Coding using Unicode

Hi all, What would you think if we could write our code using unicode ? It would be especially useful for scientific programming (we could use the greek letters), it could also be nice to use emojis for some variables. I don't see any bad consequences (apart from people that would use misleading characters but that's already possible). I don't know how hard it is to do that switch but it feels like it could be nice; Cheers

On 7/15/2019 7:34 AM, Adrien Ricocotam wrote:
You can use a subset of unicode for identifiers. See https://www.python.org/dev/peps/pep-3131/ and https://docs.python.org/3/reference/lexical_analysis.html#identifiers Eric

On 7/15/2019 7:43 AM, Adrien Ricocotam wrote:
Correct.
What about extending it ?
The PEP has a rationale about why it works like it does. If you want to extend it, you should be prepared to address the issues in the PEP. Your proposal would need to become a PEP itself. Eric

On Jul 15, 2019, at 04:43, Adrien Ricocotam <ricocotam@gmail.com> wrote:
I’m pretty sure that the docs explain that the subset of characters that Python allows in identifiers is exactly the one Unicode recommends that languages allow in identifiers (except possibly in the lowest 127 characters, where any character allowed in Python 2.x is still allowed in 3.x, even if Unicode says otherwise). This makes Python compatible with a whole lot of other languages, and language-agnostic tools and protocols that have similar notions of “identifier”. And it means Python can leave all the bikeshedding arguments to the Unicode committee instead of having to hash out the same arguments here. And it means Python automatically stays in sync with Unicode as they add new identifier characters just by upgrading to the newer version of Unicode, instead of having to go over the whole set of new characters each time to decide which ones should be identifiers.

On 15/07/2019 12:34, Adrien Ricocotam wrote:
it could also be nice to use emojis for some variables
For values of "nice" I personally find horrifying :-) Seriously though, the PEP defines valid characters for names by their unicode categories (plus a few special cases for backward compatibility). You'll have a stronger argument if you can show extra categories that should be allowed. (I'm using the term "character" loosely, don't all start!) -- Rhodri James *-* Kynesim Ltd

On Mon, Jul 15, 2019 at 01:34:02PM +0200, Adrien Ricocotam wrote:
We've been able to do that since about 2007. https://www.python.org/dev/peps/pep-3131/ In the future, before making suggestions for new features, you should do some research into what is already possible, and whether it has already been suggested before: https://duckduckgo.com/?q=python+unicode+identifiers
it could also be nice to use emojis for some variables.
I doubt that. Variable names should be meanigful, not "smiley face" or "eggplant".
I don't see any bad consequences
(1) For many people, it is very difficult to type non-ASCII identifiers in their editors. (2) For many people, support for many non-ASCII identifiers is poor. They will see a series of boxes, something like this: = .(, ) (3) Unicode allows us to play games like this: py> А = 1 py> print(А) 1 py> A = 2 py> print(A) 2 py> Α = 3 py> print(Α) 3 py> Α - 1 == А + 1 True Do you see what I did there? (4) Not only are confusables, well, confusing, but they can be used for phishing and other attacks. http://unicode.org/reports/tr36/tr36-8.html Of course there are ASCII confusables too, such as O 0 and I l (depending on the font you use) but Unicode adds hundreds of confusables. -- Steven

On 7/15/19 8:54 AM, Steven D'Aprano wrote:
= .(, )
I call foul. At least tentatively. For the moment. http://www.unicode.org/reports/tr31/ and http://www.unicode.org/reports/tr39/ specifically exclude private use characters, like U+E24C, from identifiers. And that said, while I am in favor of using unicode *as appropriate*, I agree that some of the drawbacks outweigh some of the benefits. I can enter all code points with my keyboard, but until there's better display support and fonts designed to disambiguate the confusables, I'll use non-ASCII identifiers very carefully. As has happened before, on this list, I am happy to learn otherwise. Dan

On Mon, 15 Jul 2019 at 14:33, Dan Sommers <2QdxY4RzWzUUiLuE@potatochowder.com> wrote:
That was a demo (he used private area characters to ensure getting the square box substitute character). The point is that someone with the wrong font installed, or a limited terminal app, can get this sort of output with entirely legal characters - and anyway the comment was made to explain why *extending* the list of allowed characters was bad (so what's legal right now is not relevant). On Mon, 15 Jul 2019 at 14:13, Adrien Ricocotam <ricocotam@gmail.com> wrote:
We can already do this is already (https://github.com/satwikkansal/wtfpython#-skipping-lines) so it's not a problem to me. It is a problem but not related to unicode.
That's *exactly* the issue of confusable characters, which is a Unicode issue. So I don't see how you can say it's "not related to Unicode". It's not directly related to *changing* which Unicode characters are allowed in identifiers - that much is true (at least partially, it's quite possible that changing the list would result in having more confusables, so increasing the risk) - but that's not what you claimed. Paul

Adrien - please take note that since you already wrote about "everybody could update their environment and editors" to support unicode, things like what you want (emojis in identifiers) can be supported at programming editor (and plug-ins and extensions for those) level - without impairing anyone else from working on your codebase. You can just work on an extension for your favorite editor that would transform certain escaped sequences into proper emojis. If these escapes are themselves valid identifiers, there is no stopping you and whatever enthusiast comunity you can raise from having fun with the looks of "pyemojicode", and that wold still allow people outside that community to interoperate with your code, and all of the tools that use the static source would still work. So, all you need is an extension to replace, at display time things liks EMO_fire_ -> 🔥 EMO_heart -> 🖤 And so on. With a browser extension, or a site that acts as a proxy to code hosting like github/bitbucket, enthusiasts could even see these characters in internet listings. (The escaping sequence could be less intrusive as well, your call - and it also would help getting those symbols input into the code to start with) On Mon, 15 Jul 2019 at 10:47, Paul Moore <p.f.moore@gmail.com> wrote:

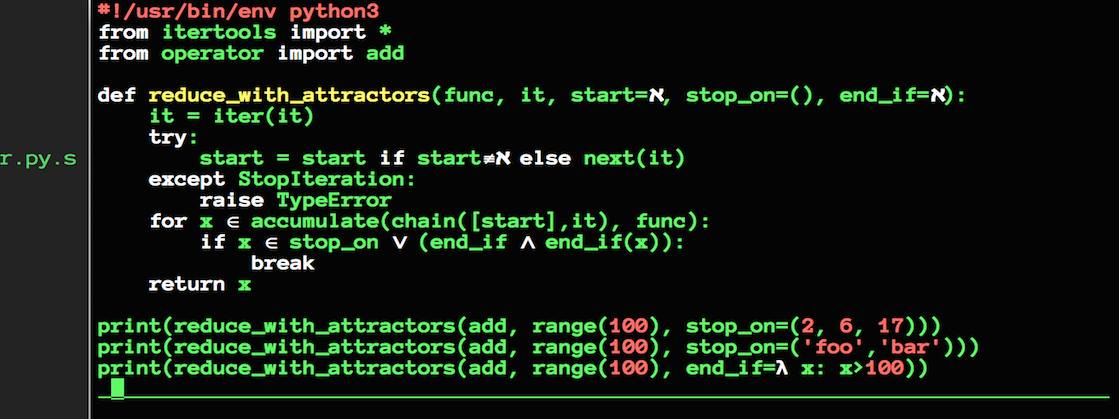
It's easy, just use vim! (with conceal plugin). I haven't changed anything other than keywords and built-ins, but the plugin is happy to replace any other sequence or pattern. On Mon, Jul 15, 2019 at 9:26 AM Joao S. O. Bueno <jsbueno@python.org.br> wrote:
-- Keeping medicines from the bloodstreams of the sick; food from the bellies of the hungry; books from the hands of the uneducated; technology from the underdeveloped; and putting advocates of freedom in prisons. Intellectual property is to the 21st century what the slave trade was to the 16th.
{kind=link}
On 7/15/2019 7:34 AM, Adrien Ricocotam wrote:
You can use a subset of unicode for identifiers. See https://www.python.org/dev/peps/pep-3131/ and https://docs.python.org/3/reference/lexical_analysis.html#identifiers Eric
On 7/15/2019 7:43 AM, Adrien Ricocotam wrote:
Correct.
What about extending it ?
The PEP has a rationale about why it works like it does. If you want to extend it, you should be prepared to address the issues in the PEP. Your proposal would need to become a PEP itself. Eric
On Jul 15, 2019, at 04:43, Adrien Ricocotam <ricocotam@gmail.com> wrote:
I’m pretty sure that the docs explain that the subset of characters that Python allows in identifiers is exactly the one Unicode recommends that languages allow in identifiers (except possibly in the lowest 127 characters, where any character allowed in Python 2.x is still allowed in 3.x, even if Unicode says otherwise). This makes Python compatible with a whole lot of other languages, and language-agnostic tools and protocols that have similar notions of “identifier”. And it means Python can leave all the bikeshedding arguments to the Unicode committee instead of having to hash out the same arguments here. And it means Python automatically stays in sync with Unicode as they add new identifier characters just by upgrading to the newer version of Unicode, instead of having to go over the whole set of new characters each time to decide which ones should be identifiers.
On 15/07/2019 12:34, Adrien Ricocotam wrote:
it could also be nice to use emojis for some variables
For values of "nice" I personally find horrifying :-) Seriously though, the PEP defines valid characters for names by their unicode categories (plus a few special cases for backward compatibility). You'll have a stronger argument if you can show extra categories that should be allowed. (I'm using the term "character" loosely, don't all start!) -- Rhodri James *-* Kynesim Ltd
On Mon, Jul 15, 2019 at 01:34:02PM +0200, Adrien Ricocotam wrote:
We've been able to do that since about 2007. https://www.python.org/dev/peps/pep-3131/ In the future, before making suggestions for new features, you should do some research into what is already possible, and whether it has already been suggested before: https://duckduckgo.com/?q=python+unicode+identifiers
it could also be nice to use emojis for some variables.
I doubt that. Variable names should be meanigful, not "smiley face" or "eggplant".
I don't see any bad consequences
(1) For many people, it is very difficult to type non-ASCII identifiers in their editors. (2) For many people, support for many non-ASCII identifiers is poor. They will see a series of boxes, something like this: = .(, ) (3) Unicode allows us to play games like this: py> А = 1 py> print(А) 1 py> A = 2 py> print(A) 2 py> Α = 3 py> print(Α) 3 py> Α - 1 == А + 1 True Do you see what I did there? (4) Not only are confusables, well, confusing, but they can be used for phishing and other attacks. http://unicode.org/reports/tr36/tr36-8.html Of course there are ASCII confusables too, such as O 0 and I l (depending on the font you use) but Unicode adds hundreds of confusables. -- Steven
On 7/15/19 8:54 AM, Steven D'Aprano wrote:
= .(, )
I call foul. At least tentatively. For the moment. http://www.unicode.org/reports/tr31/ and http://www.unicode.org/reports/tr39/ specifically exclude private use characters, like U+E24C, from identifiers. And that said, while I am in favor of using unicode *as appropriate*, I agree that some of the drawbacks outweigh some of the benefits. I can enter all code points with my keyboard, but until there's better display support and fonts designed to disambiguate the confusables, I'll use non-ASCII identifiers very carefully. As has happened before, on this list, I am happy to learn otherwise. Dan
On Mon, 15 Jul 2019 at 14:33, Dan Sommers <2QdxY4RzWzUUiLuE@potatochowder.com> wrote:
That was a demo (he used private area characters to ensure getting the square box substitute character). The point is that someone with the wrong font installed, or a limited terminal app, can get this sort of output with entirely legal characters - and anyway the comment was made to explain why *extending* the list of allowed characters was bad (so what's legal right now is not relevant). On Mon, 15 Jul 2019 at 14:13, Adrien Ricocotam <ricocotam@gmail.com> wrote:
We can already do this is already (https://github.com/satwikkansal/wtfpython#-skipping-lines) so it's not a problem to me. It is a problem but not related to unicode.
That's *exactly* the issue of confusable characters, which is a Unicode issue. So I don't see how you can say it's "not related to Unicode". It's not directly related to *changing* which Unicode characters are allowed in identifiers - that much is true (at least partially, it's quite possible that changing the list would result in having more confusables, so increasing the risk) - but that's not what you claimed. Paul
Adrien - please take note that since you already wrote about "everybody could update their environment and editors" to support unicode, things like what you want (emojis in identifiers) can be supported at programming editor (and plug-ins and extensions for those) level - without impairing anyone else from working on your codebase. You can just work on an extension for your favorite editor that would transform certain escaped sequences into proper emojis. If these escapes are themselves valid identifiers, there is no stopping you and whatever enthusiast comunity you can raise from having fun with the looks of "pyemojicode", and that wold still allow people outside that community to interoperate with your code, and all of the tools that use the static source would still work. So, all you need is an extension to replace, at display time things liks EMO_fire_ -> 🔥 EMO_heart -> 🖤 And so on. With a browser extension, or a site that acts as a proxy to code hosting like github/bitbucket, enthusiasts could even see these characters in internet listings. (The escaping sequence could be less intrusive as well, your call - and it also would help getting those symbols input into the code to start with) On Mon, 15 Jul 2019 at 10:47, Paul Moore <p.f.moore@gmail.com> wrote:
It's easy, just use vim! (with conceal plugin). I haven't changed anything other than keywords and built-ins, but the plugin is happy to replace any other sequence or pattern. On Mon, Jul 15, 2019 at 9:26 AM Joao S. O. Bueno <jsbueno@python.org.br> wrote:
-- Keeping medicines from the bloodstreams of the sick; food from the bellies of the hungry; books from the hands of the uneducated; technology from the underdeveloped; and putting advocates of freedom in prisons. Intellectual property is to the 21st century what the slave trade was to the 16th.
participants (10)
-
 Adrien Ricocotam
Adrien Ricocotam -
 Andrew Barnert
Andrew Barnert -
 Chris Angelico
Chris Angelico -
 Dan Sommers
Dan Sommers -
 David Mertz
David Mertz -
 Eric V. Smith
Eric V. Smith -
 Joao S. O. Bueno
Joao S. O. Bueno -
 Paul Moore
Paul Moore -
 Rhodri James
Rhodri James -
 Steven D'Aprano
Steven D'Aprano