Stop using timeit, use perf.timeit!

Hi, Last weeks, I made researchs on how to get stable and reliable benchmarks, especially for the corner case of microbenchmarks. The first result is a serie of article, here are the first three: https://haypo.github.io/journey-to-stable-benchmark-system.html https://haypo.github.io/journey-to-stable-benchmark-deadcode.html https://haypo.github.io/journey-to-stable-benchmark-average.html The second result is a new perf module which includes all "tricks" discovered in my research: compute average and standard deviation, spawn multiple worker child processes, automatically calibrate the number of outter-loop iterations, automatically pin worker processes to isolated CPUs, and more. The perf module allows to store benchmark results as JSON to analyze them in depth later. It helps to configure correctly a benchmark and check manually if it is reliable or not. The perf documentation also explains how to get stable and reliable benchmarks (ex: how to tune Linux to isolate CPUs). perf has 3 builtin CLI commands: * python -m perf: show and compare JSON results * python -m perf.timeit: new better and more reliable implementation of timeit * python -m metadata: display collected metadata Python 3 is recommended to get time.perf_counter(), use the new accurate statistics module, automatic CPU pinning (I will implement it on Python 2 later), etc. But Python 2.7 is also supported, fallbacks are implemented when needed. Example with the patched telco benchmark (benchmark for the decimal module) on a Linux with two isolated CPUs. First run the benchmark: --- $ python3 telco.py --json-file=telco.json ......................... Average: 26.7 ms +- 0.2 ms --- Then show the JSON content to see all details: --- $ python3 -m perf -v show telco.json Metadata: - aslr: enabled - cpu_affinity: 2, 3 - cpu_count: 4 - cpu_model_name: Intel(R) Core(TM) i7-2600 CPU @ 3.40GHz - hostname: smithers - loops: 10 - platform: Linux-4.4.9-300.fc23.x86_64-x86_64-with-fedora-23-Twenty_Three - python_executable: /usr/bin/python3 - python_implementation: cpython - python_version: 3.4.3 Run 1/25: warmup (1): 26.9 ms; samples (3): 26.8 ms, 26.8 ms, 26.7 ms Run 2/25: warmup (1): 26.8 ms; samples (3): 26.7 ms, 26.7 ms, 26.7 ms Run 3/25: warmup (1): 26.9 ms; samples (3): 26.8 ms, 26.9 ms, 26.8 ms (...) Run 25/25: warmup (1): 26.8 ms; samples (3): 26.7 ms, 26.7 ms, 26.7 ms Average: 26.7 ms +- 0.2 ms (25 runs x 3 samples; 1 warmup) --- Note: benchmarks can be analyzed with Python 2. I'm posting my email to python-dev because providing timeit results is commonly requested in review of optimization patches. The next step is to patch the CPython benchmark suite to use the perf module. I already forked the repository and started to patch some benchmarks. If you are interested by Python performance in general, please join us on the speed mailing list! https://mail.python.org/mailman/listinfo/speed Victor

On Fri, Jun 10, 2016 at 01:13:10PM +0200, Victor Stinner wrote:
Hi,
Last weeks, I made researchs on how to get stable and reliable benchmarks, especially for the corner case of microbenchmarks. The first result is a serie of article, here are the first three:
Thank you for this! I am very interested in benchmarking.
https://haypo.github.io/journey-to-stable-benchmark-system.html https://haypo.github.io/journey-to-stable-benchmark-deadcode.html https://haypo.github.io/journey-to-stable-benchmark-average.html
I strongly question your statement in the third: [quote] But how can we compare performances if results are random? Take the minimum? No! You must never (ever again) use the minimum for benchmarking! Compute the average and some statistics like the standard deviation: [end quote] While I'm happy to see a real-world use for the statistics module, I disagree with your logic. The problem is that random noise can only ever slow the code down, it cannot speed it up. To put it another way, the random errors in the timings are always positive. Suppose you micro-benchmark some code snippet and get a series of timings. We can model the measured times as: measured time t = T + ε where T is the unknown "true" timing we wish to estimate, and ε is some variable error due to noise in the system. But ε is always positive, never negative, and we always measure something larger than T. Let's suppose we somehow (magically) know what the epsilons are: measurements = [T + 0.01, T + 0.02, T + 0.04, T + 0.01] The average is (4*T + 0.08)/4 = T + 0.02 But the minimum is T + 0.01, which is a better estimate than the average. Taking the average means that *worse* epsilons will effect your estimate, while the minimum means that only the smallest epsilon effects your estimate. Taking the average is appropriate is if the error terms can be positive or negative, e.g. if they are *measurement error* rather than noise: measurements = [T + 0.01, T - 0.02, T + 0.04, T - 0.01] The average is (4*T + 0.02)/4 = T + 0.005 The minimum is T - 0.02, which is worse than the average. Unless you have good reason to think that the timing variation is mostly caused by some error which can be both positive and negative, the minimum is the right statistic to use, not the average. But ask yourself: what sort of error, noise or external influence will cause the code snippet to run FASTER than the fastest the CPU can execute it? -- Steve

On Fri, 2016-06-10 at 23:20 +1000, Steven D'Aprano wrote:
On Fri, Jun 10, 2016 at 01:13:10PM +0200, Victor Stinner wrote:
Hi,
Last weeks, I made researchs on how to get stable and reliable benchmarks, especially for the corner case of microbenchmarks. The first result is a serie of article, here are the first three:
Thank you for this! I am very interested in benchmarking.
https://haypo.github.io/journey-to-stable-benchmark-system.html https://haypo.github.io/journey-to-stable-benchmark-deadcode.html https://haypo.github.io/journey-to-stable-benchmark-average.html
I strongly question your statement in the third:
[quote] But how can we compare performances if results are random? Take the minimum?
No! You must never (ever again) use the minimum for benchmarking! Compute the average and some statistics like the standard deviation: [end quote]
While I'm happy to see a real-world use for the statistics module, I disagree with your logic.
The problem is that random noise can only ever slow the code down, it cannot speed it up.
Consider a workload being benchmarked running on one core, which has a particular pattern of cache hits and misses. Now consider another process running on a sibling core, sharing the same cache. Isn't it possible that under some circumstances the 2nd process could prefetch memory into the cache in such a way that the workload under test actually gets faster than if the 2nd process wasn't running? [...snip...] Hope this is constructive Dave

On 10 June 2016 at 15:34, David Malcolm <dmalcolm@redhat.com> wrote:
The problem is that random noise can only ever slow the code down, it cannot speed it up. [...] Isn't it possible that under some circumstances the 2nd process could prefetch memory into the cache in such a way that the workload under test actually gets faster than if the 2nd process wasn't running?
My feeling is that it would be much rarer for random effects to speed up the benchmark under test - possible in the sort of circumstance you describe, but not common. The conclusion I draw is "be careful how you interpret summary statistics if you don't know the distribution of the underlying data as an estimator of the value you are interested in". In the case of Victor's article, he's specifically trying to compensate for variations introduced by Python's hash randomisation algorithm. And for that, you would get both positive and negative effects on code speed, so the average makes sense. But only if you've already eliminated the other common noise (such as other proceses, etc). In Victor's articles, he sounds like he's done this, but he's using very Linux-specific mechanisms, and I don't know if he's done the same for other platforms. Also, the way people commonly use micro-benchmarks ("hey, look, this way of writing the expression goes faster than that way") doesn't really address questions like "is the difference statistically significant". Summary: Micro-benchmarking is hard. Victor looks like he's done some really interesting work on it, but any "easy to use" timeit tool will typically get used in an over-simplistic way in practice, and so you probably shouldn't read too much into timing figures quoted in isolation, no matter what tool was used to generate them. Paul
2016-06-10 17:09 GMT+02:00 Paul Moore <p.f.moore@gmail.com>:
Also, the way people commonly use micro-benchmarks ("hey, look, this way of writing the expression goes faster than that way") doesn't really address questions like "is the difference statistically significant".
If you use the "python3 -m perf compare method1.json method2.json", perf will checks that the difference is significant using the is_significant() method: http://perf.readthedocs.io/en/latest/api.html#perf.is_significant "This uses a Student’s two-sample, two-tailed t-test with alpha=0.95." FYI at the beginning, this function comes from the Unladen Swallow benchmark suite ;-) We should design a CLI command to do timeit+compare at once. Victor

On 6/10/2016 12:09 PM, Victor Stinner wrote:
2016-06-10 17:09 GMT+02:00 Paul Moore <p.f.moore@gmail.com>:
Also, the way people commonly use micro-benchmarks ("hey, look, this way of writing the expression goes faster than that way") doesn't really address questions like "is the difference statistically significant".
If you use the "python3 -m perf compare method1.json method2.json", perf will checks that the difference is significant using the is_significant() method: http://perf.readthedocs.io/en/latest/api.html#perf.is_significant "This uses a Student’s two-sample, two-tailed t-test with alpha=0.95."
Depending on the sampling design, a matched-pairs t-test may be more appropriate. -- Terry Jan Reedy

On 11 June 2016 at 04:09, Victor Stinner <victor.stinner@gmail.com> wrote: ..> We should design a CLI command to do timeit+compare at once. http://judge.readthedocs.io/en/latest/ might offer some inspiration There's also ministat - https://www.freebsd.org/cgi/man.cgi?query=ministat&apropos=0&sektion=0&manpath=FreeBSD+8-current&format=html
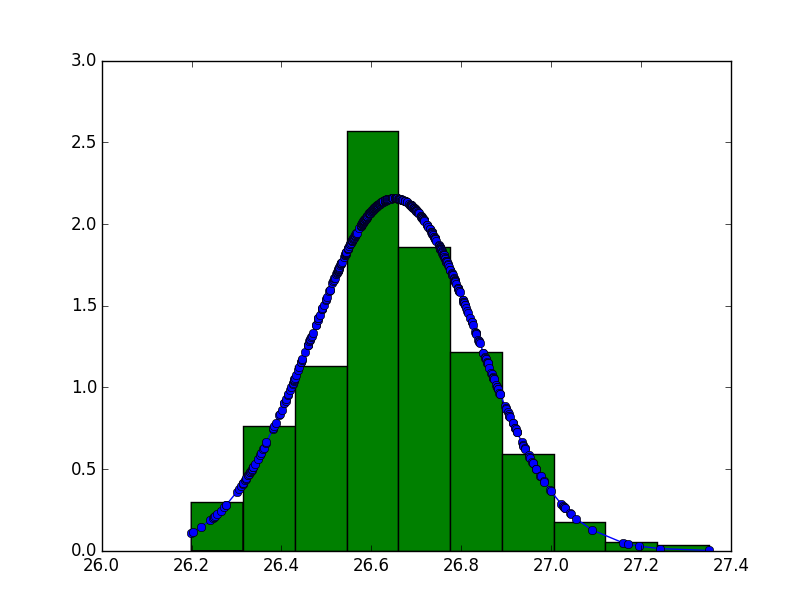
I started to work on visualisation. IMHO it helps to understand the problem. Let's create a large dataset: 500 samples (100 processes x 5 samples): --- $ python3 telco.py --json-file=telco.json -p 100 -n 5 --- Attached plot.py script creates an histogram: --- avg: 26.7 ms +- 0.2 ms; min = 26.2 ms 26.1 ms: 1 # 26.2 ms: 12 ##### 26.3 ms: 34 ############ 26.4 ms: 44 ################ 26.5 ms: 109 ###################################### 26.6 ms: 117 ######################################## 26.7 ms: 86 ############################## 26.8 ms: 50 ################## 26.9 ms: 32 ########### 27.0 ms: 10 #### 27.1 ms: 3 ## 27.2 ms: 1 # 27.3 ms: 1 # minimum 26.1 ms: 0.2% (1) of 500 samples --- Replace "if 1" with "if 0" to produce a graphical view, or just view the attached distribution.png, the numpy+scipy histogram. The distribution looks a gaussian curve: https://en.wikipedia.org/wiki/Gaussian_function The interesting thing is that only 1 sample on 500 are in the minimum bucket (26.1 ms). If you say that the performance is 26.1 ms, only 0.2% of your users will be able to reproduce this timing. The average and std dev are 26.7 ms +- 0.2 ms, so numbers 26.5 ms .. 26.9 ms: we got 109+117+86+50+32 samples in this range which gives us 394/500 = 79%. IMHO saying "26.7 ms +- 0.2 ms" (79% of samples) is less a lie than 26.1 ms (0.2%). Victor
{kind=link}
On 6/10/2016 11:07 AM, Victor Stinner wrote:
I started to work on visualisation. IMHO it helps to understand the problem.
Let's create a large dataset: 500 samples (100 processes x 5 samples):
As I finished by response to Steven, I was thinking you should do something like this to get real data.
--- $ python3 telco.py --json-file=telco.json -p 100 -n 5 ---
Attached plot.py script creates an histogram: --- avg: 26.7 ms +- 0.2 ms; min = 26.2 ms
26.1 ms: 1 # 26.2 ms: 12 ##### 26.3 ms: 34 ############ 26.4 ms: 44 ################ 26.5 ms: 109 ###################################### 26.6 ms: 117 ######################################## 26.7 ms: 86 ############################## 26.8 ms: 50 ################## 26.9 ms: 32 ########### 27.0 ms: 10 #### 27.1 ms: 3 ## 27.2 ms: 1 # 27.3 ms: 1 #
minimum 26.1 ms: 0.2% (1) of 500 samples ---
Replace "if 1" with "if 0" to produce a graphical view, or just view the attached distribution.png, the numpy+scipy histogram.
The distribution looks a gaussian curve: https://en.wikipedia.org/wiki/Gaussian_function
I am not too surprised. If there are several somewhat independent sources of slowdown, their sum would tend to be normal. I am also not surprised that there is also a bit of skewness, but probably not enough to worry about.
The interesting thing is that only 1 sample on 500 are in the minimum bucket (26.1 ms). If you say that the performance is 26.1 ms, only 0.2% of your users will be able to reproduce this timing.
The average and std dev are 26.7 ms +- 0.2 ms, so numbers 26.5 ms .. 26.9 ms: we got 109+117+86+50+32 samples in this range which gives us 394/500 = 79%.
IMHO saying "26.7 ms +- 0.2 ms" (79% of samples) is less a lie than 26.1 ms (0.2%).
-- Terry Jan Reedy
On Fri, Jun 10, 2016 at 05:07:18PM +0200, Victor Stinner wrote:
I started to work on visualisation. IMHO it helps to understand the problem.
Let's create a large dataset: 500 samples (100 processes x 5 samples): --- $ python3 telco.py --json-file=telco.json -p 100 -n 5 ---
Attached plot.py script creates an histogram: --- avg: 26.7 ms +- 0.2 ms; min = 26.2 ms
26.1 ms: 1 # 26.2 ms: 12 ##### 26.3 ms: 34 ############ 26.4 ms: 44 ################ 26.5 ms: 109 ###################################### 26.6 ms: 117 ######################################## 26.7 ms: 86 ############################## 26.8 ms: 50 ################## 26.9 ms: 32 ########### 27.0 ms: 10 #### 27.1 ms: 3 ## 27.2 ms: 1 # 27.3 ms: 1 #
minimum 26.1 ms: 0.2% (1) of 500 samples --- [...] The distribution looks a gaussian curve: https://en.wikipedia.org/wiki/Gaussian_function
Lots of distributions look a bit Gaussian, but they can be skewed, or truncated, or both. E.g. the average life-span of a lightbulb is approximately Gaussian with a central peak at some value (let's say 5000 hours), but while it is conceivable that you might be really lucky and find a bulb that lasts 15000 hours, it isn't possible to find one that lasts -10000 hours. The distribution is truncated on the left. To me, your graph looks like the distribution is skewed: the right-hand tail (shown at the bottom) is longer than the left-hand tail, six buckets compared to five buckets. There are actual statistical tests for detecting deviation from Gaussian curves, but I'd have to look them up. But as a really quick and dirty test, we can count the number of samples on either side of the central peak (the mode): left: 109+44+34+12+1 = 200 centre: 117 right: 500 - 200 - 117 = 183 It certainly looks *close* to Gaussian, but with the crude tests we are using, we can't be sure. If you took more and more samples, I would expect that the right-hand tail would get longer and longer, but the left-hand tail would not.
The interesting thing is that only 1 sample on 500 are in the minimum bucket (26.1 ms). If you say that the performance is 26.1 ms, only 0.2% of your users will be able to reproduce this timing.
Hmmm. Okay, that is a good point. In this case, you're not so much reporting your estimate of what the "true speed" of the code snippet would be in the absence of all noise, but your estimate of what your users should expect to experience "most of the time". Assuming they have exactly the same hardware, operating system, and load on their system as you have.
The average and std dev are 26.7 ms +- 0.2 ms, so numbers 26.5 ms .. 26.9 ms: we got 109+117+86+50+32 samples in this range which gives us 394/500 = 79%.
IMHO saying "26.7 ms +- 0.2 ms" (79% of samples) is less a lie than 26.1 ms (0.2%).
I think I understand the point you are making. I'll have to think about it some more to decide if I agree with you. But either way, I think the work you have done on perf is fantastic and I think this will be a great tool. I really love the histogram. Can you draw a histogram of two functions side-by-side, for comparisons? -- Steve

On Fri, 10 Jun 2016 at 10:11 Steven D'Aprano <steve@pearwood.info> wrote:
I started to work on visualisation. IMHO it helps to understand the
On Fri, Jun 10, 2016 at 05:07:18PM +0200, Victor Stinner wrote: problem.
Let's create a large dataset: 500 samples (100 processes x 5 samples): --- $ python3 telco.py --json-file=telco.json -p 100 -n 5 ---
Attached plot.py script creates an histogram: --- avg: 26.7 ms +- 0.2 ms; min = 26.2 ms
26.1 ms: 1 # 26.2 ms: 12 ##### 26.3 ms: 34 ############ 26.4 ms: 44 ################ 26.5 ms: 109 ###################################### 26.6 ms: 117 ######################################## 26.7 ms: 86 ############################## 26.8 ms: 50 ################## 26.9 ms: 32 ########### 27.0 ms: 10 #### 27.1 ms: 3 ## 27.2 ms: 1 # 27.3 ms: 1 #
minimum 26.1 ms: 0.2% (1) of 500 samples ---
[...]
The distribution looks a gaussian curve: https://en.wikipedia.org/wiki/Gaussian_function
Lots of distributions look a bit Gaussian, but they can be skewed, or truncated, or both. E.g. the average life-span of a lightbulb is approximately Gaussian with a central peak at some value (let's say 5000 hours), but while it is conceivable that you might be really lucky and find a bulb that lasts 15000 hours, it isn't possible to find one that lasts -10000 hours. The distribution is truncated on the left.
To me, your graph looks like the distribution is skewed: the right-hand tail (shown at the bottom) is longer than the left-hand tail, six buckets compared to five buckets. There are actual statistical tests for detecting deviation from Gaussian curves, but I'd have to look them up. But as a really quick and dirty test, we can count the number of samples on either side of the central peak (the mode):
left: 109+44+34+12+1 = 200 centre: 117 right: 500 - 200 - 117 = 183
It certainly looks *close* to Gaussian, but with the crude tests we are using, we can't be sure. If you took more and more samples, I would expect that the right-hand tail would get longer and longer, but the left-hand tail would not.
The interesting thing is that only 1 sample on 500 are in the minimum bucket (26.1 ms). If you say that the performance is 26.1 ms, only 0.2% of your users will be able to reproduce this timing.
Hmmm. Okay, that is a good point. In this case, you're not so much reporting your estimate of what the "true speed" of the code snippet would be in the absence of all noise, but your estimate of what your users should expect to experience "most of the time".
I think the other way to think about why you don't want to use the minimum is what if one run just happened to get lucky and ran when nothing else was running (some random lull on the system), while the second run didn't get so lucky on magically hitting an equivalent lull? Using the average helps remove the "luck of the draw" potential of taking the minimum. This is why the PyPy folks suggested to Victor to not consider the minimum but the average instead; minimum doesn't measure typical system behaviour.
Assuming they have exactly the same hardware, operating system, and load on their system as you have.
Sure, but that's true of any benchmarking. The only way to get accurate measurements for one's own system is to run the benchmarks yourself. -Brett
The average and std dev are 26.7 ms +- 0.2 ms, so numbers 26.5 ms .. 26.9 ms: we got 109+117+86+50+32 samples in this range which gives us 394/500 = 79%.
IMHO saying "26.7 ms +- 0.2 ms" (79% of samples) is less a lie than 26.1 ms (0.2%).
I think I understand the point you are making. I'll have to think about it some more to decide if I agree with you.
But either way, I think the work you have done on perf is fantastic and I think this will be a great tool. I really love the histogram. Can you draw a histogram of two functions side-by-side, for comparisons?
-- Steve _______________________________________________ Python-Dev mailing list Python-Dev@python.org https://mail.python.org/mailman/listinfo/python-dev Unsubscribe: https://mail.python.org/mailman/options/python-dev/brett%40python.org

Hi all, I wrote a blog post about this. http://blog.kevmod.com/2016/06/benchmarking-minimum-vs-average/ We can rule out any argument that one (minimum or average) is strictly better than the other, since there are cases that make either one better. It comes down to our expectation of the underlying distribution. Victor if you could calculate the sample skewness <https://en.wikipedia.org/wiki/Skewness#Sample_skewness> of your results I think that would be very interesting! kmod On Fri, Jun 10, 2016 at 10:04 AM, Steven D'Aprano <steve@pearwood.info> wrote:
I started to work on visualisation. IMHO it helps to understand the
On Fri, Jun 10, 2016 at 05:07:18PM +0200, Victor Stinner wrote: problem.
Let's create a large dataset: 500 samples (100 processes x 5 samples): --- $ python3 telco.py --json-file=telco.json -p 100 -n 5 ---
Attached plot.py script creates an histogram: --- avg: 26.7 ms +- 0.2 ms; min = 26.2 ms
26.1 ms: 1 # 26.2 ms: 12 ##### 26.3 ms: 34 ############ 26.4 ms: 44 ################ 26.5 ms: 109 ###################################### 26.6 ms: 117 ######################################## 26.7 ms: 86 ############################## 26.8 ms: 50 ################## 26.9 ms: 32 ########### 27.0 ms: 10 #### 27.1 ms: 3 ## 27.2 ms: 1 # 27.3 ms: 1 #
minimum 26.1 ms: 0.2% (1) of 500 samples ---
[...]
The distribution looks a gaussian curve: https://en.wikipedia.org/wiki/Gaussian_function
Lots of distributions look a bit Gaussian, but they can be skewed, or truncated, or both. E.g. the average life-span of a lightbulb is approximately Gaussian with a central peak at some value (let's say 5000 hours), but while it is conceivable that you might be really lucky and find a bulb that lasts 15000 hours, it isn't possible to find one that lasts -10000 hours. The distribution is truncated on the left.
To me, your graph looks like the distribution is skewed: the right-hand tail (shown at the bottom) is longer than the left-hand tail, six buckets compared to five buckets. There are actual statistical tests for detecting deviation from Gaussian curves, but I'd have to look them up. But as a really quick and dirty test, we can count the number of samples on either side of the central peak (the mode):
left: 109+44+34+12+1 = 200 centre: 117 right: 500 - 200 - 117 = 183
It certainly looks *close* to Gaussian, but with the crude tests we are using, we can't be sure. If you took more and more samples, I would expect that the right-hand tail would get longer and longer, but the left-hand tail would not.
The interesting thing is that only 1 sample on 500 are in the minimum bucket (26.1 ms). If you say that the performance is 26.1 ms, only 0.2% of your users will be able to reproduce this timing.
Hmmm. Okay, that is a good point. In this case, you're not so much reporting your estimate of what the "true speed" of the code snippet would be in the absence of all noise, but your estimate of what your users should expect to experience "most of the time".
Assuming they have exactly the same hardware, operating system, and load on their system as you have.
The average and std dev are 26.7 ms +- 0.2 ms, so numbers 26.5 ms .. 26.9 ms: we got 109+117+86+50+32 samples in this range which gives us 394/500 = 79%.
IMHO saying "26.7 ms +- 0.2 ms" (79% of samples) is less a lie than 26.1 ms (0.2%).
I think I understand the point you are making. I'll have to think about it some more to decide if I agree with you.
But either way, I think the work you have done on perf is fantastic and I think this will be a great tool. I really love the histogram. Can you draw a histogram of two functions side-by-side, for comparisons?
-- Steve _______________________________________________ Python-Dev mailing list Python-Dev@python.org https://mail.python.org/mailman/listinfo/python-dev Unsubscribe: https://mail.python.org/mailman/options/python-dev/kmod%40dropbox.com
Hi, 2016-06-10 20:37 GMT+02:00 Kevin Modzelewski via Python-Dev <python-dev@python.org>:
Hi all, I wrote a blog post about this. http://blog.kevmod.com/2016/06/benchmarking-minimum-vs-average/
Oh nice, it's even better to have different articles to explain the problem of using the minimum ;-) It added it to my doc.
We can rule out any argument that one (minimum or average) is strictly better than the other, since there are cases that make either one better. It comes down to our expectation of the underlying distribution.
Ah? In which cases do you prefer to use the minimum? Are you able to get reliable benchmark results when using the minimum?
Victor if you could calculate the sample skewness of your results I think that would be very interesting!
I'm good to copy/paste code, but less to compute statistics :-) Would be interesed to write a pull request, or at least to send me a function computing the expected value? https://github.com/haypo/perf Victor
On Sat, Jun 11, 2016 at 12:06:31AM +0200, Victor Stinner wrote:
Victor if you could calculate the sample skewness of your results I think that would be very interesting!
I'm good to copy/paste code, but less to compute statistics :-) Would be interesed to write a pull request, or at least to send me a function computing the expected value? https://github.com/haypo/perf
I have some code and tests for calculating (population and sample) skewness and kurtosis. Do you think it will be useful to add it to the statistics module? I can polish it up and aim to have it ready by 3.6.0 alpha 4. -- Steve
On 6/10/2016 9:20 AM, Steven D'Aprano wrote:
On Fri, Jun 10, 2016 at 01:13:10PM +0200, Victor Stinner wrote:
Hi,
Last weeks, I made researchs on how to get stable and reliable benchmarks, especially for the corner case of microbenchmarks. The first result is a serie of article, here are the first three:
Thank you for this! I am very interested in benchmarking.
https://haypo.github.io/journey-to-stable-benchmark-system.html https://haypo.github.io/journey-to-stable-benchmark-deadcode.html https://haypo.github.io/journey-to-stable-benchmark-average.html
I strongly question your statement in the third:
[quote] But how can we compare performances if results are random? Take the minimum?
No! You must never (ever again) use the minimum for benchmarking! Compute the average and some statistics like the standard deviation: [end quote]
While I'm happy to see a real-world use for the statistics module, I disagree with your logic.
The problem is that random noise can only ever slow the code down, it cannot speed it up. To put it another way, the random errors in the timings are always positive.
Suppose you micro-benchmark some code snippet and get a series of timings. We can model the measured times as:
measured time t = T + ε
where T is the unknown "true" timing we wish to estimate,
For comparative timings, we do not care about T. So arguments about the best estimate of T mist the point. What we do wish to estimate is the relationship between two Ts, T0 for 'control', and T1 for 'treatment', in particular T1/T0. I suspect Viktor is correct that mean(t1)/mean(t0) is better than min(t1)/min(t0) as an estimate of the true ratio T1/T0 (for a particular machine). But given that we have matched pairs of measurements with the same hashseed and address, it may be better yet to estimate T1/T0 from the ratios t1i/t0i, where i indexes experimental conditions. But it has been a long time since I have read about estimation of ratios. What I remember is that this is a nasty subject. It is also the case that while an individual with one machine wants the best ratio for that machine, we need to make CPython patch decisions for the universe of machines that run Python.
and ε is some variable error due to noise in the system. But ε is always positive, never negative,
lognormal might be a first guess. But what we really have is contributions from multiple factors, -- Terry Jan Reedy

On Fri, Jun 10, 2016 at 6:13 AM, Victor Stinner <victor.stinner@gmail.com> wrote: The second result is a new perf module which includes all "tricks"
discovered in my research: compute average and standard deviation, spawn multiple worker child processes, automatically calibrate the number of outter-loop iterations, automatically pin worker processes to isolated CPUs, and more.
Apologies in advance if this is answered in one of the links you posted, but out of curiosity was geometric mean considered? In the compiler world this is a very common way of aggregating performance results. -- Meador
2016-06-10 20:47 GMT+02:00 Meador Inge <meadori@gmail.com>:
Apologies in advance if this is answered in one of the links you posted, but out of curiosity was geometric mean considered?
In the compiler world this is a very common way of aggregating performance results.
FYI I chose to store all timings in the JSON file. So later, you are free to recompute the average differently, compute other statistics, etc. I saw that the CPython benchmark suite has an *option* to compute the geometric mean. I don't understand well the difference with the arithmeric mean. Is the geometric mean recommended to aggregate results of different (unrelated) benchmarks, or also even for multuple runs of a single benchmark? Victor
On Fri, Jun 10, 2016 at 11:22:42PM +0200, Victor Stinner wrote:
2016-06-10 20:47 GMT+02:00 Meador Inge <meadori@gmail.com>:
Apologies in advance if this is answered in one of the links you posted, but out of curiosity was geometric mean considered?
In the compiler world this is a very common way of aggregating performance results.
FYI I chose to store all timings in the JSON file. So later, you are free to recompute the average differently, compute other statistics, etc.
I saw that the CPython benchmark suite has an *option* to compute the geometric mean. I don't understand well the difference with the arithmeric mean.
Is the geometric mean recommended to aggregate results of different (unrelated) benchmarks, or also even for multuple runs of a single benchmark?
The Wikipedia article discusses this, but sits on the fence and can't decide whether using the gmean for performance results is a good or bad idea: https://en.wikipedia.org/wiki/Geometric_mean#Properties Geometric mean is usually used in finance for averaging rates of growth: https://www.math.toronto.edu/mathnet/questionCorner/geomean.html If you express your performances as speeds (as "calculations per second") then the harmonic mean is the right way to average them. -- Steve

On Fri, Jun 10, 2016, at 21:45, Steven D'Aprano wrote:
If you express your performances as speeds (as "calculations per second") then the harmonic mean is the right way to average them.
That's true in so far as you get the same result as if you were to take the arithmetic mean of the times and then converted from that to calculations per second. Is there any other particular basis for considering it "right"?
On Sat, Jun 11, 2016 at 07:43:18PM -0400, Random832 wrote:
On Fri, Jun 10, 2016, at 21:45, Steven D'Aprano wrote:
If you express your performances as speeds (as "calculations per second") then the harmonic mean is the right way to average them.
That's true in so far as you get the same result as if you were to take the arithmetic mean of the times and then converted from that to calculations per second. Is there any other particular basis for considering it "right"?
I think this is getting off-topic, so extended discussion should probably go off-list. But the brief answer is that it gives a physically meaningful result if you replace each of the data points with the mean. Which specific mean you use depends on how you are using the data points. http://mathforum.org/library/drmath/view/69480.html Consider the question: Dave can paint a room in 5 hours, and Sue can paint the same room in 3 hours. How long will it take them, working together, to paint the room? The right answer can be found the long way: Dave paints 1/5 of a room per hour, and Sue paints 1/3 of a room per hour, so together they paint (1/5+1/3) = 8/15 of a room per hour. So to paint one full room, it takes 15/8 = 1.875 hours. (Sanity check: after 1.875 hours, Sue has painted 1.875/3 of the room, or 62.5%. In that same time, Dave has painted 1.875/5 of the room, or 37.5%. Add the percentages together, and you have 100% of the room.) Using the harmonic mean, the problem is simple: data = 5, 3 # time taken per person mean = 3.75 # time taken per person on average Since they are painting the room in parallel, each person need only paint half the room on average, giving total time of: 3.75/2 = 1.875 hours If we were to use the arithmetic mean (5+3)/2 = 4 hours, we'd get the wrong answer. -- Steve

On Fri, Jun 10, 2016 at 1:13 PM, Victor Stinner <victor.stinner@gmail.com> wrote:
Hi,
Last weeks, I made researchs on how to get stable and reliable benchmarks, especially for the corner case of microbenchmarks. The first result is a serie of article, here are the first three:
https://haypo.github.io/journey-to-stable-benchmark-system.html https://haypo.github.io/journey-to-stable-benchmark-deadcode.html https://haypo.github.io/journey-to-stable-benchmark-average.html
The second result is a new perf module which includes all "tricks" discovered in my research: compute average and standard deviation, spawn multiple worker child processes, automatically calibrate the number of outter-loop iterations, automatically pin worker processes to isolated CPUs, and more.
The perf module allows to store benchmark results as JSON to analyze them in depth later. It helps to configure correctly a benchmark and check manually if it is reliable or not.
The perf documentation also explains how to get stable and reliable benchmarks (ex: how to tune Linux to isolate CPUs).
perf has 3 builtin CLI commands:
* python -m perf: show and compare JSON results * python -m perf.timeit: new better and more reliable implementation of timeit * python -m metadata: display collected metadata
Python 3 is recommended to get time.perf_counter(), use the new accurate statistics module, automatic CPU pinning (I will implement it on Python 2 later), etc. But Python 2.7 is also supported, fallbacks are implemented when needed.
Example with the patched telco benchmark (benchmark for the decimal module) on a Linux with two isolated CPUs.
First run the benchmark: --- $ python3 telco.py --json-file=telco.json ......................... Average: 26.7 ms +- 0.2 ms ---
Then show the JSON content to see all details: --- $ python3 -m perf -v show telco.json Metadata: - aslr: enabled - cpu_affinity: 2, 3 - cpu_count: 4 - cpu_model_name: Intel(R) Core(TM) i7-2600 CPU @ 3.40GHz - hostname: smithers - loops: 10 - platform: Linux-4.4.9-300.fc23.x86_64-x86_64-with-fedora-23-Twenty_Three - python_executable: /usr/bin/python3 - python_implementation: cpython - python_version: 3.4.3
Run 1/25: warmup (1): 26.9 ms; samples (3): 26.8 ms, 26.8 ms, 26.7 ms Run 2/25: warmup (1): 26.8 ms; samples (3): 26.7 ms, 26.7 ms, 26.7 ms Run 3/25: warmup (1): 26.9 ms; samples (3): 26.8 ms, 26.9 ms, 26.8 ms (...) Run 25/25: warmup (1): 26.8 ms; samples (3): 26.7 ms, 26.7 ms, 26.7 ms
Average: 26.7 ms +- 0.2 ms (25 runs x 3 samples; 1 warmup) ---
Note: benchmarks can be analyzed with Python 2.
I'm posting my email to python-dev because providing timeit results is commonly requested in review of optimization patches.
The next step is to patch the CPython benchmark suite to use the perf module. I already forked the repository and started to patch some benchmarks.
If you are interested by Python performance in general, please join us on the speed mailing list! https://mail.python.org/mailman/listinfo/speed
Victor _______________________________________________ Python-Dev mailing list Python-Dev@python.org https://mail.python.org/mailman/listinfo/python-dev Unsubscribe: https://mail.python.org/mailman/options/python-dev/g.rodola%40gmail.com
This is very interesting and also somewhat related to psutil. I wonder... would increasing process priority help isolating benchmarks even more? By this I mean "os.nice(-20)". Extra: perhaps even IO priority: https://pythonhosted.org/psutil/#psutil.Process.ionice ? -- Giampaolo - http://grodola.blogspot.com
participants (11)
-
 Brett Cannon
Brett Cannon -
 David Malcolm
David Malcolm -
 Giampaolo Rodola'
Giampaolo Rodola' -
 Kevin Modzelewski
Kevin Modzelewski -
 Meador Inge
Meador Inge -
 Paul Moore
Paul Moore -
 Random832
Random832 -
 Robert Collins
Robert Collins -
 Steven D'Aprano
Steven D'Aprano -
 Terry Reedy
Terry Reedy -
 Victor Stinner
Victor Stinner