
Thanks Skip — nice to see some examples.
Did you try running the same code with stock Python?
One reason I ask is the IIUC, you are using numpy for the individual
vector operations, and numpy already releases the GIL in some
circumstances.
It would also be fun to see David Beezley’s example from his seminal talk:
https://youtu.be/ph374fJqFPE
-CHB
On Thu, Oct 28, 2021 at 3:55 AM Skip Montanaro
Guido> To be clear, Sam’s basic approach is a bit slower for single-threaded code, and he admits that. But to sweeten the pot he has also applied a bunch of unrelated speedups that make it faster in general, so that overall it’s always a win. But presumably we could upstream the latter easily, separately from the GIL-freeing part.
Something just occurred to me. If you upstream all the other goodies (register VM, etc), when the time comes to upstream the no-GIL parts won't the complaint then be (again), "but it's slower for single-threaded code!" ? ;-)
Onto other things. For about as long as I can remember, the biggest knock against Python was, "You can never do any serious multi-threaded programming with it. It has this f**king GIL!" I know that attempts to remove it have been made multiple times, beginning with (I think) Greg Smith in the 1.4 timeframe. In my opinion, Sam's work finally solves the problem.
Not being a serious parallel programming person (I have used multi-threading a bit in Python, but only for obviously I/O-bound tasks), I thought it might be instructive — for me, at least — to kick the no-GIL tires a bit. Not having any obvious application in mind, I decided to implement a straightforward parallel matrix multiply. (I think I wrote something similar back in the mid-80s in a now defunct Smalltalk-inspired language while at GE.) Note that this was just for my own edification. I have no intention of trying to supplant numpy.matmul() or anything like that. It splits up the computation in the most straightforward (to me) way, handing off the individual vector multiplications to a variable sized thread pool. The code is here:
https://gist.github.com/smontanaro/80f788a506d2f41156dae779562fd08d
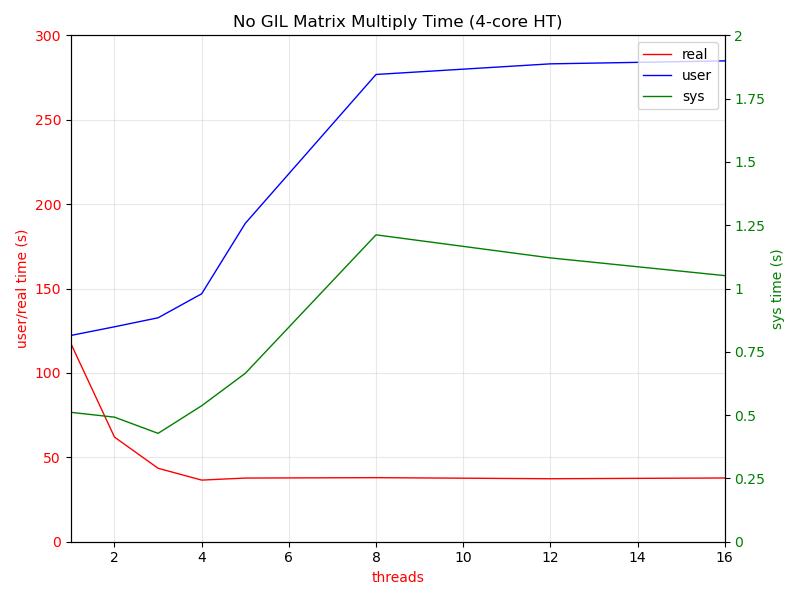
Here is a graph of some timings. My machine is a now decidedly long-in-the-tooth Dell Precision 5520 with a 7th Gen Core i7 processor (four cores + hyperthreading). The data for the graph come from the built-in bash time(1) command. As expected, wall clock time drops as you increase the number of cores until you reach four. After that, nothing improves, since the logical HT cores don't actually have their own ALU (just instruction fetch/decode I think). The slope of the real time improvement from two cores to four isn't as great as one to two, probably because I wasn't careful about keeping the rest of the system quiet. It was running my normal mix, Brave with many open tabs + Emacs. I believe I used A=240x3125, B=3125x480, giving a 240x480 result, so 15200 vector multiplies. .
[image: matmul.png]
All-in-all, I think Sam's effort is quite impressive. I got things going in fits and starts, needing a bit of help from Sam and Vadym Stupakov to get the modified numpy implementation (crosstalk between my usual Conda environment and the no-GIL stuff). I'm sure there are plenty of problems yet to be solved related to extension modules, but I trust smarter people than me can solve them without a lot of fuss. Once nogil is up-to-date with the latest 3.9 release I hope these changes can start filtering into main. Hopefully that means a 3.11 release. In fact, I'd vote for pushing back the usual release cycle to accommodate inclusion. Sam has gotten this so close it would be a huge disappointment to abandon it now. The problems faced at this point would have been amortized over years of development if the GIL had been removed 20 years ago. I say go for it.
Skip _______________________________________________ Python-Dev mailing list -- python-dev@python.org To unsubscribe send an email to python-dev-leave@python.org https://mail.python.org/mailman3/lists/python-dev.python.org/ Message archived at https://mail.python.org/archives/list/python-dev@python.org/message/WBLU6PZ2... Code of Conduct: http://python.org/psf/codeofconduct/
-- Christopher Barker, PhD (Chris) Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
{kind=link}