
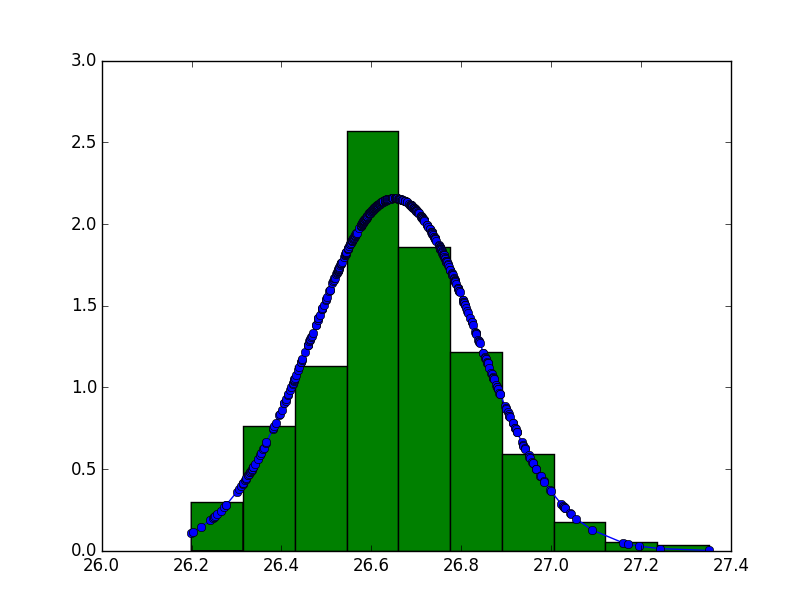
I started to work on visualisation. IMHO it helps to understand the problem. Let's create a large dataset: 500 samples (100 processes x 5 samples): --- $ python3 telco.py --json-file=telco.json -p 100 -n 5 --- Attached plot.py script creates an histogram: --- avg: 26.7 ms +- 0.2 ms; min = 26.2 ms 26.1 ms: 1 # 26.2 ms: 12 ##### 26.3 ms: 34 ############ 26.4 ms: 44 ################ 26.5 ms: 109 ###################################### 26.6 ms: 117 ######################################## 26.7 ms: 86 ############################## 26.8 ms: 50 ################## 26.9 ms: 32 ########### 27.0 ms: 10 #### 27.1 ms: 3 ## 27.2 ms: 1 # 27.3 ms: 1 # minimum 26.1 ms: 0.2% (1) of 500 samples --- Replace "if 1" with "if 0" to produce a graphical view, or just view the attached distribution.png, the numpy+scipy histogram. The distribution looks a gaussian curve: https://en.wikipedia.org/wiki/Gaussian_function The interesting thing is that only 1 sample on 500 are in the minimum bucket (26.1 ms). If you say that the performance is 26.1 ms, only 0.2% of your users will be able to reproduce this timing. The average and std dev are 26.7 ms +- 0.2 ms, so numbers 26.5 ms .. 26.9 ms: we got 109+117+86+50+32 samples in this range which gives us 394/500 = 79%. IMHO saying "26.7 ms +- 0.2 ms" (79% of samples) is less a lie than 26.1 ms (0.2%). Victor
{kind=link}