dunder methods for encoding & prettiness aware formal & informal representations

This is really an idea for an idea. I'm not sure what the ideal dunder method names or APIs should be. Encoding awareness: The informal (`str`) representations of `inf` and `-inf` are "inf" and "-inf", and that seems appropriate as a known-safe value, but if we're writing the representation to a stream, and the stream has a Unicode encoding, then those might prefer to represent themselves as "∞" and "-∞". If there were a dunder method for informal representation to which the destination stream was passed, then the object could decide how to represent itself based on the properties of the stream. Prettiness awareness: It would be nice if an object could have control of how it is represented when pretty-printed. If there is any way for that to be done now, it is not at all evident from the pprint module documentation. It would be nice if there were some method that, if implemented for the object, would be used to allow the object to tell the pretty printer to treat it is a composite with starting text, component objects, and ending text. Additional thoughts & open questions: Perhaps there should only be stream awareness for informal representation and prettiness awareness for formal representation (separate concepts and APIs) or perhaps both ideas are applicable to both kinds of representation. Is it better for a stream-aware representation method to return the value to be written to the stream or to directly append its representation to that stream?

I think the idea you're looking for is an alternative for the pprint module that allows classes to have formatting hooks that get passed in some additional information (or perhaps a PrettyPrinter object) that can affect the formatting. This would seem to be an ideal thing to try to design and put on PyPI, *except* it would be more effective if there was a standard, rather than several competing such modules, with different APIs for the formatting hooks. So I encourage having a discussion (might as well be here) about the design of the new PrettyPrinter API. On Sun, Mar 15, 2020 at 4:08 AM Steve Jorgensen <stevej@stevej.name> wrote:
-- --Guido van Rossum (python.org/~guido) *Pronouns: he/him **(why is my pronoun here?)* <http://feministing.com/2015/02/03/how-using-they-as-a-singular-pronoun-can-c...>


Hi Steve (for clarity Jorgensen) Thank you for your good idea, and your enthusiasm. And I thank Guido, for suggesting a good contribution this list can make. Here's some comments on the state of the art. In addition to https://docs.python.org/3/library/pprint.html there's also https://docs.python.org/3/library/reprlib.html and https://docs.python.org/3/library/json.html I expect that these three modules have some overlap in purpose and design (but probably not in code). And if you're brave, there's also https://docs.python.org/3/library/pickle.html and https://github.com/psf/black Time to declare a special interest. I'm a long-time user and great fan of TeX / LaTeX. And some nice way of pretty-printing Python objects using TeX notation could be useful. And also related is Geoffrey French's Larch environment for editing Python, which has a pretty-printing component. http://www.britefury.com/larch_site/ with best wishes Jonathan
Jonathan Fine wrote:
I feel kind of silly for jumping right to the idea of prototyping rather than looking for prior art. :) It clearly makes more sense to choose an existing popular library as a candidate starting point for promotion into the stdlib rather than starting from scratch.

I would love a formalized, for example, __pretty__ hook. Many of our classes have __pretty__ and __json__ "custom" dunders defined and our PrettyPrinters / JSONEncoders have checks for them (though the __pretty__ API has proven difficult to stabilize). w/r/t to repurposing __str__, I (personally) think that's a nonstarter for all the reasons listed but also because you may want to, for example, insert line breaks in a long string in order to keep the output within some width requirement. IMO, str.__str__("x" * 1000) should never even consider doing that, but str.__pretty__("x" * 1000, pprinter_ref) might. Jim Edwards On Sun, Mar 15, 2020 at 11:44 AM Guido van Rossum <guido@python.org> wrote:

On 16 Mar 2020, at 20:59, James Edwards <jheiv@jheiv.com> wrote:
I would love a formalized, for example, __pretty__ hook. Many of our classes have __pretty__ and __json__ "custom" dunders defined and our PrettyPrinters / JSONEncoders have checks for them (though the __pretty__ API has proven difficult to stabilize).
For __json__ I can see that as long the way to encode the object as JSON is a "standard" then the dunder could have value. But __pretty__ is in the eye of the beholder. No one implementation is likely to satisfy enough use cases. Indeed I can easily see that inside one app __pretty__ might need to be implement a number of ways. Maybe for internationalisation and localisation reasons. For the pretty case I'd want to have code that took an object and returns the pretty version depending on the apps demands/config. Barry

Steve Jorgensen writes:
Allowing objects to decide implicitly how to represent themselves is usually a bad idea, and we shouldn't encourage it. Yes, it's *very* cool that you can do things like "π = math.pi", and with MacroPy you can even do things like substitute "λ" for "lambda". However, if ways are provided to do this automatically depending on encodings and other variable environment state, people *will* put them into public libraries, and clients of those libraries will have to compensate for that. And of course there's the potential for foot-shooting in private libraries. If an application wants to make such substitutions, I have no objection to that. But "explicit is better than implicit", and those substitutions should be made at the level of application I/O, not the class level IMO. (Yes, I know those "levels" are ill-defined, but that's still an appropriate informal principle, I think.)
In the stdlib pprint module, I see no way to do this. However, there is a private attribute _dispatch on PrettyPrinter which presumably could be augmented to "register" formatters for user-defined classes.
Is that really enough, though? For example, presumably you want namedtuples to have their "items" printed like dict items, not like tuples. I haven't thought carefully about it, but ISTM that this would require a class-specific dunder able to extract the field names from the class and pair them with the values in the tuple, not just a start, end, component_list tuple. ISTM that if you want to do that, you could provide a private attribute that acts as flag to the __format__ method of a class that switches from the normal formatting to a "pretty" representation, and derive a PrettyPrinter class that internally sets and resets the flag. Ugly, I guess, but Should Work[tm]. Of course I'm speaking from my own preferences and experience, so WDYT? Yet another Steve :-)
Hi Steve (for clarity Turnbull) You wrote: Allowing objects to decide implicitly how to represent themselves is usually a bad idea, and we shouldn't encourage it. I'm puzzled. I thought that when I define a class X, I'm generally encouraged to define a __repr__ method, that is used to decide how an instance of X represents itself. (That is, unless I already get a good __repr__ from inheritance.) However, you wrote "decide implicitly". Perhaps I'm missing something in the "implicitly". For clarity, I'm not making a statement about your examples. Just the principle which you claim underlies your examples. best regards Jonathan
Jonathan Fine writes:
However, you wrote "decide implicitly". Perhaps I'm missing something in the "implicitly".
That's shorthand for the long form I used later: "depending on variable environment state" (such as encodings, user id, or sunspot activity). Should have done it in the opposite order, sorry. Also, I'd like to note that "inf" and "-inf" (and "nan" for that matter) are not "informal". They are readable input, part of Python syntax: % python3.8 Python 3.8.2 (default, Feb 27 2020, 19:58:50)
Steve

On Sun, Mar 15, 2020 at 6:12 PM Stephen J. Turnbull < turnbull.stephen.fw@u.tsukuba.ac.jp> wrote:
which, of course is what __repr__ is supposed to do, though in this case it doesn't quite: In [11]: fp = float("inf") In [12]: eval(repr(fp)) --------------------------------------------------------------------------- NameError Traceback (most recent call last) <ipython-input-12-4f5249ac51be> in <module> ----> 1 eval(repr(fp)) <string> in <module> NameError: name 'inf' is not defined So they are not "readable input, part of Python syntax", but they are part of the float API. Anyway, Python now has two different ways to "turn this into a string":, __str__ and __repr__. I think the OP is suggesting a third, for "pretty version". But then maybe folks would want a fourth or fifth, or ..... maybe we should, instead, think about updating the __str__ for standard types. Is there any guarantee (or even string expectation) that the __str__ for an object won't change? I've always wondered why the standard str(some object) wasn't pretty to begin with. As for using unicode symbols for things like float("inf") -- that would be an inappropriate for the __repr__, but why not __str__ ? *reality check*: I imagine a LOT of code out there (doctests, who know what else) does in fact expect the str() of builtins not to change -- so this is probably dead in the water. -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython

Christopher Barker wrote: this is probably dead in the water. Regardless of whether we can improve/modify the __str__ for existing builtin objects, I think it is definitely worthwhile to clearly establish whether they are a part of the stable API in the first place. Users should be able to know if they can rely on the __str__ remaining the same across versions. My personal preference would be for the __repr__ to be stable (since it's already denoted as the "official" string representation, often can be used to replicate the object and/or uniquely identify it) and for the __str__ to be unstable/subject to change. As for whether the __str__ of any builtin object *should* be modified is another question entirely. I'm of the opinion that it should require sufficient justification: the benefit in readability/utility gained from the change by the majority of its users should outweigh the cost of potential breakage. If we've not provided any guarantee for the __str__ to remain the same across versions (which is true, AFAIK [1]), the fact that some users have chosen to rely on it doesn't seem like it should prevent any changes from being considered at all. It just means that the changes have to be adequately worthwhile and evaluated on a case-by-case basis. --- [1] - I have not extensively reviewed all of the documentation for all __str__ stability guarantees or lack thereof, but there are none in the places where I'd expect it would be present. In particular: https://docs.python.org/3.8/reference/datamodel.html#object.__str__ or https://docs.python.org/3.8/library/stdtypes.html#str. On Sun, Mar 15, 2020 at 9:30 PM Christopher Barker <pythonchb@gmail.com> wrote:

On Sun, Mar 15, 2020 at 06:27:43PM -0700, Christopher Barker wrote:
I think there is a strong expectation, even if there's no formal guarantee, that the str and repr of builtins and stdlib objects will be reasonably stable. If they change, it will break doctests and make a huge amount of documentation, blogposts, tutorials, books etc out of date. That's not to say that we can't do it, just that we shouldn't be too flippant about it. A few releases back (3.5? 3.4? I forget...) we changed the default float repr: python2.5 -c "print 2.0/3" 0.666666666667 python3.5 -c "print(2.0/3)" 0.6666666666666666 One advantage of that is that some values are displayed with the nearest human-readable exact value, instead the actual value. One disadvantage of that is that some values are displayed with the nearest human-readable exact value, instead of the actual value :-)
I've always wondered why the standard str(some object) wasn't pretty to begin with.
Define "pretty". The main reason I don't use the pprint module at the moment is that it formats things like lists into a single long, thin column which is *less* attractive than the unformatted list: py> pprint.pprint(list(range(200))) [0, 1, 2, 3, ... 198, 199] I've inserted the ellipsis for brevity, the real output is 200 rows tall. When it comes to floats, depending on what I'm doing, I may consider any of these to be "pretty": * the minimum number of digits which are sufficient to round trip; * the mathematically exact value, which could take a lot of digits; * some short number of digits, say, 5, that is "close enough". -- Steven

- CPython has __str__ and __repr__, IPython has obj._repr_fmt_(), MarkupSafe has obj.__html__(), https://github.com/tommikaikkonen/prettyprinter has @register_pretty Neither __str__ nor __repr__ have any round-trip guarantee/expectation (they're not suitable for serialization/deserialization // marshal/unmarshal / dump/load). Monkeypatching the __str__ or __repr__ of a builtin is generally undesirable because that's global and not thread safe. Could you use the locale module for this number formatting regional preference (inf as unicode inf)? https://docs.python.org/3/library/locale.html LC_INFINITY=unicode https://docs.python.org/3/library/locale.html#locale.LC_NUMERIC
... From "[Python-ideas] Draft PEP on string interpolation" (=> f-strings) https://groups.google.com/d/msg/python-ideas/6tfm3e2UtDU/euvlY6uWAwAJ : ```quote * Does it always just read LC_ALL='utf8' (or where do I specify that global/thread/frame-local?) [...] Jinja2 uses MarkupSafe, with a class named Markup: class Markup(): def __html__() def __html_format__() IPython can display objects with _repr_fmt_() callables, which TBH I prefer because it's not name mangled and so more easily testable. [3,4] Existing IPython rich display methods [5,6,7,8] _mime_map = dict( _repr_png_="image/png", _repr_jpeg_="image/jpeg", _repr_svg_="image/svg+xml", _repr_html_="text/html", _repr_json_="application/json", _repr_javascript_="application/javascript", ) # _repr_latex_ = "text/latex" # _repr_retina_ = "image/png" Suggested IPython methods - [ ] _repr_shell_ - [ ] single_quote_shell_escape - [ ] double_quote_shell_escape - [ ] _repr_sql_ (*NOTE: SQL variants, otherworldly-escaping dependency / newb errors) [1] https://pypi.python.org/pypi/MarkupSafe [2] https://github.com/mitsuhiko/markupsafe [3] https://ipython.org/ipython-doc/dev/config/integrating.html [4] https://ipython.org/ipython-doc/dev/config/integrating.html#rich-display [5] https://github.com/ipython/ipython/blob/master/IPython/utils/capture.py [6] https://github.com/ipython/ipython/blob/master/IPython/utils/tests/test_capt... [7] https://github.com/ipython/ipython/blob/master/IPython/core/display.py [8] https://github.com/ipython/ipython/blob/master/IPython/core/tests/test_displ... * IPython: _repr_fmt_() * MarkupSafe: __html__() ``` On Sun, Mar 15, 2020 at 11:00 PM Steven D'Aprano <steve@pearwood.info> wrote:
On Sun, Mar 15, 2020 at 11:37:53PM -0400, Wes Turner wrote:
Monkeypatching the __str__ or __repr__ of a builtin is generally undesirable because that's global and not thread safe.
Monkeypatching the __str__ or __repr__ of a builtin is generally impossible. py> int.__repr__ = lambda self: 'number' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: can't set attributes of built-in/extension type 'int' -- Steven
Exactly. Python 3 uses a Unicode model for strings. And that means anywhere you have strings, you have Unicode. And you need to deal with encoding issues on I/O. I'm not sure how logfiles are any different than any other file I/O. Related note: logfiles are likely to dump arbitrary messages attached to Exceptions as well. So you really need to be able to deal with arbitrary Unicode anyway. (note: in 2.7, passing arbitrary Unicode through the Exception machinery leads to messy errors, we really don't want that) That all being said, there is something to be said for keeping all __str__ and __repr__ on builtins to be a lowest common denominator subset (i.e. ascii) -- your logging system and whatever should handle any Unicode without raising, but it may use a "ignore" or "replace" error handler, and it would be pretty ugly to strip out parts of standard representations of builtins. -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
Christopher Barker writes:
So [inf and -inf] are not "readable input, part of Python syntax", but they are part of the float API.
Thank you for the correction. Aside: help(float) doesn't mention these aspects of the API. I guess that since 1.0 / 0.0 doesn't return float("inf") and 0.0 / 0.0 doesn't return a float("nan"), that's too far into the weeds for help. WDOT?
Is there any guarantee (or even string expectation) that the __str__ for an object won't change?
Nice typo! Yes, there's a strong expectation. doctests, as you pointed out, are a good example. Python may be good for developers who are moving fast and breaking things, but that's partly because (despite frequent complaints to the contrary) we don't move fast and break things most of the time.
As for using unicode symbols for things like float("inf") -- that would be an inappropriate for the __repr__, but why not __str__ ?
Because they're not always available, even in 2020. Also, ∞ is ambiguous; it's used for the ordinal number infinity (IIRC, more precisely denoted ω), the cardinal number infinity, the positive limit of the real line, the antipode of 0 in the complex (Riemannian) sphere, and probably other things. But
complex("inf") (inf+0j)
Oof. ;-)
complex("inf") * 1j (nan+infj)
Yikes! This was fun! :-) Steve

On Mar 15, 2020, at 22:37, Stephen J. Turnbull <turnbull.stephen.fw@u.tsukuba.ac.jp> wrote:
Well, there are an infinite number of ever larger infinite ordinals, ω or ω_0 being the first one, and likewise an infinite number of infinite cardinal, aleph_0 being the first one, and people rarely use the ∞ symbol for any of them. But people definitely do use the ∞ symbol for the projective infinity (the single point added to the real line to create the projective circle), and its complex equivalent (the single point added to the complex plan to give you the Riemann sphere). And IEEE (and therefore Python) infinity definitely doesn’t mean that; it explicitly has separate positive and negative infinities, modeling the affine rather than projective extension of the reals (the positive and negative limits of the real line). There are a few different obvious ways you could build an IEEE-float-style complex out of IEEE floats, but the one that C99 and C++ both use is probably the simplest: just model then as the Cartesian product of IEEE float with itself, applying the usual arithmetic rules over IEEE float. And that means these odd things make sense:
What else would you expect? The projective real line (circle) multiplied by itself gives you the projective complex plane (sphere) with a single infinity opposite 0, but the affine real line multiplied by itself gives you an infinite number of infinities. You can look at these as the limits of every line in complex space, or as the “circle” in polar coordinates with infinite distance at every angle, or as the “square” in cartesian coordinates made up of positive and negative real infinity with every imaginary number and positive and negative imaginary infinity with every real number. When you’re dealing with a discrete approximation like IEEE floats, these three are all different, but the last one falls out naturally from the definition, so that’s what Python does—and C, C++, and lots of other languages. So, inf+0j is one real-positive-infinite number, but inf+1j is another, and there’s a whole slew of additional ones (one for each float value for the imaginary component).
complex("inf") * 1j (nan+infj)
(a+b)(c+d) = ac + ad + bc + bd (a+bj)(c+dj) = (ac - bd) + (ad + bc)j (inf+0j)(0+1j) = (inf*0 - 0*1) + (inf*1 + 0*0)j And inf*0 is nan, while inf*1 is inf, right? Here’s the fun bit: >>> cmath.isinf(_) True Again, Python, C, and lots of other languages agree here, and it makes sense once you think about it. We have a number that’s either indeterminate or multivalued or unknown on one axis, but it’s infinite on the other axis, so whatever value(s) it may represent, they all must be infinite. If you look at the values you get from other complex arithmetic and the other functions in the cmath library, they all should make sense according to the same model, and should agree with C99. (I haven’t actually tested that…)
Andrew Barnert writes:
s/people/mathematicians/ and I'd agree with you. But I did write "people".
FVO "simple" = "simplistic". :-)
And that means these odd things make sense:
FVO of "sense" = "derived from an arbitrary model (as long as we're consistent)". (This time I'm not trolling.)
I don't "expect" anything when there are several competing interpretations. I would *like* it to be 'complex("inf")' FVO inf = projective complex plane infinity. My reasoning is the available *mathematical* values we model should make sense as expressing the set of possible limits in polar coordinates as well as in Cartesian coordinates (and as the limits of arbitrary lines). But these are in some sense distinct, with a couple of exceptions. So I would prefer my calculations to tell me "you're out of bounds" rather than give me a result that looks precise but actually doesn't tell me much about the limiting process. E.g., the mathematical limit in R^2 of (ax, bx) for all a, b > 0 is (inf, inf) -- thank you very much, I guess. By contrast, +inf and -inf for R tells me a lot.
Pragmatically, that is what I said I like, except I like it in maximum generality. ;-) Steve
On Mar 16, 2020, at 02:54, Stephen J. Turnbull <turnbull.stephen.fw@u.tsukuba.ac.jp> wrote:
But people rarely talk about infinite ordinals or cardinals. Anyone who’s talking about, e.g., whether there’s a set larger than the naturals but smaller than the reals isn’t calling either one of those sets’ cardinalities ∞.
What does FVO mean? At any rate, there’s nothing wrong with simplistic. Our usual addition on natural numbers is simplistic, and there are all kinds of other sort-of-addition-like things you could define on top of successor instead of it that are less simplistic, but none of them are nearly as useful, natural, or intuitive.
But it’s not an arbitrary model (except in the sense that every number system like Z is an arbitrary model), it’s a model that falls out of the natural composition of “build C from R” and “build R-bar from R and then build IEEE from R-bar”, in either order. And it’s one that preserves all the properties you’d hope—most importantly, continuation. The fact that 2+3=5, etc., when you use complex addition instead of real addition—is the reason we call complex addition “addition” in the first place. And C-bar built in this way continues R-bar in the same way C continues R. And the C-style approximation of C-bar with IEEE float approximately continues IEEE float in the same way (albeit sadly not always with the same bounds of approximation). Which is why we can call C/Python/etc. complex addition “addition”: complex.__add__(complex(2.0), complex(3.0)) == 2.0+3.0 (in this case exactly so, but in general you need isclose and it’s not always easy to calculate the cutoff…).
If you’re suggesting that our reals should be projectively extended and then our complexes should also be projectively extended, that would make sense. But then our reals wouldn’t be modeled by IEEE floats. If you’re suggesting that our complexes should be projectively extended even though our reals are affinely extended, then you’re giving up the continuation property; complex is no longer an extension of real.
But the infinite values we’re trying to model aren’t distinct between the two coordinate systems. The finite approximations are very different, on the other hand—but that’s already true even with finite numbers. The density of covered values over any part of the complex plane is different based on whether you approximate with cartesian IEEE floats or polar IEEE floats, so of course the same is true for the infinite parts of the plane as well. So what?
Consider electrical circuits (which is presumably what the people designing this system in the first place were considering, since IEEE math is designed for EE). All observable outputs have finite real values at all times. But intermediate values in the circuit are affinely-extended complex values. (You can argue about whether those values “really exist” or are “just a way of talking about real values that change over time” or whatever; I suspect most electrical engineers don’t care, they just want to be able to use them.) You can design a circuit where it some value is inf with phase pi/2 the output will be real 5V, if it’s inf with phase pi the output will be 0V, and if it’s in between the output is in between. If you insist on calculating that in the projectively extended complexes instead, you’ll just get NaN at all inputs; if you calculate it with the affinely extended complexes, even using the approximation made from the Cartesian product of IEEE float with itself, you get a well-bounded approximation of the curve from 5V to 0V that you were looking for. If that’s not meaningful, then none of our approximate number systems are meaningful. I’m not saying there are no advantages to the projectively extended complex numbers. But there are also advantages to the projectively extended reals over the affinely extended reals, and yet, we chose the advantages of the latter over those of the former. (Well, we just went with what a bunch of electrical engineers designed in the 1970s, but…) For complex, it’s mostly the same tradeoff again—and it’s not an independent tradeoff; making it inconsistently adds complexity while throwing away half the benefits—which is why almost every language has made the same decision as Python. It’s not arbitrary, it’s the most sensible choice.
Why? If you only care about whether something is infinite, rather than which infinity, you can use isinf. If you want to insist that nobody else can ever care about which infinity, even when it’s useful to them and we could have calculated it for them, just because you don’t have a use for it, and that we should either give up IEEE float semantics or have complex semantics that don’t match our float semantics in fundamental ways and that are derived in a more complicated way with unmotivated special cases instead of the natural way that falls out of any of the usual constructions of C in mathematics, that’s not really “maximum generality” you’re asking for, but the opposite.

This makes on my count 6 messages on arcane mathematical topics that have nothing to do with the original proposition, which was to do with prettyprinting. Don't get me wrong - I enjoy such discussions as much as anyone, considering myself a mathematician of sorts. But it must be frustrating for the OP, looking for some genuine feedback, to see the discussion wander off-track. (And time-wasting for anyone with a genuine interest in the OP's suggestion who, at some future time, reads through the thread.) And this is far from the first time I have seen this sort of thing happen. May I humbly suggest that contributors to a thread might make a little more effort to discipline themselves to reply to the OP rather than waxing lyrical on some unrelated topic? (And, very tentatively, suggest that there might even be a role for the Moderator here?). I intend absolutely no offence to anyone involved. Rob Cliffe On 16/03/2020 17:33, Andrew Barnert via Python-ideas wrote:


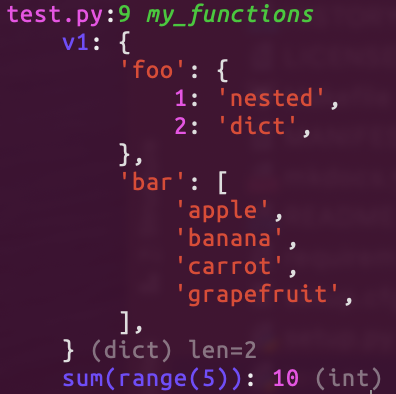
I thought about this a great deal when building the devtools package: https://pypi.org/project/devtools/ It prints common types in a pretty way (with the file, line number and value or expression that was printed): [image: image.png] But it also looks for a "__pretty__" method on objects, and if found uses that to display the object. I haven't yet documented that properly, but it's already implemented in pydantic (which I also maintain) so pydantic models can be displayed in a prettier way: [image: image.png] The challenge here is that "__pretty__" can't just return a string as that leaves all the formatting up to that method, rather than the printing/display library. So devtools expects "__pretty__" to yield objects in name, value pairs (or just values for list like objects), devtools then takes care of recursively displaying the values next to each name. Long term if an approach like this was more widely adopted, this approach should work well for things like IDEs which may want to display this data within a custom UI. I'll try and document the "__pretty__" generate when I get a chance, but if anyone has more questions, feel free to create an issue at https://github.com/samuelcolvin/python-devtools or ask here. Samuel -- Samuel Colvin
On Thu, Mar 19, 2020 at 11:38:28PM +0000, Samuel Colvin wrote:
But it also looks for a "__pretty__" method on objects, and if found uses that to display the object.
Are you aware that dunder names are reserved for Python's use?
Perhaps I don't understand the context here, but that doesn't sound like a general approach that would work very well. How would you "prettify" a scalar object which isn't a sequence and doesn't have name/value pairs? For that matter, if your library is expecting a stream of either (name, value) pairs, or just values, how does it distinguish genuine (name, value) pairs from values that look like (name, value) pairs but actually represent something else? I'm just not seeing how a display library can possibly know the right way to prettify an arbitrary object if you don't ask the object itself. As far as I can tell, pprint itself works because it only knows about a handful of special objects, it doesn't try to do anything too special with arbitrary objects it knows nothing about. -- Steven
On Fri, Mar 20, 2020 at 03:01:16PM +1100, Chris Angelico wrote:
Yes, really. https://docs.python.org/3/reference/lexical_analysis.html#reserved-classes-o...
Somebody better tell SQLAlchemy that they're breaking rules, then.
Lots of people break the rules all the time. Doesn't mean they should. -- Steven

On Fri, Mar 20, 2020 at 3:28 PM Steven D'Aprano <steve@pearwood.info> wrote:
"Subject to breakage without warning" technically applies to a *lot* of things that aren't guaranteed. Using __pretty__ as a protocol is no different from any of those. IMO it's not exactly a serious crime, even if technically it's something that could be broken. Also, since this is a proposal on python-ideas, it'd have as much blessing as __copy__, which to my knowledge has no meaning in the language itself, only in the standard library; it'd be the same with __pretty__, defined by the pprint module. ChrisA
On Fri, Mar 20, 2020 at 03:37:08PM +1100, Chris Angelico wrote:
"Subject to breakage without warning" technically applies to a *lot* of things that aren't guaranteed.
Yes?
Using __pretty__ as a protocol is no different from any of those.
If we should choose to use a `__pretty__` dunder, we have no obligation to follow Samuel's API, or make it a future-import, or give him any warning, or make any allowances for the fact that he is already using it. We can just break his code. Samuel may not have known that, but hopefully he will now.
IMO it's not exactly a serious crime,
Isn't it? Damn, I've already reported him to the federal police, the SWAT team will be arriving in 5, 4, 3, 2, ... *wink* I didn't describe it as a crime at all, I just asked if he knew he was using a reserved name.
I don't think that's a distinction that means anything. Whether the standard library or the interpreter itself breaks your code, it's still broken. -- Steven
Steven D'Aprano wrote:
Yes, really.
https://docs.python.org/3/reference/lexical_analysis.html#reserved-classes-o... I remembered the existence of this rule and tried to locate it recently (prior to this discussion), but was unable to because it doesn't explicitly mention "dunder". IMO, it would make that section much easier to find if it were to say either of: 1) System-defined names, also known as "dunder" names. 2) System-defined names, informally known as "dunder" names. 3) System-defined "dunder" names. Instead of the current: System-defined names. (or any mention of "dunder" for that matter) It would be much easier to locate. Realistically speaking, I can't imagine that the majority of Python users and library maintainers would read through the entire "Lexical Analysis" page of the docs if they're not specifically interested in parsing or something similar. :-) Regardless though, thanks for providing the link. I'll try to remember its location for future reference. On Fri, Mar 20, 2020 at 12:29 AM Steven D'Aprano <steve@pearwood.info> wrote:
On Fri, Mar 20, 2020 at 8:52 PM Kyle Stanley <aeros167@gmail.com> wrote:
The word "dunder" was coined (relatively) recently. It was not in common use when those docs were written. Another common nickname is "magic methods". So that explains why the word "dunder" isn't in those docs. And those docs are pretty "formal" / "technical" anyway, not designed for the casual user to read. But yes, it would be good to add a bit of that text to make it more findable. I'd suggest you make a PR on the docs. -CHB Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
Chistopher Barker wrote:
I'd suggest you make a PR on the docs.
Yeah I was planning on either doing that, or opening it as a "newcomer friendly"/"easy" issue on bugs.python.org. IMO, it could make for a decent first PR. On Sun, Mar 22, 2020 at 1:28 PM Christopher Barker <pythonchb@gmail.com> wrote:
I ended up opening an issue for it at https://bugs.python.org/issue40045. <http://bugs.python.org> On Sun, Mar 22, 2020 at 8:33 PM Kyle Stanley <aeros167@gmail.com> wrote:

On 20/03/20 4:55 pm, Steven D'Aprano wrote:
Are you aware that dunder names are reserved for Python's use?
Nobody is going to put you in jail if you use an unofficial dunder name. You just run the risk that your use of it will conflict with some official use in the future. -- Greg
On Fri, Mar 20, 2020 at 06:30:24PM +1300, Greg Ewing wrote:
You're the second person mentioning crime or law. What did I say to give people the impression that I think that using a dunder is a criminal offence? I didn't say that it was illegal or breaking the law, or a felony or even a misdemeaner. I didn't even make a value judgement about whether it was a good thing or a bad thing to use dunder names. I said that dunders are reserved. Not everyone knows this. What should I have said that won't be misinterpreted as an accusation of criminality? -- Steven
Hi Steven,
Are you aware that dunder names are reserved for Python's use?
I wasn't aware it was explicitly discouraged, thanks for the link. It seems to me that "__pretty__" (however it's implemented) seems a very sensible name for a method used when pretty printing objects. If it's one day implemented officially I think the approach I took is a good start, if it's not, then what I've done won't conflict with anything. :-) I'm sure I've broken lots of rules by just taking a punt at an implementation rather than enduring weeks of argument-for-arguments-sake on this mailing list, but the more I read it, the happier I am about that decision.
Perhaps I don't understand the context here, but that doesn't sound like a general approach that would work very well.
I think it does work well; though I agree I didn't explain it very well last night (indeed my rushed explanation was outright wrong in some regards). Let me explain more how my implementation of "__pretty__" works, taking an example form devtool's tests <https://github.com/samuelcolvin/python-devtools/blob/7482e87dcb2dab47884a790...> : class CustomCls: def __pretty__(self, fmt, **kwargs): yield 'Thing(' yield 1 for i in range(3): yield fmt(list(range(i))) yield ',' yield 0 yield -1 yield ')' debug(CustomCls())
__pretty__ takes two keyword arguments: fmt - a function, and skip_exc - an exception which can be raised to stop pretty printing. It then yields either: - A string, in which case that string is just displayed - An int, which tells devtools to move to a new line and maybe change the indent/context. 1 means increase indent, -1 means reduce the indent and 0 means just new line with no indent change - the value returned from fmt() which causes devtools to take care of displaying the argument passed to fmt(), including recursive display of sub-objects That's it. It's very simple but it allows effectively arbitrarily complex objects to be displayed. Especially since an object that wants to take care of all display of itself can just do so and return a string. All that fmt() actually does is mark an object as requiring devtools to take care of its display, it is implemented as a function argument to __pretty__ to avoid libraries that implement __pretty__ from needing devtools as a requirement. I hope that makes more sense and acts as a starting point for a more productive conversation about an standard approach to pretty printing. Samuel
It’s a bit ironic: if you have a nifty idea for Python, you are often told to try it out on your own. And if you expect it to maybe make its way into Python, you’d want to use a dunder... But then, dunders are reserved for the standard library. It’s a pickle. And it’s not like there’s no precedent: What about __version__ ? Which, by be the way, maybe it’s time to make official? https://www.python.org/dev/peps/pep-0396/ -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
On Mar 20, 2020, at 19:32, Christopher Barker <pythonchb@gmail.com> wrote:
It’s a bit ironic: if you have a nifty idea for Python, you are often told to try it out on your own. And if you expect it to maybe make its way into Python, you’d want to use a dunder...
But then, dunders are reserved for the standard library. It’s a pickle.
When third-party libs end up in the stdlib, they usually change. Sometimes there are just small bikeshedding changes, like simplejson/json or statistics/stats, sometimes the whole thing gets redesigned, like attr.s/dataclasses or flufl.enum/enum. If you’re designing something that you hope will one day get standardized, maybe it’s not such a bad thing that you’re forced to think of how the migration is going to go for your early adopter users, and make them think about it too. And if the stdlib version might change the semantics of the protocol in any way, which is more disruptive to users: the stdlib json module doesn’t respect your _tojson methods because it wants __json__, or the stdlib json module sort of respects your __json__ methods but gets it “wrong” in some important cases because it uses the same name but with changed semantics? And then, if you used _tojson, you can add the stdlib’s __json__ and the same module works as the backport of the 3.10 stdlib to older versions and as the more-featureful third-party module some people still need.
Samuel Colvin writes:
That depends on whether somebody decides that "pretty" is a good name for a different function (such as going through all the strings in the object and making sure they are properly capitalized and use the same sentence-ending convention, or a different signature -- see below). Single leading underscore is reserved for class-private use, so you could more safely use "sunders" (_pretty_) or "splunders" (_pretty__). I'll note (as a mail geek) that use of a private method suffers a similar issue to that of the "X-" convention for message header field names: once standardized, you can't get rid of the old name. Nowadays, the recommendation in message header standardization community (*especially* for names that you are proposing for standardization) is to just go ahead and use an unprefixed name for private protocols. I don't know how close this analogy of the field name problem to the protocol implementation name problem is, but it's some evidence for your practice.
But that's precisely the issue with __pretty__: it allows objects to decide how to format themselves, when the application wants control. The way I think of pprint (FWIW, YMMV) is as a debug utility. If I were going to extend it, I would probably use a different name such as __debug_format__ for the dunder, and it would take the usual 'self' argument, plus hint arguments 'indent', 'width', 'height' describing the "subwindow" the caller wants to give it. The return value would be a (possibly nested) list of strings, each including the indent the object proposes to use. Then the simplest implementation of the pretty() function would simply flatten the nested list, join the result, and output it, while a very opinionated pretty() might strip all the indentation, apply its own opinion of the appropriate indentation, then truncate the indented line to its opinion of the appropriate length. Steve

On Sat, 21 Mar 2020 at 06:42, Steven D'Aprano <steve@pearwood.info> wrote:
I agree with Stephen (ph) - debugging. For end user display, I'd typically want to write a custom display function. For debugging, I want a readable display with as little effort as possible (debugging is hard enough without having to write display routines or put up with unreadable data dumps). Very much personal preference, though. Paul
Steven D'Aprano writes:
Oh, that's interesting. I mostly think of pretty-printing as a display utility aimed at end users.
Well, I'm mostly the only end-user of my code, so there's definitely a bias here. I'd be interested to see the "display utility" point of view expanded. Steve
I'd be interested to see the "display utility" point of view expanded.
For me there are two use cases: I use devtool's debug() command instead of print() ALL THE TIME when debugging, so does the rest of my office and others who I've demonstrated its merits to. I use this sitecustomize trick <https://github.com/samuelcolvin/python-devtools#usage-without-import> to avoid having to import debug(). Using debug() over print() or pprint() for debugging has the following advantages, some more obvious than others: - It's much easier to read, particularly for big/complex/nested objects. Coloured output helps a lot here, so does better support for non std-lib objects like pandas dataframes, django querysets, multidict dictionaries, pydantic models etc. - I don't need to constantly write print('user.profile.age:', repr(user.profile.bio)) - just debug(user.profile.bio) takes care of showing the variable or expression I want to display as well as its value - debug() uses repr() which is mostly more useful when debugging than str() - debug() uses a slightly different logic to display nested objects compared to pprint(), you can think of it as looking much more like json.dumps(..., indent=4), maybe it's just that I'm the JSON generation, but I find it much easier to read than pprint(...) - having the file and line number saves me having to try and dig around to find where the print state is - this is particularly useful when debugging code in installed packages or in large code cases - debug() does a decent (if not perfect) job of displaying objects (e.g. strings) how I would want them in code so it can be super quick to add a test based on the value or copy it to code elsewhere - the sitecustomize trick means flake8 fails if I forget to remove debug() statements, similarly it means tests fail if I forget to remove them The second case is displaying objects to developers-as-users. For example aio-libs/aiohttp-devtools uses devtools to print request bodies and headers to aid debugging of unexpected http response codes (as far as I remember). Here I'm using devtools.pformat, it's convenient to use that method rather than have to write lots of display logic in each package. *Side Note:* I'm aware I'm talking about the devtools package (which I maintain) a lot, I'm waiting for the moment someone get's cross that I'm promoting my package. Sorry if it seems like that, but that's not what I'm trying to do, devtools isn't perfect and I wish it didn't exist. I think the python standard library should have a debug print command that knows how to print common object types but also respects a dunder method on objects which want to customise how they're displayed when debugging. The name of the debug command and the name of the dunder method don't bother me much. I'm just using devtools as an example of what I think should be in the standard library. Samuel
Samuel Colvin writes:
I'd be interested to see the "display utility" point of view expanded.
For me there are two use cases:
These both seem to be what I would consider "debugging" use cases, ie, displaying whole objects to users who have some understanding of the internals. My understanding of "display utility" was for end users. Perhaps Steven (d'Aprano) meant your "developers as users" case, but that's not what I understood. Also, am I to understand that simply adding "__pretty__" with a single "debug" function gets all the benefits you describe, or do you need additional support from devtool? Steve
On Fri, Mar 20, 2020 at 8:24 PM Stephen J. Turnbull < turnbull.stephen.fw@u.tsukuba.ac.jp> wrote:
Single leading underscore is reserved for class-private use, so you could more safely use "sunders" (_pretty_) or "splunders" (_pretty__).
Though this use case really isn't "class-private" -- it's more "package private", but I don't think it's even that. The idea is to allow anyone to make a class that plugs into this system -- so very much like a dunder, but without the blessing of the standard library. Maybe a semi-convention of "trunders" would make sense? ___pretty___ -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
Taking Rob Cliffe's statement in good part, changing the subject (belatedly, sorry!) Andrew Barnert writes:
What does FVO mean?
Sorry. "For values of"
At any rate, there’s nothing wrong with simplistic.
My usage of simplistic is to simple as complicated is to complex. The distinction relates to the cost of design vs cost to users tradeoff. "Simplistic" and "complicated" impose complexity on users in ways that could (and implicitly should) be avoided by more effort on design. So:
Our usual addition on natural numbers is simplistic,
I don't understand why you use "simplistic" here, rather than "simple".
You mean like hardware unsigned modular integer arithmetic, and two's complement addition for signed integers? But they are not "simple" for humans to use, though I would call them "simplistic" in the sense that "these are simple to implement, and people will just have to deal".
And it’s one that preserves all the properties you’d hope—most importantly, continuation.
Yes, I agree. My question is whether users would be better off with a different simplicity. After all, the electrical engineers don't get embedded reals for free, they have to test for .imag == 0 and then use .real:
But they are. (inf + 1j) and (inf + 2j) cannot be distinguished in polar coordinates, while the infinities with arg = 1/2 and arg = 1/4 cannot be distinguished in Cartesian coordinates. You need a category with a concept of limiting process to make those distinctions with the "wrong" coordinate system; extended arithmetic is not enough. Maybe the "endpoints of lines" representation of infinity in the affine complex plane gets all of the infinities?
So what?
Always a good question. :-) "Readability counts". For *my* purposes, complex numbers are just numbers visualized in projective polar coordinates, and nan + 1j *is* just nan, inf + 1j *is* just inf. We *could* have a language where the calculations of complex arithmetic are done with Cartesian pairs of IEEE reals, the strs are 'inf' and 'nan', and there's an API for extracting further information from the object if you care. Instead we have a str that gives me the WTFs when I visualize them, which I do automatically. But then, I am a (wannabe) mathematician, and quite possibly only the other 100 people who read the books I do feel the same way.
If you want to insist that nobody else can ever care
Please, sir! I am a faithful Economist, my creed is "De gustibus non est disputandum." I don't have a use case for projective arithmetic, just a matter of taste in float.__str__. I was unaware of the pragmatics of electrical engineering, and am happy to let their calculations "just work". If they are used to seeing "inf + 1j" and it is useful to them, that's more important than my occasional WTF. Steve

{kind=link}
{kind=link}
David Mertz writes:
As a mathematician who is a people (I am large, I contain multitudes), I can tell you you have the inclusion backwards for the argument you make. Damn, I'm going to miss you all during PyCon, can't make it this year. (And probably shouldn't even if I had confirmed funding, but that's another story.)
On Mon, Mar 16, 2020, 3:41 AM Andrew Barnert via Python-ideas < python-ideas@python.org> wrote:
It's convenient to be compatible with cmath. CAS systems vary in regards to whether it's inappropriate and over-reductionistic to just throw away a scalar magnitude 'times' an infinity symbol. These approach ±inf at different rates: -2/n 1/n 2/n It's not a pedantic differentiation; but my guess is that such use cases generally call for CAS and not cmath or python anyway. ... Again, could the locale module be extended to handle customizable formatting for inf?

Might be helpful to look at https://github.com/tommikaikkonen/prettyprinter and https://github.com/wolever/pprintpp
Alex Hall wrote:
Might be helpful to look at https://github.com/tommikaikkonen/prettyprinter and https://github.com/wolever/pprintpp
Right! Thx. :)
I think the idea you're looking for is an alternative for the pprint module that allows classes to have formatting hooks that get passed in some additional information (or perhaps a PrettyPrinter object) that can affect the formatting. This would seem to be an ideal thing to try to design and put on PyPI, *except* it would be more effective if there was a standard, rather than several competing such modules, with different APIs for the formatting hooks. So I encourage having a discussion (might as well be here) about the design of the new PrettyPrinter API. On Sun, Mar 15, 2020 at 4:08 AM Steve Jorgensen <stevej@stevej.name> wrote:
-- --Guido van Rossum (python.org/~guido) *Pronouns: he/him **(why is my pronoun here?)* <http://feministing.com/2015/02/03/how-using-they-as-a-singular-pronoun-can-c...>
Hi Steve (for clarity Jorgensen) Thank you for your good idea, and your enthusiasm. And I thank Guido, for suggesting a good contribution this list can make. Here's some comments on the state of the art. In addition to https://docs.python.org/3/library/pprint.html there's also https://docs.python.org/3/library/reprlib.html and https://docs.python.org/3/library/json.html I expect that these three modules have some overlap in purpose and design (but probably not in code). And if you're brave, there's also https://docs.python.org/3/library/pickle.html and https://github.com/psf/black Time to declare a special interest. I'm a long-time user and great fan of TeX / LaTeX. And some nice way of pretty-printing Python objects using TeX notation could be useful. And also related is Geoffrey French's Larch environment for editing Python, which has a pretty-printing component. http://www.britefury.com/larch_site/ with best wishes Jonathan
Jonathan Fine wrote:
I feel kind of silly for jumping right to the idea of prototyping rather than looking for prior art. :) It clearly makes more sense to choose an existing popular library as a candidate starting point for promotion into the stdlib rather than starting from scratch.
I would love a formalized, for example, __pretty__ hook. Many of our classes have __pretty__ and __json__ "custom" dunders defined and our PrettyPrinters / JSONEncoders have checks for them (though the __pretty__ API has proven difficult to stabilize). w/r/t to repurposing __str__, I (personally) think that's a nonstarter for all the reasons listed but also because you may want to, for example, insert line breaks in a long string in order to keep the output within some width requirement. IMO, str.__str__("x" * 1000) should never even consider doing that, but str.__pretty__("x" * 1000, pprinter_ref) might. Jim Edwards On Sun, Mar 15, 2020 at 11:44 AM Guido van Rossum <guido@python.org> wrote:
On 16 Mar 2020, at 20:59, James Edwards <jheiv@jheiv.com> wrote:
I would love a formalized, for example, __pretty__ hook. Many of our classes have __pretty__ and __json__ "custom" dunders defined and our PrettyPrinters / JSONEncoders have checks for them (though the __pretty__ API has proven difficult to stabilize).
For __json__ I can see that as long the way to encode the object as JSON is a "standard" then the dunder could have value. But __pretty__ is in the eye of the beholder. No one implementation is likely to satisfy enough use cases. Indeed I can easily see that inside one app __pretty__ might need to be implement a number of ways. Maybe for internationalisation and localisation reasons. For the pretty case I'd want to have code that took an object and returns the pretty version depending on the apps demands/config. Barry
Steve Jorgensen writes:
Allowing objects to decide implicitly how to represent themselves is usually a bad idea, and we shouldn't encourage it. Yes, it's *very* cool that you can do things like "π = math.pi", and with MacroPy you can even do things like substitute "λ" for "lambda". However, if ways are provided to do this automatically depending on encodings and other variable environment state, people *will* put them into public libraries, and clients of those libraries will have to compensate for that. And of course there's the potential for foot-shooting in private libraries. If an application wants to make such substitutions, I have no objection to that. But "explicit is better than implicit", and those substitutions should be made at the level of application I/O, not the class level IMO. (Yes, I know those "levels" are ill-defined, but that's still an appropriate informal principle, I think.)
In the stdlib pprint module, I see no way to do this. However, there is a private attribute _dispatch on PrettyPrinter which presumably could be augmented to "register" formatters for user-defined classes.
Is that really enough, though? For example, presumably you want namedtuples to have their "items" printed like dict items, not like tuples. I haven't thought carefully about it, but ISTM that this would require a class-specific dunder able to extract the field names from the class and pair them with the values in the tuple, not just a start, end, component_list tuple. ISTM that if you want to do that, you could provide a private attribute that acts as flag to the __format__ method of a class that switches from the normal formatting to a "pretty" representation, and derive a PrettyPrinter class that internally sets and resets the flag. Ugly, I guess, but Should Work[tm]. Of course I'm speaking from my own preferences and experience, so WDYT? Yet another Steve :-)
Hi Steve (for clarity Turnbull) You wrote: Allowing objects to decide implicitly how to represent themselves is usually a bad idea, and we shouldn't encourage it. I'm puzzled. I thought that when I define a class X, I'm generally encouraged to define a __repr__ method, that is used to decide how an instance of X represents itself. (That is, unless I already get a good __repr__ from inheritance.) However, you wrote "decide implicitly". Perhaps I'm missing something in the "implicitly". For clarity, I'm not making a statement about your examples. Just the principle which you claim underlies your examples. best regards Jonathan
Jonathan Fine writes:
However, you wrote "decide implicitly". Perhaps I'm missing something in the "implicitly".
That's shorthand for the long form I used later: "depending on variable environment state" (such as encodings, user id, or sunspot activity). Should have done it in the opposite order, sorry. Also, I'd like to note that "inf" and "-inf" (and "nan" for that matter) are not "informal". They are readable input, part of Python syntax: % python3.8 Python 3.8.2 (default, Feb 27 2020, 19:58:50)
Steve
On Sun, Mar 15, 2020 at 6:12 PM Stephen J. Turnbull < turnbull.stephen.fw@u.tsukuba.ac.jp> wrote:
which, of course is what __repr__ is supposed to do, though in this case it doesn't quite: In [11]: fp = float("inf") In [12]: eval(repr(fp)) --------------------------------------------------------------------------- NameError Traceback (most recent call last) <ipython-input-12-4f5249ac51be> in <module> ----> 1 eval(repr(fp)) <string> in <module> NameError: name 'inf' is not defined So they are not "readable input, part of Python syntax", but they are part of the float API. Anyway, Python now has two different ways to "turn this into a string":, __str__ and __repr__. I think the OP is suggesting a third, for "pretty version". But then maybe folks would want a fourth or fifth, or ..... maybe we should, instead, think about updating the __str__ for standard types. Is there any guarantee (or even string expectation) that the __str__ for an object won't change? I've always wondered why the standard str(some object) wasn't pretty to begin with. As for using unicode symbols for things like float("inf") -- that would be an inappropriate for the __repr__, but why not __str__ ? *reality check*: I imagine a LOT of code out there (doctests, who know what else) does in fact expect the str() of builtins not to change -- so this is probably dead in the water. -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
Christopher Barker wrote: this is probably dead in the water. Regardless of whether we can improve/modify the __str__ for existing builtin objects, I think it is definitely worthwhile to clearly establish whether they are a part of the stable API in the first place. Users should be able to know if they can rely on the __str__ remaining the same across versions. My personal preference would be for the __repr__ to be stable (since it's already denoted as the "official" string representation, often can be used to replicate the object and/or uniquely identify it) and for the __str__ to be unstable/subject to change. As for whether the __str__ of any builtin object *should* be modified is another question entirely. I'm of the opinion that it should require sufficient justification: the benefit in readability/utility gained from the change by the majority of its users should outweigh the cost of potential breakage. If we've not provided any guarantee for the __str__ to remain the same across versions (which is true, AFAIK [1]), the fact that some users have chosen to rely on it doesn't seem like it should prevent any changes from being considered at all. It just means that the changes have to be adequately worthwhile and evaluated on a case-by-case basis. --- [1] - I have not extensively reviewed all of the documentation for all __str__ stability guarantees or lack thereof, but there are none in the places where I'd expect it would be present. In particular: https://docs.python.org/3.8/reference/datamodel.html#object.__str__ or https://docs.python.org/3.8/library/stdtypes.html#str. On Sun, Mar 15, 2020 at 9:30 PM Christopher Barker <pythonchb@gmail.com> wrote:
On Sun, Mar 15, 2020 at 06:27:43PM -0700, Christopher Barker wrote:
I think there is a strong expectation, even if there's no formal guarantee, that the str and repr of builtins and stdlib objects will be reasonably stable. If they change, it will break doctests and make a huge amount of documentation, blogposts, tutorials, books etc out of date. That's not to say that we can't do it, just that we shouldn't be too flippant about it. A few releases back (3.5? 3.4? I forget...) we changed the default float repr: python2.5 -c "print 2.0/3" 0.666666666667 python3.5 -c "print(2.0/3)" 0.6666666666666666 One advantage of that is that some values are displayed with the nearest human-readable exact value, instead the actual value. One disadvantage of that is that some values are displayed with the nearest human-readable exact value, instead of the actual value :-)
I've always wondered why the standard str(some object) wasn't pretty to begin with.
Define "pretty". The main reason I don't use the pprint module at the moment is that it formats things like lists into a single long, thin column which is *less* attractive than the unformatted list: py> pprint.pprint(list(range(200))) [0, 1, 2, 3, ... 198, 199] I've inserted the ellipsis for brevity, the real output is 200 rows tall. When it comes to floats, depending on what I'm doing, I may consider any of these to be "pretty": * the minimum number of digits which are sufficient to round trip; * the mathematically exact value, which could take a lot of digits; * some short number of digits, say, 5, that is "close enough". -- Steven
- CPython has __str__ and __repr__, IPython has obj._repr_fmt_(), MarkupSafe has obj.__html__(), https://github.com/tommikaikkonen/prettyprinter has @register_pretty Neither __str__ nor __repr__ have any round-trip guarantee/expectation (they're not suitable for serialization/deserialization // marshal/unmarshal / dump/load). Monkeypatching the __str__ or __repr__ of a builtin is generally undesirable because that's global and not thread safe. Could you use the locale module for this number formatting regional preference (inf as unicode inf)? https://docs.python.org/3/library/locale.html LC_INFINITY=unicode https://docs.python.org/3/library/locale.html#locale.LC_NUMERIC
... From "[Python-ideas] Draft PEP on string interpolation" (=> f-strings) https://groups.google.com/d/msg/python-ideas/6tfm3e2UtDU/euvlY6uWAwAJ : ```quote * Does it always just read LC_ALL='utf8' (or where do I specify that global/thread/frame-local?) [...] Jinja2 uses MarkupSafe, with a class named Markup: class Markup(): def __html__() def __html_format__() IPython can display objects with _repr_fmt_() callables, which TBH I prefer because it's not name mangled and so more easily testable. [3,4] Existing IPython rich display methods [5,6,7,8] _mime_map = dict( _repr_png_="image/png", _repr_jpeg_="image/jpeg", _repr_svg_="image/svg+xml", _repr_html_="text/html", _repr_json_="application/json", _repr_javascript_="application/javascript", ) # _repr_latex_ = "text/latex" # _repr_retina_ = "image/png" Suggested IPython methods - [ ] _repr_shell_ - [ ] single_quote_shell_escape - [ ] double_quote_shell_escape - [ ] _repr_sql_ (*NOTE: SQL variants, otherworldly-escaping dependency / newb errors) [1] https://pypi.python.org/pypi/MarkupSafe [2] https://github.com/mitsuhiko/markupsafe [3] https://ipython.org/ipython-doc/dev/config/integrating.html [4] https://ipython.org/ipython-doc/dev/config/integrating.html#rich-display [5] https://github.com/ipython/ipython/blob/master/IPython/utils/capture.py [6] https://github.com/ipython/ipython/blob/master/IPython/utils/tests/test_capt... [7] https://github.com/ipython/ipython/blob/master/IPython/core/display.py [8] https://github.com/ipython/ipython/blob/master/IPython/core/tests/test_displ... * IPython: _repr_fmt_() * MarkupSafe: __html__() ``` On Sun, Mar 15, 2020 at 11:00 PM Steven D'Aprano <steve@pearwood.info> wrote:
On Sun, Mar 15, 2020 at 11:37:53PM -0400, Wes Turner wrote:
Monkeypatching the __str__ or __repr__ of a builtin is generally undesirable because that's global and not thread safe.
Monkeypatching the __str__ or __repr__ of a builtin is generally impossible. py> int.__repr__ = lambda self: 'number' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: can't set attributes of built-in/extension type 'int' -- Steven
Exactly. Python 3 uses a Unicode model for strings. And that means anywhere you have strings, you have Unicode. And you need to deal with encoding issues on I/O. I'm not sure how logfiles are any different than any other file I/O. Related note: logfiles are likely to dump arbitrary messages attached to Exceptions as well. So you really need to be able to deal with arbitrary Unicode anyway. (note: in 2.7, passing arbitrary Unicode through the Exception machinery leads to messy errors, we really don't want that) That all being said, there is something to be said for keeping all __str__ and __repr__ on builtins to be a lowest common denominator subset (i.e. ascii) -- your logging system and whatever should handle any Unicode without raising, but it may use a "ignore" or "replace" error handler, and it would be pretty ugly to strip out parts of standard representations of builtins. -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
Christopher Barker writes:
So [inf and -inf] are not "readable input, part of Python syntax", but they are part of the float API.
Thank you for the correction. Aside: help(float) doesn't mention these aspects of the API. I guess that since 1.0 / 0.0 doesn't return float("inf") and 0.0 / 0.0 doesn't return a float("nan"), that's too far into the weeds for help. WDOT?
Is there any guarantee (or even string expectation) that the __str__ for an object won't change?
Nice typo! Yes, there's a strong expectation. doctests, as you pointed out, are a good example. Python may be good for developers who are moving fast and breaking things, but that's partly because (despite frequent complaints to the contrary) we don't move fast and break things most of the time.
As for using unicode symbols for things like float("inf") -- that would be an inappropriate for the __repr__, but why not __str__ ?
Because they're not always available, even in 2020. Also, ∞ is ambiguous; it's used for the ordinal number infinity (IIRC, more precisely denoted ω), the cardinal number infinity, the positive limit of the real line, the antipode of 0 in the complex (Riemannian) sphere, and probably other things. But
complex("inf") (inf+0j)
Oof. ;-)
complex("inf") * 1j (nan+infj)
Yikes! This was fun! :-) Steve
On Mar 15, 2020, at 22:37, Stephen J. Turnbull <turnbull.stephen.fw@u.tsukuba.ac.jp> wrote:
Well, there are an infinite number of ever larger infinite ordinals, ω or ω_0 being the first one, and likewise an infinite number of infinite cardinal, aleph_0 being the first one, and people rarely use the ∞ symbol for any of them. But people definitely do use the ∞ symbol for the projective infinity (the single point added to the real line to create the projective circle), and its complex equivalent (the single point added to the complex plan to give you the Riemann sphere). And IEEE (and therefore Python) infinity definitely doesn’t mean that; it explicitly has separate positive and negative infinities, modeling the affine rather than projective extension of the reals (the positive and negative limits of the real line). There are a few different obvious ways you could build an IEEE-float-style complex out of IEEE floats, but the one that C99 and C++ both use is probably the simplest: just model then as the Cartesian product of IEEE float with itself, applying the usual arithmetic rules over IEEE float. And that means these odd things make sense:
What else would you expect? The projective real line (circle) multiplied by itself gives you the projective complex plane (sphere) with a single infinity opposite 0, but the affine real line multiplied by itself gives you an infinite number of infinities. You can look at these as the limits of every line in complex space, or as the “circle” in polar coordinates with infinite distance at every angle, or as the “square” in cartesian coordinates made up of positive and negative real infinity with every imaginary number and positive and negative imaginary infinity with every real number. When you’re dealing with a discrete approximation like IEEE floats, these three are all different, but the last one falls out naturally from the definition, so that’s what Python does—and C, C++, and lots of other languages. So, inf+0j is one real-positive-infinite number, but inf+1j is another, and there’s a whole slew of additional ones (one for each float value for the imaginary component).
complex("inf") * 1j (nan+infj)
(a+b)(c+d) = ac + ad + bc + bd (a+bj)(c+dj) = (ac - bd) + (ad + bc)j (inf+0j)(0+1j) = (inf*0 - 0*1) + (inf*1 + 0*0)j And inf*0 is nan, while inf*1 is inf, right? Here’s the fun bit: >>> cmath.isinf(_) True Again, Python, C, and lots of other languages agree here, and it makes sense once you think about it. We have a number that’s either indeterminate or multivalued or unknown on one axis, but it’s infinite on the other axis, so whatever value(s) it may represent, they all must be infinite. If you look at the values you get from other complex arithmetic and the other functions in the cmath library, they all should make sense according to the same model, and should agree with C99. (I haven’t actually tested that…)
Andrew Barnert writes:
s/people/mathematicians/ and I'd agree with you. But I did write "people".
FVO "simple" = "simplistic". :-)
And that means these odd things make sense:
FVO of "sense" = "derived from an arbitrary model (as long as we're consistent)". (This time I'm not trolling.)
I don't "expect" anything when there are several competing interpretations. I would *like* it to be 'complex("inf")' FVO inf = projective complex plane infinity. My reasoning is the available *mathematical* values we model should make sense as expressing the set of possible limits in polar coordinates as well as in Cartesian coordinates (and as the limits of arbitrary lines). But these are in some sense distinct, with a couple of exceptions. So I would prefer my calculations to tell me "you're out of bounds" rather than give me a result that looks precise but actually doesn't tell me much about the limiting process. E.g., the mathematical limit in R^2 of (ax, bx) for all a, b > 0 is (inf, inf) -- thank you very much, I guess. By contrast, +inf and -inf for R tells me a lot.
Pragmatically, that is what I said I like, except I like it in maximum generality. ;-) Steve
On Mar 16, 2020, at 02:54, Stephen J. Turnbull <turnbull.stephen.fw@u.tsukuba.ac.jp> wrote:
But people rarely talk about infinite ordinals or cardinals. Anyone who’s talking about, e.g., whether there’s a set larger than the naturals but smaller than the reals isn’t calling either one of those sets’ cardinalities ∞.
What does FVO mean? At any rate, there’s nothing wrong with simplistic. Our usual addition on natural numbers is simplistic, and there are all kinds of other sort-of-addition-like things you could define on top of successor instead of it that are less simplistic, but none of them are nearly as useful, natural, or intuitive.
But it’s not an arbitrary model (except in the sense that every number system like Z is an arbitrary model), it’s a model that falls out of the natural composition of “build C from R” and “build R-bar from R and then build IEEE from R-bar”, in either order. And it’s one that preserves all the properties you’d hope—most importantly, continuation. The fact that 2+3=5, etc., when you use complex addition instead of real addition—is the reason we call complex addition “addition” in the first place. And C-bar built in this way continues R-bar in the same way C continues R. And the C-style approximation of C-bar with IEEE float approximately continues IEEE float in the same way (albeit sadly not always with the same bounds of approximation). Which is why we can call C/Python/etc. complex addition “addition”: complex.__add__(complex(2.0), complex(3.0)) == 2.0+3.0 (in this case exactly so, but in general you need isclose and it’s not always easy to calculate the cutoff…).
If you’re suggesting that our reals should be projectively extended and then our complexes should also be projectively extended, that would make sense. But then our reals wouldn’t be modeled by IEEE floats. If you’re suggesting that our complexes should be projectively extended even though our reals are affinely extended, then you’re giving up the continuation property; complex is no longer an extension of real.
But the infinite values we’re trying to model aren’t distinct between the two coordinate systems. The finite approximations are very different, on the other hand—but that’s already true even with finite numbers. The density of covered values over any part of the complex plane is different based on whether you approximate with cartesian IEEE floats or polar IEEE floats, so of course the same is true for the infinite parts of the plane as well. So what?
Consider electrical circuits (which is presumably what the people designing this system in the first place were considering, since IEEE math is designed for EE). All observable outputs have finite real values at all times. But intermediate values in the circuit are affinely-extended complex values. (You can argue about whether those values “really exist” or are “just a way of talking about real values that change over time” or whatever; I suspect most electrical engineers don’t care, they just want to be able to use them.) You can design a circuit where it some value is inf with phase pi/2 the output will be real 5V, if it’s inf with phase pi the output will be 0V, and if it’s in between the output is in between. If you insist on calculating that in the projectively extended complexes instead, you’ll just get NaN at all inputs; if you calculate it with the affinely extended complexes, even using the approximation made from the Cartesian product of IEEE float with itself, you get a well-bounded approximation of the curve from 5V to 0V that you were looking for. If that’s not meaningful, then none of our approximate number systems are meaningful. I’m not saying there are no advantages to the projectively extended complex numbers. But there are also advantages to the projectively extended reals over the affinely extended reals, and yet, we chose the advantages of the latter over those of the former. (Well, we just went with what a bunch of electrical engineers designed in the 1970s, but…) For complex, it’s mostly the same tradeoff again—and it’s not an independent tradeoff; making it inconsistently adds complexity while throwing away half the benefits—which is why almost every language has made the same decision as Python. It’s not arbitrary, it’s the most sensible choice.
Why? If you only care about whether something is infinite, rather than which infinity, you can use isinf. If you want to insist that nobody else can ever care about which infinity, even when it’s useful to them and we could have calculated it for them, just because you don’t have a use for it, and that we should either give up IEEE float semantics or have complex semantics that don’t match our float semantics in fundamental ways and that are derived in a more complicated way with unmotivated special cases instead of the natural way that falls out of any of the usual constructions of C in mathematics, that’s not really “maximum generality” you’re asking for, but the opposite.
This makes on my count 6 messages on arcane mathematical topics that have nothing to do with the original proposition, which was to do with prettyprinting. Don't get me wrong - I enjoy such discussions as much as anyone, considering myself a mathematician of sorts. But it must be frustrating for the OP, looking for some genuine feedback, to see the discussion wander off-track. (And time-wasting for anyone with a genuine interest in the OP's suggestion who, at some future time, reads through the thread.) And this is far from the first time I have seen this sort of thing happen. May I humbly suggest that contributors to a thread might make a little more effort to discipline themselves to reply to the OP rather than waxing lyrical on some unrelated topic? (And, very tentatively, suggest that there might even be a role for the Moderator here?). I intend absolutely no offence to anyone involved. Rob Cliffe On 16/03/2020 17:33, Andrew Barnert via Python-ideas wrote:
I thought about this a great deal when building the devtools package: https://pypi.org/project/devtools/ It prints common types in a pretty way (with the file, line number and value or expression that was printed): [image: image.png] But it also looks for a "__pretty__" method on objects, and if found uses that to display the object. I haven't yet documented that properly, but it's already implemented in pydantic (which I also maintain) so pydantic models can be displayed in a prettier way: [image: image.png] The challenge here is that "__pretty__" can't just return a string as that leaves all the formatting up to that method, rather than the printing/display library. So devtools expects "__pretty__" to yield objects in name, value pairs (or just values for list like objects), devtools then takes care of recursively displaying the values next to each name. Long term if an approach like this was more widely adopted, this approach should work well for things like IDEs which may want to display this data within a custom UI. I'll try and document the "__pretty__" generate when I get a chance, but if anyone has more questions, feel free to create an issue at https://github.com/samuelcolvin/python-devtools or ask here. Samuel -- Samuel Colvin
On Thu, Mar 19, 2020 at 11:38:28PM +0000, Samuel Colvin wrote:
But it also looks for a "__pretty__" method on objects, and if found uses that to display the object.
Are you aware that dunder names are reserved for Python's use?
Perhaps I don't understand the context here, but that doesn't sound like a general approach that would work very well. How would you "prettify" a scalar object which isn't a sequence and doesn't have name/value pairs? For that matter, if your library is expecting a stream of either (name, value) pairs, or just values, how does it distinguish genuine (name, value) pairs from values that look like (name, value) pairs but actually represent something else? I'm just not seeing how a display library can possibly know the right way to prettify an arbitrary object if you don't ask the object itself. As far as I can tell, pprint itself works because it only knows about a handful of special objects, it doesn't try to do anything too special with arbitrary objects it knows nothing about. -- Steven
On Fri, Mar 20, 2020 at 03:01:16PM +1100, Chris Angelico wrote:
Yes, really. https://docs.python.org/3/reference/lexical_analysis.html#reserved-classes-o...
Somebody better tell SQLAlchemy that they're breaking rules, then.
Lots of people break the rules all the time. Doesn't mean they should. -- Steven
On Fri, Mar 20, 2020 at 3:28 PM Steven D'Aprano <steve@pearwood.info> wrote:
"Subject to breakage without warning" technically applies to a *lot* of things that aren't guaranteed. Using __pretty__ as a protocol is no different from any of those. IMO it's not exactly a serious crime, even if technically it's something that could be broken. Also, since this is a proposal on python-ideas, it'd have as much blessing as __copy__, which to my knowledge has no meaning in the language itself, only in the standard library; it'd be the same with __pretty__, defined by the pprint module. ChrisA
On Fri, Mar 20, 2020 at 03:37:08PM +1100, Chris Angelico wrote:
"Subject to breakage without warning" technically applies to a *lot* of things that aren't guaranteed.
Yes?
Using __pretty__ as a protocol is no different from any of those.
If we should choose to use a `__pretty__` dunder, we have no obligation to follow Samuel's API, or make it a future-import, or give him any warning, or make any allowances for the fact that he is already using it. We can just break his code. Samuel may not have known that, but hopefully he will now.
IMO it's not exactly a serious crime,
Isn't it? Damn, I've already reported him to the federal police, the SWAT team will be arriving in 5, 4, 3, 2, ... *wink* I didn't describe it as a crime at all, I just asked if he knew he was using a reserved name.
I don't think that's a distinction that means anything. Whether the standard library or the interpreter itself breaks your code, it's still broken. -- Steven
Steven D'Aprano wrote:
Yes, really.
https://docs.python.org/3/reference/lexical_analysis.html#reserved-classes-o... I remembered the existence of this rule and tried to locate it recently (prior to this discussion), but was unable to because it doesn't explicitly mention "dunder". IMO, it would make that section much easier to find if it were to say either of: 1) System-defined names, also known as "dunder" names. 2) System-defined names, informally known as "dunder" names. 3) System-defined "dunder" names. Instead of the current: System-defined names. (or any mention of "dunder" for that matter) It would be much easier to locate. Realistically speaking, I can't imagine that the majority of Python users and library maintainers would read through the entire "Lexical Analysis" page of the docs if they're not specifically interested in parsing or something similar. :-) Regardless though, thanks for providing the link. I'll try to remember its location for future reference. On Fri, Mar 20, 2020 at 12:29 AM Steven D'Aprano <steve@pearwood.info> wrote:
On Fri, Mar 20, 2020 at 8:52 PM Kyle Stanley <aeros167@gmail.com> wrote:
The word "dunder" was coined (relatively) recently. It was not in common use when those docs were written. Another common nickname is "magic methods". So that explains why the word "dunder" isn't in those docs. And those docs are pretty "formal" / "technical" anyway, not designed for the casual user to read. But yes, it would be good to add a bit of that text to make it more findable. I'd suggest you make a PR on the docs. -CHB Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
Chistopher Barker wrote:
I'd suggest you make a PR on the docs.
Yeah I was planning on either doing that, or opening it as a "newcomer friendly"/"easy" issue on bugs.python.org. IMO, it could make for a decent first PR. On Sun, Mar 22, 2020 at 1:28 PM Christopher Barker <pythonchb@gmail.com> wrote:
I ended up opening an issue for it at https://bugs.python.org/issue40045. <http://bugs.python.org> On Sun, Mar 22, 2020 at 8:33 PM Kyle Stanley <aeros167@gmail.com> wrote:
On 20/03/20 4:55 pm, Steven D'Aprano wrote:
Are you aware that dunder names are reserved for Python's use?
Nobody is going to put you in jail if you use an unofficial dunder name. You just run the risk that your use of it will conflict with some official use in the future. -- Greg
On Fri, Mar 20, 2020 at 06:30:24PM +1300, Greg Ewing wrote:
You're the second person mentioning crime or law. What did I say to give people the impression that I think that using a dunder is a criminal offence? I didn't say that it was illegal or breaking the law, or a felony or even a misdemeaner. I didn't even make a value judgement about whether it was a good thing or a bad thing to use dunder names. I said that dunders are reserved. Not everyone knows this. What should I have said that won't be misinterpreted as an accusation of criminality? -- Steven
Hi Steven,
Are you aware that dunder names are reserved for Python's use?
I wasn't aware it was explicitly discouraged, thanks for the link. It seems to me that "__pretty__" (however it's implemented) seems a very sensible name for a method used when pretty printing objects. If it's one day implemented officially I think the approach I took is a good start, if it's not, then what I've done won't conflict with anything. :-) I'm sure I've broken lots of rules by just taking a punt at an implementation rather than enduring weeks of argument-for-arguments-sake on this mailing list, but the more I read it, the happier I am about that decision.
Perhaps I don't understand the context here, but that doesn't sound like a general approach that would work very well.
I think it does work well; though I agree I didn't explain it very well last night (indeed my rushed explanation was outright wrong in some regards). Let me explain more how my implementation of "__pretty__" works, taking an example form devtool's tests <https://github.com/samuelcolvin/python-devtools/blob/7482e87dcb2dab47884a790...> : class CustomCls: def __pretty__(self, fmt, **kwargs): yield 'Thing(' yield 1 for i in range(3): yield fmt(list(range(i))) yield ',' yield 0 yield -1 yield ')' debug(CustomCls())
__pretty__ takes two keyword arguments: fmt - a function, and skip_exc - an exception which can be raised to stop pretty printing. It then yields either: - A string, in which case that string is just displayed - An int, which tells devtools to move to a new line and maybe change the indent/context. 1 means increase indent, -1 means reduce the indent and 0 means just new line with no indent change - the value returned from fmt() which causes devtools to take care of displaying the argument passed to fmt(), including recursive display of sub-objects That's it. It's very simple but it allows effectively arbitrarily complex objects to be displayed. Especially since an object that wants to take care of all display of itself can just do so and return a string. All that fmt() actually does is mark an object as requiring devtools to take care of its display, it is implemented as a function argument to __pretty__ to avoid libraries that implement __pretty__ from needing devtools as a requirement. I hope that makes more sense and acts as a starting point for a more productive conversation about an standard approach to pretty printing. Samuel
It’s a bit ironic: if you have a nifty idea for Python, you are often told to try it out on your own. And if you expect it to maybe make its way into Python, you’d want to use a dunder... But then, dunders are reserved for the standard library. It’s a pickle. And it’s not like there’s no precedent: What about __version__ ? Which, by be the way, maybe it’s time to make official? https://www.python.org/dev/peps/pep-0396/ -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
On Mar 20, 2020, at 19:32, Christopher Barker <pythonchb@gmail.com> wrote:
It’s a bit ironic: if you have a nifty idea for Python, you are often told to try it out on your own. And if you expect it to maybe make its way into Python, you’d want to use a dunder...
But then, dunders are reserved for the standard library. It’s a pickle.
When third-party libs end up in the stdlib, they usually change. Sometimes there are just small bikeshedding changes, like simplejson/json or statistics/stats, sometimes the whole thing gets redesigned, like attr.s/dataclasses or flufl.enum/enum. If you’re designing something that you hope will one day get standardized, maybe it’s not such a bad thing that you’re forced to think of how the migration is going to go for your early adopter users, and make them think about it too. And if the stdlib version might change the semantics of the protocol in any way, which is more disruptive to users: the stdlib json module doesn’t respect your _tojson methods because it wants __json__, or the stdlib json module sort of respects your __json__ methods but gets it “wrong” in some important cases because it uses the same name but with changed semantics? And then, if you used _tojson, you can add the stdlib’s __json__ and the same module works as the backport of the 3.10 stdlib to older versions and as the more-featureful third-party module some people still need.
Samuel Colvin writes:
That depends on whether somebody decides that "pretty" is a good name for a different function (such as going through all the strings in the object and making sure they are properly capitalized and use the same sentence-ending convention, or a different signature -- see below). Single leading underscore is reserved for class-private use, so you could more safely use "sunders" (_pretty_) or "splunders" (_pretty__). I'll note (as a mail geek) that use of a private method suffers a similar issue to that of the "X-" convention for message header field names: once standardized, you can't get rid of the old name. Nowadays, the recommendation in message header standardization community (*especially* for names that you are proposing for standardization) is to just go ahead and use an unprefixed name for private protocols. I don't know how close this analogy of the field name problem to the protocol implementation name problem is, but it's some evidence for your practice.
But that's precisely the issue with __pretty__: it allows objects to decide how to format themselves, when the application wants control. The way I think of pprint (FWIW, YMMV) is as a debug utility. If I were going to extend it, I would probably use a different name such as __debug_format__ for the dunder, and it would take the usual 'self' argument, plus hint arguments 'indent', 'width', 'height' describing the "subwindow" the caller wants to give it. The return value would be a (possibly nested) list of strings, each including the indent the object proposes to use. Then the simplest implementation of the pretty() function would simply flatten the nested list, join the result, and output it, while a very opinionated pretty() might strip all the indentation, apply its own opinion of the appropriate indentation, then truncate the indented line to its opinion of the appropriate length. Steve
On Sat, 21 Mar 2020 at 06:42, Steven D'Aprano <steve@pearwood.info> wrote:
I agree with Stephen (ph) - debugging. For end user display, I'd typically want to write a custom display function. For debugging, I want a readable display with as little effort as possible (debugging is hard enough without having to write display routines or put up with unreadable data dumps). Very much personal preference, though. Paul
Steven D'Aprano writes:
Oh, that's interesting. I mostly think of pretty-printing as a display utility aimed at end users.
Well, I'm mostly the only end-user of my code, so there's definitely a bias here. I'd be interested to see the "display utility" point of view expanded. Steve
I'd be interested to see the "display utility" point of view expanded.
For me there are two use cases: I use devtool's debug() command instead of print() ALL THE TIME when debugging, so does the rest of my office and others who I've demonstrated its merits to. I use this sitecustomize trick <https://github.com/samuelcolvin/python-devtools#usage-without-import> to avoid having to import debug(). Using debug() over print() or pprint() for debugging has the following advantages, some more obvious than others: - It's much easier to read, particularly for big/complex/nested objects. Coloured output helps a lot here, so does better support for non std-lib objects like pandas dataframes, django querysets, multidict dictionaries, pydantic models etc. - I don't need to constantly write print('user.profile.age:', repr(user.profile.bio)) - just debug(user.profile.bio) takes care of showing the variable or expression I want to display as well as its value - debug() uses repr() which is mostly more useful when debugging than str() - debug() uses a slightly different logic to display nested objects compared to pprint(), you can think of it as looking much more like json.dumps(..., indent=4), maybe it's just that I'm the JSON generation, but I find it much easier to read than pprint(...) - having the file and line number saves me having to try and dig around to find where the print state is - this is particularly useful when debugging code in installed packages or in large code cases - debug() does a decent (if not perfect) job of displaying objects (e.g. strings) how I would want them in code so it can be super quick to add a test based on the value or copy it to code elsewhere - the sitecustomize trick means flake8 fails if I forget to remove debug() statements, similarly it means tests fail if I forget to remove them The second case is displaying objects to developers-as-users. For example aio-libs/aiohttp-devtools uses devtools to print request bodies and headers to aid debugging of unexpected http response codes (as far as I remember). Here I'm using devtools.pformat, it's convenient to use that method rather than have to write lots of display logic in each package. *Side Note:* I'm aware I'm talking about the devtools package (which I maintain) a lot, I'm waiting for the moment someone get's cross that I'm promoting my package. Sorry if it seems like that, but that's not what I'm trying to do, devtools isn't perfect and I wish it didn't exist. I think the python standard library should have a debug print command that knows how to print common object types but also respects a dunder method on objects which want to customise how they're displayed when debugging. The name of the debug command and the name of the dunder method don't bother me much. I'm just using devtools as an example of what I think should be in the standard library. Samuel
Samuel Colvin writes:
I'd be interested to see the "display utility" point of view expanded.
For me there are two use cases:
These both seem to be what I would consider "debugging" use cases, ie, displaying whole objects to users who have some understanding of the internals. My understanding of "display utility" was for end users. Perhaps Steven (d'Aprano) meant your "developers as users" case, but that's not what I understood. Also, am I to understand that simply adding "__pretty__" with a single "debug" function gets all the benefits you describe, or do you need additional support from devtool? Steve
On Fri, Mar 20, 2020 at 8:24 PM Stephen J. Turnbull < turnbull.stephen.fw@u.tsukuba.ac.jp> wrote:
Single leading underscore is reserved for class-private use, so you could more safely use "sunders" (_pretty_) or "splunders" (_pretty__).
Though this use case really isn't "class-private" -- it's more "package private", but I don't think it's even that. The idea is to allow anyone to make a class that plugs into this system -- so very much like a dunder, but without the blessing of the standard library. Maybe a semi-convention of "trunders" would make sense? ___pretty___ -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
Taking Rob Cliffe's statement in good part, changing the subject (belatedly, sorry!) Andrew Barnert writes:
What does FVO mean?
Sorry. "For values of"
At any rate, there’s nothing wrong with simplistic.
My usage of simplistic is to simple as complicated is to complex. The distinction relates to the cost of design vs cost to users tradeoff. "Simplistic" and "complicated" impose complexity on users in ways that could (and implicitly should) be avoided by more effort on design. So:
Our usual addition on natural numbers is simplistic,
I don't understand why you use "simplistic" here, rather than "simple".
You mean like hardware unsigned modular integer arithmetic, and two's complement addition for signed integers? But they are not "simple" for humans to use, though I would call them "simplistic" in the sense that "these are simple to implement, and people will just have to deal".
And it’s one that preserves all the properties you’d hope—most importantly, continuation.
Yes, I agree. My question is whether users would be better off with a different simplicity. After all, the electrical engineers don't get embedded reals for free, they have to test for .imag == 0 and then use .real:
But they are. (inf + 1j) and (inf + 2j) cannot be distinguished in polar coordinates, while the infinities with arg = 1/2 and arg = 1/4 cannot be distinguished in Cartesian coordinates. You need a category with a concept of limiting process to make those distinctions with the "wrong" coordinate system; extended arithmetic is not enough. Maybe the "endpoints of lines" representation of infinity in the affine complex plane gets all of the infinities?
So what?
Always a good question. :-) "Readability counts". For *my* purposes, complex numbers are just numbers visualized in projective polar coordinates, and nan + 1j *is* just nan, inf + 1j *is* just inf. We *could* have a language where the calculations of complex arithmetic are done with Cartesian pairs of IEEE reals, the strs are 'inf' and 'nan', and there's an API for extracting further information from the object if you care. Instead we have a str that gives me the WTFs when I visualize them, which I do automatically. But then, I am a (wannabe) mathematician, and quite possibly only the other 100 people who read the books I do feel the same way.
If you want to insist that nobody else can ever care
Please, sir! I am a faithful Economist, my creed is "De gustibus non est disputandum." I don't have a use case for projective arithmetic, just a matter of taste in float.__str__. I was unaware of the pragmatics of electrical engineering, and am happy to let their calculations "just work". If they are used to seeing "inf + 1j" and it is useful to them, that's more important than my occasional WTF. Steve
David Mertz writes:
As a mathematician who is a people (I am large, I contain multitudes), I can tell you you have the inclusion backwards for the argument you make. Damn, I'm going to miss you all during PyCon, can't make it this year. (And probably shouldn't even if I had confirmed funding, but that's another story.)
On Mon, Mar 16, 2020, 3:41 AM Andrew Barnert via Python-ideas < python-ideas@python.org> wrote:
It's convenient to be compatible with cmath. CAS systems vary in regards to whether it's inappropriate and over-reductionistic to just throw away a scalar magnitude 'times' an infinity symbol. These approach ±inf at different rates: -2/n 1/n 2/n It's not a pedantic differentiation; but my guess is that such use cases generally call for CAS and not cmath or python anyway. ... Again, could the locale module be extended to handle customizable formatting for inf?
Might be helpful to look at https://github.com/tommikaikkonen/prettyprinter and https://github.com/wolever/pprintpp
Alex Hall wrote:
Might be helpful to look at https://github.com/tommikaikkonen/prettyprinter and https://github.com/wolever/pprintpp
Right! Thx. :)
participants (20)
-
 Alex Hall
Alex Hall -
 Andrew Barnert
Andrew Barnert -
 Barry Scott
Barry Scott -
 C. Titus Brown
C. Titus Brown -
 Chris Angelico
Chris Angelico -
 Christopher Barker
Christopher Barker -
 David Mertz
David Mertz -
 Eric V. Smith
Eric V. Smith -
 Greg Ewing
Greg Ewing -
 Guido van Rossum
Guido van Rossum -
 James Edwards
James Edwards -
 Jonathan Fine
Jonathan Fine -
 Kyle Stanley
Kyle Stanley -
 Paul Moore
Paul Moore -
 Rob Cliffe
Rob Cliffe -
 Samuel Colvin
Samuel Colvin -
 Stephen J. Turnbull
Stephen J. Turnbull -
 Steve Jorgensen
Steve Jorgensen -
 Steven D'Aprano
Steven D'Aprano -
 Wes Turner
Wes Turner