct 14 2020)
Python Projects, Coaching and Support ... https://www.egenix.com/ Python Product Development ... https://consulting.egenix.com/
::: We implement business ideas - efficiently in both time and costs :::
eGenix.com Software, Skills and Services GmbH Pastor-Loeh-Str.48 <https://www.google.com/maps/search/Pastor-Loeh-Str.48+%0D%0A%C2%A0+%C2%A0+D-40764+Langenfeld,+Germany?entry=gmail&source=g> D-40764 Langenfeld, Germany <https://www.google.com/maps/search/Pastor-Loeh-Str.48+%0D%0A%C2%A0+%C2%A0+D-40764+Langenfeld,+Germany?entry=gmail&source=g>. CEO Dipl.-Math. Marc-Andre Lemburg Registered at Amtsgericht Duesseldorf: HRB 46611 https://www.egenix.com/company/contact/ https://www.malemburg.com/
python-committers mailing list -- python-committers@python.org To unsubscribe send an email to python-committers-leave@python.org https://mail.python.org/mailman3/lists/python-committers.python.org/ Message archived at https://mail.python.org/archives/list/python-committers@python.org/message/L... Code of Conduct: https://www.python.org/psf/codeofconduct/

Le 14/10/2020 à 15:16, Pablo Galindo Salgado a écrit :
Hi!
I have updated the branch benchmarks in the pyperformance server and now they include 3.9. There are some benchmarks that are faster but on the other hand some benchmarks are substantially slower, pointing at a possible performance regression in 3.9 in some aspects. In particular some tests like "unpack sequence" are almost 20% slower. As there are some other tests were 3.9 is faster, is not fair to conclude that 3.9 is slower, but this is something we should look into in my opinion.
You can check these benchmarks I am talking about by:
- Go here: https://speed.python.org/comparison/
- In the left bar, select "lto-pgo latest in branch '3.9'" and "lto-pgo latest in branch '3.8'"
- To better read the plot, I would recommend to select a "Normalization" to the 3.8 branch (this is in the top part of the page) and to check the "horizontal" checkbox.
Those numbers tell me that it's a wash. I wouldn't worry about a small regression on a micro- or mini-benchmark while the overall picture is stable.
Regards
Antoine.
I wouldn't worry about a small regression on a micro- or mini-benchmark while the overall picture is stable.
Absolutely, I agree is not something to *worry* but I think it makes sense to investigate as the possible fix may be trivial. Part of the reason I wanted to recompute them was because the micro-benchmarks published in the What's new of 3.9 were confusing a lot of users that were thinking if 3.9 was slower.
On Wed, 14 Oct 2020 at 15:14, Antoine Pitrou <antoine@python.org> wrote:
Le 14/10/2020 à 15:16, Pablo Galindo Salgado a écrit :
Hi!
I have updated the branch benchmarks in the pyperformance server and now they include 3.9. There are some benchmarks that are faster but on the other hand some benchmarks are substantially slower, pointing at a possible performance regression in 3.9 in some aspects. In particular some tests like "unpack sequence" are almost 20% slower. As there are some other tests were 3.9 is faster, is not fair to conclude that 3.9 is slower, but this is something we should look into in my opinion.
You can check these benchmarks I am talking about by:
- Go here: https://speed.python.org/comparison/
- In the left bar, select "lto-pgo latest in branch '3.9'" and "lto-pgo latest in branch '3.8'"
- To better read the plot, I would recommend to select a "Normalization" to the 3.8 branch (this is in the top part of the page) and to check the "horizontal" checkbox.
Those numbers tell me that it's a wash. I wouldn't worry about a small regression on a micro- or mini-benchmark while the overall picture is stable.
Regards
Antoine.
python-committers mailing list -- python-committers@python.org To unsubscribe send an email to python-committers-leave@python.org https://mail.python.org/mailman3/lists/python-committers.python.org/ Message archived at https://mail.python.org/archives/list/python-committers@python.org/message/W... Code of Conduct: https://www.python.org/psf/codeofconduct/
On 14.10.2020 16:14, Antoine Pitrou wrote:
Le 14/10/2020 à 15:16, Pablo Galindo Salgado a écrit :
Hi!
I have updated the branch benchmarks in the pyperformance server and now they include 3.9. There are some benchmarks that are faster but on the other hand some benchmarks are substantially slower, pointing at a possible performance regression in 3.9 in some aspects. In particular some tests like "unpack sequence" are almost 20% slower. As there are some other tests were 3.9 is faster, is not fair to conclude that 3.9 is slower, but this is something we should look into in my opinion.
You can check these benchmarks I am talking about by:
- Go here: https://speed.python.org/comparison/
- In the left bar, select "lto-pgo latest in branch '3.9'" and "lto-pgo latest in branch '3.8'"
- To better read the plot, I would recommend to select a "Normalization" to the 3.8 branch (this is in the top part of the page) and to check the "horizontal" checkbox. Those numbers tell me that it's a wash. I wouldn't worry about a small regression on a micro- or mini-benchmark while the overall picture is stable.
Well, there's a trend here:
Those two benchmarks were somewhat faster in Py3.7 and got slower in 3.8 and then again in 3.9, so this is more than just an artifact.
-- Marc-Andre Lemburg eGenix.com
Professional Python Services directly from the Experts (#1, Oct 14 2020)
Python Projects, Coaching and Support ... https://www.egenix.com/ Python Product Development ... https://consulting.egenix.com/
::: We implement business ideas - efficiently in both time and costs :::
eGenix.com Software, Skills and Services GmbH Pastor-Loeh-Str.48 D-40764 Langenfeld, Germany. CEO Dipl.-Math. Marc-Andre Lemburg Registered at Amtsgericht Duesseldorf: HRB 46611 https://www.egenix.com/company/contact/ https://www.malemburg.com/
{kind=link}
Le 14/10/2020 à 17:25, M.-A. Lemburg a écrit :
Well, there's a trend here:
[...]
Those two benchmarks were somewhat faster in Py3.7 and got slower in 3.8 and then again in 3.9, so this is more than just an artifact.
unpack-sequence is a micro-benchmark. It's useful if you want to investigate the cause of a regression witnessed elsewhere (or if you're changing things in precisely that part of the interpreter), but it's not relevant in itself to measure Python performance.
regex-dna is a "mini"-benchmark. I suppose someone could look if there were any potentially relevant changes done in the regex engine, that would explain the changes.
Regards
Antoine.
On 14.10.2020 17:59, Antoine Pitrou wrote:
Le 14/10/2020 à 17:25, M.-A. Lemburg a écrit :
Well, there's a trend here:
[...]
Those two benchmarks were somewhat faster in Py3.7 and got slower in 3.8 and then again in 3.9, so this is more than just an artifact.
unpack-sequence is a micro-benchmark. It's useful if you want to investigate the cause of a regression witnessed elsewhere (or if you're changing things in precisely that part of the interpreter), but it's not relevant in itself to measure Python performance.
Since unpacking is done a lot in Python applications, this particular micro benchmark does have an effect on overall performance and there was some recent discussion about exactly this part of the code slowing down (even though the effects were related to macOS only AFAIR).
As with most micro benchmarks, you typically don't see the effect of one slowdown or speedup in applications. Only if several such changes come together, you notice a change.
That said, it's still good practice to keep an eye on such performance regressions and also to improve upon micro benchmarks.
The latter was my main motiviation for writing pybench back in 1997, which focuses on such micro benchmarks, rather than higher level benchmarks, where it's much harder to find out why performance changed.
regex-dna is a "mini"-benchmark. I suppose someone could look if there were any potentially relevant changes done in the regex engine, that would explain the changes.
-- Marc-Andre Lemburg eGenix.com
Professional Python Services directly from the Experts (#1, Oct 14 2020)
Python Projects, Coaching and Support ... https://www.egenix.com/ Python Product Development ... https://consulting.egenix.com/
::: We implement business ideas - efficiently in both time and costs :::
eGenix.com Software, Skills and Services GmbH Pastor-Loeh-Str.48 D-40764 Langenfeld, Germany. CEO Dipl.-Math. Marc-Andre Lemburg Registered at Amtsgericht Duesseldorf: HRB 46611 https://www.egenix.com/company/contact/ https://www.malemburg.com/
Le mer. 14 oct. 2020 à 17:59, Antoine Pitrou <antoine@python.org> a écrit :
unpack-sequence is a micro-benchmark. (...)
I suggest removing it.
I removed other similar micro-benchmarks from pyperformance in the past, since they can easily be misunderstood and misleading. For curious people, I'm keeping a collection of Python micro-benchmarks at: https://github.com/vstinner/pymicrobench
Victor
Night gathers, and now my watch begins. It shall not end until my death.
On 15.10.2020 15:50, Victor Stinner wrote:
Le mer. 14 oct. 2020 à 17:59, Antoine Pitrou <antoine@python.org> a écrit :
unpack-sequence is a micro-benchmark. (...)
I suggest removing it.
I removed other similar micro-benchmarks from pyperformance in the past, since they can easily be misunderstood and misleading. For curious people, I'm keeping a collection of Python micro-benchmarks at: https://github.com/vstinner/pymicrobench
As mentioned, those micro benchmark are more helpful in identifying performance regressions than macro benchmarks, esp. when you find that a macro benchmark is showing issues.
When you find that a macro benchmark isn't performing well anymore, it's very difficult understanding the cause and micro benchmarks help identify the reasons.
So instead of removing them, I'd suggest to add them back to the suite or have them run in a separate suite, specifically called "micro benchmarks" to address you concern about people misinterpreting them.
-- Marc-Andre Lemburg eGenix.com
Professional Python Services directly from the Experts (#1, Oct 15 2020)
Python Projects, Coaching and Support ... https://www.egenix.com/ Python Product Development ... https://consulting.egenix.com/
::: We implement business ideas - efficiently in both time and costs :::
eGenix.com Software, Skills and Services GmbH Pastor-Loeh-Str.48 D-40764 Langenfeld, Germany. CEO Dipl.-Math. Marc-Andre Lemburg Registered at Amtsgericht Duesseldorf: HRB 46611 https://www.egenix.com/company/contact/ https://www.malemburg.com/
participants (6)
-
 Antoine Pitrou
Antoine Pitrou -
 Chris Jerdonek
Chris Jerdonek -
 M.-A. Lemburg
M.-A. Lemburg -
 Pablo Galindo Salgado
Pablo Galindo Salgado -
 Paul Moore
Paul Moore -
 Victor Stinner
Victor Stinner