Optional keyword arguments

Many a python programmer have tired to see code written like: def bar(a1, a2, options=None): if options is None: options = {} ... # rest of function syntax if argument is not passed, evaluate {} and store to options def foo(options:={}): pass syntax if argument is not passed or is None, evaluate {} and store to options* def foo(options?={}): pass The Zen of Python states "there shouldn't be two ways to do the same thing." Thus, only one of ":=" or "?=" should be adopted. They should be evalued on: - Which encourages writing better code? - Which catches mistakes easier? Do we want to encourage callers to pass None to indicate default arguments? spam = { data: True } if arg else None bar(a1, a2, param=spam) versus bar(a1, a2, { data: True }) if arg else bar(a1, a2) versus _ = foo.curry(a1, a2) _({data: True}) if arg else _(a1, a2) Since Python is a strongly typed language, it seems more consistent to me that this code should throw an error: def getoptions(): ... # code to get options # whoops! missing return statement #return os.environ foo(a1, a2, param=getoptions()) := should be adopted because it catches mistakes more quickly. On the other hand, ?= replaces the "if kwarg is not None: kwarg = ..." idiom. (I propose adopting only ":=". I show "?=" as a strawman.)

Certainly the way default arguments work with mutable types is not the most intuitive and I think your complaint has some merit. However how would you define the following to work: def foo(): cons = [set(), [], (),] funs = [] for ds in cons: def g(arg:=ds): return arg funs.append(g) return funs How would you evaluate "ds" in the context of the call? If it were to have the same observable behavior as def g(arg=ds) except that you would get "fresh" reference on each invocation you would get the following: assert [f() for f in foo()] == [set(), [], ()] Note it cannot be a simple syntactic transform because: class _MISSING: pass def foo(): cons = [set(), [], (),] funs = [] for ds in cons: def g(arg=_MISSING): if arg is _MISSING: arg = eval('ds') # equivalent to arg = ds so does not produce a fresh reference return arg funs.append(g) return funs assert [f() for f in foo()] == [(), (), ()] Granted the way closures work (especially in the context of loops) is also a pretty unintuitive, but stands as a barrier to easily implementing your desired behavior. And even if that wasn't the case we still have the issue that eval('ds') doesn't give you a fresh reference. Would it implicitly deepcopy ds? e.g.: class _MISSING: pass def build_g(default): def g(arg=_MISSING): if arg is _MISSING: arg = deepcopy(default) return arg return g def foo(): cons = [set(), [], (),] funs = [] for ds in cons: g = build_g(ds) funs.append(g) return funs What if ds doesn't implement __deepcopy__? On Mon, May 18, 2020 at 7:11 AM Richard Damon <Richard@damon-family.org> wrote:

I have already replied to the OP and to the list, but there seems to be a problem with my posts getting through, so let me try again. Apologies if you see this twice: To strip at most 1 character from the end: txt[:-1] + txt[-1:].rstrip(chars) To strip at most N characters: txt[:-N] + txt[-N:].rstrip(chars) Rob Cliffe On 18/05/2020 19:32, Caleb Donovick wrote:

On Mon, May 18, 2020 at 11:32:29AM -0700, Caleb Donovick wrote:
Certainly the way default arguments work with mutable types is not the most intuitive
Neither is the alternative. def function(arg=calculate_default_value()): "What do you mean that extremely expensive calculation is performed on every function call?" "What do you mean, my default value can change from one call to the next, if the ennvironment changes?" Besides, there are at least two distinct semantics of late-binding for default values, and I guarantee that which ever one we pick, somebody is going to complain that it's the wrong one and "not intuitive". - late-bound defaults are closures, like nested functions; - late-bound defaults aren't closures, but like global lookups. Trying to base programming semantics on "intuition" is a losing prospect, because people's intuition depends so critically on their level of knowledge. To me, it is intuitively obvious that of course function defaults use early binding. Function definitions are executable statements, which implies that the default is evaluated at the same time the `def` is executed, not when the function is called. If you can't have a choice between early and late binding in a language, the sensible choice is to use early binding: - early binding is easier to implement and more efficient; - given early binding at the language level, providing late binding semantics in the function is trivial; - but given late binding at the language level, providing early binding semantics in the function is horrible. So if you asked me, I would say that early binding is the obvious, intuitive choice for function defaults. I've worked with people who insist that early binding is the "intuitive" choice in one context, and then insist that early binding is totally confusing and late binding is the "intuitive" choice in another context. And they don't like having their own words quoted back at them *wink* -- Steven
Thank you for raising a good point. I think we should ban referencing variables not in the nearest outer enclosing scope until best practices regarding closures emerge. For example: global_var = 5 class A: # not ok: def foo(a:=global_var): pass class_var = global_var # ok: def foo(a:=class_var): pass for a in [1, 2, 3]: # not ok: def callback(a:=a): pass local = a # ok: def callback2(a:=local): pass This way, the design space is kept open.

On Wed, May 20, 2020 at 10:19 PM James Lu <jamtlu@gmail.com> wrote:
Another extremely plausible interpretation is that the expression is evaluated inside the function itself. def frobnicate(stuff, start=0, end=len(stuff)): ... I don't think you can punt on this one. The semantics are going to need to be well-defined from the start. ChrisA
On Mon, May 18, 2020 at 01:06:22PM -0000, James Lu wrote:
"There should be one-- and preferably only one --obvious way to do it."
Yes? "There should be one" does not mean the same thing as "there shouldn't be two". "There should be one qualified pilot in the cockpit of the plane at all times during the flight" is not the same as "There should not be two qualified pilots in the cockpit". -- Steven

I think only using the first third of the quote makes your argument too terse Steven. To include the second part: "There should be one-- and preferably only one" which implies "It is preferable there is exactly one qualified pilot in the cockpit", and we arrive (if abbreviated) at what James said. However, to use the full quote as inspiration: "There must be at least one qualified pilot in the cockpit and there should not be a tie for seniority" and it flips again! Regardless Steven, I don't think it matters (except for setting the record straight[1]), they are not essential to his proposal? He uses this idea in his argument to say we should adopt *one* of := and ?=. Firstly, I think his application there is correct (if you assume at least one would be adopted, I think only one would be) but secondly I think his email has a strong air of false dichotomy: Python could well adopt a different solution or no solution at all and those are perfectly acceptable outcomes and I would advocate "no solution" as I prefer it over his two proposals. [1] https://xkcd.com/386/ On Tue, 19 May 2020 at 01:33, Steven D'Aprano <steve@pearwood.info> wrote:
The "if arg is None: arg = " pattern occurs in the standard library eighty-five (85) times. This command was used to find the count: ~/cpython/Lib$ perl -wln -e "/(?s)^(\s*)[^\n]if ([a-zA-Z_]+) is None:(\n)?\s+\2\s*=\s*/s and print" **

On 20/05/2020 02:13, James Lu wrote:
The "if arg is None: arg = " pattern occurs in the standard library eighty-five (85) times.
You say that like it's a bad thing. Given that it's completely clear what's going on -- you don't need to understand or guess at the syntax -- I'm really not seeing the problem here. -- Rhodri James *-* Kynesim Ltd
On Wed, May 20, 2020 at 12:23 PM Rob Cliffe via Python-ideas <python-ideas@python.org> wrote:
It would be a major breaking change if ALL default arguments were late-evaluated. Errors wouldn't be caught till later, performance would suffer, and semantics would change. More plausible would be to have a syntactic adornment that triggers this, making it completely opt-in. The semantics would be subtly different from the None variety, being more like the similar variant involving a sentinel: def spam(x, y, ham=object()): if ham is spam.__defaults__[-1]: ham = {} But with actual language support, the sentinel object wouldn't be visible anywhere, and anything involving docstrings would show the original text used, which would be WAY more helpful. This has been proposed frequently and never gone far, and I think it's because nobody can settle on a really good syntax for it. Consider: # Looks like an old Py2 repr def spam(x, y, ham=`{}`): # Way too magical, although it parses currently and might # be done with the help of a magic built-in def spam(x, y, ham=LATE%{}): # wut? def spam(x, y, ham=>{}): # even worse def spam(x, y, ham=->{}): etc etc etc. There are lots of bad syntaxes and very few that have any merit. I'd love to have this as a feature, though. ChrisA
On Wed, May 20, 2020 at 07:56:32PM +1000, Chris Angelico wrote:
What I really need is an extra 12 hours a day, and a lot fewer distractions and a lot more Round Tuits :-) I may send you a draft over the weekend for comments. -- Steven
On Wed, May 20, 2020 at 8:04 PM Steven D'Aprano <steve@pearwood.info> wrote:
Ahh, don't we all...
I may send you a draft over the weekend for comments.
Cool. If you do, I'll comment. If not, I won't. :) ChrisA

On Wed, May 20, 2020 at 5:35 AM Eric V. Smith <eric@trueblade.com> wrote:
What's wrong with confusion with the walrus operator? - If you are confused and don't know what walrus operator is, you google it and find that in a function header it means late assignment. - If you are confused and think it's referring to the walrus operator's use for inline variable assignment - well so what - it is being used as assignment here! - If you are confused and think := is binding at import-time rather than call-time - well you already are a somewhat advanced python user to be thinking about that and the use of a different syntax to bind the argument should trigger you to google it.

On 5/20/2020 9:48 AM, Peter O'Connor wrote:
I think every proposal, especially for syntax and operators, should be judged on how confusing it is to new and experienced users alike. In my mind, using the walrus operator for early binding utterly fails that test, but of course other people will have different opinions. The fact that operators are notoriously difficult to search for doesn't help any. Eric
On Thu, May 21, 2020 at 12:11 AM Eric V. Smith <eric@trueblade.com> wrote:
The fact that operators are notoriously difficult to search for doesn't help any.
The fact that people STILL think that operators are difficult to search for doesn't help either. Google for "python :=" and PEP 572 is the first hit. DuckDuckGo for "python :=" didn't give any good results; my next thought was "python := operator" which didn't do much good. For most of the common operators, you'd get it from "python operator precedence", but unfortunately DDG is showing Python 2.7 search results above Python 3, so you'd have to go down to the page eighth in the search results, then browse the table. But when you do get there, it's not too hard to glance over the table, find that ":=" is an "assignment expression" and go from there. Bing for "python :=" has what looks like three paid search results, and then the first real result is Stack Overflow asking what the colon equal (:=) operator means, and even though the question is older than PEP 572, the accepted answer has been updated to link to it. Yandex failed to find the := operator specifically, but as with DDG, I had to go for "python operator precedence". Fortunately, it did give the Py3 page as the first hit. I tried a few of the more obscure search engines, and most of them seem to give the same results as one of the above. (I suspect quite a few of them get their results from one of the big ones anyway.) So two very popular search engines (Google and Bing) give excellent results straight away, and everything can at least find the operator precedence table, which is a good way to get started. I have to penalize DuckDuckGo a bit for not putting current version results at the top, but even then, it WAS on the first page, and of course you can always say "python 3 operator precedence". Operators ARE searchable. ChrisA
On 5/20/2020 11:26 AM, Chris Angelico wrote:
I think you meant ":= is searchable using half search engines I tried, both of which are very popular". Which might be good enough for this particular proposal, but I disagree. I couldn't get anywhere with single character operators and Google. So you haven't shaken my faith in my assertion. Eric
On Thu, May 21, 2020 at 2:27 AM Eric V. Smith <eric@trueblade.com> wrote:
Actually ":= is searchable using half the search engines I tried, and with the other half, 'python operators' gets a page with all operators, from which you can get the info you need". All the search engines I tried DID get the results I wanted; some more easily than others, but all got there.
I couldn't get anywhere with single character operators and Google. So you haven't shaken my faith in my assertion.
Hmm, good point. You can Google for "python @=" but not "python @". Strange. But you can still just look for all operators and go from there. And there are some word-based things that are also hard to search for, so at that point it becomes a wash. ChrisA

On 20 May 2020, at 16:08, Eric V. Smith <eric@trueblade.com> wrote:
I think every proposal, especially for syntax and operators, should be judged on how confusing it is to new and experienced users alike. In my mind, using the walrus operator for early binding utterly fails that test, but of course other people will have different opinions.
I’d like to +1 on this one, not to mention that the walrus operator is still largely not-too-well-known, and this IMHO would add to the confusion; utterly is the word indeed :)
I don't see myself using := for a few years, because support for Python 3.8 is not widespread yet among PyPy. However, that doesn't mean I oppose evolving the language further so that down the line when Python 3.10 is ready, I'll have juicy new features to use.
"<:" Does not give the user any intuition about what it does. "<~" Ok, but same problems as "<:" and precludes the use of "<~~" due to Python's parser. "::" Could be confused with Haskell's type declaration operator. If we want to avoid confusion with the walrus operator, "options!?=..." is a decent alternative. It can be remembered as "if not there? equal to" [! there? =].


Have you seen PEP 505? https://www.python.org/dev/peps/pep-0505/ I'm still praying they add "??=" every time I need it. Maybe if someone proposed just that operator, it would go a long way towards simplifying code without resulting in endless debates? Best, Neil On Sunday, May 17, 2020 at 3:23:59 PM UTC-4, James Lu wrote:
On Sun, May 17, 2020 at 07:17:00PM -0000, James Lu wrote:
Thus, only one of ":=" or "?=" should be adopted. They should be evalued on:
That does not logically follow. Even if we accept your idea that we should have special syntax for late-binding of function defaults, and that's not clear that we should, it does not follow that the only two possible choices are `:=` and `?=`. They might be your preferred choice, but that doesn't mean that "only one of ... should be adopted". We could instead: - choose something else; - or choose nothing at all and stick to the status quo. In any case, we should rule out `:=` of contention, because it already has a meaning as the "walrus operator" for assignment expressions, which makes it legal in function defaults: def func(x=(a:=expression), y=a+1): This is already valid in 3.8, so we should forget about overloading `:=` with a second meaning.
Do we want to encourage callers to pass None to indicate default arguments?
That isn't up to us, that's up the writer of the function being called. There is a thirty year tradition of functions using None for default arguments, that's not going to go away. Neither are we going to force function writers to accept None as a default. So the way functions can be called will depend partially on the function itself, and partially on the caller's personal choice for how they prefer to handle defaults.
Being strongly typed, or weakly typed, has nothing to do with return statements. In Python, there is a 30 year tradition of being permitted to leave out the return statement in functions or methods intended to be used as "procedures" that operate by side-effect with no meaningful return value. We aren't going to break thousands of programs by making it an error to leave out the return statement. -- Steven
This is already valid in 3.8, so we should forget about overloading := with a second meaning.
def func(x=(a:=expression), y=a+1): def func(x:=options): These two syntaxes do not conflict with each other.
If it wasn't clear originally, I meant to ask, what is the best practice that should be encouraged? And we're not 'forcing' anyone, we're just making an easier syntax for doing something. There's a thirty year tradition of doing that because there's no terser way to do it. Out of the 85 instances I found in the STL, only 5 instances used "if arg is None: arg = " in one line. The others used a two-line form. Having to read 2 lines to understand a common language pattern is inefficient.
On 20/05/2020 23:20, James Lu wrote:
There's a thirty year tradition of doing that because there's no terser way to do it.
Terser does not mean better. In my experience, terser code is often harder to comprehend, particularly when you are talking about squashing a couple of lines together like this. -- Rhodri James *-* Kynesim Ltd
On Thu, May 21, 2020 at 9:58 PM Rhodri James <rhodri@kynesim.co.uk> wrote:
Except when it's more expressive. Imagine if Python didn't have ANY argument defaults, merely permitted you to make arguments optional: def int(x, ?base): if base is UNSET: base = 10 ... Would you agree that simply writing "base=10" is better? You're right that terser does not ALWAYS mean better, but "more expressive" often compasses both better and terser. Terser definitely does not mean worse. ChrisA

On Thu, May 21, 2020 at 12:27 AM James Lu <jamtlu@gmail.com> wrote:
Technically no, but there is potential to confuse beginners. What about: def func(x=:options): or a more realistic example: def func(options=:{}): It still looks like `func(x=<default>)` but the `<default>` starts with a modifier `:` to say 'this is evaluated each time'. `:<expression>` can loosely be thought of as a shorthand for `lambda: <expression>` where said lambda function is called each time the def function is called, although it probably wouldn't actually work that way. One problem is that this conflicts with some other possible syntaxes that some people might want. For example I think `:<expression>` has already been proposed precisely as a shorthand for `lambda: <expression>` in general. Some might also want `:name` to mean some kind of keyword object like in Clojure. Personally I think the best way forward on this would be to accept PEP 505. It wouldn't solve this particular problem in the most concise way but it would be pretty good and would be more broadly useful. I see the PEP is 'deferred' - what does that mean exactly? What possible paths are there to acceptance? Is the rationale for deferral documented anywhere? Are people supposed to just read all the old discussion(s) and add more posts?

Is `?=` an operator? One could define `a ?= b` as `if a is None: a = b` (which is similar to make's operator, for example). Compare: def func(arg, option=None): option ?= expr #impl instead of: def func(arg, option=None): if option is None: option = expr #impl def func(arg, option=None): if option is None: option = expr #impl def func(arg, option=None): option = expr if option is None else option #impl def func(arg, option=None): option = option if option is not None else expr #impl or the proposed: def func(arg, option?=expr): #impl One could argue that the OP proposal is cleaner, but it adds *another* special notation on function definition. On performance, this would have tobe evaluated most likely upon entering the call. With the `if` guards or a hypothetical `?=` assignment, the programmer can better control execution (other arguments and/or options may render the test irrelevant). The great disadvantage of the `if` guard is a line of screen and an identation level, (which reminds me of PEP 572 rationale). I don't really like this `?=` assignment aesthetically, but I have written code that would look cleaner with it (though beauty is the eye of the beholder). Implementing only this operator would be at least simpler than both OP proposal and full PEP 505 (see also Neil Girdhar post above).
On 22/05/2020 02:10, Tiago Illipronti Girardi wrote:
Is `?=` an operator? One could define `a ?= b` as `if a is None: a = b` (which is similar to make's operator, for example).
PEP 505 (https://www.python.org/dev/peps/pep-0505/) prefers "??=". That's a discussion that comes back now and again, but doesn't seem to get much traction one way or another. -- Rhodri James *-* Kynesim Ltd
On Thu, May 21, 2020 at 2:50 PM Alex Hall <alex.mojaki@gmail.com> wrote:
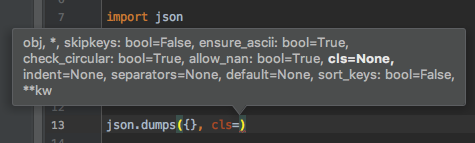
Having thought about this problem a bit more, I'm now less sure of this stance. I think there's a decent benefit to being able to specify a late/lazy default in the signature that goes beyond being concise, and I don't think anyone has mentioned it. Signatures are an important source of information beyond their obvious essential need. They're essentially documentation - often the first bit of documentation that human readers look at when looking up a function, and often the only documentation that automated tools can use. And defaults are an important part of that documentation. Take a look at the official documentation for these callables and their parameters which default to None: https://docs.python.org/3/library/collections.html#collections.ChainMap.new_... https://docs.python.org/3/library/logging.handlers.html#logging.StreamHandle... https://docs.python.org/3/library/json.html#json.dump (in particular the `cls` parameter) (we may not be able to change these signatures due to compatibility, but they should still demonstrate the point) In all cases it's not immediately clear what the actual default value is, or even what kind of object is meant to be passed to that parameter. You simply have to read through the documentation, which is quite verbose and not that easy to skim through. That's not the fault of the documentation - it could perhaps be improved, but it's not easy. It's just English (or any human language) is not very efficient here. Imagine how much easier it would be to mentally parse the documentation if the signatures were: ``` ChainMap.new_child(m={}) StreamHandler(stream=sys.stderr) json.dump(..., cls=JSONEncoder, ...) ``` In the case of json.dump, I don't know why that isn't already the signature, does anyone know? In the other cases there are good reasons those can't be the actual signatures, so imagine instead the ideal syntax for late binding. The point is that the signature now conveys the default as well as the type of the parameter, and there's less need to read through documentation. Conversely you can probably also write less documentation, or remove some existing clutter in an upgrade. There's a similar benefit if the author hasn't provided any documentation at all - it's not nice to have to read through the source of a function looking for `if m is None: m = {}`. The signature and its defaults are also helpful when you're not looking at documentation or source code at all. For example, PyCharm lets me press a key combination to see the signature of the current function, highlighting the parameter the caret is on. Here is what it looks like for `json.dumps`: [image: Screen Shot 2020-05-22 at 21.32.21.png] That's not very helpful! Here's the same for logging.StreamHandler: [image: Screen Shot 2020-05-22 at 21.33.08.png] That's sort of better, but mentally parsing `Optional[IO[str]]=...` might just slow me down more than it helps. PyCharm also uses defaults for rudimentary type checking. For example, if you set `{}` as a default value, it assumes that parameter must be a dict, and warns you if you enter something else: [image: Screen Shot 2020-05-22 at 21.35.07.png] Of course it also warns that the parameter has a mutable default, which this proposal could solve.
{kind=link}
{kind=link}
{kind=link}

Alex Hall writes:
In all cases it's not immediately clear what the actual default value is, or even what kind of object is meant to be passed to that parameter.
I agree with the basic principle, but I'm not sure this is a very strong argument. First, if you want to indicate what the type of the actual argument should be, we have annotations for that exact purpose. (Granted, these don't deal with situations like "should be nonempty," see below.) Second, in many cases the default value corresponding to None is the obvious mutable falsey: an empty dict or list or whatever. Viz:
Assuming that in many other cases we could fix the signature in this way, are the leftovers like StreamHandler important enough to justify a syntax change? I have no opinion on that, it's a real question.
The point is that the signature now conveys the default as well as the type of the parameter,
Except that it doesn't convey the type in a Pythonic way. How much of the API of dict must 'm' provide to be acceptable to ChainMap? Are there any optional APIs (i.e., APIs that dict doesn't have but ChainMap would use if available) that must have correct semantics or ChainMap goes "BOOM!"? Are non-empty mappings acceptable?! This doesn't change my lack of opinion. :-) Clearly, it's useful to know that dicts (probably including non-empty ones ;-) are acceptable to new_child, that sys.std* output streams are (probably ;-) acceptable to StreamHandler, and that cls should (probably ;-) encode Python data to JSON. Those are all good enough bets that I would take them. But it isn't as big a help as it looks on first sight, in particular to somebody who has a partially duck-type-compatible object they would like to use.
On Sat, May 23, 2020 at 2:52 PM Stephen J. Turnbull < turnbull.stephen.fw@u.tsukuba.ac.jp> wrote:
Yes, but many people can't be bothered to write annotations. This change would mean that I get extra type information even when using a function written by a programmer making as little effort as they can. Besides that, type annotations are often not easy to read - see the StreamHandler screenshot. An example of an acceptable value is additionally helpful.
A programmer making the least effort wouldn't update themselves on the grammar: the patch would be useless.
On Sat, May 23, 2020 at 11:34 PM Tiago Illipronti Girardi < tiagoigirardi@gmail.com> wrote:
A programmer making the least effort wouldn't update themselves on the grammar: the patch would be useless.
This is taking my words a bit far. Typing annotations are tedious and have to be done every time you want to provide typing information. It's easy to just not write them. I'd be surprised if anyone here *always* annotates every function they write. Learning a bit of new syntax is something you do once or twice. Plus it's hard to avoid learning it, especially if you come across the syntax in someone else's code. And once you know about it, it's the natural lazy option over `if foo is None: foo = {}`.
On Thu, May 21, 2020 at 02:50:00PM +0200, Alex Hall wrote:
Forget beginners, I know that will confuse me! Technically, *yes*, they do conflict. Ask yourself what the walrus operator `:=` means in Python 3.8, and you have a single answer: - "it's like `=` only it works as an operator". Now ask yourself what the walrus operator means if James' proposal is accepted. The answer becomes: - "well, that depends on where you see it..." or: - "in this context, it's like `=` only it works as an operator" - "but in this context, it changes the meaning of assignment completely to something very different to how the `=` works everywhere else" That's certainly a conflict. This isn't necessarily a deadly objection. For example, the `@` symbol in decorator syntax and the `@` symbol in expressions likewise conflicts: @decorate(spam @ eggs) def aardvark(): ... but both uses of the `@` symbol well and truly proved their usefulness. Whereas in this case: - the walrus operator is still new and controversial; - James' proposed `:=` in signatures hasn't proven it's usefulness.
What about:
def func(x=:options):
As a beginner, it took me months to remember to use colons in dict displays instead of equals signs, and they are two extremely common operations that beginners learn from practically Day 1. Even now, 20 years later, I still occasionally make that error. (Especially if I'm coding late at night.) You're proposing to take one uncommon operator, `:=`, and flip the order of the symbols to `=:`, as a beginner-friendly way to avoid confusion. As if people don't get confused enough by similar looking and sounding things that differ only in slight order. To steal shamelessly from the stand-up comedian Brian Regan: I before E except after C, or when sounding like A like in NEIGHBOUR and WEIGH, on weekends and holidays, and all throughout May, you'll be wrong no matter what you say.
or a more realistic example:
def func(options=:{}):
Add annotations and walrus operator: def flummox(options:dict=:(a:={x: None})): and we now have *five* distinct meanings for a colon in one line.
Personally I think the best way forward on this would be to accept PEP 505.
For the benefit of those reading this who haven't memorised all multiple-hundreds of PEPs by ID, that's the proposal to add None-aware operators to the language so we can change code like: if arg is None: arg = expression into arg ??= expression In this thread, there has been hardly any mention of the times where None is a legitimate value for the argument, and so the sentinal needs to be something else. I have written this many times: _MISSING = object() def func(arg=_MISSING): if arg is _MISSING: arg = expression Null-coalescing operators will help in only a subset of cases where we want late-binding of default arguments. -- Steven
On Sat, May 23, 2020 at 2:37 AM Steven D'Aprano <steve@pearwood.info> wrote:
OK, let's forget the colon. The point is just to have some kind of 'modifier' on the default value to say 'this is evaluated on each function call', while still having something that looks like `arg=<default>`. Maybe something like: def func(options=from {}):

On Sun, May 24, 2020 at 12:36 PM Alex Hall <alex.mojaki@gmail.com> wrote:
I worry so very little about this issue of mutable defaults that this discussion has trouble interesting me much. It's a speed bump for beginners, sure, but it's also sometimes a sort of nice (but admittedly hackish) way of adding something statefull to a function without making a class. On the other hand, I mostly thought it was cool before generators even existed; nowadays, a generator is more often a useful way to have a "stateful function" (yes, I know there are some differences; but a lot of overlap). The pattern: def fun(..., option=None): if option is None: option = something_else Becomes second nature very quickly. Once you learn it, you know it. A line of two of code isn't a big deal. But this discussion DOES remind me of something much more general that I've wanted for a long time, and that has had long discussion threads at various times. A general `deferred` or `delayed` (or other spellign) construct for language-wide delayed computation would be cool. It would also require rethinking a whole lot of corners. I think it would address this mutable default, but it would also do a thousand other useful things. Much of the inspiration comes from Dask. There we can write code like this simple one from its documentation: output = []for x in data: a = delayed(inc)(x) b = delayed(double)(x) c = delayed(add)(a, b) output.append(c) total = delayed(sum)(output) However, in that library, we need to do a final `total.compute()` to get back to actual evaluation. That feels like a minor wart, although within that library it has a purpose. What I'd rather in a hypothetical future Python is that "normal" operations without this new `delayed` keyword would implicitly call the .compute(). But things like operators or most function calls wouldn't raise an exception when they try to combine DelayedType objects with concrete things, but rather concretize them and then decide if the types were right. As syntax, I presume this would be something like: output = [] for x in data: a = delayed inc(x) b = delayed double(x) c = delayed add(a, b) output.append(c) total = sum(outputs) # concrete answer here. Obviously the simple example of adding scalars isn't worth the delay thing. But if those were expensive operations that built up a call graph, it could be useful laziness. Or for example: total = sum(outputs[:1_000_000) # larger list, don't compute everything -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On Mon, May 25, 2020 at 3:42 AM David Mertz <mertz@gnosis.cx> wrote:
And it isn't entirely correct, because now None isn't a valid parameter. It's an extremely common idiom right up until it doesn't work, and you need: _SENTINEL = object() def fun(..., option=_SENTINEL): if option is _SENTINEL: option = something_else Now, try doing that for multiple parameters at once. Or in a closure. Or anything else that would make it more complicated. ChrisA

On Sun, May 24, 2020 at 12:55 PM Chris Angelico <rosuav@gmail.com> wrote:
And it isn't entirely correct, because now None isn't a valid parameter.
Which is indeed, an extremely common use case :-)
I've thought to a while that there should be a more "standard" way to so this: A NOT_SPECIFIED singleton in builtins would be pretty clear. (though I'd like to find a shorter spelling for that) BTW, though I do find it tedious to write the: if option is SOME_SENTINEL: option = something ... It's not always the case that it's a simple setting of the value to a empty mutable -- sometimes there's some more complexity there. Which is why I kind of like that it's explicit. But if we did make it simpler, I like the idea of providing a factory function, so it would be possible to do more complex things than a simple empty container of some sort. Though that factory wouldn't have access to the full function namespace, so maybe not that flexible. -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
On Mon, May 25, 2020 at 02:19:57PM -0700, Christopher Barker wrote:
Guido's time machine strikes again! We already have that "not specified" singleton in the builtins, with a nice repr. It's spelled "None". The problem is that this is an infinite regression. No matter how many levels of "Not Specified" singletons you have, there's always going to be some context where they are all legitimate values so you need one more. Think about a function like `dir()` or `vars()`, which can operate on any object, or none at all: `dir()` is not the same as `dir(None)`, so we need a second sentinel MISSING to indicate the no argument case; but now we would like to say `dir(MISSING)`, so MISSING is likewise a legitimate value, and we need a third sentinel: since None is a legit value, we need MISSING; but MISSING is also a legit value, so we need UNDEFINED; but UNDEFINED is legit, so we need ... and so on through NOT_SPECIFIED, ABSENT, OMITTED and eventually we run out of synonyms. In the specific cases of `dir` and `vars`, it is easy enough to work around this with `*args`, but there can be functions with more complex signatures where you cannot do so conveniently. Fortunately, if you have a function that needs such a second level sentinel, you probably don't care that *other* functions like `dir` don't treat it as a special sentinel. It's only special to your library or application, not special everywhere, so the regression stops after one level. But that wouldn't be the case if it were a builtin. For the basic cases, using None is sufficient; if it's not, rolling your own is actually better than having a standard builtin, because: - it is specific to your library, you don't have to care about how other libraries might treat it (to them, it's just an arbitrary object, not a special sentinel); - you can choose whether or not to make it a public part of your library, and if so, what behaviour to give it; - and most importantly, you don't have to bike-shed the name and repr with the entire Python-Ideas mailing list *wink* -- Steven
On Mon, May 25, 2020 at 6:37 PM Steven D'Aprano <steve@pearwood.info> wrote:
A NOT_SPECIFIED singleton in builtins would be pretty clear.
Guido's time machine strikes again! We already have that "not specified" singleton in the builtins, with a nice repr. It's spelled "None".
well, yes and no. this conversation was in the context of "None" works fine most of the time.
well, those are pretty special cases -- they are about introspection -- most functions do not act on the objects themselves in such a generic ways. In the specific cases of `dir` and `vars`, it is easy enough to work
around this with `*args`, but there can be functions with more complex signatures where you cannot do so conveniently.
I've certainly had examples when I wanted to make a distinction between None and not specified, that did not have anything to do with introspecting the inputs.
It would mean "not specified" -- a nice way to combine keyword arguments with being able to be clear about it not being specified. *args can't do that. And sure, there *could* be other special cases, but it could be pretty useful anyway. The fact is that None is very heavily overloaded. I'd rather have a standard way to spell "non specified" than have every library roll their own and need to document it. Nothing would prevent folks from rolling their own if they did have a special case.
- and most importantly, you don't have to bike-shed the name and repr with the entire Python-Ideas mailing list *wink*
Now THAT is a compelling argument! -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
On Mon, May 25, 2020, 11:56 PM Christopher Barker
well, yes and no. this conversation was in the context of "None" works fine most of the time.
How many functions take None as a non-sentinel value?! How many of that tiny numbers do so only because they are poorly designed. None already is an excellent sentinel. We really don't need others. In the rare case where we really need to distinguish None from "some other sentinel" we should create our own special one. The only functions I can think of where None is appropriately non-sentinel are print(), id(), type(), and maybe a couple other oddball special ones. Seriously, can you name a function from the standard library or another popular library where None doesn't have a sentinel role as a function argument (default or not)?

Wild idea: Instead of sentinels, have a way of declaring optional arguments with no default, and a way of conditionally assigning a value to them if they are not bound. E.g. def order(eggs = 4, spam =): spam ?= Spam() Here the '?=' means "if spam is not bound, then evaluate the rhs and assign it, otherwise do nothing." -- Greg
On Tue, May 26, 2020 at 4:12 PM Greg Ewing <greg.ewing@canterbury.ac.nz> wrote:
That's interesting. I suppose the semantics would be the same as any other unbound local, then? That would actually be useful in other contexts, like where you conditionally assign in a loop, and then might not have it assigned at the end. I don't know of any current way to say "if spam is unset". It definitely needs good syntax though. The loose equals sign would be too confusing, and there's no good keyword available. It'd be kinda elegant to surround the name in square brackets: def order(eggs=4, [spam]): spam ?= Spam() but that would be confusing for other reasons. ChrisA
On 28/05/20 12:38 pm, Rob Cliffe wrote:
That clutters up the header with things that are not part of the function's signature. All the caller needs to know is that the spam argument is optional. The fact that a new Spam object is created on each call if he doesn't supply one is an implementation detail. -- Greg
On 28/05/20 7:31 pm, Chris Angelico wrote:
Is it an implementation detail that 4 will be used for eggs if it isn't passed?
That feels different to me somehow. I think it has something to do with declarative vs. procedural stuff. The default value of eggs being 4 is a static fact, but creating a new Spam object is not. To my mind, procedural code belongs in the body of the function, not in the header. -- Greg
On Thu, May 28, 2020 at 10:27:47PM +1200, Greg Ewing wrote:
Would your feeling change if we were talking about a "variables are memory locations" language, where the value 4 has to be copied into the "eggs" memory location?
To my mind, procedural code belongs in the body of the function, not in the header.
An interesting point. I would agree with it, but somehow late-bound default parameters seems to me to be an acceptable exception. But there's certainly a grey area here. Looking over some examples, I can find places where None is being used as a sentinel for what is essentially late binding defaults, but the code required to generate the default value is sufficiently complex that, even if it could be written as a single expression, I wouldn't be really happy about it being put in the function header. On the third hand, no matter how big and hairy a block of code is, if you refactor it into a function, then the late-bound default need never be more complex than a function call. -- Steven
On Thu, May 28, 2020 at 07:00:51PM +1200, Greg Ewing wrote:
I don't think you thought that through all the way. "All I need to know is that the mode argument to `open()` is optional, I don't need to know whether it defaults to read or write..." I don't think so.
Being an implementation detail implies that the functional behaviour will be identical either way, but that's incorrect under at least four circumstances: - Spam objects are mutable, e.g. lists, dicts, set; - calling Spam has side-effects; - calling Spam is particularly costly; - or if the result of calling Spam depends on the current state of the runtime environment, e.g. anything time dependent, anything to do with the state of the file system or a database, etc. The default value used by a parameter is certainly important, and one of the most common reasons I call `help(func)` is to see what the default values are. They should be in the signature, and it is an annoyance when all the signature shows is that it is None, and then I have to trawl through screenfuls of docs, or search the web, to find out what the actual default is. -- Steven
On 28/05/20 8:57 pm, Steven D'Aprano wrote:
I think we need a real example to be able to talk about this meaningfully. But I'm having trouble thinking of one. I can't remember ever writing a function with a default argument value that *has* to be mutable and *has* to have a new one created on each call *unless* the caller provided one. Anyone else have one? -- Greg
On Thu, May 28, 2020 at 12:38 PM Greg Ewing <greg.ewing@canterbury.ac.nz> wrote:
I think the most common cases are where the default is an empty list or dict. Building on my ChainMap example from before, consider this code: ``` from collections import ChainMap c1 = ChainMap().new_child() c2 = ChainMap().new_child() c1[1] = 2 print(c1[1]) c2[1] = 3 print(c1[1]) ``` Here c1 and c2 have separate new children, so modifying c2 doesn't affect c1, so '2' is printed twice. We can simulate what would happen if a new default wasn't created each time by passing the same dict to both: ``` from collections import ChainMap m = {} c1 = ChainMap().new_child(m) c2 = ChainMap().new_child(m) c1[1] = 2 print(c1[1]) c2[1] = 3 print(c1[1]) ``` Now the second print shows '3', even though we expect that value to be in c2 but not c1.

On Thursday, May 28, 2020, at 06:47 -0400, Alex Hall wrote:
That's what I thought of: an accumulator in a reduce or fold function. The default is an empty list that has to be recreated at every function call, but the caller can supply their own empty container that supports some sort of extend or add functionality.
On Thu, May 28, 2020 at 3:50 AM Alex Hall <alex.mojaki@gmail.com> wrote:
Actually, we need to one further: a default argument value that *has* to be mutable and *has* to have a new one created on each call *unless* the caller provided one ... and *has* to treat None as valid value. That I'm really having trouble with :-) -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython

On 28.05.20 17:44, Christopher Barker wrote:
That's the scenario where you'd need to create a sentinel object to take the role of None. However late binding of defaults won't save you from this. The biggest advantage, as far as I understood, is that you can specify a default (expression) as part of the function header and hence provide a meaningful example value to the users rather than just None.
On Thu, May 28, 2020 at 10:37:58PM +1200, Greg Ewing wrote:
That is too strict. The "mutable default" issue is only a subset of late binding use-cases. The value doesn't even need to be mutable, it just needs to be re-evaluated each time it is needed, not just once when the function is defined. This is by no means an exhaustive list, just a small sample of examples from the stdlib. (1) The asyncore.py module has quite a few functions that take `map=None` parameters, and then replace them with a global: if map is None: map = socket_map If the global is re-bound to a new object, then the functions should pick up the new socket_map, not keep using the old one. So this would be wrong: def poll(..., map=socket_map) (2) The cgi module: def parse(fp=None, ...): if fp is None: fp = sys.stdin Again, `fp=sys.stdin` as the parameter would be wrong; the default should be the stdin at the time the function is called, not when the function was defined. (3) code.py includes an absolute classic example of the typical mutable default problem: class InteractiveInterpreter: def __init__(self, locals=None): if locals is None: locals = {"__name__": "__console__", "__doc__": None} If locals is not passed, each instance must have its own fresh mutable namespace. (4) crypt.mksalt is another example of late-binding: def mksalt(method=None, *, rounds=None): if method is None: method = methods[0] where the global `methods` isn't even defined until after the function is created. (5) The "Example" class from doctest is another case of the mutable default issue. (That's not an example class, but a class that contains examples extracted out of the docstring. Naming is hard.) class Example: def __init__(self, ..., options=None): ... if options is None: options = {} DocTestFinder contains another one: # globs defaults to None if globs is None: if module is None: globs = {} else: globs = module.__dict__.copy() DocTestRunner is another late-binding example: # checker defaults to None self._checker = checker or OutputChecker() (6) The getpass module has: def unix_getpass(prompt='Password: ', stream=None): ... If stream is None, it tries the tty, and if that fails, stdin. The code handling the None stream is large and complex, and so might not be suitable for a late-binding default since it would be difficult to cram it all into a single expression. Other parts of the module include `stream=None` defaults as a sentinel to switch to sys.stderr. In my own code, I have examples of late-binding defaults: if vowels is None: vowels = VOWELS.get(lang, '') if rand is None: rand = random.Random() among others. -- Steven
On Thu, May 28, 2020 at 9:01 AM Greg Ewing <greg.ewing@canterbury.ac.nz> wrote:
I'm very surprised by this sentiment. The signature says that the default value for spam is an instance of Spam, namely one constructed with no arguments. That's useful information! I wrote a long post about this here: https://mail.python.org/archives/list/python-ideas@python.org/message/6TGESU... - do you have any thoughts on that? (side note - I'm just seeing now how mailman handles inline images, which is very disappointing) The fact that a new Spam object
is created on each call if he doesn't supply one is an implementation detail.
I don't think it is - knowing that the default isn't shared across calls could be quite important. But aside from that, there's only one character (`?`) which represents that detail, and that's an acceptable amount of 'clutter'. The rest (`=Spam()`) is just saying what the default value is, and we don't usually consider that clutter.

On 5/28/20 3:00 AM, Greg Ewing wrote:
But default values for arguments are really part of the responsibility for the caller, not the called function. The classic implementation would be that the caller passes all of the explicitly, and implicitly defined parameters (those with default arguments). If the language allows, you could have unpassed arguments that are passed as 'not provided' and that the called function detects and fills in with a value that isn't part of the API (which is sort of what the = None default does). This can also be done in Python with the *args and **kwargs parameters where the function can detect if something was passed there. -- Richard Damon
On 29/05/20 12:17 am, Richard Damon wrote:
I would say that's really a less-than-ideal implementation, that has the consequence of requiring information to be put in the header that doesn't strictly belong there. To my mind, the signature consists of information that a static type checker would need to verify that a call is valid. That does not include default values of arguments. The fact that a particular value is substituted if an argument is omitted is part of the behaviour of the function, not part of its signature. By putting default values in the header, we're including a tiny bit of behavioural information. By distinguishing between one-time and per-call evaluation of defaults, we're adding a bit more behavioural information. Where do we draw the line? How much of the behaviour of the function do we want to move into the header? -- Greg
Greg Ewing writes:
That's a parsimonious and reasonable definition, and the one historically used by Emacs Lisp. But the definition that says that, *in addition*, it includes the default values is also reasonable. Note that in your definition, the signature *does*, however, include the fact that defaulting (omitting) those arguments is allowed, otherwise abbreviated calls would be flagged by the static type checker. Once you've allowed defaults, I think the obvious syntactic place to put them is in the def statement, because they are useful as documentation.
Where do we draw the line? How much of the behaviour of the function do we want to move into the header?
To my mind that's a programming style question. Python has made the decision that anything that evokes a specific object (including a function or a code object) can go there.[1] For me in practice that's a good dividing line. Except that I would never put a function or code object there only to immediately evaluate it: # Just too ugly for me! def foo(x=lambda: random.randint(0,9)): x = x() # ... Footnotes: [1] I don't think this was the main intended effect of early binding of defaults, but it is an effect.
On Fri, May 29, 2020 at 3:19 AM Stephen J. Turnbull < turnbull.stephen.fw@u.tsukuba.ac.jp> wrote:
I think this is a perfect example of where my desired "delayed" (or "deferred") construct would be great. There are lots of behaviors that I have not thought through, and do not specify here. But for example: def foo(a=17, b=42,, x=delayed randint(0,9), y=delayed randrange(1,100)): if something: # The simple case is realizing a direct delayed val = concretize x elif something_else: # This line creates a call graph, not a computation z = ((y + 3) * x)**10 # Still call graph land w = a / z # Only now do computation (and decide randoms) val = concretize w - b I do not find this particularly ugly, and I think the intent is pretty clear. I chose two relatively long words, but some sort of shorter punctuation would be possible, but less intuitive to my mind. -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On Fri, May 29, 2020 at 7:05 PM David Mertz <mertz@gnosis.cx> wrote:
But if I understand correctly, a delayed value is concretized once, then the value is cached and remains concrete. So if we still have early binding, then x will only have one random value, unlike Stephen's lambda which generates a new value each time it's called.
On Fri, May 29, 2020 at 1:12 PM Alex Hall <alex.mojaki@gmail.com> wrote:
I don't think that's required by the example code I wrote. The two things that are concretized, 'x' and 'w-b', are assigned to a different name. I'm taking that as meaning "walk the call graph to produce a value" rather than "transform the underlying object". So in the code, x and y would stay permanently as a special delayed object. This is a lot like a lambda, I recognize. The difference is that the intermediate computations would look through the right-hand side and see if anything was of DeferredType. If so, the computation would become "generate the derived call graph" rather than "do numeric operations." So, for example, 'w' also is DeferredType (and always will be, although it will fall out of scope when the function ends). In some cases, generating a call graph can be arbitrarily cheaper than the actual computation; passing around the call graph rather than the result can hence be worthwhile. -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
David Mertz writes:
I think this is the correct approach, since TOOWTDI for collapsing the waveform early is "x = concretize x". TOOWDTI for preserving the call graph for a caching DeferredType doesn't exist yet. Also, Alex's interpretation makes "concretize" a name-binding operation, but I see no need for that. In another post you mention Vaex. I wonder if it's really that hard to design a language that's lazy until you need a concrete object, and it automatically gives you one. That's the way Haskell works, for example. (Making that work with existing Python semantics without explicit syntax is probably another story, but I wonder if it might be possible to do it with a minimum of explicit concretizing.)
This is a lot like a lambda, I recognize.
Except that lambda works "top-down", and it's not immediately obvious to that intermediate computations need do any looking because they could work "bottom-up". That is, DeferredType could define a full complement of dunders, all of which construct call graphs and return a corresponding DeferredType instance. This would give you full control over which subexpressions were evaluated eagerly, and which deferred. I don't think you need explicit syntax for this. The question would be do you want that level of control, or do you more often just want to defer whole expressions? (That latter would be the case if you had a expression that contained several expensive subexpressions, none of which would benefit from being cached while others are recomputed more frequently.) If the latter, I think you need syntax BTW, going back to the question of mutable defaults, it occurs to me that there is an "obvious" idiom for self-documenting sentinels for defaults that are deferred because you want a new instance each time the function is called: use the constructors! Here are some empty mutables: def foo(x=list): if x == list: x = x() def bar(x=dict): if x == dict: x = x() And here's a time-varying immutable: import datetime def baz(x=datetime.datetime.now): if x == datetime.datetime.now: x = x() I guess this fails more or less amusingly if the constructor is redefined. Of course any callable object could be the sentinel. It doesn't need to be a type or a factory function for this device to work. However, I don't see a use case for that generality. Steve

BTW, going back to the question of mutable defaults, it occurs to me
I like this a lot. And for those who are on board iwth type hinting, seems like you could indicate your intentions pretty clearly by saying something like: def foo(x: Constructing[List] = list): if x == list: x = x() A Constructing[List} being a thing whose type is supposed to be a list if provided by the user, and the final type is also list if not provided by the user.
On 29/05/2020 18:02, David Mertz wrote:
Presumably "delayed" is something that would be automatically applied to the actual parameter given, otherwise your call graphs might or might not actually be call graphs depending on how the function was called. What happens if I call "foo(y=0)" for instance? There's some risk that this will introduce a brand new gotcha, "You forgot to concretize your delayed parameter". I'm not agin it per se, but I'd need to understand the value of it better I think. Also, I'm pretty sure the average programmer will find the current if x is None: x = randint(0,9) a lot easier to understand. -- Rhodri James *-* Kynesim Ltd
On Fri, May 29, 2020 at 1:56 PM Rhodri James <rhodri@kynesim.co.uk> wrote:
I am slightly hijacking the thread. I think the "solution" to the narrow "problem" of mutable default arguments is not at all worth having. So yes, if that was the only, or even main, purpose of a hypothetical 'delayed' keyword and 'DelayedType', it would absolutely not be worthwhile. It would just happen to solve that problem as a side effect. Where I think it is valuable is the idea of letting all the normal operations work on EITHER a DelayedType or whatever type the operation would otherwise operate on. So no, `foo(y=0)` would pass in a concrete type and do greedy calculations, nothing delayed, no in-memory call graph (other than whatever is implicit in the bytecode). However, I don't really love the 'concretize' operation, which you correctly identify as a source of new bugs. I think it is necessary occasionally, and actually there is no reason it cannot be a plain old function rather than a keyword. The DelayedType object is simply some way of storing a call graph, which is has some kind of underlying representation. So the only slightly special function concretize() could just walk the graph. I think it would be better if MANY operations simply *implied* the need to concretize the call tree into a result value. The problem is, I'm really not sure exactly which operations, and probably a lot of them could have arguments in either direction. My thinking here is inspired by several data frame libraries that address this issue. * Pandas is always eager. Call a method, it does the computation right away, and usually returns the mutated data frame object (or some new similar object) to chain methods in a "fluent style." * Dask.dataframe is always lazy. It implements 95% of the Pandas API (by putting Pandas "under the hood"). You can still chain methods, but everything returns a call graph that the next method uses to build a larger call graph. The ONLY time any computation is done when you explicitly call `df.compute()` * Vaex is another data frame library that is very interesting. It is *almost always* lazy, and likewise allows chaining methods. You can easily build up call graphs behind the scenes (either by chaining or with intermediate names for "computations"). However, the RIGHT collection of methods know they need to concretize... and they just do the right thing. Of these, I've used Vaex the least by far. However, my impression is that it makes the right decisions, and users rarely need to think about what is going on behind the scenes (other than that operations on big data is darn fast). Still, "things with data frames" is more specialized than "everything one can do in Python." I'm not sure what the right answers are. For example, my first intuition is that `print(x)` is a good occasion to implicitly concretize. If you really want the underlying delayed, maybe you'd write `print(x.callgraph)` or something similar. But then, sticking in a debugging print might wind up being an expensive thing to do in that case, so... -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On 29.05.20 20:38, David Mertz wrote:
I'm still struggling to imagine a real use case which can't already be solved by generators. Usually the purpose of such computation graphs is to execute on some specialized hardware or because you want to backtrack through the graph (e.g. Tensorflow, PyTorch, etc). Dask seems to be similar in a sense that the user can choose different execution models for the graph. With generators you also don't have the problem of "concretizing" the result since any function that consumes an iterable naturally does this. If you really want to delay such a computation it's easy to write a custom type or generator function to do so and then use `next` (or even `concretize = next` beforehand).
On Fri, May 29, 2020 at 5:06 PM Dominik Vilsmeier <dominik.vilsmeier@gmx.de> wrote:
If you look for Dask presentations, you can find lots of examples, many of real world use. You want those that use dask.delayed specifically, since a lot of Dask users just use the higher-levels like dask.dataframe. But off the cuff, here's one that I don't think you can formulate as generators alone: def lazy_tree(stream, btree=BTree(), new_data=None): """Store a b-tree of results from computation and the inputs For example, a modular form of large integers, or a PRG """ for num in stream: # We expect a few million numbers to arrive result = delayed expensive_calculation(num) if result == btree.result: if new_data is None: btree.result = new_data.result btree.inits = [new_data.init] else: # Add to the inits that might produce result btree.inits.append(num) elif result < btree.value.result: btree.left = delayed lazy_tree(stream, btree.left, InitResultPair(num, result)) elif result > btree.value.result: btree.right = delayed lazy_tree(stream, btree.right, InitResultPair(num, result)) return btree I probably have some logic wrong in there since I'm doing it off the cuff without testing. And the classes BTree and InitResultPair are hypothetical. But the idea is we are partitioning on the difficult to calculate result. Multiple inits might produce that same result, but you don't know without the computation. So yes, parallelism is potentially beneficial. But also partial computation without expanding the entire tree. That could let us run a line like this to only realize a small part of the tree: btree = lazy_tree(mystream) my_node = btree.path("left/left/left/right/left/right/right/right") Obviously it is not impossible to write this without new Python semantics around delayed computation. But the scaffolding would be much more extensive. And it certainly couldn't be expressed just as a sequence of generator comprehensions. -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On Fri, May 29, 2020 at 12:36:20PM +1200, Greg Ewing wrote:
"Strictly" according to whom? Well, you obviously :-) For 30 years, Python's early bound default arguments have been part of the function signature. It's only late bound default arguments which are hidden inside the body. So you are arguing that for 30 years Python has put information into the function header that doesn't belong there. Where else would you put the parameter defaults, if not in the parameter list?
To my mind, the signature consists of information that a static type checker would need to verify that a call is valid.
A static type checker would have to know whether a parameter has a default value, even if it doesn't know what that default value is. So you are arguing that the ideal (using your word from above) function signature for, let's say, the `open` builtin should look something like this: open(file, mode= <REDACTED>, buffering= <REDACTED>, encoding= <REDACTED>, errors= <REDACTED>, newline= <REDACTED>, closefd= <REDACTED>, opener= <REDACTED>) plus type information, which I cannot be bothered showing. This ideal arrangement tells the static type checker everything it needs to know to determine whether a call is valid or not: - the name and order of the parameters; - their types (pretend I showed them); - whether they can be omitted or not; - whether or not the function takes positional only parameters (in this case, it doesn't); - whether or not the function takes vararg and keyword varargs as well (in this case, it doesn't); but none of the things that it doesn't need to know, such as the actual default value. [Aside: well, *almost* everything: it doesn't tell the static checker whether the function is in scope or not.] As a user of that function, I need to know the same things the static checker needs to know, *plus* the actual default values. I'm not sure why you care more about the type checker than the users of the function. Even if you couldn't care less about my needs, presumably you are a user of the function too.
That depends on what you define as the *function* signature and whether you equate it with the function's *type* signature. (Or dare I say it, whether you conflate it with the type signature.) Consider two almost identical functions: def add(a:int, b:int=0)->str: return a+b def add(a:int, b:int=1)->str: return a+b These two functions have: - identical names; - identical parameter lists; - identical type signatures (int, int -> int); - identical function bodies; but they are different functions, with similar but different semantics (the first defaults to a no-op, the second doesn't). Where does the difference lie? It's not specifically in the implementation (the body), that's identical. It's not in the *type* signature, we agree on that. I want to say that it is a difference in the *function* signature, which consists of not just the types, but also the function name and parameters including defaults. Not only is this a useful, practical way of discussing the difference, it matches 30 years of habit in the Python community. Reading your post is literally the first time it has dawned on me that anyone would want to exclude default values from the notion of function signature. (By the way, in Forth, function signatures are comments showing stack effects, and they're only for the human reader.)
By putting default values in the header, we're including a tiny bit of behavioural information.
Behavioural information is already present as soon as the header includes whether or not parameters can be, or must be, given by name or position, and whether or not it accepts varargs. In languages with procedures (or void functions) as well as functions, that behavioural information is also present in the signature. In languages with checked exceptions, that behavioural information is likewise present in the signature. What's your problem with these?
Yes.
Where do we draw the line? How much of the behaviour of the function do we want to move into the header?
Well obviously we don't draw the line until we've fallen down the slippery slope and the entire body of the function is part of the header! *wink* I think there are serious practical difficulties in moving much more behavioural information into the header. Not that there's much more we might want in the function header. Checked exceptions perhaps? Not me personally. What else *could* we move into the header? -- Steven
Sure, what's the problem? :-) def hof(*, op=lambda F: lambda x: F(x), fn=lambda x: x**2, val=None): # Default is squaring, do what you want. return op(fn)(val) -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On 29/05/20 11:49 pm, Steven D'Aprano wrote:
Where else would you put the parameter defaults, if not in the parameter list?
In some part of the function that's not the parameter list. :-) There are many ways it could be done. I've suggested one already (a special assignment statement). Another would be to have a special "defaults" section in the body.
A static type checker would have to know whether a parameter has a default value, even if it doesn't know what that default value is.
It has to know that the parameter is *optional*, yes. It doesn't need to know what the default value is, or even whether it has a default value at all. Even if the default value is available to the type checker, it's just going to ignore it. The only thing that *might* make use of it is the code generator.
As a user of that function, I need to know the same things the static checker needs to know, *plus* the actual default values. I'm not sure > why you care more about the type checker than the users of the function.
I need to know a whole lot of *other* things about the function too, but we don't expect to find them all in the header. We have docstrings for that. I'm not saying that default values shouldn't be in the header. I'm saying you can't argue that because *some* information about default values currently happens to be in the header, then *all* of it should be. That just doesn't follow.
That depends on what you define as the *function* signature and whether you equate it with the function's *type* signature.
It seems to me that the whole concept of a signature only makes sense in relation to static analysis. If you're not doing static analysis of some kind, then *everything* about a function is behaviour. In Python, you can attempt to call any function with any parameters, and something will happen, even if it's just raising an exception. The only reason for singling out certain characteristics of a function and calling them its "signature" is if you want to do some sort of static analysis about whether a call is valid. So, I think that "signature" always implies "type signature", for some notion of "type".
Certainly. But that doesn't prove that the default values have to be in the header! In an alternative universe, they could be written def add(a:int, [b:int])->str: b ?= 0 return a+b def add(a:int, [b:int])->str: b ?= 1 return a+b The default value of b would then have to be conveyed by the documentation -- just like everything else about what the function does.
I want to say that it is a difference in the *function* signature,
Then you would have to come up with some principle for deciding what is part of this "function signature", other than "whatever happens to be in the header".
Not only is this a useful, practical way of discussing the difference, it matches 30 years of habit in the Python community.
It's certainly a habit, and one which spans more than one language. But I think we need to recognise it as just that -- a habit, not a law.
I can understand that. I even surprised myself when I came to that conclusion, because I hadn't really thought about it before. I think we're so used to seeing default values in the header in other languages, such as C++, that we've come to regard it as part of the natural order. But I think C++ is a bad example to follow, because there the default values are in the header for *implementation* reasons. There are lots of other places in C++ as well where implementation issues leak into the language design (e.g. the fact that all member functions of a class need to be declared in its header file, including private ones -- I don't think anyone regards *that* as a desirable feature!) It's also worth remembering that in early versions of C, not even the *types* of the parameters were written in the header -- e.g. you wrote functions like int foo(a, b) float a; char *b; { .... } So none of this stuff is universal across languages.
What's your problem with [including behavioural information in the header]?
Only that the more stuff you put in the header, the more cluttered it becomes, so we need a good reason for every item we include. The only objective rule I can think of for deciding whether to put something in the header is whether it's needed for static analysis. (And even that depends on exactly what static analysis you want to perform.) If you have a better one, I'd be interested to hear it.
Not that there's much more we might want in the function header. Checked exceptions perhaps?
No! Not checked exceptions! Stay away! [Holds up crucifix, garlic and holy water.] -- Greg
On 26.05.20 06:03, David Mertz wrote:
* From the builtins there is `iter` which accepts a sentinel as second argument (including None). * `dataclasses.field` can receive `default=None` so it needs a sentinel. * `functools.reduce` accepts None for its `initial` parameter (https://github.com/python/cpython/blob/3.8/Lib/functools.py#L232). * There is also [`sched.scheduler.enterabs`](https://github.com/python/cpython/blob/v3.8.3/Lib/sched.py#L65) where `kwargs=None` will be passed on to the underlying `Event`. For the following ones None could be a sentinel but it's still a valid (meaningful) argument (different from the default): * `functools.lru_cache` -- `maxsize=None` means no bounds for the cache (default is 128). * `collections.deque` -- `maxlen=None` means no bounds for the deque (though this is the default). Other example functions from Numpy: * [`numpy.concatenate`](https://numpy.org/doc/1.18/reference/generated/numpy.concatenate.html) -- here `axis=None` means to flatten the arrays before concatenation (the default is `axis=0`). * Any function performing a reduction, e.g. [`np.sum`](https://numpy.org/doc/1.18/reference/generated/numpy.sum.html) -- here if `keepdims=` is provided (including None) then it will passed to the `sum` method of ndarray-sub-classes, otherwise not. * [`np.diff`](https://numpy.org/doc/1.18/reference/generated/numpy.diff.html) supports prepending / appending values prior to the computation, including None (though that application is probably rare).
All of those uses, including those where you say otherwise, treat None as a sentinel. In the iter() case, the optional seconds argument is *called* 'sentinel'. Guido recently mentioned that he had forgotten the two argument form of iter(), which is indeed funny... But useful. Well, ok functions.reduce() really does make it's own sentinel in order to show NONE as a "plain value". So I'll grant that one case is slightly helped by a hypothetical 'undef'. The NumPy, deque, and lru_cache cases are all ones where None is a perfect sentinel and the hypothetical 'undef' syntax would have zero value. I was wondering if anyone would mention Pandas, which is great, but in many ways and abuse of Pythonic programming. There None in an initializing collection (often) gets converted to NaN, both of which mean "missing", which is something different. This is kind of an abuse of both None and NaN... which they know, and introduced an experimental pd.NA for exactly that reason... Unfortunately, so far, actually using of.NA is cumbersome, but hopefully that gets better next version. Within actual Pandas and function parameters, None is always a sentinel. On Tue, May 26, 2020, 4:48 AM Dominik Vilsmeier <dominik.vilsmeier@gmx.de> wrote:
On Tue, May 26, 2020 at 10:14 PM David Mertz <mertz@gnosis.cx> wrote:
All of those uses, including those where you say otherwise, treat None as a sentinel. In the iter() case, the optional seconds argument is *called* 'sentinel'. Guido recently mentioned that he had forgotten the two argument form of iter(), which is indeed funny... But useful.
The second argument uses *any arbitrary value* as a sentinel. For instance: print("Type commands, or quit to end:") for cmd in iter(input, "quit"): do_stuff(cmd) There is nothing whatsoever about None here. It will call the function until it returns the sentinel. And this is completely different from the one-arg form of iter, so you can't use None as a default.
Well, ok functions.reduce() really does make it's own sentinel in order to show NONE as a "plain value". So I'll grant that one case is slightly helped by a hypothetical 'undef'.
Same again: reduce behaves as if the initial is prepended onto the sequence, and it has to treat None the same as any other value. But it would have to treat 'undef' as a value too, if it is indeed a value.
The NumPy, deque, and lru_cache cases are all ones where None is a perfect sentinel and the hypothetical 'undef' syntax would have zero value.
Yes, and I know a lot of languages in which lru_cache would use -1 as its sentinel. Granted.
I was wondering if anyone would mention Pandas, which is great, but in many ways and abuse of Pythonic programming. There None in an initializing collection (often) gets converted to NaN, both of which mean "missing", which is something different. This is kind of an abuse of both None and NaN... which they know, and introduced an experimental pd.NA for exactly that reason... Unfortunately, so far, actually using of.NA is cumbersome, but hopefully that gets better next version.
Within actual Pandas and function parameters, None is always a sentinel.
Definitely not always. Often, yes, but most definitely not always. ChrisA
On 26.05.20 14:10, David Mertz wrote:
Maybe we have a different understanding of "sentinel" in this context. I understand it as an auxiliary object that is used to detect whether the user has supplied an argument for a parameter or not. So if the set of possible (meaningful) arguments is "A" then the sentinel must not be an element of A. So in cases where None has meaning as an argument it can't act as a sentinel. `iter` is probably implemented via varargs but if it was designed to take a `sentinel=` keyword parameter then you'd need a dedicated sentinel object since the user can supply *any* object as the (user-defined) sentinel, including None: >>> list(iter([1, 2, None, 4, 5].pop, None)) [5, 4]
For both `deque` and `lru_cache` None is a sensible argument so it can't act as a sentinel. It just happens that these two cases don't need to check if an argument was supplied or not, so they don't need a sentinel. For the Numpy cases, `np.sum` and `np.diff`, None does have a meaning from user perspective, so they need a dedicated sentinel (which is `np._NoValue`). If `keepdims` is not supplied, it won't be passed on to sub-classes; if it is set to None then the sub-class receives `keepdims=None` as well: >>> class Test(np.ndarray): ... def sum(self, **kwargs): ... return kwargs ... >>> a = Test(0) >>> np.sum(a) {'axis': None, 'out': None} >>> np.sum(a, keepdims=None) {'axis': None, 'out': None, 'keepdims': None} For `np.diff`, if no argument is provided for `append` (or `prepend`) then nothing is appended (prepended), otherwise the supplied value is used (including None): >>> np.diff([1, 2]) array([1]) >>> np.diff([1, 2], append=None) TypeError: unsupported operand type(s) for -: 'NoneType' and 'int' For `np.concatenate` None is a meaningful argument to `axis` since it will flatten the arrays before concatenation.
I wouldn't say it's an abuse, it's an interpretation of these values. Using NaN has the clear advantage that it fits into a float array so it's memory efficient.
On Tue, May 26, 2020 at 12:02 PM Dominik Vilsmeier <dominik.vilsmeier@gmx.de> wrote:
I think getting caught up in the specific functions is a bit of a rabbit hole. I think the general point stands that None is usually fine as sentinel, and in the rare cases it's not, it's easy to define your own. But lru_cache() and deque() seem kinda obvious here. The default cache size is a finite number, but we can pass in any other positive integer for maxsize. Therefore, nothing in the domain of positive integers can carry the sentinel meaning "unbounded" or "infinite." We need a special value to signal different behavior (in other words, a sentinel). In C/C++, we'd probably use -1. It's an integer, but not one that makes sense as a size. I suppose we might use float('inf') as a name for unbounded, but then there are issues of converting that float to an int... or really just doing what currently happens of taking a different code path. For every practical purpose, sys.maxsize would be fine. It is not technically infinite, but it's far larger than the amount of memory you can possibly cache. I do that relative often myself... "really big" is enough like "infinite" for most practical purposes (I could make an even bigger integer in Python, of course, but that it mnemonic and plenty big). Or we could use a string like '"UNBOUNDED"'. Or an enumeration. Or a module constant. But since there is just one special state/code path to signal, None is a perfect sentinel. If `keepdims` is not supplied, it won't be passed on to sub-classes; if it
is set to None then the sub-class receives `keepdims=None` as well:
Yeah, OK, there's a slight different if you subclass ndarray. I've never felt an urge to do that, and never seen code that did... but it's possible.
For `np.concatenate` None is a meaningful argument to `axis` since it will flatten the arrays before concatenation.
This is again very similar to the sentinel in lru_cache(). It means "use a different approach" to the algorithm. I'm not sure what the C code does, but in concept it's basically: sentinel = None if axis is sentinel: a = a.flatten() b = b.flatten() axis = 0 ... rest of logic ...
I know why they did it. But as a data scientist, I sometimes (even often) care about the difference between "this computation went wonky" and "this data was never collected." NaN is being used for both meanings, but they are actually importantly different cases. -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On Mon, May 25, 2020 at 08:54:52PM -0700, Christopher Barker wrote:
Um, yes? I know what the context is, I'm pretty sure I already pointed out that None works fine most of the time. So we already have the feature you wanted: a sentinel value that implies "no value was passed". That's one of the purposes of None. If you want a *second* such sentinel value, we run into the problem I go on to describe.
It's not just introspection. What should `len(Undef)` do? If Undef or Missing or whatever you call it is supposed to represent a missing argument, one not given at all, then we ought to get: >>> len(Undef) TypeError: len() takes exactly one argument (0 given) since len takes no default values. But if Undef is considered to be an actual object, like any other object, we ought to get this: TypeError: object of type 'UndefType' has no len() So take your choice: either - we give fake error messages with misleading descriptions; - or we sometimes have to treat this "missing" sentinel as not missing at all, but just a plain old value like every other value. But that's what happens with None, so the same thing will happen with Undef, so we can add a third level of "the sentinel you use to represent a missing value when both None and Undef are regular values" except the exact same thing will happen to this third-level sentinel. And so on and so on. We cannot escape this so long as None/Undef/Missing etc are actual first class objects, like None and other builtins. But doing otherwise, having Undef be *not an object* but a kinda ghost in the interpreter, is a huge language change and I doubt it would be worth it. -- Steven
On Tue, May 26, 2020 at 12:53 PM Steven D'Aprano <steve@pearwood.info> wrote:
JavaScript and R, for example, do have a special pseudo-values for "even more missing". In JS, it is null vs undefined. In R, it is... well, actually NULL vs. NA vs. NaN. E.g.:
c(NULL, NA, NaN, 0, "") [1] NA "NaN" "0" ""
The NULL is a syntactic placeholder, but it's not a value, even a sentinel (i.e. it doesn't get in the array). Python *could* do that. But it would require very big changes in many corners of the language, for no significant benefit I can see. In other words, I agree with Steven. -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On Wed, May 27, 2020 at 2:51 AM Steven D'Aprano <steve@pearwood.info> wrote:
But is it a huge change? I thought so too, until Greg suggested a quite plausible option: leave the local unbound. There'd be two changes needed, and one of them could have other value. The semantics would be exactly the same as any other unbound local. def foo(): if False: x = 0 # what is x now? There is no *value* in x, yet x has a state. So we could have some kind of definition of optional parameters where, rather than receiving a default, they would simply not be bound. def foo(?x): # what is x? There would want to be a new way to query this state, though, because I think this code is ugly enough to die: def foo(?x): try: x except UnboundLocalError: ... # do this if x wasn't passed in else: ... # do this if we have a value for x But if we could do something a bit more elegant, this would become quite plausible. And the "is this name bound" check would potentially have other value, too. "Undef" wouldn't be a thing. It wouldn't be a global name, it wouldn't be a keyword, it certainly wouldn't be an object. But "unbound" would become a perfectly viable state for a local variable. (It's probably best to define this ONLY for local variables. Module or class name bindings behave differently, so they would simply never be in this unbound state. For the intended purpose - parameter nondefaults - that won't be a problem.) ChrisA
On Wed, May 27, 2020 at 5:19 AM Alex Hall <alex.mojaki@gmail.com> wrote:
When you're looping, searching for something, and then seeing if you found any. If you want to stop at the first, you can use 'break' and 'else' (although a lot of people don't know about that), but what if you're locating the last match, and can't search in reverse? Or some sort of best match or all match? How do you then say "none found"? Usually you end up needing a sentinel, but if you could simply leave the variable unbound, you could then check for that at the end. ChrisA
On Tue, May 26, 2020 at 9:24 PM Chris Angelico <rosuav@gmail.com> wrote:
This proposal would still leave defaults out of the signature, and thus the only benefit I'm seeing is being able to avoid typing `if obj is sentinel`. In fact it saves even less typing than other proposals since you still have to write `obj ?= value`. I don't think that's a significant benefit, and others have expressed similar. So is there any use for it which can't be satisfied by a sentinel? Otherwise I would definitely prefer None-aware operators from PEP 505.
On Tue, May 26, 2020 at 8:30 PM Greg Ewing <greg.ewing@canterbury.ac.nz> wrote:
It does so very little that I would definitely not want syntax ONLY for that. The example of lru_cache() is god here... None is a sentinel, but it is NOT the default value. So there is a value of 128 supplied, even if the user doesn't supply one. Changing syntax for something that doesn't even actually save a line, isn't worth it. I'm assuming you mean something along the lines of: def foo(a, b, mode=): if undef mode: mode = whatever It's really just a sentinel, no better than None. If we want to save more, we're back to PEP 505 and None-coalescing. I'm feeling more sympathetic to that than I did in earlier discussion. But I'm still a bit horrified by some of the use cases that were presented at that time (not directly in the PEP). E.g.: data = json.load(fh) needle ?= data?.child?.grandchild?[key]?[index]?.attr When it looks like that, I get visions of APL or Perl unreadability. So I guess what I'm sympathetic with is about 1/3 of PEP 505. Like only: stuff = this ?? that Yes, there are still rare non-None sentinels to deal with differently, but that is 90% of the issue being discussed. -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
Greg Ewing writes:
"Did the user supply a value for this optional argument?" is a simple and reasonable question to ask.
True.
It deserves to have a simple and direct way of answering it that always works.
"Deserves"? I wouldn't go farther than "it might be fun to have" that. In Emacs Lisp, it's useful to defend against users who don't update their package libraries with #'boundp and #'fboundp checks. These invariably occur in top-level forms, though, not on function arguments. But what's the use case for this magical predicate? Writing a nastygram to the user's boss if they dare to use gregs-package._sentinels._af5d8a21858f42808c9bcc17012b77bcc2fd6ab3b071dbd4a05f13f410470541 as an actual argument?
On Wed, May 27, 2020 at 05:03:09AM +1000, Chris Angelico wrote:
In Python code, no, it has no state, it's just an unbound name. That's literally a name that has nothing bound to it, hence no state. In the CPython 3 implementation, it has a hidden state: there's a fixed array representing the locals, one of those array slots represents x, and there is some kind of C-level special state to distinguish between "this slot is filled" and "this slot is not filled". But that's purely an optimization. Locals can also be backed by a dict, like globals. That is what happens in Jython, so when you call locals() you get back the actual local namespace dict and modifications to the variables works. (Unlike in CPython.) # Jython 2.7 >>> def test(): ... locals()['x'] = 999 ... if False: ... # Fool the compiler into treating x as a local. ... x = None ... print(x) ... >>> test() 999 IronPython appears to be different yet again, but I don't understand what it is doing so I can't explain it. In CPython 2, some locals were backed by the fast array slots, some were not. I think (but I'm not sure!) that if the compiler saw an exec or a star import inside a function, it switched off the fast array optimization. Or something like that. The bottom line here is that the Python execution model has names. Names can be bound to a value (an object), or they can be unbound in which case they have no state *in Python*. Whether that unboundness is represented by a nil pointer or a special magic value or is a consequence of a key being missing from a namespace dict is part of the implementation, not part of the Python semantics.
We could have an `if undef` keyword :-) if undef x: x = something (Not entirely serious about this proposal.)
There's always: if 'x' in locals()
Of course they are! # Module level state. x = None; del x # Ensure x is unbound. print(x) I frequently write top-level module code that tests for the existence of a global or builtin: try: spam except NameError: def spam(): ... That could become: if undef spam: def spam(): ... I would be cross if `if undef` worked inside functions but not globally. -- Steven
On Thu, May 28, 2020 at 8:01 PM Steven D'Aprano <steve@pearwood.info> wrote:
Is the UnboundLocalError that you'd get on trying to access 'x' a CPython implementation detail or a language feature? If it's a language feature, then the name 'x' must be in the state of "local variable without a value". This is a valid situation. There is no value, but this is the state of the variable. It's not "no state" any more than zero is a non-number or NULL is a non-pointer. ChrisA
On Thu, May 28, 2020 at 08:04:07PM +1000, Chris Angelico wrote:
I think the existence of UnboundLocalError is a red herring. See my recent post in this thread discussing Micropython. What *isn't* a red herring is whether or not x is treated as a local variable. That is a language feature. But whether it raises NameError or UnboundLocalError is, I think, up to the implementation.
Oh ho, I see what you are doing now :-) I'm going to stick with my argument that Python variables have two states: bound or unbound. But you want to talk about the *meta-state* of what scope they are in: LEGB = Local, Enclosing (nonlocal), Global, Builtin There's at least one other case not captured in that acronym, Class scope. There may be other odd corner cases. In any case, if you want to distinguish between "unbound locals" and "unbound globals" and even "unbound builtins", then I acknowledge that these are genuine, and important, distinctions to make, with real semantic differences in Python. But I think that the scope of a variable is metadata (metastate), when it comes to the state of any variable (whether LEGB or C) it can be bound to a value or unbound and that's all. At this point I'm not sure what, if any, difference to the current discusion it will make whether we label a variable's scope metastate or state.
Zero is definitely a number with a value. It's the additive identity. NULL being a pointer is, I think, a mere consequence of the impoverished type systems of languages like C :-) The idea of NULL is that it should be just pointer-ish enough to satisfy the compiler and allow you to assign it to pointer variables, but not pointer-ish enough to fool the compiler into allowing you to dereference it and crash the machine. -- Steven
On Fri, May 29, 2020 at 10:51 PM Steven D'Aprano <steve@pearwood.info> wrote:
The reason locals are special is that you can't have a module-level name without a value, because it's exactly the same as simply not having one; but you CAN have a local name that must be exactly that local, and you can't look up a module or builtin name, but it still doesn't have a value. I believe local scope is the only one that behaves this way.
Sure. But "unbound" is a state. In theory, you could have an optional parameter which, if no value is given, has no value stored in it.
Agreed, I don't care whether it's "state" or "metastate". I would just call it "state" - the name has no value associated with it, yet it is local - but if you want to consider it a metastate of "unbound" as distinct from its main state (which would be the value), then sure.
Exactly. All of them ARE states. A box containing nothing is validly containing zero things. A NULL pointer is an actual thing. And an unbound local name is a real situation that can be seen. ChrisA
On 29.05.20 15:09, Chris Angelico wrote:
Indeed locals are special, but why was it designed this way? Why not resolve such an unbound local name in the enclosing scopes? It seems that there is no way to modify locals once the function is compiled (this is probably due to the fact that locals are optimized as a static array?). For example: >>> x = 1 >>> def foo(): ... exec('x = 2') ... print(x) ... >>> foo() 1 However in Python 2.7 this is possible: >>> x = 1 >>> def foo(): ... exec('x = 2') ... print(x) ... >>> foo() 2 >>> x 1
On Fri, May 29, 2020 at 04:52:38PM +0200, Dominik Vilsmeier wrote:
Indeed locals are special, but why was it designed this way? Why not resolve such an unbound local name in the enclosing scopes?
Probably for speed. When I first learned about the LGB rule (so long ago there wasn't even an E for Enclosing!) I thought that Python *literally* did this: - look for a local name 'x' - if not found, look for a global name 'x' - if not found, look for a builtin name 'x' on every name lookup. But that's not what the interpreter actually does. It has separate byte code instructions for fast local lookup, nonlocal lookup, and global/builtin lookup. So the compiler needs to know at compile-time which instruction to use. Python might have used a single lookup which searched each scope in turn, I believe that is (roughly) how Lua works. But that would mean that within the same lexical block, a variable is sometimes global and sometimes local: def func(): # Inside this block we have: print(x) # x is global x = 1 print(x) # And now it's local. and you can get that effect in Lua. That's a perfectly logical and unambiguous rule, but it's probably not very practical, especially if the function is large of if the assignment is buried in a conditional. def spam(): if condition: x = 1 print(x) # Is x local or global? And that's what happens for builtins and globals! py> print(len) # builtin <built-in function len> py> len = 1 py> print(len) # global 1 py> del len py> print(len) # builtin again <built-in function len> But inside a function, that's probably a Bad Thing. We could require explicit declarations of scope for every variable, like languages such as Pascal, C and Java use. But we don't. What we have is a lexical rule for determining what scope names inside functions belong to. Roughly something like this: - every undotted name inside a function belongs to exactly one scope; - if there is a global or nonlocal declaration, that takes precedence; - otherwise, any binding operation to that variable anywhere in the function, even in unreachable code, forces the variable to belong to the local scope; - otherwise, if there is an enclosing function, and there is a local with that name in the enclosing function, then the name in the nested function belongs to the enclosing scope; - otherwise it's a global/builtin. As a consequence of having scopes determined lexically, the compiler is free to optimize for fast local lookups, and use different byte codes for each lookup. In CPython 3.8: LOAD_NAME # globals, builtins and class scope LOAD_GLOBAL # globals and builtins LOAD_DEREF # closures and nonlocals LOAD_FAST # locals LOAD_CONST # literals and certain other constants Other implementations might not use the same lookup mechanisms, so long as the keep the same semantics.
Not without byte-code hacking. As you point out, in Python 2 it prints 2, not 1, because the interpreter took extraordinary efforts to make it work that way. I don't remember all the details but it was confusing and hardly anyone used it except by accident (which made it even more confusing) and so it was taken out in Python 3. The reason it doesn't work in Python 3 isn't because of the static array optimization. exec() could modify the static array (in CPython, it doesn't, but it could). Jython has no such static array, but if and when Jython 3 is available, it too should print 1 rather than 2. The reason for Python's behaviour is that according to the lexical rule, the lack of any assignment to x means that x is treated as a global/builtin, not a local. Even if the exec() succeeded in creating a local variable x with value 2, we have no way to tell the compiler to look up x in the local scope. (Except by doing it manually.) So hypothetically, this could work in a legal Python 3 interpreter: x = "in the global scope" def spam(): exec('x = "in the local scope"') print(x) print(locals()['x'] # prints in the global scope in the local scope Although it doesn't work in CPython 3, it might work in some future Jython 3 or other interpreters where modifications to locals() are reflected in changes to local variables. -- Steven
On 30/05/20 2:52 am, Dominik Vilsmeier wrote:
Indeed locals are special, but why was it designed this way? Why not resolve such an unbound local name in the enclosing scopes?
From experience with other languages I can attest that "sometimes local, sometimes global depending on what gets executed first" is a source of bugs. I like that Python always makes up its mind about whether a given name is local or not. -- Greg
On 30/05/20 7:15 pm, Steven D'Aprano wrote:
Out of curiosity, which languages are you thinking of? I know Lua does that, I can't think of any others.
You've probably never seen the one I'm thinking of. It's a proprietary, vaguely VB-like language used for scripting a particular application. It doesn't work like Lua, but it does have scoping rules that can lead to some surprising results. I've been bitten by it treating something as global that I intended to be local, which has made me appreciate Python's approach to scoping. One particularly weird thing it does: if you don't declare a variable (it has optional declarations) it will *usually* infer it to be local if you assign to it. But if the first assignment is in a conditional branch of the code, it seems to get confused. If you do this: if something then x = 5 else x = 7 end if and later refer to x, it complains that x hasn't been defined. Go figure. -- Greg
Greg Ewing writes:
By contrast, Lisps (at least Lisp2s like Emacs Lisp and Steel Bank Common Lisp) have #'makunbound, and this is an unbound symbol error in both: (defvar x 1) (defvar result '()) (let ((x 2)) (push x result) (makunbound 'x) (push x result) # error is signaled here result) Since Common Lisp is the world's most overengineered language, I would guess this scoping rule is deliberate.
Some versions of GCC would occasionally complain that "x might be used uninitialized" in similar code in C, too. Spent a lot of time on such warnings, sometimes GCC was right, but sometimes it just didn't make sense. Apparently compiling such code, at least with optimization, can be hard.
On Thu, May 28, 2020 at 11:57 AM Steven D'Aprano <steve@pearwood.info> wrote:
Consider this code: ``` x = 1 def foo(): print(x) x = 2 foo() ``` Here `print(x)` doesn't print '1', it gives `UnboundLocalError: local variable 'x' referenced before assignment`. It knows that `x` is meant to be a local and ignores the global value. That doesn't look like an implementation detail to me - does Jython do something different?
On Thu, May 28, 2020 at 12:11:38PM +0200, Alex Hall wrote:
I never said that Python's scoping rules were implementation details. I said that the storage mechanism of *how* local variables are stored, and hence whether or not writes to `locals()` are reflected in the local variables, is an implementation detail. I'm too lazy to look it up right now, but I'm 99.9999999% (nine nines) certain that Python's execution model defines that any binding operation inside the function scope to an undotted name inside a function must make it a local, unless explicitly declared nonlocal or global. (Even if that binding operation is unreachable code.) Binding operations include regular assignment with `=`, imports, `for`, `with ... as`, `except ... as`, and `del`. I don't know about the walrus operator. That means that any non-buggy compliant Python must print NameError, or its subclass UnboundLocalError, when calling your foo function above. (I *think* that NameError would be acceptable, but you might have to ask the Steering Council to make a ruling if it's not already documented.) However the behaviour of locals()['x'] = 999 inside that function is explicitly documented as subject to implementation differences, which is what I was talking about. For the record, both IronPython and Jython 2.7 raise UnboundLocalError, but micropython just raises NameError: $ micropython MicroPython v1.9.4 on 2019-01-13; linux version Use Ctrl-D to exit, Ctrl-E for paste mode
Micropython often gets special dispensation to bend the rules, but in this case I don't think that it needs it. So long as any implementation raises a NameError, not necessarily UnboundLocalError, I think that's sufficient. -- Steven
On Fri, May 29, 2020 at 2:18 PM Steven D'Aprano <steve@pearwood.info> wrote:
I didn't know what it was you were saying back then, and I'm trying, but I still haven't figured it out. I understand bits of it, but I don't know what larger point you're trying to make. I think there are some things you need to try harder to communicate clearly. Chris sad:
There is no *value* in x, yet x has a state.
You responded:
In Python code, no, it has no state, it's just an unbound name.
and then started talking about the locals() dict in great detail for reasons I haven't grasped. My point with that code snippet is that Python (not just some implementations) can distinguish between a bound local, an unbound local, a bound variable of some other type, and a name that isn't defined at all. I think labeling those as 'states' is pretty reasonable. It seemed pretty clear to me that that's the kind of thing Chris was talking about. Maybe you disagree with that label, or are trying to make some other distinction, but I don't see the relevance, as the word 'state' isn't the point anyway. Chris was just saying that a statement like `x ?= y` meaning 'assign the value of y to the local variable x if x is currently unbound' already fits neatly into the language model and doesn't require major changes. Do you disagree? (although I don't endorse the proposal for `x ?= y`)
On Fri, May 29, 2020 at 06:03:30PM +0200, Alex Hall wrote:
Okay, I will try to explain in more detail. I don't know if it will help or just make things more confusing, but I also replied to a post by Dominik covering this. Simplifying somewhat, we can say that under Python's execution rules, every undotted name must belong to at most one scope: - global and/or builtin; - an enclosing function; - the local function. So the compiler has to look each name up in only one of those places, counting globals and builtins as a single scope for this purpose. That is, as I understand it, a strict language guarantee and part of the execution model for Python 3. (Python 2 may have been a bit less strict.) How the compiler does the lookup, and whether the variables are stored as key:values in a mapping, or in a static array, or in a database, or written down as pencil marks on a Turing machine paper tape, is an implementation detail. But the scopes themselves are not. If the variables are implemented as key:values in a mapping, then an unbound variable is one where the key doesn't exist in the mapping. If they are implemented in a static array, then an unbound variable is one where that array cell happens to contain a special sentinel value (possibly a null pointer) to flag it as "unbound". (That's because a memory location cannot contain nothing, it must has some value.) But that distinction between "unbound and doesn't exist at all" versus "unbound but the cell exists" is just an implementation detail. Specifically: nothing in the language specification states that local variables MUST be cells of a static array. [...]
Some pertinent observations: 1. Python cannot distinguish between bound and unbound until runtime. 2. The mechanism of how it distinuishes between bound and unbound is not part of the language, but is an implementation detail. E.g. is it a missing key or a special sentinel value like a null pointer, or something else? The language doesn't care. 3. As part of the execution model, Python enforces a rule that each undotted name belongs to a single scope. This rule uses lexical scoping, which means it can be perfectly and unambiguously determined at compile time. (For simplicity, I'm counting builtins and globals together for this purpose, and ignoring class scopes and comprehensions.) 4. You refer to "variable of some other type" -- in dynamic languages like Python, "type" normally refers to the value bound to the name, not the name itself. So I think it is better to use a different word to distiguish *kinds* of variables. I hope that you agree with those four points. You want to distinguish between "kinds of variables" like global, nonlocal, local:
I think labeling those as 'states' is pretty reasonable.
There are two major reasons why labelling the scope of a variable "state" is not reasonable. Firstly, if it is a state of a variable, then in principle we ought to be able to mutate the state at runtime by some operation like "setting a flag" on the variable: declare x set state of x to global set state of x to local where at each stage there is exactly one variable x that is literally being moved from one scope to another scope (which may or may not require it to be moved in memory). I won't quite say that this is absurd, but it's hard to think of any reason why we would want this. And I certainly cannot think of any language which offers it as a language feature. Even if some language does support it, Python doesn't. Even in Lua, where a name can sometimes refer to a local variable and sometimes to a global within the same block of code, we're not changing the state of a single x, we're referring to two different variables with the same name but in different scopes. We can move variables from one scope to another but only by rewriting the code. That's not a runtime operation :-) The second reason why it is not helpful or meaningful to consider "local, nonlocal, global" to be distinct *kinds* (you said "types" but that is subject to confusion with typed variables in statically typed languages) of variables is that if they were different kinds of thing, they should have functional differences, but they don't. A constant and a variable are different kinds of things. Constants only support two operations: - set an initial value; - get that value; but all variables, regardless of scope, share a maximum of three fundamental operations: - set a value; - get the current value; - delete the variable. There are implementation differences that have observable effects on performance (local lookups are faster than global lookups); there are also practical differences as far as usability and usefulness (e.g. isolation, Globals Considered Harmful, thread safety etc). But fundamentally anything we can do with a local, we can do with a global, etc, all variables are the same kind of thing: def spam(arg): x = arg + 1 return x # Becomes: def spam(): global arg, x x = arg + 1 try: return x finally: del x (The calling conventions would be slightly different, but otherwise the functionality is the same.) Similarly we can replace globals with nonlocals; and if Python had persistent static local variables, we could replace nonlocals and globals with locals too. So globals, nonlocals and locals are pretty much functionally interchangable, except that locals are automatically deleted when the function returns, rather than being manually deleted. The difference is not in *what* they are, but *which scope* they belong to. Which is metadata about the variable, not part of the variable's state. -- Steven
On Sat, May 30, 2020 at 6:00 AM Steven D'Aprano <steve@pearwood.info> wrote:
I'm sorry, I should have been more explicit - I understand how variables work and didn't need a more detailed explanation. The problem is that it's not clear how all these details were relevant to the wider context of the discussion. Your post didn't address that, and now I think the answer is that it's not relevant and that you simply hadn't understood the context. More generally, I'm sorry about this post. I mean it with the best of intentions, but I need to be brutally honest and I don't think there's any way to make this easy for you to read. Please bear with me and be patient. In your case, "try harder to communicate clearly" generally doesn't mean writing in more detail. On the contrary, I think you could usually err on the side of writing too little. I get the impression that you enjoy writing these long posts, and that's fine, but you need to understand that doing so doesn't increase your chances of being understood. Try to focus on quality over quantity, and make sure it's clear *why* you're saying what you say. Connect it to the rest of the discussion. More important than your writing is your reading and understanding. Spend more time reading past posts in the thread and absorbing them so you can remember what was said later. If you think someone is implying that something was said previously, try to find that reference. I've seen you forgetting even your own words (a point about final classes https://mail.python.org/archives/list/python-ideas@python.org/message/QXUABJ...) and not even doing a basic search to see what was being referred to, and then others have to take time to directly quote or link for you. Possibly as a symptom of being more enthusiastic about writing than reading, it often feels like you start replying to a post before you have finished reading it. The most blatant example of this was [here]( https://mail.python.org/archives/list/python-ideas@python.org/message/HHJ6XX...). I basically said "It's clear what the arguments are, but not which parameters they're bound to", and you basically quoted me with a redundant interjection "It's clear what the arguments are, [But it's not clear which parameters they're bound to] but not which parameters they're bound to". I asked "Steven, what happened above? ... It feels like you're not reading what I say." and then in the same post I went on to say "Anyway, talking about this has made me feel not so convinced of my own argument." [Your response]( https://mail.python.org/archives/list/python-ideas@python.org/message/FGITGC...) was "Trust me Alex, I am reading what you say. What I don't know is whether you mean what you say, because frankly I think your position ... is so obviously wrong that I don't understand why you are standing by it." In other words, your response (1) didn't answer the question of what happened, and (2) immediately demonstrated again the very problem of not reading which I was pointing out and you had casually brushed aside, insisting that I was standing by a position which I had just abandoned. In addition to simply reading what people say, take more time to think about their words and try harder to understand what they mean. When in doubt, try to interpret them as being as rational as possible. This is called the principle of charity. Maybe you already know this, but I don't think you're implementing it well. This kind of problem is a repeating pattern with you in this list. I find it exhausting and frustrating not only having discussions with you but watching you have discussions with other people and doing the same things to them. Now, as to what happened in this thread: Greg first proposed "a way of declaring optional arguments with no default, and a way of conditionally assigning a value to them if they are not bound.": https://mail.python.org/archives/list/python-ideas@python.org/message/4C2WQR... Chris referred to this idea here: https://mail.python.org/archives/list/python-ideas@python.org/message/SJPGHG... He quite clearly mentioned that Greg suggested the idea, which would be a cue to look that up if you weren't sure about it. But aside from that, he basically spelled out the proposal again as he saw it, with slightly different syntax. You responded to that post by Chris, starting a long discussion about the semantics of the word 'state' in regards to variables. It seems to me that most of this was pointless. I was struggling to see what relevance your arguments had to the proposal by Greg and Chris, and you didn't seem to be aware of that problem. I don't think I was alone in this experience. Finally, when I brought you back to the main point ( https://mail.python.org/archives/list/python-ideas@python.org/message/PEHDA3...) it became clear that you didn't understand the proposal. `?=` was not the extent of it, and both of the above posts clearly laid out that there would also be a way to declare optional parameters without a default (either `def foo(bar=):` or `def foo(?bar):`) which could therefore be unbound in the body. I think it's reasonable to expect that would have read these posts, especially considering you replied to one of them. And if you see an obvious flaw, take some time to refresh your memory and reread a proposal so you know that it hasn't been addressed already.
Attempting to bring things back on topic to function parameters with late binding. On Fri, May 29, 2020 at 06:03:30PM +0200, Alex Hall wrote:
I have no idea whether `?=` alone requires major changes or not. Probably not, since we can already implement it as a try...except: try: x except NameError: x = y But as the proposal relates to function calls, it is a big change that will turn early detection of some errors into late detection. Consider what happens when you call a function. The interpreter matches up arguments supplied in the function call to parameters in the function signature. If any parameters don't get an argument, the intrepreter provides default values. If, after applying defaults, any parameter doesn't have a value then the intrepreter raises TypeError, otherwise it calls the function and enters the body of the function. The consequence of this is that if the function body is entered, it is impossible for any parameter to be unbound. def spam(arg): # if we enter the body of the function, then arg must be # bound and `arg ?= ...` will never apply. That means that Chris' proposed `?=` operator would not help at all to get late-binding defaults. Adding a bind-only-if-unbound operator might be useful, or not, but it doesn't solve the mutable default issue. In order to solve the mutable default issue, the intrepreter has to stop raising TypeError, and instead enter the function body with the function parameters left unbound. So exceptions like this will disappear: py> len() TypeError: len() takes exactly one argument (0 given) to be replaced with something like this: UnboundLocalError: local variable referenced before assignment when the function tries to access the unbound parameter. And we change code currently written like this: def spam(arg=None): if arg is None: arg = expression into code written like this: def spam(arg): arg ?= expression which saves one line, not much benefit to gain for the pain. So a general purpose `?` bind-if-unbound operator doesn't solve the problem at hand, even if it were useful in other ways. What if it wasn't a general purpose operator, but instead special syntax that applies only in function signatures? Then we could write: def spam(arg?=expression): and the rule for the interpreter would become: Match up arguments supplied in the function call to parameters in the function signature. If any parameters don't get an argument, apply default values: - if the default is set with `=`, it is early-bound and nothing changes from today; - if the default is set with `?=` it is late-bound and the default is re-evaluated as needed; Finally, if after applying defaults, any parameter doesn't have a value, then the intrepreter raises TypeError, otherwise it calls the function and enters the body of the function. The concept of bound-or-unbound doesn't come into this, or at least no more that it already applies to the status quo. The whole process takes place before the function is called. The only differences from the status quo are that the `?` tells: - the compiler to delay evaluating the default and store the expression itself (in some format), rather than evaluate the expression and store the evaluated value; - the interpreter to re-evaluate that expression, not just fetch the pre-evaluated value. Is that a big change or hard to implement? I don't know. -- Steven
On 30/05/20 12:11 am, Steven D'Aprano wrote:
That's true, but just to be clear, my ?= idea doesn't rely on that implementation detail. If locals were kept in a dict, for example, it could work by testing whether the name has an entry in the dict. This also means that it *could* be made to work in class and global scopes if it were so desired. -- Greg
On Sat, May 30, 2020 at 04:34:49PM +1200, Greg Ewing wrote:
This thread is huge and I'm losing track of who said what and what they meant by it. I thought `?=` was Chris' idea :-) Is this `?=` idea for a general purpose operator we can use anywhere we like? That's what I thought it was, but now I'm doubting my own memory. E.g. I do this lots of times: try: spam except NameError: spam = expression (Well, usually I end up using `def spam()...` but that's another story.) If we had that operator I could use: spam ?= value Or do you mean for it to be purely syntax for function signature lines, i.e. only valid in a signature line: def spam(arg?=expression): ... If so, I thought you were opposed to putting late-binding inside signature lines. Also, it would still require special handling by the interpreter to ensure that the expression was re-evaluated each time it was needed. Otherwise it's still just early binding.
This also means that it *could* be made to work in class and global scopes if it were so desired.
I cannot imagine why it could only be made to work in locals but not elsewhere. A NameError (including subclasses) is a NameError, and a name is always either bound or unbound, there is no third state it could be. It either is bound to a value, or not bound to a value. Some people (Alex, Chris I think?) have tried to argue that there is a distinction between an unbound variable and a variable that doesn't exist at all, but I'm not clear what they think that distinction would be, or why (if such a distinction exists) the interpreter doesn't tell when it's one or the other: NameError: name 'grue' is not defined NameError: name 'bleen' doesn't exist at all -- Steven
On Sat, May 30, 2020 at 6:13 PM Steven D'Aprano <steve@pearwood.info> wrote:
I was talking about a somewhat similar notion of being able to cleanly ask the question "is this variable bound to anything", but the ideas have been broadly similar and it's not easy to figure out who said what :)
The difference would be that, when a local variable doesn't exist, a global or builtin is searched for. That's very different from the local existing but having no value. Local scope is the only one where this happens, but it's kinda slightly important, given how much Python code executes at that scope :) ChrisA
On 30/05/20 8:03 pm, Steven D'Aprano wrote:
Is this `?=` idea for a general purpose operator we can use anywhere we like?
I introduced it as part of a two-part idea for allowing optional parameters without a default. But there would be nothing to stop you from using it elsewhere. The syntax was inspired by a similar thing in makefiles. It's entirely possible that someone else has used it for something else, though.
That was my idea, yes. -- Greg
On Tue, May 26, 2020 at 9:52 AM Steven D'Aprano <steve@pearwood.info> wrote:
A NOT_SPECIFIED singleton in builtins would be pretty clear.
This is the point -- it "implies" no value was passed -- which is usually good enough, but there is something to be said for being more explicit about that. and it's "one" of the purposes -- None has many purposes, and these sometimes (though not often) confilct / overlap with the "no value was passed" use case. If you want a *second* such sentinel value, we run into the problem I go
on to describe.
As far as I can tell -- that problem is that it still wouldn't be useful for ALL cases of not passing arguments.Which doesn't, by any means mean that it would never be useful. I would venture to guess that if such a special value existed already, it would be mostly used in cases where None would have been fine, but it would be more explicit, which I think would be a good thing. Another thing to keep in mind is that None is not, in fact, all that special. The only things (that I can think of at the moment) special about are: - it is a builtin - it is the default value passed back from function calls - It's a well established convention - anything else?? (note: it would become a more special part of the language id PEP 505 or something like it were to be adapted) That later point is key -- we all agree to use None for things like the current example: meaning no specified, but there's nothing in the language spec or None itself that requires that. And this theoretical NOT_SPECIFIED value *could* have special properties in the language, for instance: function_call(x=NOT_SPECIFIED) could be illegal. Is that a good idea? I haven't thought it out, but it *could* be done. Anyway -- all I'm suggesting is that yes, it would be nice to have another "standard" value with a more defined meaning. Is it critically important? no Would it be very disruptive? no. well, maybe yes, as we'd have a long period of people using both None and gteh new one in the same context -- and that would be even more confusing. Could there be a dozen or more other "standard" values that would be equally useful? maybe, and if that's the case, then yeah, probably not worth doing this at all. I'm not sure if this is really parallel, but this reminds me of NaN -- NaN can be the result of a calculation gone bad, and it's also used to mean "missing value", or "not set", and other use cases. And this works most of the time OK, but it IS an issue in some cases -- witness the massive discussions around how to handle missing values in numpy. Another special floating point value that specifically means "missing data" would be pretty helpful. Anyway, I'm not pushing this, and there doesn't seem to be much support, so I'm done. I am intrigued by Chris A's idea of leveraging unbound locals though. -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
On 24.05.20 19:38, David Mertz wrote:
Do you have an example which can't be solved by using generator expressions and itertools? As far as I understand the Dask docs the purpose of this is to execute in parallel which wouldn't be the case for pure Python I suppose? The above example can be written as: a = (inc(x) for x in data) b = (double(x) for x in data) c = (add(x, y) for x, y in zip(a, b)) total = sum(c)
Subject changed for tangent. On Sun, May 24, 2020 at 4:14 PM Dominik Vilsmeier <dominik.vilsmeier@gmx.de> wrote:
Obviously delayed execution CAN be done in Python, since Dask is a pure-Python library that does it. For the narrow example I took from the start of the dask.delayed docs, your version look equivalent. But there are many, not very complicated cases, where you cannot make the call graph as simple as a sequence of generator comprehensions. I could make some contrived example. Or with a little more work, I could make an actual useful example. For example, think of creating different delayed objects within conditional branches inside the loop. Yes, some could be expressed with an if in the comprehensions, but many cannot. It's true that Dask is most useful for parallel execution, whether in multiple threads, multiple processes, or multiple worker nodes. That doesn't mean it would be a bad thing for language level capabilities to make similar libraries easier. Kinda like the way we have asyncio, uvloop, and curio all built on the same primitives. But another really nice thing in delayed execution is that we do not necessarily want the *final* computation. Or indeed, the DAG might not have only one "final state." Building a DAG of delayed operations is almost free. We might build one with thousands or millions of different operations involved (and Dask users really do that). But imaging that different paths through the DAG lead to the states/values "final1", "final2", "final3" that share many, but not all of the same computation steps. After building the DAG, we can make a decision which computations to perform: if some_condition(): x = concretize final1 elif other_condition(): x = concretize final2 else: x = concretize final3 If we avoid 2/3, or even 1/3 of the computation by having that approach, that is a nice win where we are compute bound. -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On Sun, May 24, 2020 at 01:38:26PM -0400, David Mertz wrote:
Sure, but when you have seven parameters that all take late-bound defaults, it becomes a PITA. def func(...): # late binding boilerplate if dopey is None: if happy is None: if doc is None: if sneezy is None: if grumpy is None: if sleepy is None: if bashful is None: # AAAAND at last we get to the actual function body... This "if arg is None..." idiom is okay, but it's just a tiny bit of extra friction when coding. Nothing as drastic as a "design flaw" or a "wart" on the language, but it's slightly rough edge.
Well, I don't know about a thousand, but I'm currently writing up a proto-PEP for delayed evaluation, and I've got six use-cases so far. -- Steven
On 24.05.20 18:34, Alex Hall wrote:
It looks like the most common use case for this is to deal with mutable defaults, so what is needed is some way to specify a default factory, similar to `collections.defaultdict(list)` or `dataclasses.field(default_factory=list)`. This can be handled by a decorator, e.g. by manually supplying the factories or perhaps inferring them from type annotations: @supply_defaults def foo(x: list = None, y: dict = None): print(x, y) # [], {} @supply_defaults(x=list, y=dict) def bar(x=None, y=None): print(x, y) # [], {} This doesn't require any change to the syntax and should serve most purposes. A rough implementation of such a decorator: import functools import inspect def supply_defaults(*args, **defaults): def decorator(func): signature = inspect.signature(func) defaults.update( (name, param.annotation) for name, param in signature.parameters.items() if param.default is None and param.annotation is not param.empty ) @functools.wraps(func) def wrapper(*args, **kwargs): bound = signature.bind(*args, **kwargs) kwargs.update( (name, defaults[name]()) for name in defaults.keys() - bound.arguments.keys() ) return func(*args, **kwargs) return wrapper if args: return decorator(args[0]) return decorator
On Sun, May 24, 2020 at 10:05 PM Dominik Vilsmeier <dominik.vilsmeier@gmx.de> wrote:
This still leaves the information out of the signature, which I've argued is a more important consideration than saving a couple of lines of boilerplate. You could solve this by allowing people to write: ``` @supply_defaults(x=list, y=dict) def bar(x=[], y={}): print(x, y) # [], {} ``` and telling `supply_defaults` to ignore the actual defaults wherever factories are supplied, but there's no guarantee people will put sensible defaults in the signature. For the mutable defaults only case, you could have: ``` @copy_mutable_defaults def bar(x=[], y={}): print(x, y) # [], {} ``` which would only pay attention to a specific whitelist of default types like list, dict, and set, and copy them each time. Not great.
On 24/05/2020 21:03, Dominik Vilsmeier wrote:
That's very clever, but if you compare it with the status quo: def bar(x=None, y=None): if x is None: x = [] if y is None: y={} it doesn't save a lot of typing and will be far more obscure to newbies who may not know about decorators. (And if other decorators are used on the same function, the fog only thickens.) They may not know why the contorted way of assigning to x and y is necessary, but they can follow what it does. Even someone familiar with decorators will have to look up supply_defaults and find out what it does (and it jolly well ought to be copiously documented :-)). Trying to do some blue-sky thinking, I have tried to come up with other ideas, but have not found anything very convincing, e.g.: Idea: Invent a new kind of string which behave like f-strings, called say g-strings. Add a rule that if the default value of an argument is (an expression containing) a g-string, the default value is recalculated every time the function is called and a value for that argument is not passed. So: def bar(x=g'{ [] }], y=g'{ {} }'): Cons: I could list a couple myself, no doubt others can think of many more. No, forget fudges. I think what is needed is to take the bull by the horns and add some *new syntax* that says "this default value should be (re)calculated every time it is needed". Personally I don't think the walrus operator is too bad: def bar(x:=[], y:={}): It's concise, and arguably will largely only confuse people who are already confused. It AKAICS introduces no ambiguity (it's currently a syntax error). It *is* somewhat arbitrary (in one context the walrus means 'this assignment becomes an expression', in another it means 'recalculate this expression every time it's needed'). But hey, you could say the same about colon, comma, parentheses, braces and what-have-you. It is IMO practical. It needs no new keywords. Other syntaxes are of course possible, but for me, in this case, conciseness is a virtue. YMMV. (Possibly heretical) Thought: ISTM that when the decision was made that arg default values should be evaluated once, at function definition time, rather than every time the function is called and the default needs to be supplied that that was the *wrong* decision. There may have been what seemed good reasons for it at the time (can anyone point me to any relevant discussions, or is this too far back in the Python primeval soup?). But it is a constant surprise to newbies (and sometimes not-so-newbies). As is attested to by the number of web pages on this topic. (Many of them defend the status quo and explain that it's really quite logical - but why does the status quo *need* to be defended quite so vigorously?) I realise that it's far too late to change this behaviour in Python 3. And also that there are uses for the current behaviour. (Though I can't recall having used it myself.) But maybe for Python 4?
On 25.05.20 03:03, Rob Cliffe via Python-ideas wrote:
Actually it was intended to use type annotations a la PEP 585 (using builtin types directly) and hence not requiring explicit specification of the factory: @supply_defaults def bar(x: list = None, y: dict = None): pass This also has the advantage that the types are visible in the function signature. Sure this works only in a limited number of cases, but the case of mutable defaults seems to be quite prominent, and this solves it at little cost.
What about using `~` instead of `:=`. As a horizontal symbol it has some similarity to `=` and usually "~" denotes proportionality which also allows to make a connection to the use case. For proportionality "x ~ y" means there's a non-zero constant "k" such that "x = k*y" and in the case of defaults it would mean, there's a non-trivial step such that `x = step(y)` (where `step=eval` roughly). def bar(x=1, y~[], z ~ {}): It looks better with spaces around "~" but that's probably a matter of being used to it. A disadvantage is that `~` is already a unary operator, so one could do this: `def foo(x~~y)`. But how often does this occur anyway?
On Mon, May 25, 2020, 6:49 AM Rob Cliffe via Python-ideas < python-ideas@python.org> wrote:
Not heretical so much as just half-baked. DISCLAIMER: I'm far from an expert. I'm not even a professional developer. But I think the idea that handling defaults this way was a mistake from the beginning is exactly wrong, and that this aspect of python doesn't need to be touched. I think that people who complain about this are missing the largeness of some fundamental problems that changing it would cause. And I think the set of decisions that would have to be made to implement it- no matter what those decisions they are- would lead to no end frustration, probably more than the current state of affairs. *First of all*: supplying a default object one time and having it start fresh at every call would *require copying the object*. But it is not clear what kind of copying of these default values should be done. The language doesn't inherently know how to arbitrarily make copies of every object; decisions have to be made to define what copying the object would MEAN in different contexts. Would it mean: *1.* copy.copy() applied to the object every function call? *2.* copy.deepcopy() applied every function call? The two options above would allow the object class to decide HOW the copying occurs (by relying on the default copy.copy or copy.deepcopy method, or providing __copy__ or __deepcopy__). But it would NOT allow the class to decide WHICH CHOICE is made-- copy, or deepcopy. No matter which is chosen, it will be problematic. deepcopy() will be desirable sometimes, copy() will be desirable other times. And other times, NEITHER will be desirable. copy/deepcopying doesn't even always actually make a copy, which will be unexpected for some: class C: ... copy(C) is C # True copy('xyz') is 'xyz' # True Some objects in the wild are simply not meant to be copied, but ignorant users WILL try to use them as copied defaults anyway ("ignorant" not used as a sleight; it is critical for being productive developer to maintain just the right level of ignorance so that I do not have to CARE about details of the things I am using). If a user tries to use such an object like so: from foo import bar def h(a:=bar()): ... ...it will require the creator of the foo library to maintain a __copy__ or __deepcopy__ method to provide an error message telling the user their object can't be used this way. And copying doesn't come for free; copying persistent objects, especially that take up a lot of memory at every function call, rather than freshly initializing them, could become extremely slow. Yes, this can be circumvented by simply not using the new feature. However, then you have to explain, in detail, how to know when to use the feature or not. *SIGH*. On top of this, Python already has a reputation for slowness; some of this is earned, some if it isn't and is just a result of people writing bad python code. If we made it EASY and actually encouraged people-- by providing a specific feature-- to get in the habit of writing code that slows things down considerably, this seems like a bad plan. Worse: it will create a situation where for every public-facing type, every developer of every library will have to stop for a minute and think "What will happen if the user tries to make my object work using the new := copy-at-call feature?" Allowing objects to be faithfully copied, OFTEN, is generally NOT a concern I worry about at all. I am not sure if pro developers do either, but I doubt it. *3.* The language does something more fancy like an eval() of the actual code text entered into the default parameter definition. If this 3rd one: do references inside of this definition get updated at the time of the call? Or do we create different behavior depending on whether the default value is a literal? Both could feel unexpected to the user depending on the case: # literal case def f(a:=[]): ... f() # a inside f is eval('[]') at call time; no problem here # non literal case _A = [] def g(a := _A): ... _A.append(1) g() What is the default of a inside g() here? eval ('_A'), which is [1]? Would not THAT be every bit as confusing to a newbie as the current situation? If we want the value of a in g() to be [1], an object does not be able to control how it is copied; the current copy/deepcopy machinery has to be totally circumvented. If we want the default value of a in g() to be [], we'll need some combination of *1* *or* *2* *and* *3*: an eval() of the initial value when the module runs, and then at the function call, a copy() or deepcopy() is applied to whatever was evaluated at the module import. It seems to me that this second version of *3* -- an eval followed by a copy() or deepcopy() -- makes the most sense and would be least surprising. However, now you still run into all of the same pitfalls that need to be solved in the case of *1* and *2*. *4.* Instead of copy() or deepcopy(), use the same basic copying algorithm contained therein, but with no calls to __copy__ and __deepcopy__; it is essentially a new kind of copying operation. This would make things a little faster. But this way of copying is another thing I have to learn if I want my user defined objects to behave in predictable and thoroughly understood ways. *Second of all*: no matter which way forward is chosen, it seems to be that this new syntax would have to slow things down, considerably in many cases. To summarize: We are already talking about making things easier to understand for the type of new coder that finds this issue confusing, but I don't think it is going to be THAT much easier to explain to the same coder that: A. there are two ways to provide default values for function parameters, = and := B. you can make sure you have a fresh new object every time by using the new shiny := syntax! C. ...except you often shouldn't use that because it will needlessly slow things down for large objects D. also, let me explain to you the difference between copy and deepcopy... hold on, yeah i know that's not what you asked about, just hear me out E. oh btw now that you understand about copy/deepcopy, many objects aren't copied even if you use the := --- Ricky. "I've never met a Kentucky man who wasn't either thinking about going home or actually going home." - Happy Chandler
On 25.05.20 17:29, Ricky Teachey wrote:
It wouldn't copy the provided default, it would just reevaluate the expression. Python has already a way of deferring evaluation, generator expressions: >>> x = 1 >>> g = (x for __ in range(2)) >>> next(g) 1 >>> x = 2 >>> next(g) 2 It's like using a generator expression as the default value and then if the argument is not provided Python would use `next(gen)` instead of the `gen` object itself to fill the missing value. E.g.: def foo(x = ([] for __ in it.count())): # if `x` is not provided use `next` on that generator pass Doing this today would use the generator itself to fill a missing `x`, so this doesn't buy anything without changing the language.
On Tue, May 26, 2020 at 2:24 AM Dominik Vilsmeier <dominik.vilsmeier@gmx.de> wrote:
Well.... if you want to define the semantics that way, there's a way cleaner form. Just talk about a lambda function: def foo(x = lambda: []): pass and then the function would be called and its return value assigned to x, if the parameter isn't given. But if this were actual language syntax, then it would simply be "the expression is evaluated at call time" or something like that. ChrisA
On Mon, May 25, 2020 at 12:33 PM Chris Angelico <rosuav@gmail.com> wrote:
This late binding is what I was clumsily referring to as option *3* (version with no copying). But this is still going to end up having what people would consider surprising behavior, is it not? It is essentially equivalent to this using current syntax: late_binder = lambda: [] def f(a = None): if a is None: a = late_binder() But if you have behavior like this (assuming the := syntax): _A = [] def f(a:=_A): ... ...which is the same as this: _A = [] def f(a=None): if a is None: a = _A Here's a little bit more fleshed out example: _complex_mutable_default = MyObj(a = 1, b = 2, c = 3, d = 4, e = 5, f = 6, g = 7, h = 8, i = 9, j = 10) def func(x := _complex_mutable_default): ... Above, _complex_mutable_default is *NOT* immutable-- it is *mutable*. It gets late-evaluated every call, rather than being evaluated at definition time. This is going to be pretty surprising for a lot of people. Of course it won't come up nearly as often as the current def `f(a=[]): ...` issue, but this will eventually need to be explained to people every bit as much as the "mutable default argument" issue. People will need to understand they can't do this, and have to do this instead: _complex_mutable_default_factory = lambda: MyObj(a = 1, b = 2, c = 3, d = 4, e = 5, f = 6, g = 7, h = 8, i = 9, j = 10) def func(x := _complex_mutable_default_factory()): ... Now, perhaps it will be worth this syntax change to capture a large portion of more simple cases. But I wonder if people will spend the next decade complaining about a new category of "surprising behavior" that needs to be fixed. Anyway, my opinion: I think things are fine as they are. It is not a heavy lift to perform the "if <thing> is None:" dance.
On Tue, May 26, 2020 at 7:19 AM Ricky Teachey <ricky@teachey.org> wrote:
I don't see how this is going to be any different from anything else. If you do the same thing using the current "=object()" idiom, and you break out the complex default into a global, then obviously you're asking for it to be evaluated only once. Surely that shouldn't be at all surprising. ChrisA

Hello, On Tue, 26 May 2020 07:34:32 +1000 Chris Angelico <rosuav@gmail.com> wrote: []
The more worrying sounds the idea to have a special evaluation context for specially marked default arguments. Just imagine - *everywhere* (#1) in the language the evaluation is eager, while for specially marked default arguments it's deferred. Which leads to the situation that: def foo(x := a + b) vs c = a + b def foo(x := c) can lead to different results. I'd suggest that people should love "explicit is better than implicit" principle of the language. And those who don't, aren't going to be satisfied by minor bend-in's like that - they will want more (while even small things like that will be confusing for all the rest). I'd suggest they're looking for generic macros facility instead, which in this particular case will allow them to wrap default argument expression in lambda, then insert if's in the body to call that lambda if the argument value is not provided. So, just revive https://www.python.org/dev/peps/pep-0511/ and rock on. (And that PEP is just a convenience, you can do everything needed for that right away, albeit in a nicely tangled manner.) #1: Except for https://www.python.org/dev/peps/pep-0563 , but annotations (and results of their evaluation) are not the part of the baseline language semantics (baseline == as implemented by CPython).
ChrisA
[] -- Best regards, Paul mailto:pmiscml@gmail.com
On Tue, May 26, 2020 at 8:06 AM Paul Sokolovsky <pmiscml@gmail.com> wrote:
def foo(x = None): if x is None: x = a + b c = a + b def foo(x = None): if x is None: x = c Is it surprising that these behave differently? You are refactoring something from a late-bound default argument value into a global variable. Surely it's obvious that it will now be evaluated once?
I'd suggest that people should love "explicit is better than implicit" principle of the language.
Explicit meaning that you need to use a specific symbol that means "this is to be late-bound"? Or explicit meaning "something that I like", as opposed to implicit meaning "something that I don't like", which is how most people seem to interpret that line of the Zen? ChrisA
On 5/25/2020 6:37 PM, Chris Angelico wrote:
That's a great comment, and so true. When f-strings were first proposed, people used that exact same line from the Zen to mean "I don't like f-strings". And I was always puzzled: in what way is it not explicit? The other old chestnut that bugs me is "but you won't be able to use this feature for years, because you'll have to support old versions of Python for so long". So what? That's true of every language feature ever added. Should we never add anything? This is really just a way to shut down changes, too. That said, I can say I'm -1 on any late binding proposal, just because I don't think the feature-to-cost benefit justifies it. I don't even need to appeal to any other argument! Eric
On Mon, May 25, 2020 at 06:45:47PM -0400, Eric V. Smith wrote:
We agree on that! But...
Well, there's this: f-strings look like strings. They're called strings. People think of them as not just strings but string literals. But they're actually executable code that is run at runtime, making them semantically an implicit call to `eval`. py> print("Actual string: {sum(len(s) for s in dir(builtins))}") Actual string: {sum(len(s) for s in dir(builtins))} py> print(f"Actual eval: {sum(len(s) for s in dir(builtins))}") Actual eval: 1882 The dissassembly of the regular string is two lines, specifically a LOAD_CONST and a RETURN_VALUE: py> dis.dis( ... compile('"Actual string: {sum(len(s) for s in dir(builtins))}"', ... '', 'eval')) 1 0 LOAD_CONST 0 ('Actual ...') 2 RETURN_VALUE (I've truncated the value of the constant for brevity.) The dissassembly of the f-string is twenty-five lines of byte-code, including four calls to CALL_FUNCTION. In my experience, people get defensive when you point this out, and say "But it returns a string, so its a string". By that logic, this function is a string too: lambda: str(sum(len(s) for s in dir(builtins))) The difference between the f-string and the lambda is that the lambda needs explicit parens to perform the computation, the f-string doesn't. Isn't the whole point of f-strings to iterpolate evaluated expressions into a format string without needing an explicit evaluation? -- Steven
Hello, On Tue, 26 May 2020 08:37:59 +1000 Chris Angelico <rosuav@gmail.com> wrote: []
Of course it will be obvious - you provided explicit control flow to make it work like that, and all that stays within the bounds of the existing semantics of the language.
No, it means "use explicit 'if' if you want to deal with mutable default".
I'd prefer to think in terms of implementation complexity. Implemented in adhoc way (and that's how things get implemented in C, in particular, in CPython), it will be quite a noticeable complexity up-glitch to function representation/implementation, and all it achieves is trading one confusion for another. (Well, for two others: why the heck there're 2 ways to define default args, which is to use when, and why one of them doesn't work across subexpression refactoring. Oh, and old confusion still stays with us. There's really no easy way to resolve the original confusion, short of banging mutable defaults. Which actually one that I'd like, because it would necessitate pushing "const" (currently, "Final") variable annotation down to the core of the language, for Python remains literally the last one which lacks it comparing to the competition.)
ChrisA
-- Best regards, Paul mailto:pmiscml@gmail.com
On Tue, May 26, 2020 at 02:25:38AM +0300, Paul Sokolovsky wrote:
Point of terminology here. Let's not conflate two separate issues. There is nothing wrong with putting a mutable default value directly in the function signature def func(param=[]): works absolutely fine for what it does. It's just that what it does is not what some people want it to do. The real issue is not mutable defaults as such, but early versus late binding.
To answer those questions: (1) There are two ways to define default args, because there *are* two ways to define default args: - calcuate the default argument once and re-use it as needed; - or re-calculate the default argument each time you need it. Asking why there are two ways is a very odd question. It's rather like asking why there are two ways to travel around a circle (clockwise and counter-clockerwise, and at least three ways to parse a binary tree (preorder, inorder, postorder). Because there just are, that's the nature of the thing. (2) You use whichever one you need for the specific function you are writing. Nobody can answer that except yourself. If you don't understand Python's object model well enough to answer that question, then you're going to be stumbling over problems in all sorts of things: a = [] b = a b.append(1) a == [1] # Why??? If you want the default value to be X, then: - if you want a fresh X each time, then you want late binding; - if you want the same X each time, then you want early binding; - if you don't care, then early binding is likely to be a little more efficient. (3) One of them doesn't work across subexpression refactoring for the exact same reason that it doesn't work in other function calls, and for the same reason it may not work *right now* with the `if arg is None` idiom: def func(arg=None): if arg is None: arg = print('computation') or [] versus: c = print('computation') or [] def func(arg=None): if arg is None: arg = c Likewise if you refactor an expression outside of a loop, the behaviour will change.
Oh, and old confusion still stays with us.
*shrug* People who code on automatic pilot without thinking about what the code they write *actually* means rather than what they *assume* it means are always going to be confused by one thing or another. I only have so much sympathy for people who get confused or angry when the language doesn't read their mind and Do What I Mean. At some hypothetical future point that Python has some syntactic method for explicitly marking defaults as late-binding: # straw-man proposal def func(s='', arg=mutable {}): if people continue to write `arg={}` when they want `arg=mutable {}` then I will have no sympathy for them. That's just a PEBCAK error, not a language flaw.
There's really no easy way to resolve the original confusion, short of banging mutable defaults.
How does the compiler know if an arbitrary object is mutable or not? When I want early binding of a mutable object, and I sometimes do, why should the compiler tell me I can't have it just because some other person may, or may not, be confused by the semantics of the language? -- Steven
On Mon, May 25, 2020 at 6:24 PM Dominik Vilsmeier <dominik.vilsmeier@gmx.de> wrote:
Agreed, it would definitely reevaluate each time, there would be no copying involved at any stage. And evaluating each time wouldn't be slow, it might even be faster than the `if x is None` check. Although if *all* defaults were changed to evaluate each time, that'd probably slow things down a little. A couple of examples where these kinds of semantics are needed: logging.StreamHandler has: ``` def __init__(self, stream=None): if stream is None: stream = sys.stderr ``` This doesn't use a normal default so that something can patch sys.stderr (very common and useful) before instantiating the handler but after importing logging. The code: ``` if context is None: context = getcontext() ``` appears 44 times in _pydecimal.py, although I can't guarantee that all of them could be replaced by one of these proposals.
On Mon, May 25, 2020 at 06:22:14PM +0200, Dominik Vilsmeier wrote:
A function would be a more obvious mechanism. But this won't work to solve the mutable default problem. Here's a simulation: # we want to delay evaluation for arg=x # in this case we have arg=[] x = [] g = lambda: x def func(): arg = g() return arg At first it seems to work: py> func() [] py> func() [] But we have the same problem with mutable defaults: py> L = func() py> L.append(1) py> func() [1] The problem is that this model just reuses the object referenced in x. That's early binding! Python functions don't use a hidden function or generator `g`, as in this simulation, or a global variable `x`. They stash the default value inside the function object, in a dunder attribute, and then retrieve it when needed. To get late binding, you need to stash not the *value* of x, in this example an empty list `[]`, but some sort of code which will create a new empty list each time. A naive implementation might stash the source code expression and literally evaluate it: x = '[]' g = lambda: eval(x) but there are probably faster ways: x = '[]' g = eval('lambda: %s' % (x,)) One way or the other, late binding has to re-evaluate the expression for the default value. Whether it uses the actual source code, or some clever byte-code, it has to recalculate that value each time, not just retrieve it from somewhere it was stashed. -- Steven
On Mon, May 25, 2020 at 02:03:49AM +0100, Rob Cliffe via Python-ideas wrote: [quoting Dominik Vilsmeier]
It looks like the most common use case for this is to deal with mutable defaults
It might be the most common use case, but it's hardly the only use case. The PEP talks about special cases :-) I can tell you that it is very frustrating to what to do something and not be able to do it, not for good design reasons, or for implementation reasons, but simply because the language designers chose to support only a subset of behaviour. Mutable defaults is a subset of late-binding defaults. A solution to late-binding automatically solves the mutable default question. Why settle for half a solution? Looking at some of my mutable defaults, I've used the usual `[]` and `{}` of course, but I've also used `[0]` amd other pre-populated lists, sets and dicts, and instances of custom classes. I've also used default values that are functions themselves, which are technically mutable even if we don't typically mutate them. I've also used plenty of *immutable* defaults, where I have wanted them recalculated on each use. [Rob]
Idea: Invent a new kind of string which behave like f-strings, called say g-strings.
G-strings? *cough*
That's pretty much the same rule I've been working on for my proto-PEP, except for the "g-string" part. I know that f-strings have become super-popular, but that doesn't make every piece of syntax a nail that we hammer with the "random-letter"- string until we have 26 different string prefixes :-) [...]
It really wasn't a mistake. Look at your default values: the great majority of defaults need to be evaluated only once. Making every default value a late-bound expression would be wasteful of time and memory. (Although a sufficiently smart compiler could minimize that waste in the common case of immutable literals. How? By sneakily shifting to early binding and avoiding the late evaluation!) There's also at least two execution models for late binding that I know of, and which ever one you chose, some people would complain that it's not the right one. If you can only have one model for function defaults, early binding is the clear winner. With early binding, it is easy to implement late binding in the function body using the "if None: arg = value" idiom. But with late binding, it is *seriously* inconvenient and difficult to go the other way and implement early binding semantics.
But it is a constant surprise to newbies (and sometimes not-so-newbies).
Yes, people say that they want late binding. Then they use closures, which implement late binding, and they complain that it's a bug and it was the wrong decision to use late binding. Then they go back to writing a function definition, and complain that they should have used late binding. I remind you that the usual work-around for the "closures use late binding" gotcha is to use *early binding* to fix it. The gotcha: py> def func(): ... L = [] ... for i in range(3): ... # closure using late binding for i ... L.append(lambda: 100+i) ... return [f() for f in L] ... py> func() [102, 102, 102] The solution is to work around the problem with early binding: py> def func(): ... L = [] ... for i in range(3): ... # work around the problem ... L.append(lambda i=i: 100+i) ... return [f() for f in L] ... py> func() [100, 101, 102] If functions used late binding for all defaults: - people would still be surprised, just as they are with closures; - it would be wasteful of time and memory, slowing down function calls for no good reason; - it would make early binding semantics really difficult; - and it would destroy the work-around for late binding, preventing it from working. Late binding of function defaults an option? Sure. But if Python had used late binding for all defaults, with no way to opt out, the language would be significantly worse: slower, heavier memory usage, and more annoying to use. -- Steven
Certainly the way default arguments work with mutable types is not the most intuitive and I think your complaint has some merit. However how would you define the following to work: def foo(): cons = [set(), [], (),] funs = [] for ds in cons: def g(arg:=ds): return arg funs.append(g) return funs How would you evaluate "ds" in the context of the call? If it were to have the same observable behavior as def g(arg=ds) except that you would get "fresh" reference on each invocation you would get the following: assert [f() for f in foo()] == [set(), [], ()] Note it cannot be a simple syntactic transform because: class _MISSING: pass def foo(): cons = [set(), [], (),] funs = [] for ds in cons: def g(arg=_MISSING): if arg is _MISSING: arg = eval('ds') # equivalent to arg = ds so does not produce a fresh reference return arg funs.append(g) return funs assert [f() for f in foo()] == [(), (), ()] Granted the way closures work (especially in the context of loops) is also a pretty unintuitive, but stands as a barrier to easily implementing your desired behavior. And even if that wasn't the case we still have the issue that eval('ds') doesn't give you a fresh reference. Would it implicitly deepcopy ds? e.g.: class _MISSING: pass def build_g(default): def g(arg=_MISSING): if arg is _MISSING: arg = deepcopy(default) return arg return g def foo(): cons = [set(), [], (),] funs = [] for ds in cons: g = build_g(ds) funs.append(g) return funs What if ds doesn't implement __deepcopy__? On Mon, May 18, 2020 at 7:11 AM Richard Damon <Richard@damon-family.org> wrote:
I have already replied to the OP and to the list, but there seems to be a problem with my posts getting through, so let me try again. Apologies if you see this twice: To strip at most 1 character from the end: txt[:-1] + txt[-1:].rstrip(chars) To strip at most N characters: txt[:-N] + txt[-N:].rstrip(chars) Rob Cliffe On 18/05/2020 19:32, Caleb Donovick wrote:
On Mon, May 18, 2020 at 11:32:29AM -0700, Caleb Donovick wrote:
Certainly the way default arguments work with mutable types is not the most intuitive
Neither is the alternative. def function(arg=calculate_default_value()): "What do you mean that extremely expensive calculation is performed on every function call?" "What do you mean, my default value can change from one call to the next, if the ennvironment changes?" Besides, there are at least two distinct semantics of late-binding for default values, and I guarantee that which ever one we pick, somebody is going to complain that it's the wrong one and "not intuitive". - late-bound defaults are closures, like nested functions; - late-bound defaults aren't closures, but like global lookups. Trying to base programming semantics on "intuition" is a losing prospect, because people's intuition depends so critically on their level of knowledge. To me, it is intuitively obvious that of course function defaults use early binding. Function definitions are executable statements, which implies that the default is evaluated at the same time the `def` is executed, not when the function is called. If you can't have a choice between early and late binding in a language, the sensible choice is to use early binding: - early binding is easier to implement and more efficient; - given early binding at the language level, providing late binding semantics in the function is trivial; - but given late binding at the language level, providing early binding semantics in the function is horrible. So if you asked me, I would say that early binding is the obvious, intuitive choice for function defaults. I've worked with people who insist that early binding is the "intuitive" choice in one context, and then insist that early binding is totally confusing and late binding is the "intuitive" choice in another context. And they don't like having their own words quoted back at them *wink* -- Steven
Thank you for raising a good point. I think we should ban referencing variables not in the nearest outer enclosing scope until best practices regarding closures emerge. For example: global_var = 5 class A: # not ok: def foo(a:=global_var): pass class_var = global_var # ok: def foo(a:=class_var): pass for a in [1, 2, 3]: # not ok: def callback(a:=a): pass local = a # ok: def callback2(a:=local): pass This way, the design space is kept open.
On Wed, May 20, 2020 at 10:19 PM James Lu <jamtlu@gmail.com> wrote:
Another extremely plausible interpretation is that the expression is evaluated inside the function itself. def frobnicate(stuff, start=0, end=len(stuff)): ... I don't think you can punt on this one. The semantics are going to need to be well-defined from the start. ChrisA
On Mon, May 18, 2020 at 01:06:22PM -0000, James Lu wrote:
"There should be one-- and preferably only one --obvious way to do it."
Yes? "There should be one" does not mean the same thing as "there shouldn't be two". "There should be one qualified pilot in the cockpit of the plane at all times during the flight" is not the same as "There should not be two qualified pilots in the cockpit". -- Steven
I think only using the first third of the quote makes your argument too terse Steven. To include the second part: "There should be one-- and preferably only one" which implies "It is preferable there is exactly one qualified pilot in the cockpit", and we arrive (if abbreviated) at what James said. However, to use the full quote as inspiration: "There must be at least one qualified pilot in the cockpit and there should not be a tie for seniority" and it flips again! Regardless Steven, I don't think it matters (except for setting the record straight[1]), they are not essential to his proposal? He uses this idea in his argument to say we should adopt *one* of := and ?=. Firstly, I think his application there is correct (if you assume at least one would be adopted, I think only one would be) but secondly I think his email has a strong air of false dichotomy: Python could well adopt a different solution or no solution at all and those are perfectly acceptable outcomes and I would advocate "no solution" as I prefer it over his two proposals. [1] https://xkcd.com/386/ On Tue, 19 May 2020 at 01:33, Steven D'Aprano <steve@pearwood.info> wrote:
The "if arg is None: arg = " pattern occurs in the standard library eighty-five (85) times. This command was used to find the count: ~/cpython/Lib$ perl -wln -e "/(?s)^(\s*)[^\n]if ([a-zA-Z_]+) is None:(\n)?\s+\2\s*=\s*/s and print" **
On 20/05/2020 02:13, James Lu wrote:
The "if arg is None: arg = " pattern occurs in the standard library eighty-five (85) times.
You say that like it's a bad thing. Given that it's completely clear what's going on -- you don't need to understand or guess at the syntax -- I'm really not seeing the problem here. -- Rhodri James *-* Kynesim Ltd
On Wed, May 20, 2020 at 12:23 PM Rob Cliffe via Python-ideas <python-ideas@python.org> wrote:
It would be a major breaking change if ALL default arguments were late-evaluated. Errors wouldn't be caught till later, performance would suffer, and semantics would change. More plausible would be to have a syntactic adornment that triggers this, making it completely opt-in. The semantics would be subtly different from the None variety, being more like the similar variant involving a sentinel: def spam(x, y, ham=object()): if ham is spam.__defaults__[-1]: ham = {} But with actual language support, the sentinel object wouldn't be visible anywhere, and anything involving docstrings would show the original text used, which would be WAY more helpful. This has been proposed frequently and never gone far, and I think it's because nobody can settle on a really good syntax for it. Consider: # Looks like an old Py2 repr def spam(x, y, ham=`{}`): # Way too magical, although it parses currently and might # be done with the help of a magic built-in def spam(x, y, ham=LATE%{}): # wut? def spam(x, y, ham=>{}): # even worse def spam(x, y, ham=->{}): etc etc etc. There are lots of bad syntaxes and very few that have any merit. I'd love to have this as a feature, though. ChrisA
On Wed, May 20, 2020 at 07:56:32PM +1000, Chris Angelico wrote:
What I really need is an extra 12 hours a day, and a lot fewer distractions and a lot more Round Tuits :-) I may send you a draft over the weekend for comments. -- Steven
On Wed, May 20, 2020 at 8:04 PM Steven D'Aprano <steve@pearwood.info> wrote:
Ahh, don't we all...
I may send you a draft over the weekend for comments.
Cool. If you do, I'll comment. If not, I won't. :) ChrisA
On Wed, May 20, 2020 at 5:35 AM Eric V. Smith <eric@trueblade.com> wrote:
What's wrong with confusion with the walrus operator? - If you are confused and don't know what walrus operator is, you google it and find that in a function header it means late assignment. - If you are confused and think it's referring to the walrus operator's use for inline variable assignment - well so what - it is being used as assignment here! - If you are confused and think := is binding at import-time rather than call-time - well you already are a somewhat advanced python user to be thinking about that and the use of a different syntax to bind the argument should trigger you to google it.
On 5/20/2020 9:48 AM, Peter O'Connor wrote:
I think every proposal, especially for syntax and operators, should be judged on how confusing it is to new and experienced users alike. In my mind, using the walrus operator for early binding utterly fails that test, but of course other people will have different opinions. The fact that operators are notoriously difficult to search for doesn't help any. Eric
On Thu, May 21, 2020 at 12:11 AM Eric V. Smith <eric@trueblade.com> wrote:
The fact that operators are notoriously difficult to search for doesn't help any.
The fact that people STILL think that operators are difficult to search for doesn't help either. Google for "python :=" and PEP 572 is the first hit. DuckDuckGo for "python :=" didn't give any good results; my next thought was "python := operator" which didn't do much good. For most of the common operators, you'd get it from "python operator precedence", but unfortunately DDG is showing Python 2.7 search results above Python 3, so you'd have to go down to the page eighth in the search results, then browse the table. But when you do get there, it's not too hard to glance over the table, find that ":=" is an "assignment expression" and go from there. Bing for "python :=" has what looks like three paid search results, and then the first real result is Stack Overflow asking what the colon equal (:=) operator means, and even though the question is older than PEP 572, the accepted answer has been updated to link to it. Yandex failed to find the := operator specifically, but as with DDG, I had to go for "python operator precedence". Fortunately, it did give the Py3 page as the first hit. I tried a few of the more obscure search engines, and most of them seem to give the same results as one of the above. (I suspect quite a few of them get their results from one of the big ones anyway.) So two very popular search engines (Google and Bing) give excellent results straight away, and everything can at least find the operator precedence table, which is a good way to get started. I have to penalize DuckDuckGo a bit for not putting current version results at the top, but even then, it WAS on the first page, and of course you can always say "python 3 operator precedence". Operators ARE searchable. ChrisA
On 5/20/2020 11:26 AM, Chris Angelico wrote:
I think you meant ":= is searchable using half search engines I tried, both of which are very popular". Which might be good enough for this particular proposal, but I disagree. I couldn't get anywhere with single character operators and Google. So you haven't shaken my faith in my assertion. Eric
On Thu, May 21, 2020 at 2:27 AM Eric V. Smith <eric@trueblade.com> wrote:
Actually ":= is searchable using half the search engines I tried, and with the other half, 'python operators' gets a page with all operators, from which you can get the info you need". All the search engines I tried DID get the results I wanted; some more easily than others, but all got there.
I couldn't get anywhere with single character operators and Google. So you haven't shaken my faith in my assertion.
Hmm, good point. You can Google for "python @=" but not "python @". Strange. But you can still just look for all operators and go from there. And there are some word-based things that are also hard to search for, so at that point it becomes a wash. ChrisA
On 20 May 2020, at 16:08, Eric V. Smith <eric@trueblade.com> wrote:
I think every proposal, especially for syntax and operators, should be judged on how confusing it is to new and experienced users alike. In my mind, using the walrus operator for early binding utterly fails that test, but of course other people will have different opinions.
I’d like to +1 on this one, not to mention that the walrus operator is still largely not-too-well-known, and this IMHO would add to the confusion; utterly is the word indeed :)
I don't see myself using := for a few years, because support for Python 3.8 is not widespread yet among PyPy. However, that doesn't mean I oppose evolving the language further so that down the line when Python 3.10 is ready, I'll have juicy new features to use.
"<:" Does not give the user any intuition about what it does. "<~" Ok, but same problems as "<:" and precludes the use of "<~~" due to Python's parser. "::" Could be confused with Haskell's type declaration operator. If we want to avoid confusion with the walrus operator, "options!?=..." is a decent alternative. It can be remembered as "if not there? equal to" [! there? =].
Have you seen PEP 505? https://www.python.org/dev/peps/pep-0505/ I'm still praying they add "??=" every time I need it. Maybe if someone proposed just that operator, it would go a long way towards simplifying code without resulting in endless debates? Best, Neil On Sunday, May 17, 2020 at 3:23:59 PM UTC-4, James Lu wrote:
On Sun, May 17, 2020 at 07:17:00PM -0000, James Lu wrote:
Thus, only one of ":=" or "?=" should be adopted. They should be evalued on:
That does not logically follow. Even if we accept your idea that we should have special syntax for late-binding of function defaults, and that's not clear that we should, it does not follow that the only two possible choices are `:=` and `?=`. They might be your preferred choice, but that doesn't mean that "only one of ... should be adopted". We could instead: - choose something else; - or choose nothing at all and stick to the status quo. In any case, we should rule out `:=` of contention, because it already has a meaning as the "walrus operator" for assignment expressions, which makes it legal in function defaults: def func(x=(a:=expression), y=a+1): This is already valid in 3.8, so we should forget about overloading `:=` with a second meaning.
Do we want to encourage callers to pass None to indicate default arguments?
That isn't up to us, that's up the writer of the function being called. There is a thirty year tradition of functions using None for default arguments, that's not going to go away. Neither are we going to force function writers to accept None as a default. So the way functions can be called will depend partially on the function itself, and partially on the caller's personal choice for how they prefer to handle defaults.
Being strongly typed, or weakly typed, has nothing to do with return statements. In Python, there is a 30 year tradition of being permitted to leave out the return statement in functions or methods intended to be used as "procedures" that operate by side-effect with no meaningful return value. We aren't going to break thousands of programs by making it an error to leave out the return statement. -- Steven
This is already valid in 3.8, so we should forget about overloading := with a second meaning.
def func(x=(a:=expression), y=a+1): def func(x:=options): These two syntaxes do not conflict with each other.
If it wasn't clear originally, I meant to ask, what is the best practice that should be encouraged? And we're not 'forcing' anyone, we're just making an easier syntax for doing something. There's a thirty year tradition of doing that because there's no terser way to do it. Out of the 85 instances I found in the STL, only 5 instances used "if arg is None: arg = " in one line. The others used a two-line form. Having to read 2 lines to understand a common language pattern is inefficient.
On 20/05/2020 23:20, James Lu wrote:
There's a thirty year tradition of doing that because there's no terser way to do it.
Terser does not mean better. In my experience, terser code is often harder to comprehend, particularly when you are talking about squashing a couple of lines together like this. -- Rhodri James *-* Kynesim Ltd
On Thu, May 21, 2020 at 9:58 PM Rhodri James <rhodri@kynesim.co.uk> wrote:
Except when it's more expressive. Imagine if Python didn't have ANY argument defaults, merely permitted you to make arguments optional: def int(x, ?base): if base is UNSET: base = 10 ... Would you agree that simply writing "base=10" is better? You're right that terser does not ALWAYS mean better, but "more expressive" often compasses both better and terser. Terser definitely does not mean worse. ChrisA
On Thu, May 21, 2020 at 12:27 AM James Lu <jamtlu@gmail.com> wrote:
Technically no, but there is potential to confuse beginners. What about: def func(x=:options): or a more realistic example: def func(options=:{}): It still looks like `func(x=<default>)` but the `<default>` starts with a modifier `:` to say 'this is evaluated each time'. `:<expression>` can loosely be thought of as a shorthand for `lambda: <expression>` where said lambda function is called each time the def function is called, although it probably wouldn't actually work that way. One problem is that this conflicts with some other possible syntaxes that some people might want. For example I think `:<expression>` has already been proposed precisely as a shorthand for `lambda: <expression>` in general. Some might also want `:name` to mean some kind of keyword object like in Clojure. Personally I think the best way forward on this would be to accept PEP 505. It wouldn't solve this particular problem in the most concise way but it would be pretty good and would be more broadly useful. I see the PEP is 'deferred' - what does that mean exactly? What possible paths are there to acceptance? Is the rationale for deferral documented anywhere? Are people supposed to just read all the old discussion(s) and add more posts?
Is `?=` an operator? One could define `a ?= b` as `if a is None: a = b` (which is similar to make's operator, for example). Compare: def func(arg, option=None): option ?= expr #impl instead of: def func(arg, option=None): if option is None: option = expr #impl def func(arg, option=None): if option is None: option = expr #impl def func(arg, option=None): option = expr if option is None else option #impl def func(arg, option=None): option = option if option is not None else expr #impl or the proposed: def func(arg, option?=expr): #impl One could argue that the OP proposal is cleaner, but it adds *another* special notation on function definition. On performance, this would have tobe evaluated most likely upon entering the call. With the `if` guards or a hypothetical `?=` assignment, the programmer can better control execution (other arguments and/or options may render the test irrelevant). The great disadvantage of the `if` guard is a line of screen and an identation level, (which reminds me of PEP 572 rationale). I don't really like this `?=` assignment aesthetically, but I have written code that would look cleaner with it (though beauty is the eye of the beholder). Implementing only this operator would be at least simpler than both OP proposal and full PEP 505 (see also Neil Girdhar post above).
On 22/05/2020 02:10, Tiago Illipronti Girardi wrote:
Is `?=` an operator? One could define `a ?= b` as `if a is None: a = b` (which is similar to make's operator, for example).
PEP 505 (https://www.python.org/dev/peps/pep-0505/) prefers "??=". That's a discussion that comes back now and again, but doesn't seem to get much traction one way or another. -- Rhodri James *-* Kynesim Ltd
On Thu, May 21, 2020 at 2:50 PM Alex Hall <alex.mojaki@gmail.com> wrote:
Having thought about this problem a bit more, I'm now less sure of this stance. I think there's a decent benefit to being able to specify a late/lazy default in the signature that goes beyond being concise, and I don't think anyone has mentioned it. Signatures are an important source of information beyond their obvious essential need. They're essentially documentation - often the first bit of documentation that human readers look at when looking up a function, and often the only documentation that automated tools can use. And defaults are an important part of that documentation. Take a look at the official documentation for these callables and their parameters which default to None: https://docs.python.org/3/library/collections.html#collections.ChainMap.new_... https://docs.python.org/3/library/logging.handlers.html#logging.StreamHandle... https://docs.python.org/3/library/json.html#json.dump (in particular the `cls` parameter) (we may not be able to change these signatures due to compatibility, but they should still demonstrate the point) In all cases it's not immediately clear what the actual default value is, or even what kind of object is meant to be passed to that parameter. You simply have to read through the documentation, which is quite verbose and not that easy to skim through. That's not the fault of the documentation - it could perhaps be improved, but it's not easy. It's just English (or any human language) is not very efficient here. Imagine how much easier it would be to mentally parse the documentation if the signatures were: ``` ChainMap.new_child(m={}) StreamHandler(stream=sys.stderr) json.dump(..., cls=JSONEncoder, ...) ``` In the case of json.dump, I don't know why that isn't already the signature, does anyone know? In the other cases there are good reasons those can't be the actual signatures, so imagine instead the ideal syntax for late binding. The point is that the signature now conveys the default as well as the type of the parameter, and there's less need to read through documentation. Conversely you can probably also write less documentation, or remove some existing clutter in an upgrade. There's a similar benefit if the author hasn't provided any documentation at all - it's not nice to have to read through the source of a function looking for `if m is None: m = {}`. The signature and its defaults are also helpful when you're not looking at documentation or source code at all. For example, PyCharm lets me press a key combination to see the signature of the current function, highlighting the parameter the caret is on. Here is what it looks like for `json.dumps`: [image: Screen Shot 2020-05-22 at 21.32.21.png] That's not very helpful! Here's the same for logging.StreamHandler: [image: Screen Shot 2020-05-22 at 21.33.08.png] That's sort of better, but mentally parsing `Optional[IO[str]]=...` might just slow me down more than it helps. PyCharm also uses defaults for rudimentary type checking. For example, if you set `{}` as a default value, it assumes that parameter must be a dict, and warns you if you enter something else: [image: Screen Shot 2020-05-22 at 21.35.07.png] Of course it also warns that the parameter has a mutable default, which this proposal could solve.
Alex Hall writes:
In all cases it's not immediately clear what the actual default value is, or even what kind of object is meant to be passed to that parameter.
I agree with the basic principle, but I'm not sure this is a very strong argument. First, if you want to indicate what the type of the actual argument should be, we have annotations for that exact purpose. (Granted, these don't deal with situations like "should be nonempty," see below.) Second, in many cases the default value corresponding to None is the obvious mutable falsey: an empty dict or list or whatever. Viz:
Assuming that in many other cases we could fix the signature in this way, are the leftovers like StreamHandler important enough to justify a syntax change? I have no opinion on that, it's a real question.
The point is that the signature now conveys the default as well as the type of the parameter,
Except that it doesn't convey the type in a Pythonic way. How much of the API of dict must 'm' provide to be acceptable to ChainMap? Are there any optional APIs (i.e., APIs that dict doesn't have but ChainMap would use if available) that must have correct semantics or ChainMap goes "BOOM!"? Are non-empty mappings acceptable?! This doesn't change my lack of opinion. :-) Clearly, it's useful to know that dicts (probably including non-empty ones ;-) are acceptable to new_child, that sys.std* output streams are (probably ;-) acceptable to StreamHandler, and that cls should (probably ;-) encode Python data to JSON. Those are all good enough bets that I would take them. But it isn't as big a help as it looks on first sight, in particular to somebody who has a partially duck-type-compatible object they would like to use.
On Sat, May 23, 2020 at 2:52 PM Stephen J. Turnbull < turnbull.stephen.fw@u.tsukuba.ac.jp> wrote:
Yes, but many people can't be bothered to write annotations. This change would mean that I get extra type information even when using a function written by a programmer making as little effort as they can. Besides that, type annotations are often not easy to read - see the StreamHandler screenshot. An example of an acceptable value is additionally helpful.
A programmer making the least effort wouldn't update themselves on the grammar: the patch would be useless.
On Sat, May 23, 2020 at 11:34 PM Tiago Illipronti Girardi < tiagoigirardi@gmail.com> wrote:
A programmer making the least effort wouldn't update themselves on the grammar: the patch would be useless.
This is taking my words a bit far. Typing annotations are tedious and have to be done every time you want to provide typing information. It's easy to just not write them. I'd be surprised if anyone here *always* annotates every function they write. Learning a bit of new syntax is something you do once or twice. Plus it's hard to avoid learning it, especially if you come across the syntax in someone else's code. And once you know about it, it's the natural lazy option over `if foo is None: foo = {}`.
On Thu, May 21, 2020 at 02:50:00PM +0200, Alex Hall wrote:
Forget beginners, I know that will confuse me! Technically, *yes*, they do conflict. Ask yourself what the walrus operator `:=` means in Python 3.8, and you have a single answer: - "it's like `=` only it works as an operator". Now ask yourself what the walrus operator means if James' proposal is accepted. The answer becomes: - "well, that depends on where you see it..." or: - "in this context, it's like `=` only it works as an operator" - "but in this context, it changes the meaning of assignment completely to something very different to how the `=` works everywhere else" That's certainly a conflict. This isn't necessarily a deadly objection. For example, the `@` symbol in decorator syntax and the `@` symbol in expressions likewise conflicts: @decorate(spam @ eggs) def aardvark(): ... but both uses of the `@` symbol well and truly proved their usefulness. Whereas in this case: - the walrus operator is still new and controversial; - James' proposed `:=` in signatures hasn't proven it's usefulness.
What about:
def func(x=:options):
As a beginner, it took me months to remember to use colons in dict displays instead of equals signs, and they are two extremely common operations that beginners learn from practically Day 1. Even now, 20 years later, I still occasionally make that error. (Especially if I'm coding late at night.) You're proposing to take one uncommon operator, `:=`, and flip the order of the symbols to `=:`, as a beginner-friendly way to avoid confusion. As if people don't get confused enough by similar looking and sounding things that differ only in slight order. To steal shamelessly from the stand-up comedian Brian Regan: I before E except after C, or when sounding like A like in NEIGHBOUR and WEIGH, on weekends and holidays, and all throughout May, you'll be wrong no matter what you say.
or a more realistic example:
def func(options=:{}):
Add annotations and walrus operator: def flummox(options:dict=:(a:={x: None})): and we now have *five* distinct meanings for a colon in one line.
Personally I think the best way forward on this would be to accept PEP 505.
For the benefit of those reading this who haven't memorised all multiple-hundreds of PEPs by ID, that's the proposal to add None-aware operators to the language so we can change code like: if arg is None: arg = expression into arg ??= expression In this thread, there has been hardly any mention of the times where None is a legitimate value for the argument, and so the sentinal needs to be something else. I have written this many times: _MISSING = object() def func(arg=_MISSING): if arg is _MISSING: arg = expression Null-coalescing operators will help in only a subset of cases where we want late-binding of default arguments. -- Steven
On Sat, May 23, 2020 at 2:37 AM Steven D'Aprano <steve@pearwood.info> wrote:
OK, let's forget the colon. The point is just to have some kind of 'modifier' on the default value to say 'this is evaluated on each function call', while still having something that looks like `arg=<default>`. Maybe something like: def func(options=from {}):
On Sun, May 24, 2020 at 12:36 PM Alex Hall <alex.mojaki@gmail.com> wrote:
I worry so very little about this issue of mutable defaults that this discussion has trouble interesting me much. It's a speed bump for beginners, sure, but it's also sometimes a sort of nice (but admittedly hackish) way of adding something statefull to a function without making a class. On the other hand, I mostly thought it was cool before generators even existed; nowadays, a generator is more often a useful way to have a "stateful function" (yes, I know there are some differences; but a lot of overlap). The pattern: def fun(..., option=None): if option is None: option = something_else Becomes second nature very quickly. Once you learn it, you know it. A line of two of code isn't a big deal. But this discussion DOES remind me of something much more general that I've wanted for a long time, and that has had long discussion threads at various times. A general `deferred` or `delayed` (or other spellign) construct for language-wide delayed computation would be cool. It would also require rethinking a whole lot of corners. I think it would address this mutable default, but it would also do a thousand other useful things. Much of the inspiration comes from Dask. There we can write code like this simple one from its documentation: output = []for x in data: a = delayed(inc)(x) b = delayed(double)(x) c = delayed(add)(a, b) output.append(c) total = delayed(sum)(output) However, in that library, we need to do a final `total.compute()` to get back to actual evaluation. That feels like a minor wart, although within that library it has a purpose. What I'd rather in a hypothetical future Python is that "normal" operations without this new `delayed` keyword would implicitly call the .compute(). But things like operators or most function calls wouldn't raise an exception when they try to combine DelayedType objects with concrete things, but rather concretize them and then decide if the types were right. As syntax, I presume this would be something like: output = [] for x in data: a = delayed inc(x) b = delayed double(x) c = delayed add(a, b) output.append(c) total = sum(outputs) # concrete answer here. Obviously the simple example of adding scalars isn't worth the delay thing. But if those were expensive operations that built up a call graph, it could be useful laziness. Or for example: total = sum(outputs[:1_000_000) # larger list, don't compute everything -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On Mon, May 25, 2020 at 3:42 AM David Mertz <mertz@gnosis.cx> wrote:
And it isn't entirely correct, because now None isn't a valid parameter. It's an extremely common idiom right up until it doesn't work, and you need: _SENTINEL = object() def fun(..., option=_SENTINEL): if option is _SENTINEL: option = something_else Now, try doing that for multiple parameters at once. Or in a closure. Or anything else that would make it more complicated. ChrisA
On Sun, May 24, 2020 at 12:55 PM Chris Angelico <rosuav@gmail.com> wrote:
And it isn't entirely correct, because now None isn't a valid parameter.
Which is indeed, an extremely common use case :-)
I've thought to a while that there should be a more "standard" way to so this: A NOT_SPECIFIED singleton in builtins would be pretty clear. (though I'd like to find a shorter spelling for that) BTW, though I do find it tedious to write the: if option is SOME_SENTINEL: option = something ... It's not always the case that it's a simple setting of the value to a empty mutable -- sometimes there's some more complexity there. Which is why I kind of like that it's explicit. But if we did make it simpler, I like the idea of providing a factory function, so it would be possible to do more complex things than a simple empty container of some sort. Though that factory wouldn't have access to the full function namespace, so maybe not that flexible. -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
On Mon, May 25, 2020 at 02:19:57PM -0700, Christopher Barker wrote:
Guido's time machine strikes again! We already have that "not specified" singleton in the builtins, with a nice repr. It's spelled "None". The problem is that this is an infinite regression. No matter how many levels of "Not Specified" singletons you have, there's always going to be some context where they are all legitimate values so you need one more. Think about a function like `dir()` or `vars()`, which can operate on any object, or none at all: `dir()` is not the same as `dir(None)`, so we need a second sentinel MISSING to indicate the no argument case; but now we would like to say `dir(MISSING)`, so MISSING is likewise a legitimate value, and we need a third sentinel: since None is a legit value, we need MISSING; but MISSING is also a legit value, so we need UNDEFINED; but UNDEFINED is legit, so we need ... and so on through NOT_SPECIFIED, ABSENT, OMITTED and eventually we run out of synonyms. In the specific cases of `dir` and `vars`, it is easy enough to work around this with `*args`, but there can be functions with more complex signatures where you cannot do so conveniently. Fortunately, if you have a function that needs such a second level sentinel, you probably don't care that *other* functions like `dir` don't treat it as a special sentinel. It's only special to your library or application, not special everywhere, so the regression stops after one level. But that wouldn't be the case if it were a builtin. For the basic cases, using None is sufficient; if it's not, rolling your own is actually better than having a standard builtin, because: - it is specific to your library, you don't have to care about how other libraries might treat it (to them, it's just an arbitrary object, not a special sentinel); - you can choose whether or not to make it a public part of your library, and if so, what behaviour to give it; - and most importantly, you don't have to bike-shed the name and repr with the entire Python-Ideas mailing list *wink* -- Steven
On Mon, May 25, 2020 at 6:37 PM Steven D'Aprano <steve@pearwood.info> wrote:
A NOT_SPECIFIED singleton in builtins would be pretty clear.
Guido's time machine strikes again! We already have that "not specified" singleton in the builtins, with a nice repr. It's spelled "None".
well, yes and no. this conversation was in the context of "None" works fine most of the time.
well, those are pretty special cases -- they are about introspection -- most functions do not act on the objects themselves in such a generic ways. In the specific cases of `dir` and `vars`, it is easy enough to work
around this with `*args`, but there can be functions with more complex signatures where you cannot do so conveniently.
I've certainly had examples when I wanted to make a distinction between None and not specified, that did not have anything to do with introspecting the inputs.
It would mean "not specified" -- a nice way to combine keyword arguments with being able to be clear about it not being specified. *args can't do that. And sure, there *could* be other special cases, but it could be pretty useful anyway. The fact is that None is very heavily overloaded. I'd rather have a standard way to spell "non specified" than have every library roll their own and need to document it. Nothing would prevent folks from rolling their own if they did have a special case.
- and most importantly, you don't have to bike-shed the name and repr with the entire Python-Ideas mailing list *wink*
Now THAT is a compelling argument! -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
On Mon, May 25, 2020, 11:56 PM Christopher Barker
well, yes and no. this conversation was in the context of "None" works fine most of the time.
How many functions take None as a non-sentinel value?! How many of that tiny numbers do so only because they are poorly designed. None already is an excellent sentinel. We really don't need others. In the rare case where we really need to distinguish None from "some other sentinel" we should create our own special one. The only functions I can think of where None is appropriately non-sentinel are print(), id(), type(), and maybe a couple other oddball special ones. Seriously, can you name a function from the standard library or another popular library where None doesn't have a sentinel role as a function argument (default or not)?
Wild idea: Instead of sentinels, have a way of declaring optional arguments with no default, and a way of conditionally assigning a value to them if they are not bound. E.g. def order(eggs = 4, spam =): spam ?= Spam() Here the '?=' means "if spam is not bound, then evaluate the rhs and assign it, otherwise do nothing." -- Greg
On Tue, May 26, 2020 at 4:12 PM Greg Ewing <greg.ewing@canterbury.ac.nz> wrote:
That's interesting. I suppose the semantics would be the same as any other unbound local, then? That would actually be useful in other contexts, like where you conditionally assign in a loop, and then might not have it assigned at the end. I don't know of any current way to say "if spam is unset". It definitely needs good syntax though. The loose equals sign would be too confusing, and there's no good keyword available. It'd be kinda elegant to surround the name in square brackets: def order(eggs=4, [spam]): spam ?= Spam() but that would be confusing for other reasons. ChrisA
On 28/05/20 12:38 pm, Rob Cliffe wrote:
That clutters up the header with things that are not part of the function's signature. All the caller needs to know is that the spam argument is optional. The fact that a new Spam object is created on each call if he doesn't supply one is an implementation detail. -- Greg
On 28/05/20 7:31 pm, Chris Angelico wrote:
Is it an implementation detail that 4 will be used for eggs if it isn't passed?
That feels different to me somehow. I think it has something to do with declarative vs. procedural stuff. The default value of eggs being 4 is a static fact, but creating a new Spam object is not. To my mind, procedural code belongs in the body of the function, not in the header. -- Greg
On Thu, May 28, 2020 at 10:27:47PM +1200, Greg Ewing wrote:
Would your feeling change if we were talking about a "variables are memory locations" language, where the value 4 has to be copied into the "eggs" memory location?
To my mind, procedural code belongs in the body of the function, not in the header.
An interesting point. I would agree with it, but somehow late-bound default parameters seems to me to be an acceptable exception. But there's certainly a grey area here. Looking over some examples, I can find places where None is being used as a sentinel for what is essentially late binding defaults, but the code required to generate the default value is sufficiently complex that, even if it could be written as a single expression, I wouldn't be really happy about it being put in the function header. On the third hand, no matter how big and hairy a block of code is, if you refactor it into a function, then the late-bound default need never be more complex than a function call. -- Steven
On Thu, May 28, 2020 at 07:00:51PM +1200, Greg Ewing wrote:
I don't think you thought that through all the way. "All I need to know is that the mode argument to `open()` is optional, I don't need to know whether it defaults to read or write..." I don't think so.
Being an implementation detail implies that the functional behaviour will be identical either way, but that's incorrect under at least four circumstances: - Spam objects are mutable, e.g. lists, dicts, set; - calling Spam has side-effects; - calling Spam is particularly costly; - or if the result of calling Spam depends on the current state of the runtime environment, e.g. anything time dependent, anything to do with the state of the file system or a database, etc. The default value used by a parameter is certainly important, and one of the most common reasons I call `help(func)` is to see what the default values are. They should be in the signature, and it is an annoyance when all the signature shows is that it is None, and then I have to trawl through screenfuls of docs, or search the web, to find out what the actual default is. -- Steven
On 28/05/20 8:57 pm, Steven D'Aprano wrote:
I think we need a real example to be able to talk about this meaningfully. But I'm having trouble thinking of one. I can't remember ever writing a function with a default argument value that *has* to be mutable and *has* to have a new one created on each call *unless* the caller provided one. Anyone else have one? -- Greg
On Thu, May 28, 2020 at 12:38 PM Greg Ewing <greg.ewing@canterbury.ac.nz> wrote:
I think the most common cases are where the default is an empty list or dict. Building on my ChainMap example from before, consider this code: ``` from collections import ChainMap c1 = ChainMap().new_child() c2 = ChainMap().new_child() c1[1] = 2 print(c1[1]) c2[1] = 3 print(c1[1]) ``` Here c1 and c2 have separate new children, so modifying c2 doesn't affect c1, so '2' is printed twice. We can simulate what would happen if a new default wasn't created each time by passing the same dict to both: ``` from collections import ChainMap m = {} c1 = ChainMap().new_child(m) c2 = ChainMap().new_child(m) c1[1] = 2 print(c1[1]) c2[1] = 3 print(c1[1]) ``` Now the second print shows '3', even though we expect that value to be in c2 but not c1.
On Thursday, May 28, 2020, at 06:47 -0400, Alex Hall wrote:
That's what I thought of: an accumulator in a reduce or fold function. The default is an empty list that has to be recreated at every function call, but the caller can supply their own empty container that supports some sort of extend or add functionality.
On Thu, May 28, 2020 at 3:50 AM Alex Hall <alex.mojaki@gmail.com> wrote:
Actually, we need to one further: a default argument value that *has* to be mutable and *has* to have a new one created on each call *unless* the caller provided one ... and *has* to treat None as valid value. That I'm really having trouble with :-) -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
On 28.05.20 17:44, Christopher Barker wrote:
That's the scenario where you'd need to create a sentinel object to take the role of None. However late binding of defaults won't save you from this. The biggest advantage, as far as I understood, is that you can specify a default (expression) as part of the function header and hence provide a meaningful example value to the users rather than just None.
On Thu, May 28, 2020 at 10:37:58PM +1200, Greg Ewing wrote:
That is too strict. The "mutable default" issue is only a subset of late binding use-cases. The value doesn't even need to be mutable, it just needs to be re-evaluated each time it is needed, not just once when the function is defined. This is by no means an exhaustive list, just a small sample of examples from the stdlib. (1) The asyncore.py module has quite a few functions that take `map=None` parameters, and then replace them with a global: if map is None: map = socket_map If the global is re-bound to a new object, then the functions should pick up the new socket_map, not keep using the old one. So this would be wrong: def poll(..., map=socket_map) (2) The cgi module: def parse(fp=None, ...): if fp is None: fp = sys.stdin Again, `fp=sys.stdin` as the parameter would be wrong; the default should be the stdin at the time the function is called, not when the function was defined. (3) code.py includes an absolute classic example of the typical mutable default problem: class InteractiveInterpreter: def __init__(self, locals=None): if locals is None: locals = {"__name__": "__console__", "__doc__": None} If locals is not passed, each instance must have its own fresh mutable namespace. (4) crypt.mksalt is another example of late-binding: def mksalt(method=None, *, rounds=None): if method is None: method = methods[0] where the global `methods` isn't even defined until after the function is created. (5) The "Example" class from doctest is another case of the mutable default issue. (That's not an example class, but a class that contains examples extracted out of the docstring. Naming is hard.) class Example: def __init__(self, ..., options=None): ... if options is None: options = {} DocTestFinder contains another one: # globs defaults to None if globs is None: if module is None: globs = {} else: globs = module.__dict__.copy() DocTestRunner is another late-binding example: # checker defaults to None self._checker = checker or OutputChecker() (6) The getpass module has: def unix_getpass(prompt='Password: ', stream=None): ... If stream is None, it tries the tty, and if that fails, stdin. The code handling the None stream is large and complex, and so might not be suitable for a late-binding default since it would be difficult to cram it all into a single expression. Other parts of the module include `stream=None` defaults as a sentinel to switch to sys.stderr. In my own code, I have examples of late-binding defaults: if vowels is None: vowels = VOWELS.get(lang, '') if rand is None: rand = random.Random() among others. -- Steven
On Thu, May 28, 2020 at 9:01 AM Greg Ewing <greg.ewing@canterbury.ac.nz> wrote:
I'm very surprised by this sentiment. The signature says that the default value for spam is an instance of Spam, namely one constructed with no arguments. That's useful information! I wrote a long post about this here: https://mail.python.org/archives/list/python-ideas@python.org/message/6TGESU... - do you have any thoughts on that? (side note - I'm just seeing now how mailman handles inline images, which is very disappointing) The fact that a new Spam object
is created on each call if he doesn't supply one is an implementation detail.
I don't think it is - knowing that the default isn't shared across calls could be quite important. But aside from that, there's only one character (`?`) which represents that detail, and that's an acceptable amount of 'clutter'. The rest (`=Spam()`) is just saying what the default value is, and we don't usually consider that clutter.
On 5/28/20 3:00 AM, Greg Ewing wrote:
But default values for arguments are really part of the responsibility for the caller, not the called function. The classic implementation would be that the caller passes all of the explicitly, and implicitly defined parameters (those with default arguments). If the language allows, you could have unpassed arguments that are passed as 'not provided' and that the called function detects and fills in with a value that isn't part of the API (which is sort of what the = None default does). This can also be done in Python with the *args and **kwargs parameters where the function can detect if something was passed there. -- Richard Damon
On 29/05/20 12:17 am, Richard Damon wrote:
I would say that's really a less-than-ideal implementation, that has the consequence of requiring information to be put in the header that doesn't strictly belong there. To my mind, the signature consists of information that a static type checker would need to verify that a call is valid. That does not include default values of arguments. The fact that a particular value is substituted if an argument is omitted is part of the behaviour of the function, not part of its signature. By putting default values in the header, we're including a tiny bit of behavioural information. By distinguishing between one-time and per-call evaluation of defaults, we're adding a bit more behavioural information. Where do we draw the line? How much of the behaviour of the function do we want to move into the header? -- Greg
Greg Ewing writes:
That's a parsimonious and reasonable definition, and the one historically used by Emacs Lisp. But the definition that says that, *in addition*, it includes the default values is also reasonable. Note that in your definition, the signature *does*, however, include the fact that defaulting (omitting) those arguments is allowed, otherwise abbreviated calls would be flagged by the static type checker. Once you've allowed defaults, I think the obvious syntactic place to put them is in the def statement, because they are useful as documentation.
Where do we draw the line? How much of the behaviour of the function do we want to move into the header?
To my mind that's a programming style question. Python has made the decision that anything that evokes a specific object (including a function or a code object) can go there.[1] For me in practice that's a good dividing line. Except that I would never put a function or code object there only to immediately evaluate it: # Just too ugly for me! def foo(x=lambda: random.randint(0,9)): x = x() # ... Footnotes: [1] I don't think this was the main intended effect of early binding of defaults, but it is an effect.
On Fri, May 29, 2020 at 3:19 AM Stephen J. Turnbull < turnbull.stephen.fw@u.tsukuba.ac.jp> wrote:
I think this is a perfect example of where my desired "delayed" (or "deferred") construct would be great. There are lots of behaviors that I have not thought through, and do not specify here. But for example: def foo(a=17, b=42,, x=delayed randint(0,9), y=delayed randrange(1,100)): if something: # The simple case is realizing a direct delayed val = concretize x elif something_else: # This line creates a call graph, not a computation z = ((y + 3) * x)**10 # Still call graph land w = a / z # Only now do computation (and decide randoms) val = concretize w - b I do not find this particularly ugly, and I think the intent is pretty clear. I chose two relatively long words, but some sort of shorter punctuation would be possible, but less intuitive to my mind. -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On Fri, May 29, 2020 at 7:05 PM David Mertz <mertz@gnosis.cx> wrote:
But if I understand correctly, a delayed value is concretized once, then the value is cached and remains concrete. So if we still have early binding, then x will only have one random value, unlike Stephen's lambda which generates a new value each time it's called.
On Fri, May 29, 2020 at 1:12 PM Alex Hall <alex.mojaki@gmail.com> wrote:
I don't think that's required by the example code I wrote. The two things that are concretized, 'x' and 'w-b', are assigned to a different name. I'm taking that as meaning "walk the call graph to produce a value" rather than "transform the underlying object". So in the code, x and y would stay permanently as a special delayed object. This is a lot like a lambda, I recognize. The difference is that the intermediate computations would look through the right-hand side and see if anything was of DeferredType. If so, the computation would become "generate the derived call graph" rather than "do numeric operations." So, for example, 'w' also is DeferredType (and always will be, although it will fall out of scope when the function ends). In some cases, generating a call graph can be arbitrarily cheaper than the actual computation; passing around the call graph rather than the result can hence be worthwhile. -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
David Mertz writes:
I think this is the correct approach, since TOOWTDI for collapsing the waveform early is "x = concretize x". TOOWDTI for preserving the call graph for a caching DeferredType doesn't exist yet. Also, Alex's interpretation makes "concretize" a name-binding operation, but I see no need for that. In another post you mention Vaex. I wonder if it's really that hard to design a language that's lazy until you need a concrete object, and it automatically gives you one. That's the way Haskell works, for example. (Making that work with existing Python semantics without explicit syntax is probably another story, but I wonder if it might be possible to do it with a minimum of explicit concretizing.)
This is a lot like a lambda, I recognize.
Except that lambda works "top-down", and it's not immediately obvious to that intermediate computations need do any looking because they could work "bottom-up". That is, DeferredType could define a full complement of dunders, all of which construct call graphs and return a corresponding DeferredType instance. This would give you full control over which subexpressions were evaluated eagerly, and which deferred. I don't think you need explicit syntax for this. The question would be do you want that level of control, or do you more often just want to defer whole expressions? (That latter would be the case if you had a expression that contained several expensive subexpressions, none of which would benefit from being cached while others are recomputed more frequently.) If the latter, I think you need syntax BTW, going back to the question of mutable defaults, it occurs to me that there is an "obvious" idiom for self-documenting sentinels for defaults that are deferred because you want a new instance each time the function is called: use the constructors! Here are some empty mutables: def foo(x=list): if x == list: x = x() def bar(x=dict): if x == dict: x = x() And here's a time-varying immutable: import datetime def baz(x=datetime.datetime.now): if x == datetime.datetime.now: x = x() I guess this fails more or less amusingly if the constructor is redefined. Of course any callable object could be the sentinel. It doesn't need to be a type or a factory function for this device to work. However, I don't see a use case for that generality. Steve
BTW, going back to the question of mutable defaults, it occurs to me
I like this a lot. And for those who are on board iwth type hinting, seems like you could indicate your intentions pretty clearly by saying something like: def foo(x: Constructing[List] = list): if x == list: x = x() A Constructing[List} being a thing whose type is supposed to be a list if provided by the user, and the final type is also list if not provided by the user.
On 29/05/2020 18:02, David Mertz wrote:
Presumably "delayed" is something that would be automatically applied to the actual parameter given, otherwise your call graphs might or might not actually be call graphs depending on how the function was called. What happens if I call "foo(y=0)" for instance? There's some risk that this will introduce a brand new gotcha, "You forgot to concretize your delayed parameter". I'm not agin it per se, but I'd need to understand the value of it better I think. Also, I'm pretty sure the average programmer will find the current if x is None: x = randint(0,9) a lot easier to understand. -- Rhodri James *-* Kynesim Ltd
On Fri, May 29, 2020 at 1:56 PM Rhodri James <rhodri@kynesim.co.uk> wrote:
I am slightly hijacking the thread. I think the "solution" to the narrow "problem" of mutable default arguments is not at all worth having. So yes, if that was the only, or even main, purpose of a hypothetical 'delayed' keyword and 'DelayedType', it would absolutely not be worthwhile. It would just happen to solve that problem as a side effect. Where I think it is valuable is the idea of letting all the normal operations work on EITHER a DelayedType or whatever type the operation would otherwise operate on. So no, `foo(y=0)` would pass in a concrete type and do greedy calculations, nothing delayed, no in-memory call graph (other than whatever is implicit in the bytecode). However, I don't really love the 'concretize' operation, which you correctly identify as a source of new bugs. I think it is necessary occasionally, and actually there is no reason it cannot be a plain old function rather than a keyword. The DelayedType object is simply some way of storing a call graph, which is has some kind of underlying representation. So the only slightly special function concretize() could just walk the graph. I think it would be better if MANY operations simply *implied* the need to concretize the call tree into a result value. The problem is, I'm really not sure exactly which operations, and probably a lot of them could have arguments in either direction. My thinking here is inspired by several data frame libraries that address this issue. * Pandas is always eager. Call a method, it does the computation right away, and usually returns the mutated data frame object (or some new similar object) to chain methods in a "fluent style." * Dask.dataframe is always lazy. It implements 95% of the Pandas API (by putting Pandas "under the hood"). You can still chain methods, but everything returns a call graph that the next method uses to build a larger call graph. The ONLY time any computation is done when you explicitly call `df.compute()` * Vaex is another data frame library that is very interesting. It is *almost always* lazy, and likewise allows chaining methods. You can easily build up call graphs behind the scenes (either by chaining or with intermediate names for "computations"). However, the RIGHT collection of methods know they need to concretize... and they just do the right thing. Of these, I've used Vaex the least by far. However, my impression is that it makes the right decisions, and users rarely need to think about what is going on behind the scenes (other than that operations on big data is darn fast). Still, "things with data frames" is more specialized than "everything one can do in Python." I'm not sure what the right answers are. For example, my first intuition is that `print(x)` is a good occasion to implicitly concretize. If you really want the underlying delayed, maybe you'd write `print(x.callgraph)` or something similar. But then, sticking in a debugging print might wind up being an expensive thing to do in that case, so... -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On 29.05.20 20:38, David Mertz wrote:
I'm still struggling to imagine a real use case which can't already be solved by generators. Usually the purpose of such computation graphs is to execute on some specialized hardware or because you want to backtrack through the graph (e.g. Tensorflow, PyTorch, etc). Dask seems to be similar in a sense that the user can choose different execution models for the graph. With generators you also don't have the problem of "concretizing" the result since any function that consumes an iterable naturally does this. If you really want to delay such a computation it's easy to write a custom type or generator function to do so and then use `next` (or even `concretize = next` beforehand).
On Fri, May 29, 2020 at 5:06 PM Dominik Vilsmeier <dominik.vilsmeier@gmx.de> wrote:
If you look for Dask presentations, you can find lots of examples, many of real world use. You want those that use dask.delayed specifically, since a lot of Dask users just use the higher-levels like dask.dataframe. But off the cuff, here's one that I don't think you can formulate as generators alone: def lazy_tree(stream, btree=BTree(), new_data=None): """Store a b-tree of results from computation and the inputs For example, a modular form of large integers, or a PRG """ for num in stream: # We expect a few million numbers to arrive result = delayed expensive_calculation(num) if result == btree.result: if new_data is None: btree.result = new_data.result btree.inits = [new_data.init] else: # Add to the inits that might produce result btree.inits.append(num) elif result < btree.value.result: btree.left = delayed lazy_tree(stream, btree.left, InitResultPair(num, result)) elif result > btree.value.result: btree.right = delayed lazy_tree(stream, btree.right, InitResultPair(num, result)) return btree I probably have some logic wrong in there since I'm doing it off the cuff without testing. And the classes BTree and InitResultPair are hypothetical. But the idea is we are partitioning on the difficult to calculate result. Multiple inits might produce that same result, but you don't know without the computation. So yes, parallelism is potentially beneficial. But also partial computation without expanding the entire tree. That could let us run a line like this to only realize a small part of the tree: btree = lazy_tree(mystream) my_node = btree.path("left/left/left/right/left/right/right/right") Obviously it is not impossible to write this without new Python semantics around delayed computation. But the scaffolding would be much more extensive. And it certainly couldn't be expressed just as a sequence of generator comprehensions. -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On Fri, May 29, 2020 at 12:36:20PM +1200, Greg Ewing wrote:
"Strictly" according to whom? Well, you obviously :-) For 30 years, Python's early bound default arguments have been part of the function signature. It's only late bound default arguments which are hidden inside the body. So you are arguing that for 30 years Python has put information into the function header that doesn't belong there. Where else would you put the parameter defaults, if not in the parameter list?
To my mind, the signature consists of information that a static type checker would need to verify that a call is valid.
A static type checker would have to know whether a parameter has a default value, even if it doesn't know what that default value is. So you are arguing that the ideal (using your word from above) function signature for, let's say, the `open` builtin should look something like this: open(file, mode= <REDACTED>, buffering= <REDACTED>, encoding= <REDACTED>, errors= <REDACTED>, newline= <REDACTED>, closefd= <REDACTED>, opener= <REDACTED>) plus type information, which I cannot be bothered showing. This ideal arrangement tells the static type checker everything it needs to know to determine whether a call is valid or not: - the name and order of the parameters; - their types (pretend I showed them); - whether they can be omitted or not; - whether or not the function takes positional only parameters (in this case, it doesn't); - whether or not the function takes vararg and keyword varargs as well (in this case, it doesn't); but none of the things that it doesn't need to know, such as the actual default value. [Aside: well, *almost* everything: it doesn't tell the static checker whether the function is in scope or not.] As a user of that function, I need to know the same things the static checker needs to know, *plus* the actual default values. I'm not sure why you care more about the type checker than the users of the function. Even if you couldn't care less about my needs, presumably you are a user of the function too.
That depends on what you define as the *function* signature and whether you equate it with the function's *type* signature. (Or dare I say it, whether you conflate it with the type signature.) Consider two almost identical functions: def add(a:int, b:int=0)->str: return a+b def add(a:int, b:int=1)->str: return a+b These two functions have: - identical names; - identical parameter lists; - identical type signatures (int, int -> int); - identical function bodies; but they are different functions, with similar but different semantics (the first defaults to a no-op, the second doesn't). Where does the difference lie? It's not specifically in the implementation (the body), that's identical. It's not in the *type* signature, we agree on that. I want to say that it is a difference in the *function* signature, which consists of not just the types, but also the function name and parameters including defaults. Not only is this a useful, practical way of discussing the difference, it matches 30 years of habit in the Python community. Reading your post is literally the first time it has dawned on me that anyone would want to exclude default values from the notion of function signature. (By the way, in Forth, function signatures are comments showing stack effects, and they're only for the human reader.)
By putting default values in the header, we're including a tiny bit of behavioural information.
Behavioural information is already present as soon as the header includes whether or not parameters can be, or must be, given by name or position, and whether or not it accepts varargs. In languages with procedures (or void functions) as well as functions, that behavioural information is also present in the signature. In languages with checked exceptions, that behavioural information is likewise present in the signature. What's your problem with these?
Yes.
Where do we draw the line? How much of the behaviour of the function do we want to move into the header?
Well obviously we don't draw the line until we've fallen down the slippery slope and the entire body of the function is part of the header! *wink* I think there are serious practical difficulties in moving much more behavioural information into the header. Not that there's much more we might want in the function header. Checked exceptions perhaps? Not me personally. What else *could* we move into the header? -- Steven
Sure, what's the problem? :-) def hof(*, op=lambda F: lambda x: F(x), fn=lambda x: x**2, val=None): # Default is squaring, do what you want. return op(fn)(val) -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On 29/05/20 11:49 pm, Steven D'Aprano wrote:
Where else would you put the parameter defaults, if not in the parameter list?
In some part of the function that's not the parameter list. :-) There are many ways it could be done. I've suggested one already (a special assignment statement). Another would be to have a special "defaults" section in the body.
A static type checker would have to know whether a parameter has a default value, even if it doesn't know what that default value is.
It has to know that the parameter is *optional*, yes. It doesn't need to know what the default value is, or even whether it has a default value at all. Even if the default value is available to the type checker, it's just going to ignore it. The only thing that *might* make use of it is the code generator.
As a user of that function, I need to know the same things the static checker needs to know, *plus* the actual default values. I'm not sure > why you care more about the type checker than the users of the function.
I need to know a whole lot of *other* things about the function too, but we don't expect to find them all in the header. We have docstrings for that. I'm not saying that default values shouldn't be in the header. I'm saying you can't argue that because *some* information about default values currently happens to be in the header, then *all* of it should be. That just doesn't follow.
That depends on what you define as the *function* signature and whether you equate it with the function's *type* signature.
It seems to me that the whole concept of a signature only makes sense in relation to static analysis. If you're not doing static analysis of some kind, then *everything* about a function is behaviour. In Python, you can attempt to call any function with any parameters, and something will happen, even if it's just raising an exception. The only reason for singling out certain characteristics of a function and calling them its "signature" is if you want to do some sort of static analysis about whether a call is valid. So, I think that "signature" always implies "type signature", for some notion of "type".
Certainly. But that doesn't prove that the default values have to be in the header! In an alternative universe, they could be written def add(a:int, [b:int])->str: b ?= 0 return a+b def add(a:int, [b:int])->str: b ?= 1 return a+b The default value of b would then have to be conveyed by the documentation -- just like everything else about what the function does.
I want to say that it is a difference in the *function* signature,
Then you would have to come up with some principle for deciding what is part of this "function signature", other than "whatever happens to be in the header".
Not only is this a useful, practical way of discussing the difference, it matches 30 years of habit in the Python community.
It's certainly a habit, and one which spans more than one language. But I think we need to recognise it as just that -- a habit, not a law.
I can understand that. I even surprised myself when I came to that conclusion, because I hadn't really thought about it before. I think we're so used to seeing default values in the header in other languages, such as C++, that we've come to regard it as part of the natural order. But I think C++ is a bad example to follow, because there the default values are in the header for *implementation* reasons. There are lots of other places in C++ as well where implementation issues leak into the language design (e.g. the fact that all member functions of a class need to be declared in its header file, including private ones -- I don't think anyone regards *that* as a desirable feature!) It's also worth remembering that in early versions of C, not even the *types* of the parameters were written in the header -- e.g. you wrote functions like int foo(a, b) float a; char *b; { .... } So none of this stuff is universal across languages.
What's your problem with [including behavioural information in the header]?
Only that the more stuff you put in the header, the more cluttered it becomes, so we need a good reason for every item we include. The only objective rule I can think of for deciding whether to put something in the header is whether it's needed for static analysis. (And even that depends on exactly what static analysis you want to perform.) If you have a better one, I'd be interested to hear it.
Not that there's much more we might want in the function header. Checked exceptions perhaps?
No! Not checked exceptions! Stay away! [Holds up crucifix, garlic and holy water.] -- Greg
On 26.05.20 06:03, David Mertz wrote:
* From the builtins there is `iter` which accepts a sentinel as second argument (including None). * `dataclasses.field` can receive `default=None` so it needs a sentinel. * `functools.reduce` accepts None for its `initial` parameter (https://github.com/python/cpython/blob/3.8/Lib/functools.py#L232). * There is also [`sched.scheduler.enterabs`](https://github.com/python/cpython/blob/v3.8.3/Lib/sched.py#L65) where `kwargs=None` will be passed on to the underlying `Event`. For the following ones None could be a sentinel but it's still a valid (meaningful) argument (different from the default): * `functools.lru_cache` -- `maxsize=None` means no bounds for the cache (default is 128). * `collections.deque` -- `maxlen=None` means no bounds for the deque (though this is the default). Other example functions from Numpy: * [`numpy.concatenate`](https://numpy.org/doc/1.18/reference/generated/numpy.concatenate.html) -- here `axis=None` means to flatten the arrays before concatenation (the default is `axis=0`). * Any function performing a reduction, e.g. [`np.sum`](https://numpy.org/doc/1.18/reference/generated/numpy.sum.html) -- here if `keepdims=` is provided (including None) then it will passed to the `sum` method of ndarray-sub-classes, otherwise not. * [`np.diff`](https://numpy.org/doc/1.18/reference/generated/numpy.diff.html) supports prepending / appending values prior to the computation, including None (though that application is probably rare).
All of those uses, including those where you say otherwise, treat None as a sentinel. In the iter() case, the optional seconds argument is *called* 'sentinel'. Guido recently mentioned that he had forgotten the two argument form of iter(), which is indeed funny... But useful. Well, ok functions.reduce() really does make it's own sentinel in order to show NONE as a "plain value". So I'll grant that one case is slightly helped by a hypothetical 'undef'. The NumPy, deque, and lru_cache cases are all ones where None is a perfect sentinel and the hypothetical 'undef' syntax would have zero value. I was wondering if anyone would mention Pandas, which is great, but in many ways and abuse of Pythonic programming. There None in an initializing collection (often) gets converted to NaN, both of which mean "missing", which is something different. This is kind of an abuse of both None and NaN... which they know, and introduced an experimental pd.NA for exactly that reason... Unfortunately, so far, actually using of.NA is cumbersome, but hopefully that gets better next version. Within actual Pandas and function parameters, None is always a sentinel. On Tue, May 26, 2020, 4:48 AM Dominik Vilsmeier <dominik.vilsmeier@gmx.de> wrote:
On Tue, May 26, 2020 at 10:14 PM David Mertz <mertz@gnosis.cx> wrote:
All of those uses, including those where you say otherwise, treat None as a sentinel. In the iter() case, the optional seconds argument is *called* 'sentinel'. Guido recently mentioned that he had forgotten the two argument form of iter(), which is indeed funny... But useful.
The second argument uses *any arbitrary value* as a sentinel. For instance: print("Type commands, or quit to end:") for cmd in iter(input, "quit"): do_stuff(cmd) There is nothing whatsoever about None here. It will call the function until it returns the sentinel. And this is completely different from the one-arg form of iter, so you can't use None as a default.
Well, ok functions.reduce() really does make it's own sentinel in order to show NONE as a "plain value". So I'll grant that one case is slightly helped by a hypothetical 'undef'.
Same again: reduce behaves as if the initial is prepended onto the sequence, and it has to treat None the same as any other value. But it would have to treat 'undef' as a value too, if it is indeed a value.
The NumPy, deque, and lru_cache cases are all ones where None is a perfect sentinel and the hypothetical 'undef' syntax would have zero value.
Yes, and I know a lot of languages in which lru_cache would use -1 as its sentinel. Granted.
I was wondering if anyone would mention Pandas, which is great, but in many ways and abuse of Pythonic programming. There None in an initializing collection (often) gets converted to NaN, both of which mean "missing", which is something different. This is kind of an abuse of both None and NaN... which they know, and introduced an experimental pd.NA for exactly that reason... Unfortunately, so far, actually using of.NA is cumbersome, but hopefully that gets better next version.
Within actual Pandas and function parameters, None is always a sentinel.
Definitely not always. Often, yes, but most definitely not always. ChrisA
On 26.05.20 14:10, David Mertz wrote:
Maybe we have a different understanding of "sentinel" in this context. I understand it as an auxiliary object that is used to detect whether the user has supplied an argument for a parameter or not. So if the set of possible (meaningful) arguments is "A" then the sentinel must not be an element of A. So in cases where None has meaning as an argument it can't act as a sentinel. `iter` is probably implemented via varargs but if it was designed to take a `sentinel=` keyword parameter then you'd need a dedicated sentinel object since the user can supply *any* object as the (user-defined) sentinel, including None: >>> list(iter([1, 2, None, 4, 5].pop, None)) [5, 4]
For both `deque` and `lru_cache` None is a sensible argument so it can't act as a sentinel. It just happens that these two cases don't need to check if an argument was supplied or not, so they don't need a sentinel. For the Numpy cases, `np.sum` and `np.diff`, None does have a meaning from user perspective, so they need a dedicated sentinel (which is `np._NoValue`). If `keepdims` is not supplied, it won't be passed on to sub-classes; if it is set to None then the sub-class receives `keepdims=None` as well: >>> class Test(np.ndarray): ... def sum(self, **kwargs): ... return kwargs ... >>> a = Test(0) >>> np.sum(a) {'axis': None, 'out': None} >>> np.sum(a, keepdims=None) {'axis': None, 'out': None, 'keepdims': None} For `np.diff`, if no argument is provided for `append` (or `prepend`) then nothing is appended (prepended), otherwise the supplied value is used (including None): >>> np.diff([1, 2]) array([1]) >>> np.diff([1, 2], append=None) TypeError: unsupported operand type(s) for -: 'NoneType' and 'int' For `np.concatenate` None is a meaningful argument to `axis` since it will flatten the arrays before concatenation.
I wouldn't say it's an abuse, it's an interpretation of these values. Using NaN has the clear advantage that it fits into a float array so it's memory efficient.
On Tue, May 26, 2020 at 12:02 PM Dominik Vilsmeier <dominik.vilsmeier@gmx.de> wrote:
I think getting caught up in the specific functions is a bit of a rabbit hole. I think the general point stands that None is usually fine as sentinel, and in the rare cases it's not, it's easy to define your own. But lru_cache() and deque() seem kinda obvious here. The default cache size is a finite number, but we can pass in any other positive integer for maxsize. Therefore, nothing in the domain of positive integers can carry the sentinel meaning "unbounded" or "infinite." We need a special value to signal different behavior (in other words, a sentinel). In C/C++, we'd probably use -1. It's an integer, but not one that makes sense as a size. I suppose we might use float('inf') as a name for unbounded, but then there are issues of converting that float to an int... or really just doing what currently happens of taking a different code path. For every practical purpose, sys.maxsize would be fine. It is not technically infinite, but it's far larger than the amount of memory you can possibly cache. I do that relative often myself... "really big" is enough like "infinite" for most practical purposes (I could make an even bigger integer in Python, of course, but that it mnemonic and plenty big). Or we could use a string like '"UNBOUNDED"'. Or an enumeration. Or a module constant. But since there is just one special state/code path to signal, None is a perfect sentinel. If `keepdims` is not supplied, it won't be passed on to sub-classes; if it
is set to None then the sub-class receives `keepdims=None` as well:
Yeah, OK, there's a slight different if you subclass ndarray. I've never felt an urge to do that, and never seen code that did... but it's possible.
For `np.concatenate` None is a meaningful argument to `axis` since it will flatten the arrays before concatenation.
This is again very similar to the sentinel in lru_cache(). It means "use a different approach" to the algorithm. I'm not sure what the C code does, but in concept it's basically: sentinel = None if axis is sentinel: a = a.flatten() b = b.flatten() axis = 0 ... rest of logic ...
I know why they did it. But as a data scientist, I sometimes (even often) care about the difference between "this computation went wonky" and "this data was never collected." NaN is being used for both meanings, but they are actually importantly different cases. -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On Mon, May 25, 2020 at 08:54:52PM -0700, Christopher Barker wrote:
Um, yes? I know what the context is, I'm pretty sure I already pointed out that None works fine most of the time. So we already have the feature you wanted: a sentinel value that implies "no value was passed". That's one of the purposes of None. If you want a *second* such sentinel value, we run into the problem I go on to describe.
It's not just introspection. What should `len(Undef)` do? If Undef or Missing or whatever you call it is supposed to represent a missing argument, one not given at all, then we ought to get: >>> len(Undef) TypeError: len() takes exactly one argument (0 given) since len takes no default values. But if Undef is considered to be an actual object, like any other object, we ought to get this: TypeError: object of type 'UndefType' has no len() So take your choice: either - we give fake error messages with misleading descriptions; - or we sometimes have to treat this "missing" sentinel as not missing at all, but just a plain old value like every other value. But that's what happens with None, so the same thing will happen with Undef, so we can add a third level of "the sentinel you use to represent a missing value when both None and Undef are regular values" except the exact same thing will happen to this third-level sentinel. And so on and so on. We cannot escape this so long as None/Undef/Missing etc are actual first class objects, like None and other builtins. But doing otherwise, having Undef be *not an object* but a kinda ghost in the interpreter, is a huge language change and I doubt it would be worth it. -- Steven
On Tue, May 26, 2020 at 12:53 PM Steven D'Aprano <steve@pearwood.info> wrote:
JavaScript and R, for example, do have a special pseudo-values for "even more missing". In JS, it is null vs undefined. In R, it is... well, actually NULL vs. NA vs. NaN. E.g.:
c(NULL, NA, NaN, 0, "") [1] NA "NaN" "0" ""
The NULL is a syntactic placeholder, but it's not a value, even a sentinel (i.e. it doesn't get in the array). Python *could* do that. But it would require very big changes in many corners of the language, for no significant benefit I can see. In other words, I agree with Steven. -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On Wed, May 27, 2020 at 2:51 AM Steven D'Aprano <steve@pearwood.info> wrote:
But is it a huge change? I thought so too, until Greg suggested a quite plausible option: leave the local unbound. There'd be two changes needed, and one of them could have other value. The semantics would be exactly the same as any other unbound local. def foo(): if False: x = 0 # what is x now? There is no *value* in x, yet x has a state. So we could have some kind of definition of optional parameters where, rather than receiving a default, they would simply not be bound. def foo(?x): # what is x? There would want to be a new way to query this state, though, because I think this code is ugly enough to die: def foo(?x): try: x except UnboundLocalError: ... # do this if x wasn't passed in else: ... # do this if we have a value for x But if we could do something a bit more elegant, this would become quite plausible. And the "is this name bound" check would potentially have other value, too. "Undef" wouldn't be a thing. It wouldn't be a global name, it wouldn't be a keyword, it certainly wouldn't be an object. But "unbound" would become a perfectly viable state for a local variable. (It's probably best to define this ONLY for local variables. Module or class name bindings behave differently, so they would simply never be in this unbound state. For the intended purpose - parameter nondefaults - that won't be a problem.) ChrisA
On Wed, May 27, 2020 at 5:19 AM Alex Hall <alex.mojaki@gmail.com> wrote:
When you're looping, searching for something, and then seeing if you found any. If you want to stop at the first, you can use 'break' and 'else' (although a lot of people don't know about that), but what if you're locating the last match, and can't search in reverse? Or some sort of best match or all match? How do you then say "none found"? Usually you end up needing a sentinel, but if you could simply leave the variable unbound, you could then check for that at the end. ChrisA
On Tue, May 26, 2020 at 9:24 PM Chris Angelico <rosuav@gmail.com> wrote:
This proposal would still leave defaults out of the signature, and thus the only benefit I'm seeing is being able to avoid typing `if obj is sentinel`. In fact it saves even less typing than other proposals since you still have to write `obj ?= value`. I don't think that's a significant benefit, and others have expressed similar. So is there any use for it which can't be satisfied by a sentinel? Otherwise I would definitely prefer None-aware operators from PEP 505.
On Tue, May 26, 2020 at 8:30 PM Greg Ewing <greg.ewing@canterbury.ac.nz> wrote:
It does so very little that I would definitely not want syntax ONLY for that. The example of lru_cache() is god here... None is a sentinel, but it is NOT the default value. So there is a value of 128 supplied, even if the user doesn't supply one. Changing syntax for something that doesn't even actually save a line, isn't worth it. I'm assuming you mean something along the lines of: def foo(a, b, mode=): if undef mode: mode = whatever It's really just a sentinel, no better than None. If we want to save more, we're back to PEP 505 and None-coalescing. I'm feeling more sympathetic to that than I did in earlier discussion. But I'm still a bit horrified by some of the use cases that were presented at that time (not directly in the PEP). E.g.: data = json.load(fh) needle ?= data?.child?.grandchild?[key]?[index]?.attr When it looks like that, I get visions of APL or Perl unreadability. So I guess what I'm sympathetic with is about 1/3 of PEP 505. Like only: stuff = this ?? that Yes, there are still rare non-None sentinels to deal with differently, but that is 90% of the issue being discussed. -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
Greg Ewing writes:
"Did the user supply a value for this optional argument?" is a simple and reasonable question to ask.
True.
It deserves to have a simple and direct way of answering it that always works.
"Deserves"? I wouldn't go farther than "it might be fun to have" that. In Emacs Lisp, it's useful to defend against users who don't update their package libraries with #'boundp and #'fboundp checks. These invariably occur in top-level forms, though, not on function arguments. But what's the use case for this magical predicate? Writing a nastygram to the user's boss if they dare to use gregs-package._sentinels._af5d8a21858f42808c9bcc17012b77bcc2fd6ab3b071dbd4a05f13f410470541 as an actual argument?
On Wed, May 27, 2020 at 05:03:09AM +1000, Chris Angelico wrote:
In Python code, no, it has no state, it's just an unbound name. That's literally a name that has nothing bound to it, hence no state. In the CPython 3 implementation, it has a hidden state: there's a fixed array representing the locals, one of those array slots represents x, and there is some kind of C-level special state to distinguish between "this slot is filled" and "this slot is not filled". But that's purely an optimization. Locals can also be backed by a dict, like globals. That is what happens in Jython, so when you call locals() you get back the actual local namespace dict and modifications to the variables works. (Unlike in CPython.) # Jython 2.7 >>> def test(): ... locals()['x'] = 999 ... if False: ... # Fool the compiler into treating x as a local. ... x = None ... print(x) ... >>> test() 999 IronPython appears to be different yet again, but I don't understand what it is doing so I can't explain it. In CPython 2, some locals were backed by the fast array slots, some were not. I think (but I'm not sure!) that if the compiler saw an exec or a star import inside a function, it switched off the fast array optimization. Or something like that. The bottom line here is that the Python execution model has names. Names can be bound to a value (an object), or they can be unbound in which case they have no state *in Python*. Whether that unboundness is represented by a nil pointer or a special magic value or is a consequence of a key being missing from a namespace dict is part of the implementation, not part of the Python semantics.
We could have an `if undef` keyword :-) if undef x: x = something (Not entirely serious about this proposal.)
There's always: if 'x' in locals()
Of course they are! # Module level state. x = None; del x # Ensure x is unbound. print(x) I frequently write top-level module code that tests for the existence of a global or builtin: try: spam except NameError: def spam(): ... That could become: if undef spam: def spam(): ... I would be cross if `if undef` worked inside functions but not globally. -- Steven
On Thu, May 28, 2020 at 8:01 PM Steven D'Aprano <steve@pearwood.info> wrote:
Is the UnboundLocalError that you'd get on trying to access 'x' a CPython implementation detail or a language feature? If it's a language feature, then the name 'x' must be in the state of "local variable without a value". This is a valid situation. There is no value, but this is the state of the variable. It's not "no state" any more than zero is a non-number or NULL is a non-pointer. ChrisA
On Thu, May 28, 2020 at 08:04:07PM +1000, Chris Angelico wrote:
I think the existence of UnboundLocalError is a red herring. See my recent post in this thread discussing Micropython. What *isn't* a red herring is whether or not x is treated as a local variable. That is a language feature. But whether it raises NameError or UnboundLocalError is, I think, up to the implementation.
Oh ho, I see what you are doing now :-) I'm going to stick with my argument that Python variables have two states: bound or unbound. But you want to talk about the *meta-state* of what scope they are in: LEGB = Local, Enclosing (nonlocal), Global, Builtin There's at least one other case not captured in that acronym, Class scope. There may be other odd corner cases. In any case, if you want to distinguish between "unbound locals" and "unbound globals" and even "unbound builtins", then I acknowledge that these are genuine, and important, distinctions to make, with real semantic differences in Python. But I think that the scope of a variable is metadata (metastate), when it comes to the state of any variable (whether LEGB or C) it can be bound to a value or unbound and that's all. At this point I'm not sure what, if any, difference to the current discusion it will make whether we label a variable's scope metastate or state.
Zero is definitely a number with a value. It's the additive identity. NULL being a pointer is, I think, a mere consequence of the impoverished type systems of languages like C :-) The idea of NULL is that it should be just pointer-ish enough to satisfy the compiler and allow you to assign it to pointer variables, but not pointer-ish enough to fool the compiler into allowing you to dereference it and crash the machine. -- Steven
On Fri, May 29, 2020 at 10:51 PM Steven D'Aprano <steve@pearwood.info> wrote:
The reason locals are special is that you can't have a module-level name without a value, because it's exactly the same as simply not having one; but you CAN have a local name that must be exactly that local, and you can't look up a module or builtin name, but it still doesn't have a value. I believe local scope is the only one that behaves this way.
Sure. But "unbound" is a state. In theory, you could have an optional parameter which, if no value is given, has no value stored in it.
Agreed, I don't care whether it's "state" or "metastate". I would just call it "state" - the name has no value associated with it, yet it is local - but if you want to consider it a metastate of "unbound" as distinct from its main state (which would be the value), then sure.
Exactly. All of them ARE states. A box containing nothing is validly containing zero things. A NULL pointer is an actual thing. And an unbound local name is a real situation that can be seen. ChrisA
On 29.05.20 15:09, Chris Angelico wrote:
Indeed locals are special, but why was it designed this way? Why not resolve such an unbound local name in the enclosing scopes? It seems that there is no way to modify locals once the function is compiled (this is probably due to the fact that locals are optimized as a static array?). For example: >>> x = 1 >>> def foo(): ... exec('x = 2') ... print(x) ... >>> foo() 1 However in Python 2.7 this is possible: >>> x = 1 >>> def foo(): ... exec('x = 2') ... print(x) ... >>> foo() 2 >>> x 1
On Fri, May 29, 2020 at 04:52:38PM +0200, Dominik Vilsmeier wrote:
Indeed locals are special, but why was it designed this way? Why not resolve such an unbound local name in the enclosing scopes?
Probably for speed. When I first learned about the LGB rule (so long ago there wasn't even an E for Enclosing!) I thought that Python *literally* did this: - look for a local name 'x' - if not found, look for a global name 'x' - if not found, look for a builtin name 'x' on every name lookup. But that's not what the interpreter actually does. It has separate byte code instructions for fast local lookup, nonlocal lookup, and global/builtin lookup. So the compiler needs to know at compile-time which instruction to use. Python might have used a single lookup which searched each scope in turn, I believe that is (roughly) how Lua works. But that would mean that within the same lexical block, a variable is sometimes global and sometimes local: def func(): # Inside this block we have: print(x) # x is global x = 1 print(x) # And now it's local. and you can get that effect in Lua. That's a perfectly logical and unambiguous rule, but it's probably not very practical, especially if the function is large of if the assignment is buried in a conditional. def spam(): if condition: x = 1 print(x) # Is x local or global? And that's what happens for builtins and globals! py> print(len) # builtin <built-in function len> py> len = 1 py> print(len) # global 1 py> del len py> print(len) # builtin again <built-in function len> But inside a function, that's probably a Bad Thing. We could require explicit declarations of scope for every variable, like languages such as Pascal, C and Java use. But we don't. What we have is a lexical rule for determining what scope names inside functions belong to. Roughly something like this: - every undotted name inside a function belongs to exactly one scope; - if there is a global or nonlocal declaration, that takes precedence; - otherwise, any binding operation to that variable anywhere in the function, even in unreachable code, forces the variable to belong to the local scope; - otherwise, if there is an enclosing function, and there is a local with that name in the enclosing function, then the name in the nested function belongs to the enclosing scope; - otherwise it's a global/builtin. As a consequence of having scopes determined lexically, the compiler is free to optimize for fast local lookups, and use different byte codes for each lookup. In CPython 3.8: LOAD_NAME # globals, builtins and class scope LOAD_GLOBAL # globals and builtins LOAD_DEREF # closures and nonlocals LOAD_FAST # locals LOAD_CONST # literals and certain other constants Other implementations might not use the same lookup mechanisms, so long as the keep the same semantics.
Not without byte-code hacking. As you point out, in Python 2 it prints 2, not 1, because the interpreter took extraordinary efforts to make it work that way. I don't remember all the details but it was confusing and hardly anyone used it except by accident (which made it even more confusing) and so it was taken out in Python 3. The reason it doesn't work in Python 3 isn't because of the static array optimization. exec() could modify the static array (in CPython, it doesn't, but it could). Jython has no such static array, but if and when Jython 3 is available, it too should print 1 rather than 2. The reason for Python's behaviour is that according to the lexical rule, the lack of any assignment to x means that x is treated as a global/builtin, not a local. Even if the exec() succeeded in creating a local variable x with value 2, we have no way to tell the compiler to look up x in the local scope. (Except by doing it manually.) So hypothetically, this could work in a legal Python 3 interpreter: x = "in the global scope" def spam(): exec('x = "in the local scope"') print(x) print(locals()['x'] # prints in the global scope in the local scope Although it doesn't work in CPython 3, it might work in some future Jython 3 or other interpreters where modifications to locals() are reflected in changes to local variables. -- Steven
On 30/05/20 2:52 am, Dominik Vilsmeier wrote:
Indeed locals are special, but why was it designed this way? Why not resolve such an unbound local name in the enclosing scopes?
From experience with other languages I can attest that "sometimes local, sometimes global depending on what gets executed first" is a source of bugs. I like that Python always makes up its mind about whether a given name is local or not. -- Greg
On 30/05/20 7:15 pm, Steven D'Aprano wrote:
Out of curiosity, which languages are you thinking of? I know Lua does that, I can't think of any others.
You've probably never seen the one I'm thinking of. It's a proprietary, vaguely VB-like language used for scripting a particular application. It doesn't work like Lua, but it does have scoping rules that can lead to some surprising results. I've been bitten by it treating something as global that I intended to be local, which has made me appreciate Python's approach to scoping. One particularly weird thing it does: if you don't declare a variable (it has optional declarations) it will *usually* infer it to be local if you assign to it. But if the first assignment is in a conditional branch of the code, it seems to get confused. If you do this: if something then x = 5 else x = 7 end if and later refer to x, it complains that x hasn't been defined. Go figure. -- Greg
Greg Ewing writes:
By contrast, Lisps (at least Lisp2s like Emacs Lisp and Steel Bank Common Lisp) have #'makunbound, and this is an unbound symbol error in both: (defvar x 1) (defvar result '()) (let ((x 2)) (push x result) (makunbound 'x) (push x result) # error is signaled here result) Since Common Lisp is the world's most overengineered language, I would guess this scoping rule is deliberate.
Some versions of GCC would occasionally complain that "x might be used uninitialized" in similar code in C, too. Spent a lot of time on such warnings, sometimes GCC was right, but sometimes it just didn't make sense. Apparently compiling such code, at least with optimization, can be hard.
On Thu, May 28, 2020 at 11:57 AM Steven D'Aprano <steve@pearwood.info> wrote:
Consider this code: ``` x = 1 def foo(): print(x) x = 2 foo() ``` Here `print(x)` doesn't print '1', it gives `UnboundLocalError: local variable 'x' referenced before assignment`. It knows that `x` is meant to be a local and ignores the global value. That doesn't look like an implementation detail to me - does Jython do something different?
On Thu, May 28, 2020 at 12:11:38PM +0200, Alex Hall wrote:
I never said that Python's scoping rules were implementation details. I said that the storage mechanism of *how* local variables are stored, and hence whether or not writes to `locals()` are reflected in the local variables, is an implementation detail. I'm too lazy to look it up right now, but I'm 99.9999999% (nine nines) certain that Python's execution model defines that any binding operation inside the function scope to an undotted name inside a function must make it a local, unless explicitly declared nonlocal or global. (Even if that binding operation is unreachable code.) Binding operations include regular assignment with `=`, imports, `for`, `with ... as`, `except ... as`, and `del`. I don't know about the walrus operator. That means that any non-buggy compliant Python must print NameError, or its subclass UnboundLocalError, when calling your foo function above. (I *think* that NameError would be acceptable, but you might have to ask the Steering Council to make a ruling if it's not already documented.) However the behaviour of locals()['x'] = 999 inside that function is explicitly documented as subject to implementation differences, which is what I was talking about. For the record, both IronPython and Jython 2.7 raise UnboundLocalError, but micropython just raises NameError: $ micropython MicroPython v1.9.4 on 2019-01-13; linux version Use Ctrl-D to exit, Ctrl-E for paste mode
Micropython often gets special dispensation to bend the rules, but in this case I don't think that it needs it. So long as any implementation raises a NameError, not necessarily UnboundLocalError, I think that's sufficient. -- Steven
On Fri, May 29, 2020 at 2:18 PM Steven D'Aprano <steve@pearwood.info> wrote:
I didn't know what it was you were saying back then, and I'm trying, but I still haven't figured it out. I understand bits of it, but I don't know what larger point you're trying to make. I think there are some things you need to try harder to communicate clearly. Chris sad:
There is no *value* in x, yet x has a state.
You responded:
In Python code, no, it has no state, it's just an unbound name.
and then started talking about the locals() dict in great detail for reasons I haven't grasped. My point with that code snippet is that Python (not just some implementations) can distinguish between a bound local, an unbound local, a bound variable of some other type, and a name that isn't defined at all. I think labeling those as 'states' is pretty reasonable. It seemed pretty clear to me that that's the kind of thing Chris was talking about. Maybe you disagree with that label, or are trying to make some other distinction, but I don't see the relevance, as the word 'state' isn't the point anyway. Chris was just saying that a statement like `x ?= y` meaning 'assign the value of y to the local variable x if x is currently unbound' already fits neatly into the language model and doesn't require major changes. Do you disagree? (although I don't endorse the proposal for `x ?= y`)
On Fri, May 29, 2020 at 06:03:30PM +0200, Alex Hall wrote:
Okay, I will try to explain in more detail. I don't know if it will help or just make things more confusing, but I also replied to a post by Dominik covering this. Simplifying somewhat, we can say that under Python's execution rules, every undotted name must belong to at most one scope: - global and/or builtin; - an enclosing function; - the local function. So the compiler has to look each name up in only one of those places, counting globals and builtins as a single scope for this purpose. That is, as I understand it, a strict language guarantee and part of the execution model for Python 3. (Python 2 may have been a bit less strict.) How the compiler does the lookup, and whether the variables are stored as key:values in a mapping, or in a static array, or in a database, or written down as pencil marks on a Turing machine paper tape, is an implementation detail. But the scopes themselves are not. If the variables are implemented as key:values in a mapping, then an unbound variable is one where the key doesn't exist in the mapping. If they are implemented in a static array, then an unbound variable is one where that array cell happens to contain a special sentinel value (possibly a null pointer) to flag it as "unbound". (That's because a memory location cannot contain nothing, it must has some value.) But that distinction between "unbound and doesn't exist at all" versus "unbound but the cell exists" is just an implementation detail. Specifically: nothing in the language specification states that local variables MUST be cells of a static array. [...]
Some pertinent observations: 1. Python cannot distinguish between bound and unbound until runtime. 2. The mechanism of how it distinuishes between bound and unbound is not part of the language, but is an implementation detail. E.g. is it a missing key or a special sentinel value like a null pointer, or something else? The language doesn't care. 3. As part of the execution model, Python enforces a rule that each undotted name belongs to a single scope. This rule uses lexical scoping, which means it can be perfectly and unambiguously determined at compile time. (For simplicity, I'm counting builtins and globals together for this purpose, and ignoring class scopes and comprehensions.) 4. You refer to "variable of some other type" -- in dynamic languages like Python, "type" normally refers to the value bound to the name, not the name itself. So I think it is better to use a different word to distiguish *kinds* of variables. I hope that you agree with those four points. You want to distinguish between "kinds of variables" like global, nonlocal, local:
I think labeling those as 'states' is pretty reasonable.
There are two major reasons why labelling the scope of a variable "state" is not reasonable. Firstly, if it is a state of a variable, then in principle we ought to be able to mutate the state at runtime by some operation like "setting a flag" on the variable: declare x set state of x to global set state of x to local where at each stage there is exactly one variable x that is literally being moved from one scope to another scope (which may or may not require it to be moved in memory). I won't quite say that this is absurd, but it's hard to think of any reason why we would want this. And I certainly cannot think of any language which offers it as a language feature. Even if some language does support it, Python doesn't. Even in Lua, where a name can sometimes refer to a local variable and sometimes to a global within the same block of code, we're not changing the state of a single x, we're referring to two different variables with the same name but in different scopes. We can move variables from one scope to another but only by rewriting the code. That's not a runtime operation :-) The second reason why it is not helpful or meaningful to consider "local, nonlocal, global" to be distinct *kinds* (you said "types" but that is subject to confusion with typed variables in statically typed languages) of variables is that if they were different kinds of thing, they should have functional differences, but they don't. A constant and a variable are different kinds of things. Constants only support two operations: - set an initial value; - get that value; but all variables, regardless of scope, share a maximum of three fundamental operations: - set a value; - get the current value; - delete the variable. There are implementation differences that have observable effects on performance (local lookups are faster than global lookups); there are also practical differences as far as usability and usefulness (e.g. isolation, Globals Considered Harmful, thread safety etc). But fundamentally anything we can do with a local, we can do with a global, etc, all variables are the same kind of thing: def spam(arg): x = arg + 1 return x # Becomes: def spam(): global arg, x x = arg + 1 try: return x finally: del x (The calling conventions would be slightly different, but otherwise the functionality is the same.) Similarly we can replace globals with nonlocals; and if Python had persistent static local variables, we could replace nonlocals and globals with locals too. So globals, nonlocals and locals are pretty much functionally interchangable, except that locals are automatically deleted when the function returns, rather than being manually deleted. The difference is not in *what* they are, but *which scope* they belong to. Which is metadata about the variable, not part of the variable's state. -- Steven
On Sat, May 30, 2020 at 6:00 AM Steven D'Aprano <steve@pearwood.info> wrote:
I'm sorry, I should have been more explicit - I understand how variables work and didn't need a more detailed explanation. The problem is that it's not clear how all these details were relevant to the wider context of the discussion. Your post didn't address that, and now I think the answer is that it's not relevant and that you simply hadn't understood the context. More generally, I'm sorry about this post. I mean it with the best of intentions, but I need to be brutally honest and I don't think there's any way to make this easy for you to read. Please bear with me and be patient. In your case, "try harder to communicate clearly" generally doesn't mean writing in more detail. On the contrary, I think you could usually err on the side of writing too little. I get the impression that you enjoy writing these long posts, and that's fine, but you need to understand that doing so doesn't increase your chances of being understood. Try to focus on quality over quantity, and make sure it's clear *why* you're saying what you say. Connect it to the rest of the discussion. More important than your writing is your reading and understanding. Spend more time reading past posts in the thread and absorbing them so you can remember what was said later. If you think someone is implying that something was said previously, try to find that reference. I've seen you forgetting even your own words (a point about final classes https://mail.python.org/archives/list/python-ideas@python.org/message/QXUABJ...) and not even doing a basic search to see what was being referred to, and then others have to take time to directly quote or link for you. Possibly as a symptom of being more enthusiastic about writing than reading, it often feels like you start replying to a post before you have finished reading it. The most blatant example of this was [here]( https://mail.python.org/archives/list/python-ideas@python.org/message/HHJ6XX...). I basically said "It's clear what the arguments are, but not which parameters they're bound to", and you basically quoted me with a redundant interjection "It's clear what the arguments are, [But it's not clear which parameters they're bound to] but not which parameters they're bound to". I asked "Steven, what happened above? ... It feels like you're not reading what I say." and then in the same post I went on to say "Anyway, talking about this has made me feel not so convinced of my own argument." [Your response]( https://mail.python.org/archives/list/python-ideas@python.org/message/FGITGC...) was "Trust me Alex, I am reading what you say. What I don't know is whether you mean what you say, because frankly I think your position ... is so obviously wrong that I don't understand why you are standing by it." In other words, your response (1) didn't answer the question of what happened, and (2) immediately demonstrated again the very problem of not reading which I was pointing out and you had casually brushed aside, insisting that I was standing by a position which I had just abandoned. In addition to simply reading what people say, take more time to think about their words and try harder to understand what they mean. When in doubt, try to interpret them as being as rational as possible. This is called the principle of charity. Maybe you already know this, but I don't think you're implementing it well. This kind of problem is a repeating pattern with you in this list. I find it exhausting and frustrating not only having discussions with you but watching you have discussions with other people and doing the same things to them. Now, as to what happened in this thread: Greg first proposed "a way of declaring optional arguments with no default, and a way of conditionally assigning a value to them if they are not bound.": https://mail.python.org/archives/list/python-ideas@python.org/message/4C2WQR... Chris referred to this idea here: https://mail.python.org/archives/list/python-ideas@python.org/message/SJPGHG... He quite clearly mentioned that Greg suggested the idea, which would be a cue to look that up if you weren't sure about it. But aside from that, he basically spelled out the proposal again as he saw it, with slightly different syntax. You responded to that post by Chris, starting a long discussion about the semantics of the word 'state' in regards to variables. It seems to me that most of this was pointless. I was struggling to see what relevance your arguments had to the proposal by Greg and Chris, and you didn't seem to be aware of that problem. I don't think I was alone in this experience. Finally, when I brought you back to the main point ( https://mail.python.org/archives/list/python-ideas@python.org/message/PEHDA3...) it became clear that you didn't understand the proposal. `?=` was not the extent of it, and both of the above posts clearly laid out that there would also be a way to declare optional parameters without a default (either `def foo(bar=):` or `def foo(?bar):`) which could therefore be unbound in the body. I think it's reasonable to expect that would have read these posts, especially considering you replied to one of them. And if you see an obvious flaw, take some time to refresh your memory and reread a proposal so you know that it hasn't been addressed already.
Attempting to bring things back on topic to function parameters with late binding. On Fri, May 29, 2020 at 06:03:30PM +0200, Alex Hall wrote:
I have no idea whether `?=` alone requires major changes or not. Probably not, since we can already implement it as a try...except: try: x except NameError: x = y But as the proposal relates to function calls, it is a big change that will turn early detection of some errors into late detection. Consider what happens when you call a function. The interpreter matches up arguments supplied in the function call to parameters in the function signature. If any parameters don't get an argument, the intrepreter provides default values. If, after applying defaults, any parameter doesn't have a value then the intrepreter raises TypeError, otherwise it calls the function and enters the body of the function. The consequence of this is that if the function body is entered, it is impossible for any parameter to be unbound. def spam(arg): # if we enter the body of the function, then arg must be # bound and `arg ?= ...` will never apply. That means that Chris' proposed `?=` operator would not help at all to get late-binding defaults. Adding a bind-only-if-unbound operator might be useful, or not, but it doesn't solve the mutable default issue. In order to solve the mutable default issue, the intrepreter has to stop raising TypeError, and instead enter the function body with the function parameters left unbound. So exceptions like this will disappear: py> len() TypeError: len() takes exactly one argument (0 given) to be replaced with something like this: UnboundLocalError: local variable referenced before assignment when the function tries to access the unbound parameter. And we change code currently written like this: def spam(arg=None): if arg is None: arg = expression into code written like this: def spam(arg): arg ?= expression which saves one line, not much benefit to gain for the pain. So a general purpose `?` bind-if-unbound operator doesn't solve the problem at hand, even if it were useful in other ways. What if it wasn't a general purpose operator, but instead special syntax that applies only in function signatures? Then we could write: def spam(arg?=expression): and the rule for the interpreter would become: Match up arguments supplied in the function call to parameters in the function signature. If any parameters don't get an argument, apply default values: - if the default is set with `=`, it is early-bound and nothing changes from today; - if the default is set with `?=` it is late-bound and the default is re-evaluated as needed; Finally, if after applying defaults, any parameter doesn't have a value, then the intrepreter raises TypeError, otherwise it calls the function and enters the body of the function. The concept of bound-or-unbound doesn't come into this, or at least no more that it already applies to the status quo. The whole process takes place before the function is called. The only differences from the status quo are that the `?` tells: - the compiler to delay evaluating the default and store the expression itself (in some format), rather than evaluate the expression and store the evaluated value; - the interpreter to re-evaluate that expression, not just fetch the pre-evaluated value. Is that a big change or hard to implement? I don't know. -- Steven
On 30/05/20 12:11 am, Steven D'Aprano wrote:
That's true, but just to be clear, my ?= idea doesn't rely on that implementation detail. If locals were kept in a dict, for example, it could work by testing whether the name has an entry in the dict. This also means that it *could* be made to work in class and global scopes if it were so desired. -- Greg
On Sat, May 30, 2020 at 04:34:49PM +1200, Greg Ewing wrote:
This thread is huge and I'm losing track of who said what and what they meant by it. I thought `?=` was Chris' idea :-) Is this `?=` idea for a general purpose operator we can use anywhere we like? That's what I thought it was, but now I'm doubting my own memory. E.g. I do this lots of times: try: spam except NameError: spam = expression (Well, usually I end up using `def spam()...` but that's another story.) If we had that operator I could use: spam ?= value Or do you mean for it to be purely syntax for function signature lines, i.e. only valid in a signature line: def spam(arg?=expression): ... If so, I thought you were opposed to putting late-binding inside signature lines. Also, it would still require special handling by the interpreter to ensure that the expression was re-evaluated each time it was needed. Otherwise it's still just early binding.
This also means that it *could* be made to work in class and global scopes if it were so desired.
I cannot imagine why it could only be made to work in locals but not elsewhere. A NameError (including subclasses) is a NameError, and a name is always either bound or unbound, there is no third state it could be. It either is bound to a value, or not bound to a value. Some people (Alex, Chris I think?) have tried to argue that there is a distinction between an unbound variable and a variable that doesn't exist at all, but I'm not clear what they think that distinction would be, or why (if such a distinction exists) the interpreter doesn't tell when it's one or the other: NameError: name 'grue' is not defined NameError: name 'bleen' doesn't exist at all -- Steven
On Sat, May 30, 2020 at 6:13 PM Steven D'Aprano <steve@pearwood.info> wrote:
I was talking about a somewhat similar notion of being able to cleanly ask the question "is this variable bound to anything", but the ideas have been broadly similar and it's not easy to figure out who said what :)
The difference would be that, when a local variable doesn't exist, a global or builtin is searched for. That's very different from the local existing but having no value. Local scope is the only one where this happens, but it's kinda slightly important, given how much Python code executes at that scope :) ChrisA
On 30/05/20 8:03 pm, Steven D'Aprano wrote:
Is this `?=` idea for a general purpose operator we can use anywhere we like?
I introduced it as part of a two-part idea for allowing optional parameters without a default. But there would be nothing to stop you from using it elsewhere. The syntax was inspired by a similar thing in makefiles. It's entirely possible that someone else has used it for something else, though.
That was my idea, yes. -- Greg
On Tue, May 26, 2020 at 9:52 AM Steven D'Aprano <steve@pearwood.info> wrote:
A NOT_SPECIFIED singleton in builtins would be pretty clear.
This is the point -- it "implies" no value was passed -- which is usually good enough, but there is something to be said for being more explicit about that. and it's "one" of the purposes -- None has many purposes, and these sometimes (though not often) confilct / overlap with the "no value was passed" use case. If you want a *second* such sentinel value, we run into the problem I go
on to describe.
As far as I can tell -- that problem is that it still wouldn't be useful for ALL cases of not passing arguments.Which doesn't, by any means mean that it would never be useful. I would venture to guess that if such a special value existed already, it would be mostly used in cases where None would have been fine, but it would be more explicit, which I think would be a good thing. Another thing to keep in mind is that None is not, in fact, all that special. The only things (that I can think of at the moment) special about are: - it is a builtin - it is the default value passed back from function calls - It's a well established convention - anything else?? (note: it would become a more special part of the language id PEP 505 or something like it were to be adapted) That later point is key -- we all agree to use None for things like the current example: meaning no specified, but there's nothing in the language spec or None itself that requires that. And this theoretical NOT_SPECIFIED value *could* have special properties in the language, for instance: function_call(x=NOT_SPECIFIED) could be illegal. Is that a good idea? I haven't thought it out, but it *could* be done. Anyway -- all I'm suggesting is that yes, it would be nice to have another "standard" value with a more defined meaning. Is it critically important? no Would it be very disruptive? no. well, maybe yes, as we'd have a long period of people using both None and gteh new one in the same context -- and that would be even more confusing. Could there be a dozen or more other "standard" values that would be equally useful? maybe, and if that's the case, then yeah, probably not worth doing this at all. I'm not sure if this is really parallel, but this reminds me of NaN -- NaN can be the result of a calculation gone bad, and it's also used to mean "missing value", or "not set", and other use cases. And this works most of the time OK, but it IS an issue in some cases -- witness the massive discussions around how to handle missing values in numpy. Another special floating point value that specifically means "missing data" would be pretty helpful. Anyway, I'm not pushing this, and there doesn't seem to be much support, so I'm done. I am intrigued by Chris A's idea of leveraging unbound locals though. -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
On 24.05.20 19:38, David Mertz wrote:
Do you have an example which can't be solved by using generator expressions and itertools? As far as I understand the Dask docs the purpose of this is to execute in parallel which wouldn't be the case for pure Python I suppose? The above example can be written as: a = (inc(x) for x in data) b = (double(x) for x in data) c = (add(x, y) for x, y in zip(a, b)) total = sum(c)
Subject changed for tangent. On Sun, May 24, 2020 at 4:14 PM Dominik Vilsmeier <dominik.vilsmeier@gmx.de> wrote:
Obviously delayed execution CAN be done in Python, since Dask is a pure-Python library that does it. For the narrow example I took from the start of the dask.delayed docs, your version look equivalent. But there are many, not very complicated cases, where you cannot make the call graph as simple as a sequence of generator comprehensions. I could make some contrived example. Or with a little more work, I could make an actual useful example. For example, think of creating different delayed objects within conditional branches inside the loop. Yes, some could be expressed with an if in the comprehensions, but many cannot. It's true that Dask is most useful for parallel execution, whether in multiple threads, multiple processes, or multiple worker nodes. That doesn't mean it would be a bad thing for language level capabilities to make similar libraries easier. Kinda like the way we have asyncio, uvloop, and curio all built on the same primitives. But another really nice thing in delayed execution is that we do not necessarily want the *final* computation. Or indeed, the DAG might not have only one "final state." Building a DAG of delayed operations is almost free. We might build one with thousands or millions of different operations involved (and Dask users really do that). But imaging that different paths through the DAG lead to the states/values "final1", "final2", "final3" that share many, but not all of the same computation steps. After building the DAG, we can make a decision which computations to perform: if some_condition(): x = concretize final1 elif other_condition(): x = concretize final2 else: x = concretize final3 If we avoid 2/3, or even 1/3 of the computation by having that approach, that is a nice win where we are compute bound. -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On Sun, May 24, 2020 at 01:38:26PM -0400, David Mertz wrote:
Sure, but when you have seven parameters that all take late-bound defaults, it becomes a PITA. def func(...): # late binding boilerplate if dopey is None: if happy is None: if doc is None: if sneezy is None: if grumpy is None: if sleepy is None: if bashful is None: # AAAAND at last we get to the actual function body... This "if arg is None..." idiom is okay, but it's just a tiny bit of extra friction when coding. Nothing as drastic as a "design flaw" or a "wart" on the language, but it's slightly rough edge.
Well, I don't know about a thousand, but I'm currently writing up a proto-PEP for delayed evaluation, and I've got six use-cases so far. -- Steven
On 24.05.20 18:34, Alex Hall wrote:
It looks like the most common use case for this is to deal with mutable defaults, so what is needed is some way to specify a default factory, similar to `collections.defaultdict(list)` or `dataclasses.field(default_factory=list)`. This can be handled by a decorator, e.g. by manually supplying the factories or perhaps inferring them from type annotations: @supply_defaults def foo(x: list = None, y: dict = None): print(x, y) # [], {} @supply_defaults(x=list, y=dict) def bar(x=None, y=None): print(x, y) # [], {} This doesn't require any change to the syntax and should serve most purposes. A rough implementation of such a decorator: import functools import inspect def supply_defaults(*args, **defaults): def decorator(func): signature = inspect.signature(func) defaults.update( (name, param.annotation) for name, param in signature.parameters.items() if param.default is None and param.annotation is not param.empty ) @functools.wraps(func) def wrapper(*args, **kwargs): bound = signature.bind(*args, **kwargs) kwargs.update( (name, defaults[name]()) for name in defaults.keys() - bound.arguments.keys() ) return func(*args, **kwargs) return wrapper if args: return decorator(args[0]) return decorator
On Sun, May 24, 2020 at 10:05 PM Dominik Vilsmeier <dominik.vilsmeier@gmx.de> wrote:
This still leaves the information out of the signature, which I've argued is a more important consideration than saving a couple of lines of boilerplate. You could solve this by allowing people to write: ``` @supply_defaults(x=list, y=dict) def bar(x=[], y={}): print(x, y) # [], {} ``` and telling `supply_defaults` to ignore the actual defaults wherever factories are supplied, but there's no guarantee people will put sensible defaults in the signature. For the mutable defaults only case, you could have: ``` @copy_mutable_defaults def bar(x=[], y={}): print(x, y) # [], {} ``` which would only pay attention to a specific whitelist of default types like list, dict, and set, and copy them each time. Not great.
On 24/05/2020 21:03, Dominik Vilsmeier wrote:
That's very clever, but if you compare it with the status quo: def bar(x=None, y=None): if x is None: x = [] if y is None: y={} it doesn't save a lot of typing and will be far more obscure to newbies who may not know about decorators. (And if other decorators are used on the same function, the fog only thickens.) They may not know why the contorted way of assigning to x and y is necessary, but they can follow what it does. Even someone familiar with decorators will have to look up supply_defaults and find out what it does (and it jolly well ought to be copiously documented :-)). Trying to do some blue-sky thinking, I have tried to come up with other ideas, but have not found anything very convincing, e.g.: Idea: Invent a new kind of string which behave like f-strings, called say g-strings. Add a rule that if the default value of an argument is (an expression containing) a g-string, the default value is recalculated every time the function is called and a value for that argument is not passed. So: def bar(x=g'{ [] }], y=g'{ {} }'): Cons: I could list a couple myself, no doubt others can think of many more. No, forget fudges. I think what is needed is to take the bull by the horns and add some *new syntax* that says "this default value should be (re)calculated every time it is needed". Personally I don't think the walrus operator is too bad: def bar(x:=[], y:={}): It's concise, and arguably will largely only confuse people who are already confused. It AKAICS introduces no ambiguity (it's currently a syntax error). It *is* somewhat arbitrary (in one context the walrus means 'this assignment becomes an expression', in another it means 'recalculate this expression every time it's needed'). But hey, you could say the same about colon, comma, parentheses, braces and what-have-you. It is IMO practical. It needs no new keywords. Other syntaxes are of course possible, but for me, in this case, conciseness is a virtue. YMMV. (Possibly heretical) Thought: ISTM that when the decision was made that arg default values should be evaluated once, at function definition time, rather than every time the function is called and the default needs to be supplied that that was the *wrong* decision. There may have been what seemed good reasons for it at the time (can anyone point me to any relevant discussions, or is this too far back in the Python primeval soup?). But it is a constant surprise to newbies (and sometimes not-so-newbies). As is attested to by the number of web pages on this topic. (Many of them defend the status quo and explain that it's really quite logical - but why does the status quo *need* to be defended quite so vigorously?) I realise that it's far too late to change this behaviour in Python 3. And also that there are uses for the current behaviour. (Though I can't recall having used it myself.) But maybe for Python 4?
On 25.05.20 03:03, Rob Cliffe via Python-ideas wrote:
Actually it was intended to use type annotations a la PEP 585 (using builtin types directly) and hence not requiring explicit specification of the factory: @supply_defaults def bar(x: list = None, y: dict = None): pass This also has the advantage that the types are visible in the function signature. Sure this works only in a limited number of cases, but the case of mutable defaults seems to be quite prominent, and this solves it at little cost.
What about using `~` instead of `:=`. As a horizontal symbol it has some similarity to `=` and usually "~" denotes proportionality which also allows to make a connection to the use case. For proportionality "x ~ y" means there's a non-zero constant "k" such that "x = k*y" and in the case of defaults it would mean, there's a non-trivial step such that `x = step(y)` (where `step=eval` roughly). def bar(x=1, y~[], z ~ {}): It looks better with spaces around "~" but that's probably a matter of being used to it. A disadvantage is that `~` is already a unary operator, so one could do this: `def foo(x~~y)`. But how often does this occur anyway?
On Mon, May 25, 2020, 6:49 AM Rob Cliffe via Python-ideas < python-ideas@python.org> wrote:
Not heretical so much as just half-baked. DISCLAIMER: I'm far from an expert. I'm not even a professional developer. But I think the idea that handling defaults this way was a mistake from the beginning is exactly wrong, and that this aspect of python doesn't need to be touched. I think that people who complain about this are missing the largeness of some fundamental problems that changing it would cause. And I think the set of decisions that would have to be made to implement it- no matter what those decisions they are- would lead to no end frustration, probably more than the current state of affairs. *First of all*: supplying a default object one time and having it start fresh at every call would *require copying the object*. But it is not clear what kind of copying of these default values should be done. The language doesn't inherently know how to arbitrarily make copies of every object; decisions have to be made to define what copying the object would MEAN in different contexts. Would it mean: *1.* copy.copy() applied to the object every function call? *2.* copy.deepcopy() applied every function call? The two options above would allow the object class to decide HOW the copying occurs (by relying on the default copy.copy or copy.deepcopy method, or providing __copy__ or __deepcopy__). But it would NOT allow the class to decide WHICH CHOICE is made-- copy, or deepcopy. No matter which is chosen, it will be problematic. deepcopy() will be desirable sometimes, copy() will be desirable other times. And other times, NEITHER will be desirable. copy/deepcopying doesn't even always actually make a copy, which will be unexpected for some: class C: ... copy(C) is C # True copy('xyz') is 'xyz' # True Some objects in the wild are simply not meant to be copied, but ignorant users WILL try to use them as copied defaults anyway ("ignorant" not used as a sleight; it is critical for being productive developer to maintain just the right level of ignorance so that I do not have to CARE about details of the things I am using). If a user tries to use such an object like so: from foo import bar def h(a:=bar()): ... ...it will require the creator of the foo library to maintain a __copy__ or __deepcopy__ method to provide an error message telling the user their object can't be used this way. And copying doesn't come for free; copying persistent objects, especially that take up a lot of memory at every function call, rather than freshly initializing them, could become extremely slow. Yes, this can be circumvented by simply not using the new feature. However, then you have to explain, in detail, how to know when to use the feature or not. *SIGH*. On top of this, Python already has a reputation for slowness; some of this is earned, some if it isn't and is just a result of people writing bad python code. If we made it EASY and actually encouraged people-- by providing a specific feature-- to get in the habit of writing code that slows things down considerably, this seems like a bad plan. Worse: it will create a situation where for every public-facing type, every developer of every library will have to stop for a minute and think "What will happen if the user tries to make my object work using the new := copy-at-call feature?" Allowing objects to be faithfully copied, OFTEN, is generally NOT a concern I worry about at all. I am not sure if pro developers do either, but I doubt it. *3.* The language does something more fancy like an eval() of the actual code text entered into the default parameter definition. If this 3rd one: do references inside of this definition get updated at the time of the call? Or do we create different behavior depending on whether the default value is a literal? Both could feel unexpected to the user depending on the case: # literal case def f(a:=[]): ... f() # a inside f is eval('[]') at call time; no problem here # non literal case _A = [] def g(a := _A): ... _A.append(1) g() What is the default of a inside g() here? eval ('_A'), which is [1]? Would not THAT be every bit as confusing to a newbie as the current situation? If we want the value of a in g() to be [1], an object does not be able to control how it is copied; the current copy/deepcopy machinery has to be totally circumvented. If we want the default value of a in g() to be [], we'll need some combination of *1* *or* *2* *and* *3*: an eval() of the initial value when the module runs, and then at the function call, a copy() or deepcopy() is applied to whatever was evaluated at the module import. It seems to me that this second version of *3* -- an eval followed by a copy() or deepcopy() -- makes the most sense and would be least surprising. However, now you still run into all of the same pitfalls that need to be solved in the case of *1* and *2*. *4.* Instead of copy() or deepcopy(), use the same basic copying algorithm contained therein, but with no calls to __copy__ and __deepcopy__; it is essentially a new kind of copying operation. This would make things a little faster. But this way of copying is another thing I have to learn if I want my user defined objects to behave in predictable and thoroughly understood ways. *Second of all*: no matter which way forward is chosen, it seems to be that this new syntax would have to slow things down, considerably in many cases. To summarize: We are already talking about making things easier to understand for the type of new coder that finds this issue confusing, but I don't think it is going to be THAT much easier to explain to the same coder that: A. there are two ways to provide default values for function parameters, = and := B. you can make sure you have a fresh new object every time by using the new shiny := syntax! C. ...except you often shouldn't use that because it will needlessly slow things down for large objects D. also, let me explain to you the difference between copy and deepcopy... hold on, yeah i know that's not what you asked about, just hear me out E. oh btw now that you understand about copy/deepcopy, many objects aren't copied even if you use the := --- Ricky. "I've never met a Kentucky man who wasn't either thinking about going home or actually going home." - Happy Chandler
On 25.05.20 17:29, Ricky Teachey wrote:
It wouldn't copy the provided default, it would just reevaluate the expression. Python has already a way of deferring evaluation, generator expressions: >>> x = 1 >>> g = (x for __ in range(2)) >>> next(g) 1 >>> x = 2 >>> next(g) 2 It's like using a generator expression as the default value and then if the argument is not provided Python would use `next(gen)` instead of the `gen` object itself to fill the missing value. E.g.: def foo(x = ([] for __ in it.count())): # if `x` is not provided use `next` on that generator pass Doing this today would use the generator itself to fill a missing `x`, so this doesn't buy anything without changing the language.
On Tue, May 26, 2020 at 2:24 AM Dominik Vilsmeier <dominik.vilsmeier@gmx.de> wrote:
Well.... if you want to define the semantics that way, there's a way cleaner form. Just talk about a lambda function: def foo(x = lambda: []): pass and then the function would be called and its return value assigned to x, if the parameter isn't given. But if this were actual language syntax, then it would simply be "the expression is evaluated at call time" or something like that. ChrisA
On Mon, May 25, 2020 at 12:33 PM Chris Angelico <rosuav@gmail.com> wrote:
This late binding is what I was clumsily referring to as option *3* (version with no copying). But this is still going to end up having what people would consider surprising behavior, is it not? It is essentially equivalent to this using current syntax: late_binder = lambda: [] def f(a = None): if a is None: a = late_binder() But if you have behavior like this (assuming the := syntax): _A = [] def f(a:=_A): ... ...which is the same as this: _A = [] def f(a=None): if a is None: a = _A Here's a little bit more fleshed out example: _complex_mutable_default = MyObj(a = 1, b = 2, c = 3, d = 4, e = 5, f = 6, g = 7, h = 8, i = 9, j = 10) def func(x := _complex_mutable_default): ... Above, _complex_mutable_default is *NOT* immutable-- it is *mutable*. It gets late-evaluated every call, rather than being evaluated at definition time. This is going to be pretty surprising for a lot of people. Of course it won't come up nearly as often as the current def `f(a=[]): ...` issue, but this will eventually need to be explained to people every bit as much as the "mutable default argument" issue. People will need to understand they can't do this, and have to do this instead: _complex_mutable_default_factory = lambda: MyObj(a = 1, b = 2, c = 3, d = 4, e = 5, f = 6, g = 7, h = 8, i = 9, j = 10) def func(x := _complex_mutable_default_factory()): ... Now, perhaps it will be worth this syntax change to capture a large portion of more simple cases. But I wonder if people will spend the next decade complaining about a new category of "surprising behavior" that needs to be fixed. Anyway, my opinion: I think things are fine as they are. It is not a heavy lift to perform the "if <thing> is None:" dance.
On Tue, May 26, 2020 at 7:19 AM Ricky Teachey <ricky@teachey.org> wrote:
I don't see how this is going to be any different from anything else. If you do the same thing using the current "=object()" idiom, and you break out the complex default into a global, then obviously you're asking for it to be evaluated only once. Surely that shouldn't be at all surprising. ChrisA
Hello, On Tue, 26 May 2020 07:34:32 +1000 Chris Angelico <rosuav@gmail.com> wrote: []
The more worrying sounds the idea to have a special evaluation context for specially marked default arguments. Just imagine - *everywhere* (#1) in the language the evaluation is eager, while for specially marked default arguments it's deferred. Which leads to the situation that: def foo(x := a + b) vs c = a + b def foo(x := c) can lead to different results. I'd suggest that people should love "explicit is better than implicit" principle of the language. And those who don't, aren't going to be satisfied by minor bend-in's like that - they will want more (while even small things like that will be confusing for all the rest). I'd suggest they're looking for generic macros facility instead, which in this particular case will allow them to wrap default argument expression in lambda, then insert if's in the body to call that lambda if the argument value is not provided. So, just revive https://www.python.org/dev/peps/pep-0511/ and rock on. (And that PEP is just a convenience, you can do everything needed for that right away, albeit in a nicely tangled manner.) #1: Except for https://www.python.org/dev/peps/pep-0563 , but annotations (and results of their evaluation) are not the part of the baseline language semantics (baseline == as implemented by CPython).
ChrisA
[] -- Best regards, Paul mailto:pmiscml@gmail.com
On Tue, May 26, 2020 at 8:06 AM Paul Sokolovsky <pmiscml@gmail.com> wrote:
def foo(x = None): if x is None: x = a + b c = a + b def foo(x = None): if x is None: x = c Is it surprising that these behave differently? You are refactoring something from a late-bound default argument value into a global variable. Surely it's obvious that it will now be evaluated once?
I'd suggest that people should love "explicit is better than implicit" principle of the language.
Explicit meaning that you need to use a specific symbol that means "this is to be late-bound"? Or explicit meaning "something that I like", as opposed to implicit meaning "something that I don't like", which is how most people seem to interpret that line of the Zen? ChrisA
On 5/25/2020 6:37 PM, Chris Angelico wrote:
That's a great comment, and so true. When f-strings were first proposed, people used that exact same line from the Zen to mean "I don't like f-strings". And I was always puzzled: in what way is it not explicit? The other old chestnut that bugs me is "but you won't be able to use this feature for years, because you'll have to support old versions of Python for so long". So what? That's true of every language feature ever added. Should we never add anything? This is really just a way to shut down changes, too. That said, I can say I'm -1 on any late binding proposal, just because I don't think the feature-to-cost benefit justifies it. I don't even need to appeal to any other argument! Eric
On Mon, May 25, 2020 at 06:45:47PM -0400, Eric V. Smith wrote:
We agree on that! But...
Well, there's this: f-strings look like strings. They're called strings. People think of them as not just strings but string literals. But they're actually executable code that is run at runtime, making them semantically an implicit call to `eval`. py> print("Actual string: {sum(len(s) for s in dir(builtins))}") Actual string: {sum(len(s) for s in dir(builtins))} py> print(f"Actual eval: {sum(len(s) for s in dir(builtins))}") Actual eval: 1882 The dissassembly of the regular string is two lines, specifically a LOAD_CONST and a RETURN_VALUE: py> dis.dis( ... compile('"Actual string: {sum(len(s) for s in dir(builtins))}"', ... '', 'eval')) 1 0 LOAD_CONST 0 ('Actual ...') 2 RETURN_VALUE (I've truncated the value of the constant for brevity.) The dissassembly of the f-string is twenty-five lines of byte-code, including four calls to CALL_FUNCTION. In my experience, people get defensive when you point this out, and say "But it returns a string, so its a string". By that logic, this function is a string too: lambda: str(sum(len(s) for s in dir(builtins))) The difference between the f-string and the lambda is that the lambda needs explicit parens to perform the computation, the f-string doesn't. Isn't the whole point of f-strings to iterpolate evaluated expressions into a format string without needing an explicit evaluation? -- Steven
Hello, On Tue, 26 May 2020 08:37:59 +1000 Chris Angelico <rosuav@gmail.com> wrote: []
Of course it will be obvious - you provided explicit control flow to make it work like that, and all that stays within the bounds of the existing semantics of the language.
No, it means "use explicit 'if' if you want to deal with mutable default".
I'd prefer to think in terms of implementation complexity. Implemented in adhoc way (and that's how things get implemented in C, in particular, in CPython), it will be quite a noticeable complexity up-glitch to function representation/implementation, and all it achieves is trading one confusion for another. (Well, for two others: why the heck there're 2 ways to define default args, which is to use when, and why one of them doesn't work across subexpression refactoring. Oh, and old confusion still stays with us. There's really no easy way to resolve the original confusion, short of banging mutable defaults. Which actually one that I'd like, because it would necessitate pushing "const" (currently, "Final") variable annotation down to the core of the language, for Python remains literally the last one which lacks it comparing to the competition.)
ChrisA
-- Best regards, Paul mailto:pmiscml@gmail.com
On Tue, May 26, 2020 at 02:25:38AM +0300, Paul Sokolovsky wrote:
Point of terminology here. Let's not conflate two separate issues. There is nothing wrong with putting a mutable default value directly in the function signature def func(param=[]): works absolutely fine for what it does. It's just that what it does is not what some people want it to do. The real issue is not mutable defaults as such, but early versus late binding.
To answer those questions: (1) There are two ways to define default args, because there *are* two ways to define default args: - calcuate the default argument once and re-use it as needed; - or re-calculate the default argument each time you need it. Asking why there are two ways is a very odd question. It's rather like asking why there are two ways to travel around a circle (clockwise and counter-clockerwise, and at least three ways to parse a binary tree (preorder, inorder, postorder). Because there just are, that's the nature of the thing. (2) You use whichever one you need for the specific function you are writing. Nobody can answer that except yourself. If you don't understand Python's object model well enough to answer that question, then you're going to be stumbling over problems in all sorts of things: a = [] b = a b.append(1) a == [1] # Why??? If you want the default value to be X, then: - if you want a fresh X each time, then you want late binding; - if you want the same X each time, then you want early binding; - if you don't care, then early binding is likely to be a little more efficient. (3) One of them doesn't work across subexpression refactoring for the exact same reason that it doesn't work in other function calls, and for the same reason it may not work *right now* with the `if arg is None` idiom: def func(arg=None): if arg is None: arg = print('computation') or [] versus: c = print('computation') or [] def func(arg=None): if arg is None: arg = c Likewise if you refactor an expression outside of a loop, the behaviour will change.
Oh, and old confusion still stays with us.
*shrug* People who code on automatic pilot without thinking about what the code they write *actually* means rather than what they *assume* it means are always going to be confused by one thing or another. I only have so much sympathy for people who get confused or angry when the language doesn't read their mind and Do What I Mean. At some hypothetical future point that Python has some syntactic method for explicitly marking defaults as late-binding: # straw-man proposal def func(s='', arg=mutable {}): if people continue to write `arg={}` when they want `arg=mutable {}` then I will have no sympathy for them. That's just a PEBCAK error, not a language flaw.
There's really no easy way to resolve the original confusion, short of banging mutable defaults.
How does the compiler know if an arbitrary object is mutable or not? When I want early binding of a mutable object, and I sometimes do, why should the compiler tell me I can't have it just because some other person may, or may not, be confused by the semantics of the language? -- Steven
On Mon, May 25, 2020 at 6:24 PM Dominik Vilsmeier <dominik.vilsmeier@gmx.de> wrote:
Agreed, it would definitely reevaluate each time, there would be no copying involved at any stage. And evaluating each time wouldn't be slow, it might even be faster than the `if x is None` check. Although if *all* defaults were changed to evaluate each time, that'd probably slow things down a little. A couple of examples where these kinds of semantics are needed: logging.StreamHandler has: ``` def __init__(self, stream=None): if stream is None: stream = sys.stderr ``` This doesn't use a normal default so that something can patch sys.stderr (very common and useful) before instantiating the handler but after importing logging. The code: ``` if context is None: context = getcontext() ``` appears 44 times in _pydecimal.py, although I can't guarantee that all of them could be replaced by one of these proposals.
On Mon, May 25, 2020 at 06:22:14PM +0200, Dominik Vilsmeier wrote:
A function would be a more obvious mechanism. But this won't work to solve the mutable default problem. Here's a simulation: # we want to delay evaluation for arg=x # in this case we have arg=[] x = [] g = lambda: x def func(): arg = g() return arg At first it seems to work: py> func() [] py> func() [] But we have the same problem with mutable defaults: py> L = func() py> L.append(1) py> func() [1] The problem is that this model just reuses the object referenced in x. That's early binding! Python functions don't use a hidden function or generator `g`, as in this simulation, or a global variable `x`. They stash the default value inside the function object, in a dunder attribute, and then retrieve it when needed. To get late binding, you need to stash not the *value* of x, in this example an empty list `[]`, but some sort of code which will create a new empty list each time. A naive implementation might stash the source code expression and literally evaluate it: x = '[]' g = lambda: eval(x) but there are probably faster ways: x = '[]' g = eval('lambda: %s' % (x,)) One way or the other, late binding has to re-evaluate the expression for the default value. Whether it uses the actual source code, or some clever byte-code, it has to recalculate that value each time, not just retrieve it from somewhere it was stashed. -- Steven
On Mon, May 25, 2020 at 02:03:49AM +0100, Rob Cliffe via Python-ideas wrote: [quoting Dominik Vilsmeier]
It looks like the most common use case for this is to deal with mutable defaults
It might be the most common use case, but it's hardly the only use case. The PEP talks about special cases :-) I can tell you that it is very frustrating to what to do something and not be able to do it, not for good design reasons, or for implementation reasons, but simply because the language designers chose to support only a subset of behaviour. Mutable defaults is a subset of late-binding defaults. A solution to late-binding automatically solves the mutable default question. Why settle for half a solution? Looking at some of my mutable defaults, I've used the usual `[]` and `{}` of course, but I've also used `[0]` amd other pre-populated lists, sets and dicts, and instances of custom classes. I've also used default values that are functions themselves, which are technically mutable even if we don't typically mutate them. I've also used plenty of *immutable* defaults, where I have wanted them recalculated on each use. [Rob]
Idea: Invent a new kind of string which behave like f-strings, called say g-strings.
G-strings? *cough*
That's pretty much the same rule I've been working on for my proto-PEP, except for the "g-string" part. I know that f-strings have become super-popular, but that doesn't make every piece of syntax a nail that we hammer with the "random-letter"- string until we have 26 different string prefixes :-) [...]
It really wasn't a mistake. Look at your default values: the great majority of defaults need to be evaluated only once. Making every default value a late-bound expression would be wasteful of time and memory. (Although a sufficiently smart compiler could minimize that waste in the common case of immutable literals. How? By sneakily shifting to early binding and avoiding the late evaluation!) There's also at least two execution models for late binding that I know of, and which ever one you chose, some people would complain that it's not the right one. If you can only have one model for function defaults, early binding is the clear winner. With early binding, it is easy to implement late binding in the function body using the "if None: arg = value" idiom. But with late binding, it is *seriously* inconvenient and difficult to go the other way and implement early binding semantics.
But it is a constant surprise to newbies (and sometimes not-so-newbies).
Yes, people say that they want late binding. Then they use closures, which implement late binding, and they complain that it's a bug and it was the wrong decision to use late binding. Then they go back to writing a function definition, and complain that they should have used late binding. I remind you that the usual work-around for the "closures use late binding" gotcha is to use *early binding* to fix it. The gotcha: py> def func(): ... L = [] ... for i in range(3): ... # closure using late binding for i ... L.append(lambda: 100+i) ... return [f() for f in L] ... py> func() [102, 102, 102] The solution is to work around the problem with early binding: py> def func(): ... L = [] ... for i in range(3): ... # work around the problem ... L.append(lambda i=i: 100+i) ... return [f() for f in L] ... py> func() [100, 101, 102] If functions used late binding for all defaults: - people would still be surprised, just as they are with closures; - it would be wasteful of time and memory, slowing down function calls for no good reason; - it would make early binding semantics really difficult; - and it would destroy the work-around for late binding, preventing it from working. Late binding of function defaults an option? Sure. But if Python had used late binding for all defaults, with no way to opt out, the language would be significantly worse: slower, heavier memory usage, and more annoying to use. -- Steven
participants (23)
-
 Alex Hall
Alex Hall -
 Caleb Donovick
Caleb Donovick -
 Chris Angelico
Chris Angelico -
 Christopher Barker
Christopher Barker -
 Dan Sommers
Dan Sommers -
 David Mertz
David Mertz -
 Dominik Vilsmeier
Dominik Vilsmeier -
 Eric V. Smith
Eric V. Smith -
 Greg Ewing
Greg Ewing -
 Henk-Jaap Wagenaar
Henk-Jaap Wagenaar -
 James Lu
James Lu -
 MRAB
MRAB -
 Neil Girdhar
Neil Girdhar -
 Paul Sokolovsky
Paul Sokolovsky -
 Peter O'Connor
Peter O'Connor -
 Rhodri James
Rhodri James -
 Richard Damon
Richard Damon -
 Ricky Teachey
Ricky Teachey -
 Rob Cliffe
Rob Cliffe -
 Stephen J. Turnbull
Stephen J. Turnbull -
 Steven D'Aprano
Steven D'Aprano -
 Thierry Parmentelat
Thierry Parmentelat -
 Tiago Illipronti Girardi
Tiago Illipronti Girardi