
add one:if scikit-image can implements a ridge filter. just like watershed mixed with the skeleton. make all region a same label, then do level loop, just stop when one pixel left. It's usful in geography and hydrology analysis. ----- 原始邮件 ----- 发件人:Juan Nunez-Iglesias <jni.soma@gmail.com> 收件人:scikit-image <scikit-image@python.org>, imagepy@sina.com, "Mailing_list_for_scikit-image_(http://scikit-image.org)" <scikit-image@python.org> 主题:Re: [scikit-image] my watershed 日期:2017年09月21日 13点48分 Hi Yan, Thanks for this. Simple functions are very good for one’s own images, as well as to understand an algorithm, but for a widely used library like scikit-image, flexibility and robustness are least as important as speed. In skimage, we aim to support floating point input images, for which your code won’t work. There is a lot of thought into edge cases going into the skimage implementation, which unfortunately could have an effect on performance. The question we need to solve isn’t “can we make a super-fast watershed implementation”, but, “can we make a flexible and robust implementation that is also fast?” Using Numba is certainly not off-limits, but any candidate implementation should at a minimum pass the skimage test suite. I once tried a level-by-level implementation of watershed, by the way. It has a fatal flaw, which is that valleys with no markers will never get labeled. Here’s a test case that works with skimage but fails in your implementation. (Note also that your implementation overwrites the seeds image, which is pretty crazy. =) Thanks again! Juan. In [44]: import watershed In [45]: from skimage import morphology In [46]: import numpy as np In [47]: image = np.array([1, 0, 1, 0, 1, 0, 1], dtype=np.uint8) In [48]: seeds = np.array([0, 1, 0, 0, 0, 2, 0]) In [49]: morphology.watershed(image, seeds) Out[49]: array([1, 1, 1, 1, 2, 2, 2], dtype=int32) In [50]: watershed.watershed(image, seeds) Out[50]: array([0, 0, 0, 0, 0, 0, 0]) In [51]: seeds Out[51]: array([0, 0, 0, 0, 0, 0, 0]) On 12 Sep 2017, 6:34 AM +1000, imagepy@sina.com, wrote: Hi: Now It supports nd. but less of test. this image, skimage cost 20s, mine less than 1s. It is wrriten with numba in 90 lines. did not support compactness, but it's simple, and fast. YXDragon _______________________________________________ scikit-image mailing list scikit-image@python.org https://mail.python.org/mailman/listinfo/scikit-image
{kind=link}

Actually this specific function has been on my mind for some time! Do you have a reference implementation, preferably in nD? =) On 21 Sep 2017, 4:33 PM +1000, imagepy@sina.com, wrote:
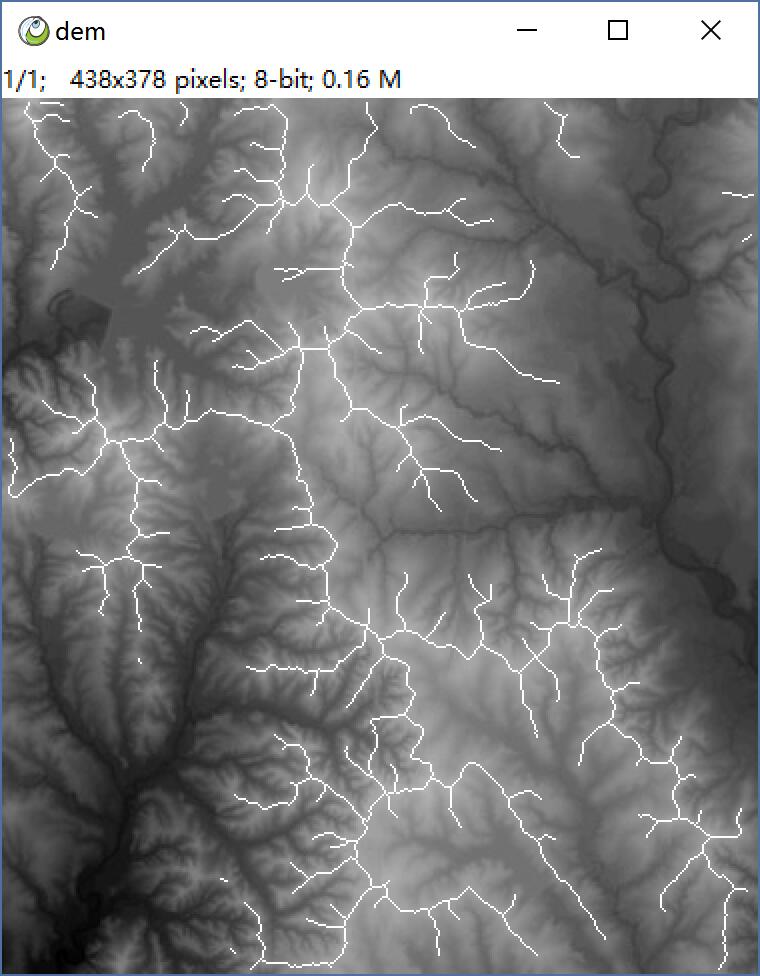
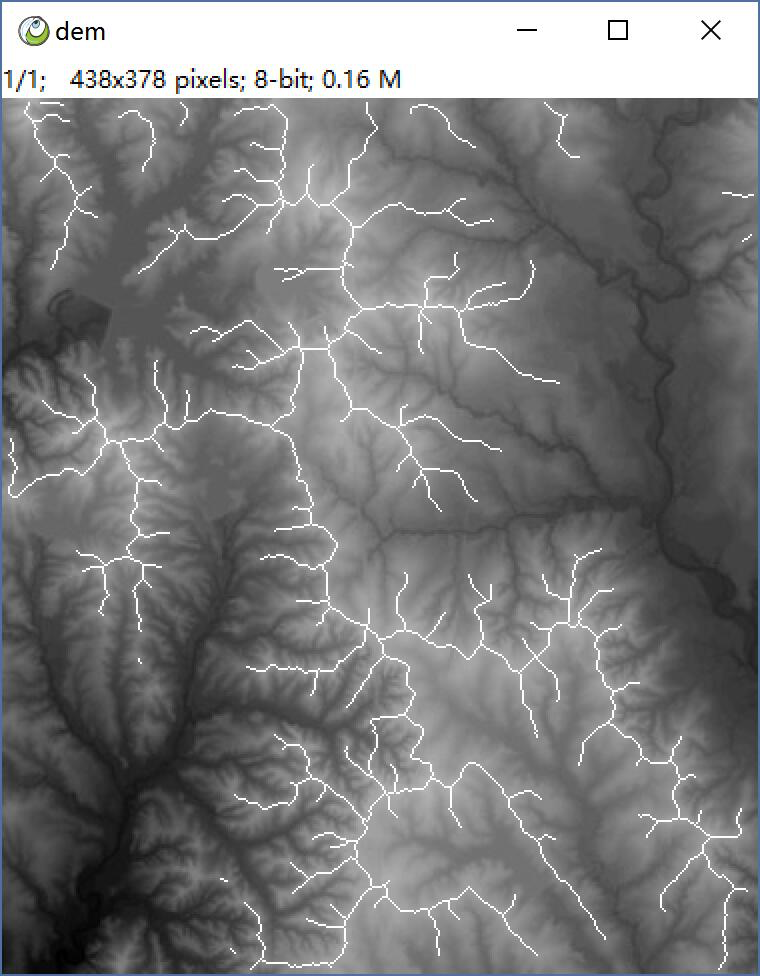
add one: if scikit-image can implements a ridge filter. just like watershed mixed with the skeleton. make all region a same label, then do level loop, just stop when one pixel left. It's usful in geography and hydrology analysis.
----- 原始邮件 ----- 发件人:Juan Nunez-Iglesias <jni.soma@gmail.com> 收件人:scikit-image <scikit-image@python.org>, imagepy@sina.com, "Mailing_list_for_scikit-image_(http://scikit-image.org)" <scikit-image@python.org> 主题:Re: [scikit-image] my watershed 日期:2017年09月21日 13点48分
Hi Yan,
Thanks for this. Simple functions are very good for one’s own images, as well as to understand an algorithm, but for a widely used library like scikit-image, flexibility and robustness are least as important as speed. In skimage, we aim to support floating point input images, for which your code won’t work. There is a lot of thought into edge cases going into the skimage implementation, which unfortunately could have an effect on performance. The question we need to solve isn’t “can we make a super-fast watershed implementation”, but, “can we make a flexible and robust implementation that is also fast?” Using Numba is certainly not off-limits, but any candidate implementation should at a minimum pass the skimage test suite.
I once tried a level-by-level implementation of watershed, by the way. It has a fatal flaw, which is that valleys with no markers will never get labeled. Here’s a test case that works with skimage but fails in your implementation. (Note also that your implementation overwrites the seeds image, which is pretty crazy. =)
Thanks again!
Juan.
In [44]: import watershed In [45]: from skimage import morphology In [46]: import numpy as np In [47]: image = np.array([1, 0, 1, 0, 1, 0, 1], dtype=np.uint8) In [48]: seeds = np.array([0, 1, 0, 0, 0, 2, 0]) In [49]: morphology.watershed(image, seeds) Out[49]: array([1, 1, 1, 1, 2, 2, 2], dtype=int32) In [50]: watershed.watershed(image, seeds) Out[50]: array([0, 0, 0, 0, 0, 0, 0]) In [51]: seeds Out[51]: array([0, 0, 0, 0, 0, 0, 0])
On 12 Sep 2017, 6:34 AM +1000, imagepy@sina.com, wrote:
Hi: Now It supports nd. but less of test. this image, skimage cost 20s, mine less than 1s. It is wrriten with numba in 90 lines. did not support compactness, but it's simple, and fast.
YXDragon _______________________________________________ scikit-image mailing list scikit-image@python.org https://mail.python.org/mailman/listinfo/scikit-image
{kind=link}
participants (2)
-
 imagepy@sina.com
imagepy@sina.com -
 Juan Nunez-Iglesias
Juan Nunez-Iglesias