type hints : I'd like to suggest allowing unicode → as an alternative to ->

well it’s all in the title the specific character that I am referring to is this one In [1]: print("\u2192”) → https://unicode-table.com/en/2192/ —— just curious about how people would feel about taking better advantage of non-ascii characters when that seems to make sense fyi here’s how both options appear in a markdown-based website thanks !

On Sun, May 17, 2020 at 2:24 PM Thierry Parmentelat < thierry.parmentelat@inria.fr> wrote:
I'm not a fan of the idea, just in case the code ends up being copied somewhere it can't be rendered properly. If we consider the arrow, what about ≤ instead of <=, ≥ instead of >=, ≠ instead of !=, × instead of `*`, and math.π instead of math.pi?

math.π instead of math.pi
That is already possible, just not done in the standard library, no? Your point still stands, but it's rather different to your other examples, which are actual changes to syntax. With regards to the actual proposal, I quite like the idea of being able to use them, but I don't think it's worth portability issues - style guides would just end up forbidding it anyway. They're also hard to type, and of course,
There should be one-- and preferably only one --obvious way to do it.
On Sun, 17 May 2020 at 13:32, Alex Hall <alex.mojaki@gmail.com> wrote:

Hello, On Sun, 17 May 2020 14:31:34 +0200 Alex Hall <alex.mojaki@gmail.com> wrote: []
If we consider the arrow, what about ≤ instead of <=, ≥ instead of
=, ≠ instead of !=, × instead of `*`, and math.π instead of math.pi?
Before this goes too a big shaky bikeshed over almost nothing, let me point out that if you're looking to improve something in type annotations, I would suggest to look for true ugliness there. Something like Callable[[Dict[str, int], Sequence[Foo]], Dict[PrimaryKey, List[int]]]. That's rather unreadable. Actually, let me just quote https://docs.python.org/3/library/typing.html#typing.Callable
Callable type; Callable[[int], str] is a function of (int) -> str.
Lolwhat? If it's a function of "(int) -> str", then it should be written just about like that. With https://www.python.org/dev/peps/pep-0563/ , a lot of things which weren't previously possible, are now possible. Somebody should start thinking how to take advantage of that, up to allowing "(int) -> str". Which is apparently not possible currently, as while "evaluation" is postponed, it still should parse eagerly as Python syntax. But even {(int): str} is a better type annotation for a function than Callable[[int], str]. And if we e.g. talk about making "->" a special operator which would allow it to appear in other contexts than function definition, "(int) -> str" (and other interesting annotation syntaxes) would be possible. -- Best regards, Paul mailto:pmiscml@gmail.com
totally agree on the awkwardness :-)
would be nice too - although this is orthogonal to my initial proposal, right ?
well, {(int): str} already means something; are you suggesting that an expression like this could have different meanings whether it’s in an annotation or not ? that sounds scary ...
again, that’s be quite cool for typing function parameters :)

On 18/05/20 1:59 am, Paul Sokolovsky wrote:
I don't agree -- it looks more like some kind of dict type, and would be better reserved for that purpose.
And if we e.g. talk about making "->" a special operator which would allow it to appear in other contexts
Or maybe we could leverage the new walrus operator and write str := (int) -- Greg


I'm going to ask that people please try to keep this thread on-topic to the question of using Unicode characters directly for things that we currently use two ASCII characters to represent. Other ideas that spring up from this question are totally welcome to be done as new threads of discussion. On Sun, May 17, 2020 at 6:42 PM MRAB <python@mrabarnett.plus.com> wrote:

On Tue, May 19, 2020 at 11:31 AM Brett Cannon <brett@python.org> wrote:
Indeed -- and also: please refer to earlier conversations on this list and elsewhere -- this is NOT a new idea! I'd suggest also that the question at hand be more global: Should Python be extended to allow non-ascii characters in syntax? Rather than one or two specific ones. ON a related note, another way to get "Nicer" multi-character operatores is lignatures. Jet BRains has put out a font with a pretty full set: https://www.jetbrains.com/lp/mono/#ligatures (you can use that font with most Editors / IDEs -- works great with Sublime, for instance) That way, it's still two ascii characters, but it looks like one nifty symbol in your editor. Maybe no need to complicate Python? ;-) -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
On 19 May 2020, at 20:27, Brett Cannon <brett@python.org> wrote:
I'm going to ask that people please try to keep this thread on-topic to the question of using Unicode characters directly for things that we currently use two ASCII characters to represent. Other ideas that spring up from this question are totally welcome to be done as new threads of discussion.
Thank you for re-focusing the discussion I’d like to express the strong opinion that anything related to a particular IDE is not the right answer I’m not going to switch to jetbrains just to get ligatures or fancy rendering, am I ? would you ? Plus, it’s not only IDE’s, I’m prominently concerned by beginners and students, who start reading code on sources like github, or teaching websites, or notebooks; one cannot expect all these stacks to go this extra mile, that is just not right IMHO back to the point as phrased by Brett: I reckon the languages communities have mostly so far stuck to ASCII, probably for good reasons, but the thing is Unicode has been around for quite some time now, and can be deemed generally available so why not take full advantage of it ? It is my feeling that part of the awkwardness of the typing annotations, rightfully outlined above, is due to the narrow set of characters at our disposal, hence the awkward Iterable[] (this one at least clearly deserves better IMHO), and Dict[,] likewise There has to be nicer and more legible ways to express all these I tend to start the discussion on typing annotations because they are more recent, and clearly more in need of improvement however like Alex Hall pointed out, using dedicated symbols like
quoting ≤ instead of <=, ≥ instead of >=, ≠ instead of !=, would make a lot of sense as well
I also reckon it is still cumbersome to simply enter Unicode characters from a keyboard sometimes; I guess if the big players were located in other countries that would maybe be different But that will change over time, no matter the speed, some day that will be for granted So again maybe 2020 is the right time to break that barrier ? === PS. it looks like one reasonable thread to spawn off from the earlier exchanges here is about the definition of an arrow operator for defining function types I’ll leave it to the person who originally extended the discussion in that direction :)

On Wed, May 20, 2020 at 4:36 PM Thierry Parmentelat <thierry.parmentelat@inria.fr> wrote:
The Dvorak keyboard was invented nearly a hundred years ago. How's it looking as a viable alternative? If you think that a keyboard with fancy arrows on it will take off any quicker, you're extremely hopeful. MUCH more practical will be to use vim conceal etc, leave your source code unchanged, and just change the way it looks to you. There are similar features available in a number of editors. ChrisA

On 05/20/2020 12:44 AM, Chris Angelico wrote:
On Wed, May 20, 2020 at 4:36 PM Thierry Parmentelat wrote:
Well, 25 years ago I had to write my own Dvorak device driver for use with MS-DOS, now it's included in at least Windows and Linux (a Dvorak mapping, not my device driver). So much more viable. :)
If you think that a keyboard with fancy arrows on it will take off any quicker, you're extremely hopeful.
I wouldn't be surprised if it did, although a standard set of keyboard shortcuts is more likely.
I'll have to look into that. -- ~Ethan~
On Thu, May 21, 2020 at 1:48 AM Ethan Furman <ethan@stoneleaf.us> wrote:
I'm pretty doubtful. Keyboards seem to be LOSING keys, not gaining them. Which is a trend that I deplore (where are my F1-F12 keys?? and I doubt I'll ever see F13-F16), but I still cling to the hope that not ALL keyboards are going that way. ChrisA

On Thu, May 21, 2020 at 01:58:29AM +1000, Chris Angelico wrote:
On Thu, May 21, 2020 at 1:48 AM Ethan Furman <ethan@stoneleaf.us> wrote:
Indeed. The ultimate expression of this trend is, of course, the smartphone, where you have no physical keyboard at all. Even if people don't do their for-real development on their smartphone, they will insist on replying to emails, messages, Stackoverflow questions etc on them, and they won't necessarily have [insert name of app here]. So unless the symbol shows up on the smartphone's native keyboard emulator people won't be able to use it at least part of the time. -- Steven

On 2020-05-20 00:44, Chris Angelico wrote:
If you think that a keyboard with fancy arrows on it will take off any quicker, you're extremely hopeful.
While I'm not sure how useful this is in the long run, the oft mentioned drawback of "hard to type/view" Unicode chars isn't as insurmountable as some think: - Word processors have had a palette to insert symbols for decades. - Editors have had "snippets" for perhaps almost as long. - Code formatters such as "go fmt", yapf, black, etc could update them. - All maintained OSs support a great majority of Unicode, with font support. - AltGr and Compose keys are available. I've been using Unicode everywhere for about a decade—it's time to retire the argument that input is still hard or rare. Dedicated keys are not really necessary. -Mike
On Wed, May 20, 2020 at 01:13:10PM -0700, Mike Miller wrote:
Not everyone is programming in a GUI environment all the time, and even when they are, GUI "insert symbol palettes" are of greatly variable quality.
- Editors have had "snippets" for perhaps almost as long.
Sure, but like the "insert symbol" command, needing to use a snippet adds friction. Even in the best case, think of the difference between: * type a minus sign `-` * use a snippet or symbol palette to find and insert a `→` symbol.
- Code formatters such as "go fmt", yapf, black, etc could update them. - All maintained OSs support a great majority of Unicode, with font support.
Which is still patchy, but getting better. I still come across monospaced fonts where certain symbols have annoying "off by one pixel" display bugs, or are missing the exact symbol you need. I use a lot of arrows in my maths equations, and they are invariably too small, too big or placed too close to the baseline, depending on the font. At smaller font sizes, the arrow head tends to look like "grit on the monitor". In a word processor, I can manually tweak that, but in a programming environment using a text editor, there's not much I can do except search for that One Perfect Font. Still not found it after decades of searching.
- AltGr and Compose keys are available.
And require the editor or OS to support it, a keyboard to have the right compose key, and most importantly of all, for the user to remember a bunch of esoteric key codes to get the symbol needed. I can remember Win key .. to give MIDDLE DOT · but it's the wrong dot, I need DOT PRODUCT ⋅ (which unfortunately is displayed as a missing- character glyph in my email client and editor). But I have no idea what key combination I need to press to get DOT PRODUCT. Last night I had one of my students ask me how they are supposed to type maths symbols during an online test if they can't google for it and copy it from some website. I didn't have an answer. So what is the key code for the → symbol?
I've been using Unicode everywhere for about a decade—it's time to retire the argument that input is still hard or rare.
I can sincerely say that I am very happy that your experience is so good, but I'm also exceedingly jealous of it. I don't think your experience scales to the majority of people. -- Steven
I guess we’re getting to the gist of it I was not proposing that everybody MUST enter → I was suggesting that some people MAY want to do that so their code looks prettier in contexts where no additional intelligence is available to embellish things Do we want to get stuck in the 20th century just because everything is not yet perfect in a non-purely ASCII world ?
Hello, On Thu, 21 May 2020 13:26:32 +0200 Thierry Parmentelat <thierry.parmentelat@inria.fr> wrote: []
Do we want to get stuck in the 20th century just because everything is not yet perfect in a non-purely ASCII world ?
Short answer: yes. Long answer: ASCII was defined in 1963 and hasn't won over yet, e.g. EBCDIC is alive and kicking: https://en.wikipedia.org/wiki/EBCDIC . Ergo, 50 years isn't enough for a character encoding to become truly pervasive. I suggest we wait and see whether 100 years makes a difference, which in the case of Unicode means: let's talk again closer to 22th century. [] -- Best regards, Paul mailto:pmiscml@gmail.com
On 2020-05-20 14:56, Steven D'Aprano wrote:
Not everyone is programming in a GUI environment all the time
Well, I gave a number of examples to show there are many ways to do it. Not every example will work well for everyone. The best that works for your platform and tools should be chosen. There are numerous others I didn't bother to mention.
- Code formatters such as "go fmt", yapf, black, etc could update them.
I think this is the choice with the least effort required, a code formatter. For example, a tip was given to me that you can save keystrokes writing Python by using single-quotes exclusively (which I do) then let black change them to double later. I still come across
monospaced fonts where certain symbols have annoying "off by one pixel" display bugs, or are missing the exact symbol you need.
I use "Source code pro" often and Symbola occasionally and they work well. Full math notation is problematic and likely farther than anyone is proposing. I do use box-drawing occasionally and don't have any alignment problems with them even cross-platform.
It's true that I did take a few moments to configure things to make it easier for me. Once done however, easy. But, the majority is now using emoji everywhere, in defiance of curmudgeons. I've never heard anyone complain it's "too hard." -Mike

On Wed, 20 May 2020 at 17:17, Mike Miller <python-ideas@mgmiller.net> wrote:
Input _is_ hard or rare. Deal with it. Even the font is not uniformily configured across systems, and a glyph one does see here may not show properly on the terminal, or other editing environment. I see absolutely no gain of using optional arcane symbols in soruce code. Of course documentation derived from annotations can be as prettified as one want. It seems that the only sane thing to do is to use a baseline of well established symbols on source code, and anyone can have a customized editor to render (or input) those as they see fit - and even thought that always have been a possibility, very few people does so. (I had a coleague once which did set a special VIM config to display "!=" as "[can't type, math 'different' sign from here]" and even that was mostly a toy than anything really useful.
I guess that is my point exactly: the main reason why this person has been unable to make anything useful out of that otherwise perfectly sound idea is that it is not allowed in the language, so people need to mess with solutions on the outside sphere - editors, IDE’s, documentation post-processing - that essentially have no chance to be sustainable, and/as it causes extra burden for everybody We should allow code to be natively pretty, and not rely on other tools to do the prettifying job - or not
On Thu, 21 May 2020 at 10:06, Thierry Parmentelat <thierry.parmentelat@inria.fr> wrote:
And then, suppose you can "solve" this chicken and egg problem by allowing it on the language. Get 2 or 3 years for people to catch on the language version that accepts it (how much code out there using 1_000_000 numric spacing already?) - then, supposing tools evolve along with it, ok, maybe in 4 years I can fire-up a "visual studio code" with a setup that allows me to hold a modifier key and pops-up a floating virtual keyboard with the unicode operators and type it almost seamlessly - how would that help me to type code snippets in e-mails or web-forms??? That is effectivelly locking people out of the language unless they have a "proper coding tool" - which likely would also be needed to display code properly. (may I remind you that some of these symbols are not even on the basic BMP so it is not feasible to use them in idle. That is, if you answered the question about which right arrow to use, asked above) Whereas the same effort for a 'magic symbol palette' plugin for vscode, pycharm or whatever is the IDE of the moment can support displaying the ASCII operators as unicode, in the way it is already possible with VI - while keeping the source code editable when I ssh into a docker container with misconfigured keyboard settings.
that’s an easy one, see the OP In [1]: print("\u2192”) → for all the rest, I am sorry, all the arguments about people having trouble inputing those characters are not relevant, it’s not as if using unicode characters was mandatory arguments about some people not seeing such code properly are of course much more valid but you seem to forget that using unicode characters is already possible in strings, and identifiers even so somebody else opened that box already … And if IDLE can’t do it, it’s a problem already I am convinced this will happen, one day or another, with or without Python, only question is when, not if

You are SERIOUSLY suggesting that typing 'Ctrl-Shift-U 2 1 9 2 <enter>' is easier for me than typing '->' as I do now!? And it remains easier if I use a different computer where I have to figure out or remember some different way of getting the Unicode code point into the editor? The goal of this being to wind up with source code that will render gray boxes for unknown character if I don't have the right font or the right display context? Even if *I* don't start using that special character (or others), I wind up having to edit and view code that other people have written, which means I need to deal with a tool stack to handle things that are hard to enter on most keyboards. As is... my editor looks like this. I don't type all those special things, except once in a configuration file. But the "prettification" is handled transparently when I type some ASCII sequences. -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On 21 May 2020, at 23:03, David Mertz <mertz@gnosis.cx> wrote:
You are SERIOUSLY suggesting that typing 'Ctrl-Shift-U 2 1 9 2 <enter>' is easier for me than typing '->' as I do now!?
that’s not how I’d do it; and I dont think I said or suggested anything to that effect
this thread seems to be obsessing on entering with the keyboard; that is not my point at all
As is... my editor looks like this. I don't type all those special things, except once in a configuration file. But the "prettification" is handled transparently when I type some ASCII sequences.
that’s nice ! it’s a real shame though, and a bit of a waste honestly, that everybody needs to cook their own brew of an editor to get there and primarily all I’m trying to say is that, one day, this will be a legal piece of code, so that we can share and enjoy exactly like this instead of in poor work-it-out-yourself ascii
On Thu, May 21, 2020, 5:51 PM Thierry Parmentelat < thierry.parmentelat@inria.fr> wrote:
I don't know how'd you'd do it on you particular OS, certain, operating system, editor, etc. But I very much doubt that's a key on your keyboard, so you'd have to do something akin to this. Maybe you have an old APL keyboard, but most people don't. The reason everyone is "obsessing" about how someone would actually make your symbol appear is that it won't happen magically by thinking it. So you are proposing and huge hit to ergonomics for everyone for no discernable benefit. that’s nice ! it’s a real shame though, and a bit of a waste honestly, that
everybody needs to cook their own brew of an editor to get there
I'm more than happy to share my vim conceal config. There plugin comes with something similar, but I've customized it to my liking. But other people would probably prefer something different... Which they can have. and primarily all I’m trying to say is that, one day, this will be a legal
piece of code,
I very much hope that will never happen. I'm 99% sure my hope will be realized. I will never be able to use a keyboard with 100k keys on it... Admittedly, I don't really understand Chinese character entry methods.

On 5/21/2020 5:51 PM, Thierry Parmentelat wrote:
I believe I speak for a significant majority of professional programmers when I say that eye-candy like this adds no value to the language for me. It gives me no new capabilities, I don't see it making me more productive, and we have syntax that works quite well already. What if I want to use a font in my editor that doesn't support →? Does that mean that I won't be able to edit some random bit of code I download? --Edwin
As is... my editor looks like this. I don't type all those special things, except once in a configuration file. But the "prettification" is handled transparently when I type some ASCII sequences. [image: Python-arrow.png]
The first screenshot (of completely pointless code I just typed to use a few symbols or sequences) used vim conceal plugin; also my particular configuration of what to substitute visually on screen. That approach lets entire patterns get replaced by... whatever you want. E.g. I replace `set()` with the empty-set symbol, but no one else is required to by the plugin if they don't want to (or the script Z/R for int/float, likewise). For comparison, I changed my system text editor to use JetBrains Mono Medium. The editor is called "Text Editor" on my system, but it's a rebranded gEdit, which is a pretty reasonable code editor. Someone else in the thread pointed to that font which uses ligatures to make composed characters. So it's not a substitution but simply another way of drawing some letter pairs. The result is in the attached screenshot. This approach is somewhat less flexible in that it gets exactly those ligatures that JetBrains decides you want. In concept, there is no reason this couldn't create a 'float' ligature that renders as a script R, for example. But that is not a combo JetBrains decided to use. The main point of this, is that the code is still just plain ASCII, it just happens to look "fancier." It requires no plugins, and it does not require a JetBrains IDE or editor. I haven't tried every editor, but I believe that most or all that use GUI fonts will work fine. Not sure about ligatures and Linux terminal, someone can try it. -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.

On Fri, May 22, 2020 at 11:21 AM David Mertz <mertz@gnosis.cx> wrote:
The ability to pretty-ify code in this way is inspiring; I'm going to have to look into it. There could be many other IMO more useful/helpful pretty-fication ideas out there that could not be accomplished with unicode, or simple "replace these symbols with another one" configurations. Couple of examples: 1. I've often thought it would be nice if the parameter type-hints sort of floated underneath (or maybe above? underneath makes more sense to me) the parameter names, rather than using the colon at all. Or, perhaps using colors to specify types - Indigo for ints, scarlet for strings, fuchsia for floats, perhaps italics for optionals, that sort of thing. 2. Another really nice improvement, so that I could share raw, copy-and-pasted pretty-ified code with my professional engineering coworkers (as a set of engineering calculations), would be for the editor to detect mathematical equations and display them that way. Like: from scipy.integrate import quad def f(x, i, j, a, b): return quad(a*x**2 + b , 0, 1, args=(a,b)) ...would be displayed *automatically* (without having to muck about with sympy), and able to be copied, as: [image: image.png] ( latex code: $f=\int_{i}^{j} a x^2 + b \,dx$ ) *BACK ON TOPIC:* The point of giving the examples above is not to rabbit trail, but to agree with others who have basically said going down this particular road-- putting a lot of effort into including fancy unicode symbols as part of the syntax-- would be a mistake. IMO, a big reason it would be a mistake is, it doesn't bring *ENOUGH* to the table for making things look nicer-- there is so much more that could be done to make reading python an even more pleasurable experience beyond using unicode symbols. And not only that, make it useful to more people beyond the circle of those who actually even *KNOW* they are reading "python" (as opposed to just English pseudocode describing mathematical/algorithmic processes). --- Ricky. "I've never met a Kentucky man who wasn't either thinking about going home or actually going home." - Happy Chandler
On Thu, May 21, 2020 at 04:04:20PM +0200, Thierry Parmentelat wrote:
If we still have to come up with a good looking, unambiguous per ASCII digraph or trigraph symbol, then what does the Unicode symbol grant us? The moment we say "why bother with the ASCII digraph, everyone can use the Unicode symbol?" then we are proposing that it be mandatory. Even if it is not mandatory, people will want to use the same symbol throughout a project. Once somebody allows → in a module, they're probably going to require → and reject patches using -> Now of course people can *work around this* by copying and pasting, symbol palettes, etc but it does add to the friction of using Python. If the benefit isn't greater than the amount of friction, the overall experience is worse. Allowing Unicode symbols expands the range of operators and special symbols we can use, and potentially makes it easier to add new language features. But if we have ASCII fallbacks for every one of those, then it doesn't add any extra power or functionality to the language, it just adds complexity for minimal benefit.
Indeed, this is true, but neither identifiers nor strings carry syntactic meaning. We don't has to ask what the identifier straß means to understand the code, at worst we could treat it as an obfuscated name like xyz. Likewise for string constants. Mandatory or not, giving syntactic meaning to Unicode symbols (as opposed to merely allowing them in indentifiers and strings) will lead to a massive increase in community questions: "What's the meaning of that curly less than sign ⊰ in Python?" or more likely: "What's with all the small boxes '' in Python code?" (assuming they even display at all, in my mail client the above symbol displays as a space; they could easily also display as �). So unless you're volunteering to personally seek out and answer all those questions, this can only increase the amount of community support needed for not very much benefit at all. We have had non-ASCII identifiers for, oh, 15 or 20 years now, but still the vast bulk of identifiers use nothing but ASCII, even when not written in English. At least for projects which have much visibility in the public, English-speaking internet :-) (I expect that people and companies use a lot more non-ASCII in their private code. And there is an interesting little project called ChinesePython that translates the language into Chinese, but I don't know how successful it is or if it is even still maintained.) So the cost of allowing non-ASCII identifers is much lower than the cost of non-ASCII symbols; even if the benefit is low, it can still be a win for non-ASCII identifiers and strings, while the cost:benefit ratio end up negative for non-ASCII symbols.
I am convinced this will happen, one day or another, with or without Python, only question is when, not if
*shrug* If you are serious about persuing this, you could start by doing a survey of what other languages allow non-ASCII symbols, and report on their experience and popularity. You might also check out Coconut, which is superset of Python that compiles down to Python. Another option might be to provide a pre-processor that translates (say) → into -> for example. We might have .pyu files (u for unicode) translate into .py files before being compiled or run. A good practical project for someone seriously interested in advancing this idea would be a translator that goes in both directions, from pure ASCII to non-ASCII. (Remember that string literals, docstrings and comments shouldn't be touched.) -- Steven
On Thursday, May 21, 2020 9:20 AM Joao S. O. Bueno [mailto:jsbueno@python.org.br] wrote
It wouldn't. No matter how slick of a Unicode operator insertion setup you have, it still is quicker and easier to type ->. I fail to understand how suggesting that all new python programmers use a slower, more complex entry method can be perceived as more "user-friendly". Especially since they have to learn what -> means anyway. Not only that, not all fonts support all Unicode characters. There would need to be a FAQ section in the docs on fonts that work with Python. --Edwin

Executive summary: I'd like to make three points. 1. Accessibility matters, and I think this change would be inaccessible to users of screen readers. 2. Yes, a variety of tools imposes a burden, but also confers benefits. 3. There's no such thing as "pretty source code." There are only tools that display source code beautifully. Down and dirty details: The first is new to this discussion: Let's not make life more annoying for the accessibility developers and the people who *need* accessibility accommodations. Not all visual puns are audible puns. "→" looks like "->", but "Unicode U+2192 RIGHTWARDS ARROW" sounds nothing like "HYPHEN GREATER-THAN". (I'm guessing at the pronunciation, I don't use a screen reader myself. OK, probably the reader just says "RIGHTWARDS ARROW" or even "RIGHTARROW", but it's still not close to the same.) At the very least, we should do a case-by-case check when we want to pun this way, and also ask an accessibility expert (better three) about whether screen readers make this connection, and if not, whether their users would be able to. Second, about Tower-of-Babelonian tool proliferation: Thierry Parmentelat writes:
This situation that has no chance to be sustainable obviously *is* sustainable. It's been this way for as long as I've been using computers (daily use for work or study since 1979). I very much doubt it is going to change, ever, because tools are personal. Yes, it causes a certain amount of burden for everybody, but it also provides great benefits for everybody, or network externalities would impel us to accept a common set of tools.
We should allow code to be natively pretty, and not rely on other tools to do the prettifying job - or not
There's no such thing as code being "natively pretty". Code (source code) is a sequence of bits grouped into bytes grouped into characters grouped into statements grouped into a file. I can't see the pits on a BD or the microwaves in a wireless connection, and I doubt you can. There are software tools doing a prettifying job every time source code is displayed, printed, or read out loud, and a mass audience language like Python needs to adapt to the tools of the mass audience. Yes, we humans can help relatively "dumb" tools do a better job of displaying pretty code (for example, "significant whitespace"), but it's the quality of tool that matters most. Fred Brooks had a good essay on "sharp tools", slightly off-point, in *The Mythical Man-Month*. (I'm pretty sure of the citation but unfortunately my copies of MMM are all at school for access by my students. :-) He advocated having a tool-building specialist on his "surgical team" of (proprietary) developers, but in the open source world, we all publish our tools, which is both the glory and the disaster of something like Emacs. There are also habits that won't change -- even if *you* habitually use one of the many right arrows in Unicode instead of "->", most of us will continue to touch-type "->", and you're going to have to read it. And code is eternal: 20 years from now, somebody's going to be upset about some misfeature in the stdlib, and they're going to have to read it. (Well, maybe not "->", depends on whether they need to look at the stub files, which is a "probably not", stub files are more useful to the Python compiler than to humans most of the time.) If you want all your Python code to use non-ASCII characters in the syntax whether you wrote it or not, *your tools will have to do it for you*. Steve

On Thursday, May 21, 2020, at 8:48, Joao S. O. Bueno wrote:
Input _is_ hard or rare. Deal with it.
[...]
It seems that the only sane thing to do is to use a baseline of well established symbols on source code [...]
According to https://en.wikipedia.org/wiki/Digraphs_and_trigraphs, Python is already on thin ice by using the full set of ASCII characters. I wonder how many non-native English speakers have given up on Python because of that. I'm old enough to remember terminals that didn't support lower case letters, let alone "curly braces," and to have used dozens of different keybpards with all sorts of "common" symbols (e.g., [, {, /, \, <) in all sorts of different places. I had a customer who was old enough to use upper case letter O for zero and lower case letter l for 1 because she was old enough to have learned to type before typewriters had number keys; that made a real mess of sorting street addresses. But I digress. Sort of. Yes, some characters are harder to enter for some people at some times. We're all different, and so are our computing tools. Imagine that. When I studied Koine Greek in school (c. 2003 or 2004), I learned what I had to to type up my homework. Was I fast? No, not really. Was I fast enough? Yep. I'm not for full blown, use every Unicode character we can, but I'm not against using characters outside the ISO 646 invariant character set, either. Using π or ϖ as an alias for math.pi? Not too bad. Matched pairs of left/right quotation marks? Maybe, but not without a lot more thought. Different right arrows for different operations? That's asking for trouble. -- “Atoms are not things.” – Werner Heisenberg Dan Sommers, http://www.tombstonezero.net/dan
On Thu, May 21, 2020 at 09:43:33AM -0400, Dan Sommers wrote:
How old was your customer? The Hansen Writing Ball, first commercially sold in 1870, had digit keys: https://historythings.com/life-changing-invention-typewriters/ The first recognisable typewriter, the Sholdes and Glidden Type-writer (note the hyphen!), was sold in 1864. Here's a photo of one: https://historythings.com/wp-content/uploads/2016/07/9999006136-l.jpg The photo isn't clear enough to see the keys, but there are 44 of them. Since the Sholdes typewriter didn't have lowercase letters, it's hard to imagine what the remaining keys after the uppercase letters and punctuation marks were if they weren't digits. (44 keys would nicely match 26 letters, 10 digits, space and seven punctuation marks.) And this 1903 Olympia typewriter clearly has digits: https://historythings.com/wp-content/uploads/2016/07/SAM_2381_clipped_rev_1.... It is certainly true that many people of a certain age used to interchange 0 and O, and 1 and l, but I don't think it had anything to do with learning to type on typewriters without digits. What did they use when they needed the digits 2 through 9? -- Steven
On Friday, May 22, 2020, at 8:28, Steven D'Aprano wrote:
https://historythings.com/life-changing-invention-typewriters/
I can see 0, 2, 3, 4, 5, and 6 clearly. I can't see a 1, although it appears that the key between the 0 and the Q is missing its label.
The photo is not clear, but I can convince myself that the keys on the top row start at 2 and run through 9 and 0. Still no 1.
And this 1903 Olympia typewriter clearly has digits:
https://historythings.com/wp-content/uploads/2016/07/SAM_2381_clipped_rev_1....
Still no 1.
Okay, "before typewriters had number keys" is obviously wrong. Those pictures support "before typewriters had 1 keys." -- “Atoms are not things.” – Werner Heisenberg Dan Sommers, http://www.tombstonezero.net/dan

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
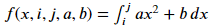{kind=link}
The old images I find lack the '1', but not the '0'. What model was this you had? On Sun, May 24, 2020 at 1:48 PM Rob Cliffe via Python-ideas < python-ideas@python.org> wrote:
-- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
{kind=link}
On 2020-05-21 05:48, Joao S. O. Bueno wrote:
Maybe long ago. My terminals support even color emoji, have for years, and are all free. The only thing I've seen recently that doesn't is the Linux console, which I use rarely for admin tasks. (Oddly enough, it does handle right arrow properly.) fbterm is an option there for those wanting more. Even Windows 10 has gotten in on the act terminal-wise. If you're still on XP or 7, it's way past time to upgrade. -Mike
On Thu, 21 May 2020 at 18:15, Mike Miller <python-ideas@mgmiller.net> wrote:
If you format all your computers from a single image, maybe. My pet project over the last year is a unicode art library, I use a Ubuntu 2018 and a Fedora system daily - on my personal machine, which is the Fedora, I've installed all available font packages an their kitchen sink. Still, emoji support varies wildly across terminal programs and even across the same terminal program in Ubuntu and on Fedora. Although, yes, it is likely that "older" glyphs like unicode mathematic symbols will be present in all of then and render . However, that does not mean it will render ok as a single-cell character in a mono-spaced font - as the character "east asian width" property is marked as "A" (Ambiguous), and may vary according to the installed font - even Qt5, perhaps the most sophisticated windowing toolkit available in the World, is severely bugged when displaying non single-width characters in a monospaced cell character environment such as coding space. (Of course, it may be that native Windows character and widget engines or Mac OS's are better in this particular requisite)
I consider this thread to be moot at this time - I am just answering this e-mail because you answered me directly - but I had seem no strong support, I had seem you not answering direct questioning about how this will make things harder to learn and use but for writting down your own rationalizations on it. I'd suggest you'd just pause for a bit, and read carefully some of the other e-mails, if mine, focused mainly technical infeasibility of even typing or displaying that character, and consider these questionings for real - not with the ready made answers you have ready in your mind. I am recording a video series trying to present Python programing to absolute beginners - and to keep things timely, the ambiguity between two valid quote types is already a _pain_ - which I simply try to avoid by making consistent use of just one quote type. But after a 4 hour crash course, no one that is not already familiar with coding, could come up comfortable with using both ' or " interchangibly unless I spend 30 minutes focusing ont that.
On Fri, May 22, 2020 at 11:02 PM Joao S. O. Bueno <jsbueno@python.org.br> wrote:
Seriously? In primary school English class I learned that you can nest quotations by using different quote characters. Maybe we need to consider that first-grade English (or whatever your native language is) should be considered a prerequisite for coding, and just teach those kinds of concepts (including words like "singular" and "plural", since they're so helpful for diagnosing bugs). ChrisA
On 2020-05-22 05:57, Joao S. O. Bueno wrote:
Yes, though I'm sure no one is seriously proposing using wide, or combining chars, or other obscure things. Just some useful symbols from around the 0x2000 range of the BMP, which are widely/universally supported by now. To be honest, keyboard entry is the least interesting aspect of this. To reiterate, we found a zero-ongoing-effort entry method, typing and leaving " -> " in the source, and "upgrading it" to " → " with a formatter or other tool when desired. That's assuming you already have tools set up. I recommend them, but they would not be required obviously and neither would the upgraded character for compatibility reasons. More importantly, does it help readability? I think it does, however not strongly. I'm perhaps +0.5 on a few of these characters. Word processors do upgrades to hyphens, for example, to make the resulting doc more readable. Is that kind of thing useful for Python? -Mike

On 22/05/2020 18:21, Mike Miller wrote:
Generally speaking, no. Editors that do things for you behind your back are an open invitation to bugs. I find that for most word processing that I do, I have to turn off the automatic translation/correction/whatever to prevent them from incorrectly rewriting my input. Prettifying code so that it no longer runs when you cut and paste is one example; more often I find they mangle the capitalisation of company names, product ID and so forth. I would hate to find an editor starting to do similar things for me. Sometimes even basic things like "electric modes" (auto-indentation after you hit RETURN) can make more work for you! -- Rhodri James *-* Kynesim Ltd
On Wed, May 20, 2020 at 8:36 AM Thierry Parmentelat < thierry.parmentelat@inria.fr> wrote:
= might be an improvement because that's a symbol learned in school, but
This seems to be the main (only?) argument beyond it being pretty - that it's somehow easier for beginners to deal with. I think it's the opposite. Many (probably most) people are going to come across a unicode symbol having previously only encountered ASCII symbols and probably thinking that was the only option. That includes all currently experienced Python programmers who aren't up to date on the latest news, and all beginners who learned using anything but the most up to date material. Even after this feature has been around for a while, many (most?) new learning materials will not include unicode symbols because authors don't want to go through the extra effort to write those symbols. And if you think Python is ASCII only, then when you see unicode, you'll think something is wrong. Someone's editor magically transformed `->` or the website has some overly clever rendering or something. That would be my reaction if I saw such code now. Indeed, if I copied the code and ran it with the wrong version of Python, I'd get the expected SyntaxError. Overall it just creates confusion. If you try to teach people from the beginning that both options exist, then that just slows down learning. Learning coding is hard enough for most people without being distracted by minor details about syntax. If someone thinks that special unicode symbols are the only option, or if they know they're optional but get the impression that they're preferred and feel pressure to use them, then typing code becomes a pain. In particular beginners often start coding with a basic editor such as notepad so that they aren't distracted by unneeded features or reliant on tools which do too much work for them that they need to learn on their own ( https://cseducators.stackexchange.com/a/634). So they won't have fancy IDEs to insert symbols for them, and must rely on their OS. Finally, in what way does it make it easier for beginners? `->` is pretty clearly meant to represent an arrow, but beyond that an arrow is not particularly informative. The student would still need to learn that → in that particular context is a type hint for the return value, which is not immediately obvious. Whatever difficulties they may have learning that concept, the symbol used is not going to make much difference. ≥ instead of ultimately the student still needs to learn what `>=` means as it will be used most of the time.
On 21 May 2020, at 15:45, Alex Hall <alex.mojaki@gmail.com> wrote:
Many (probably most) people are going to come across a unicode symbol having previously only encountered ASCII symbols and probably thinking that was the only option. That includes all currently experienced Python programmers who aren't up to date on the latest news, and all beginners who learned using anything but the most up to date material. Even after this feature has been around for a while, many (most?) new learning materials will not include unicode symbols because authors don't want to go through the extra effort to write those symbols.
I’m having a hard time with statements like
Many (probably most) people are going to come across a unicode symbol having previously only encountered ASCII symbols
clearly the experienced Python programmers are not the main target here our 7-year old schoolboys are used to typing é's and ç and ü’s and À’s, and this is Europe, not China, so... what was the point of defining unicode in the first place then ?
On 21/05/2020 15:09, Thierry Parmentelat wrote:
clearly the experienced Python programmers are not the main target here our 7-year old schoolboys are used to typing é's and ç and ü’s and À’s, and this is Europe, not China, so...
You say that, but it is a source of endless annoyance to me that the Linux UK Keyboard doesn't offer AltGr shortcuts for a c-cedilla. It makes addressing my colleague François quite a pain :-/ -- Rhodri James *-* Kynesim Ltd
Yeah well, if the whole english-speaking keyboard industry shares the feelings expressed on this thread, it’s no wonder ;-) I suggest you take a look at the US-international (not sure there is a UK-international) input method, that I think is available on all 3 OSes in one form or another, and that is cool for that sort of things (the keyboard I am using right now is a regular qwerty keyboard with no alt-gr modifier) and the other way around I can assure you that coding with a regular French keyboard - the infamous AZERTY thingy - is something you don’t want to have to do; you’d need alt-gr to enter a mere { - and digits come through shift- !
On Thu, May 21, 2020 at 4:09 PM Thierry Parmentelat < thierry.parmentelat@inria.fr> wrote:
What I mean is that they would only have seen ASCII symbols used for Python syntax i.e. not counting the contents of strings. Currently that's the experience of 100% of all Python coders. That percentage will drop a little if and when this feature is announced, but not much, and from there it can only decrease gradually. Again, if I saw a unicode arrow used as syntax on GitHub or something in the wild right now, I would think it's an error, which incidentally would be correct. Wouldn't you? That will be the experience of anyone who sees this before learning about it, and that will always include some beginners.
On 21 May 2020, at 16:18, Alex Hall <alex.mojaki@gmail.com> wrote:
What I mean is that they would only have seen ASCII symbols used for Python syntax i.e. not counting the contents of strings.
and identifiers
Currently that's the experience of 100% of all Python coders. That percentage will drop a little if and when this feature is announced, but not much, and from there it can only decrease gradually.
Again, if I saw a unicode arrow used as syntax on GitHub or something in the wild right now, I would think it's an error, which incidentally would be correct. Wouldn't you?
yes, like I would have taken a walrus operator for a syntax error just a couple years ago maybe; things change..
That will be the experience of anyone who sees this before learning about it, and that will always include some beginners.
the only thing that beginners know is: they don’t know much, I don’t see them necessarily jumping to conclusions
On Thu, May 21, 2020 at 4:36 PM Thierry Parmentelat < thierry.parmentelat@inria.fr> wrote:
I think you make a good point, but it's not quite the same. If I see: ``` if (match := re.match(...)): x = match.group(1) ``` and I don't know what `:=` means, I pretty much have to Google it, guess, or otherwise learn. I'm not going to think that a colon was accidentally added to `match = re.match(...)` because that's not valid syntax either. I *might* think it's supposed to be `match == re.match(...)`, but that would just raise more questions - `match` is an undefined variable, and you don't compare match objects. Besides, how did this mistake happen? Didn't this person run their code? If I see: ``` def foo() → Bar: ``` I'm going to think that either: 1. Some fancy rendering is going on, like the ligatures some have been talking about. Right *now*, that's probably the most likely hypothesis, considering that some people do this in their editors. If it was actually valid syntax, I'd be surprised when that reasonable guess turned out wrong, especially if I paste it somewhere and get a SyntaxError with my slightly outdated Python. Which leads me to the next guess... 2. In the process of transferring from the editor to a blog/email/document/etc the code has been mangled. I don't know exactly how, but someone was complaining on this list recently that plain ASCII quotes had turned into fancy matching quotes which lead to a confusing error message. So it seems plausible that `->` got transformed somehow. It's not similarly plausible that `==` randomly became `:=`.

21.05.20 16:45, Alex Hall пише:
But in my school I learned ⩾, not ≥. It was used in USSR and I believe in other European countries (maybe it is French or Germany tradition?). If Python will become accepting ≥ as an alias of >=, I insist that it should accept also ⩾. And ⊃, because it is the symbol used for superset relations for sets (currently written as >= in Python). And maybe other national or domain specific mathematical symbols. Imagine confusion when
=, ≥, ⩾ and ⊃ are occurred in the same program.
On Thu, May 21, 2020 at 06:48:55PM +0300, Serhiy Storchaka wrote:
As far as I am aware, there is no mathematical difference between the two greater-than-or-equal operators ⩾ and ≥ it is a purely stylistic issue, just as some fonts use two lines in dollar signs and some only one. I don't know why Unicode gives them two different code points, but if I were a betting man, I would put money on it being because some legacy character set provided them both. (One of the motivations of Unicode is to allow the round-tripping from every common legacy charset without loss.)
An annoying thing about superset and subset operators is that mathematicians don't agree on whether the superset symbol ⊃ is strict or not. This is why we also have unambiguous symbols ⊇ (superset-or-equal) and ⊋ (strict superset not equal).
Imagine the confusion if somebody had variables spam, Spam, sPAM, SPam, sPAm. Or worse, SPΑM, SPАM and SPAM. *wink* Let's not worry too much encouraging people's bad habits. People can write obfuscated code in any language. I am sure that before this is a problem, linters and code formatters like black will keep it under control. -- Steven
On 22/05/2020 20:40, Steven D'Aprano wrote:
Imagine the confusion if somebody had variables spam, Spam, sPAM, SPam, sPAm. Or worse, SPΑM, SPАM and SPAM.
Randall is way ahead of you. https://xkcd.com/2309/ :-) -- Rhodri James *-* Kynesim Ltd
Hello, On Mon, 18 May 2020 02:39:27 +0100 MRAB <python@mrabarnett.plus.com> wrote: []
To make it clear, the talk is about "better", not "existing" annotation syntax, which is a square (literally) peg in a round hole. With PEP 0563, there's totally no need to wrap everything in square brackets, and atrocities like __class_getitem__ can be treated like an implementation detail of a particular Python implementation (CPython, that is). With PEP 0563, while evaluating annotations, one can just pass to eval() a suitably constructed "globals" dict, to enable any operators on any symbols (which would be represented by objects, not classes), or just operate on AST with even finer level of control. -- Best regards, Paul mailto:pmiscml@gmail.com
Hello, On Mon, 18 May 2020 13:25:50 +1200 Greg Ewing <greg.ewing@canterbury.ac.nz> wrote:
Well, I don't say "ideal", I say "better". The point is that the world learned long ago that any type of information can be represented with just recursive parens: (foo (bar 1 (2) 3)), but some variety in punctuation helps mere humans among us.
With the idea that someone may confuse ":=" for "<-", so we can swap result and argument types comparing to their natural/intuitive order? Well, I guess that's not what I'm talking about. But we indeed can treat ":=" as a function operator in annotations, and write: (int) := str Actually, we don't have to use funky novelties, and mere "-" looks better as a lookalike for "->" than ":=". The following works as expected: ========= from __future__ import annotations def foo(f: (str, int) - int = map, seq: list = None): pass print(foo.__annotations__) import ast print(ast.dump(ast.parse(foo.__annotations__["f"]).body[0])) ========= I'd still consider it a better idea to just make "->" an operator on the AST level. Can stop there, because realistically (or sanely) PEP-0563 annotations would be parsed via an AST (example above). But if there's desire to assign some semantics to it, it can be that of making a tuple, with precedence just above "," operator, so "foo -> bar, 1 -> 2" would evaluate to ((foo, bar), (1, 2)). Worst-case, can add a __rarrow__ dunder.
-- Greg
-- Best regards, Paul mailto:pmiscml@gmail.com
On 24/05/20 10:26 am, Paul Sokolovsky wrote:
No, with the idea of making use of an already-legal expression and not introducing any new syntax into the grammar.
But that would be backwards with respect to the flow of data when := is used for assignment. Also, it is not currently legal syntax when there is more than one argument, because := doesn't support unpacking. -- Greg

IMHO, if `->` becomes an operator with semantics, then `[t1, ..., tn] -> tr` should mean `typing.Callable[[t1, ..., tn], tr]`.

I would like to comment that the graphical presentation, at least in IDEs/where the font can be controlled, can be achieved using fonts: https://stackoverflow.com/questions/41774046/enabling-intellijs-fancy-%E2%89... On Sun, 17 May 2020 at 13:26, Thierry Parmentelat < thierry.parmentelat@inria.fr> wrote:
{kind=link}

I would like to comment that the graphical presentation, at least in IDEs/where the font can be controlled, can be achieved using fonts:
Precisely. Nicer than the arrow symbol, it would be to type "-" + ">" and get an arrow visually. The same can be done about getting >= as a single symbol and == and === and <=> as single symbols. It seems like a matter of code presentation, not code itself.
Wouldn't it be better implemented on an editor as a display option instead of changing python? Because, as I understand, it's an issue of appearing nice on screen, rather than storing (and parsing) `'\u2192'` as an alias to `'->'` on type hints. It *would* look nice, though
On Sun, May 17, 2020 at 2:24 PM Thierry Parmentelat < thierry.parmentelat@inria.fr> wrote:
I'm not a fan of the idea, just in case the code ends up being copied somewhere it can't be rendered properly. If we consider the arrow, what about ≤ instead of <=, ≥ instead of >=, ≠ instead of !=, × instead of `*`, and math.π instead of math.pi?
math.π instead of math.pi
That is already possible, just not done in the standard library, no? Your point still stands, but it's rather different to your other examples, which are actual changes to syntax. With regards to the actual proposal, I quite like the idea of being able to use them, but I don't think it's worth portability issues - style guides would just end up forbidding it anyway. They're also hard to type, and of course,
There should be one-- and preferably only one --obvious way to do it.
On Sun, 17 May 2020 at 13:32, Alex Hall <alex.mojaki@gmail.com> wrote:
Hello, On Sun, 17 May 2020 14:31:34 +0200 Alex Hall <alex.mojaki@gmail.com> wrote: []
If we consider the arrow, what about ≤ instead of <=, ≥ instead of
=, ≠ instead of !=, × instead of `*`, and math.π instead of math.pi?
Before this goes too a big shaky bikeshed over almost nothing, let me point out that if you're looking to improve something in type annotations, I would suggest to look for true ugliness there. Something like Callable[[Dict[str, int], Sequence[Foo]], Dict[PrimaryKey, List[int]]]. That's rather unreadable. Actually, let me just quote https://docs.python.org/3/library/typing.html#typing.Callable
Callable type; Callable[[int], str] is a function of (int) -> str.
Lolwhat? If it's a function of "(int) -> str", then it should be written just about like that. With https://www.python.org/dev/peps/pep-0563/ , a lot of things which weren't previously possible, are now possible. Somebody should start thinking how to take advantage of that, up to allowing "(int) -> str". Which is apparently not possible currently, as while "evaluation" is postponed, it still should parse eagerly as Python syntax. But even {(int): str} is a better type annotation for a function than Callable[[int], str]. And if we e.g. talk about making "->" a special operator which would allow it to appear in other contexts than function definition, "(int) -> str" (and other interesting annotation syntaxes) would be possible. -- Best regards, Paul mailto:pmiscml@gmail.com
totally agree on the awkwardness :-)
would be nice too - although this is orthogonal to my initial proposal, right ?
well, {(int): str} already means something; are you suggesting that an expression like this could have different meanings whether it’s in an annotation or not ? that sounds scary ...
again, that’s be quite cool for typing function parameters :)
On 18/05/20 1:59 am, Paul Sokolovsky wrote:
I don't agree -- it looks more like some kind of dict type, and would be better reserved for that purpose.
And if we e.g. talk about making "->" a special operator which would allow it to appear in other contexts
Or maybe we could leverage the new walrus operator and write str := (int) -- Greg
I'm going to ask that people please try to keep this thread on-topic to the question of using Unicode characters directly for things that we currently use two ASCII characters to represent. Other ideas that spring up from this question are totally welcome to be done as new threads of discussion. On Sun, May 17, 2020 at 6:42 PM MRAB <python@mrabarnett.plus.com> wrote:
On Tue, May 19, 2020 at 11:31 AM Brett Cannon <brett@python.org> wrote:
Indeed -- and also: please refer to earlier conversations on this list and elsewhere -- this is NOT a new idea! I'd suggest also that the question at hand be more global: Should Python be extended to allow non-ascii characters in syntax? Rather than one or two specific ones. ON a related note, another way to get "Nicer" multi-character operatores is lignatures. Jet BRains has put out a font with a pretty full set: https://www.jetbrains.com/lp/mono/#ligatures (you can use that font with most Editors / IDEs -- works great with Sublime, for instance) That way, it's still two ascii characters, but it looks like one nifty symbol in your editor. Maybe no need to complicate Python? ;-) -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
On 19 May 2020, at 20:27, Brett Cannon <brett@python.org> wrote:
I'm going to ask that people please try to keep this thread on-topic to the question of using Unicode characters directly for things that we currently use two ASCII characters to represent. Other ideas that spring up from this question are totally welcome to be done as new threads of discussion.
Thank you for re-focusing the discussion I’d like to express the strong opinion that anything related to a particular IDE is not the right answer I’m not going to switch to jetbrains just to get ligatures or fancy rendering, am I ? would you ? Plus, it’s not only IDE’s, I’m prominently concerned by beginners and students, who start reading code on sources like github, or teaching websites, or notebooks; one cannot expect all these stacks to go this extra mile, that is just not right IMHO back to the point as phrased by Brett: I reckon the languages communities have mostly so far stuck to ASCII, probably for good reasons, but the thing is Unicode has been around for quite some time now, and can be deemed generally available so why not take full advantage of it ? It is my feeling that part of the awkwardness of the typing annotations, rightfully outlined above, is due to the narrow set of characters at our disposal, hence the awkward Iterable[] (this one at least clearly deserves better IMHO), and Dict[,] likewise There has to be nicer and more legible ways to express all these I tend to start the discussion on typing annotations because they are more recent, and clearly more in need of improvement however like Alex Hall pointed out, using dedicated symbols like
quoting ≤ instead of <=, ≥ instead of >=, ≠ instead of !=, would make a lot of sense as well
I also reckon it is still cumbersome to simply enter Unicode characters from a keyboard sometimes; I guess if the big players were located in other countries that would maybe be different But that will change over time, no matter the speed, some day that will be for granted So again maybe 2020 is the right time to break that barrier ? === PS. it looks like one reasonable thread to spawn off from the earlier exchanges here is about the definition of an arrow operator for defining function types I’ll leave it to the person who originally extended the discussion in that direction :)
On Wed, May 20, 2020 at 4:36 PM Thierry Parmentelat <thierry.parmentelat@inria.fr> wrote:
The Dvorak keyboard was invented nearly a hundred years ago. How's it looking as a viable alternative? If you think that a keyboard with fancy arrows on it will take off any quicker, you're extremely hopeful. MUCH more practical will be to use vim conceal etc, leave your source code unchanged, and just change the way it looks to you. There are similar features available in a number of editors. ChrisA
On 05/20/2020 12:44 AM, Chris Angelico wrote:
On Wed, May 20, 2020 at 4:36 PM Thierry Parmentelat wrote:
Well, 25 years ago I had to write my own Dvorak device driver for use with MS-DOS, now it's included in at least Windows and Linux (a Dvorak mapping, not my device driver). So much more viable. :)
If you think that a keyboard with fancy arrows on it will take off any quicker, you're extremely hopeful.
I wouldn't be surprised if it did, although a standard set of keyboard shortcuts is more likely.
I'll have to look into that. -- ~Ethan~
On Thu, May 21, 2020 at 1:48 AM Ethan Furman <ethan@stoneleaf.us> wrote:
I'm pretty doubtful. Keyboards seem to be LOSING keys, not gaining them. Which is a trend that I deplore (where are my F1-F12 keys?? and I doubt I'll ever see F13-F16), but I still cling to the hope that not ALL keyboards are going that way. ChrisA
On Thu, May 21, 2020 at 01:58:29AM +1000, Chris Angelico wrote:
On Thu, May 21, 2020 at 1:48 AM Ethan Furman <ethan@stoneleaf.us> wrote:
Indeed. The ultimate expression of this trend is, of course, the smartphone, where you have no physical keyboard at all. Even if people don't do their for-real development on their smartphone, they will insist on replying to emails, messages, Stackoverflow questions etc on them, and they won't necessarily have [insert name of app here]. So unless the symbol shows up on the smartphone's native keyboard emulator people won't be able to use it at least part of the time. -- Steven
On 2020-05-20 00:44, Chris Angelico wrote:
If you think that a keyboard with fancy arrows on it will take off any quicker, you're extremely hopeful.
While I'm not sure how useful this is in the long run, the oft mentioned drawback of "hard to type/view" Unicode chars isn't as insurmountable as some think: - Word processors have had a palette to insert symbols for decades. - Editors have had "snippets" for perhaps almost as long. - Code formatters such as "go fmt", yapf, black, etc could update them. - All maintained OSs support a great majority of Unicode, with font support. - AltGr and Compose keys are available. I've been using Unicode everywhere for about a decade—it's time to retire the argument that input is still hard or rare. Dedicated keys are not really necessary. -Mike
On Wed, May 20, 2020 at 01:13:10PM -0700, Mike Miller wrote:
Not everyone is programming in a GUI environment all the time, and even when they are, GUI "insert symbol palettes" are of greatly variable quality.
- Editors have had "snippets" for perhaps almost as long.
Sure, but like the "insert symbol" command, needing to use a snippet adds friction. Even in the best case, think of the difference between: * type a minus sign `-` * use a snippet or symbol palette to find and insert a `→` symbol.
- Code formatters such as "go fmt", yapf, black, etc could update them. - All maintained OSs support a great majority of Unicode, with font support.
Which is still patchy, but getting better. I still come across monospaced fonts where certain symbols have annoying "off by one pixel" display bugs, or are missing the exact symbol you need. I use a lot of arrows in my maths equations, and they are invariably too small, too big or placed too close to the baseline, depending on the font. At smaller font sizes, the arrow head tends to look like "grit on the monitor". In a word processor, I can manually tweak that, but in a programming environment using a text editor, there's not much I can do except search for that One Perfect Font. Still not found it after decades of searching.
- AltGr and Compose keys are available.
And require the editor or OS to support it, a keyboard to have the right compose key, and most importantly of all, for the user to remember a bunch of esoteric key codes to get the symbol needed. I can remember Win key .. to give MIDDLE DOT · but it's the wrong dot, I need DOT PRODUCT ⋅ (which unfortunately is displayed as a missing- character glyph in my email client and editor). But I have no idea what key combination I need to press to get DOT PRODUCT. Last night I had one of my students ask me how they are supposed to type maths symbols during an online test if they can't google for it and copy it from some website. I didn't have an answer. So what is the key code for the → symbol?
I've been using Unicode everywhere for about a decade—it's time to retire the argument that input is still hard or rare.
I can sincerely say that I am very happy that your experience is so good, but I'm also exceedingly jealous of it. I don't think your experience scales to the majority of people. -- Steven
I guess we’re getting to the gist of it I was not proposing that everybody MUST enter → I was suggesting that some people MAY want to do that so their code looks prettier in contexts where no additional intelligence is available to embellish things Do we want to get stuck in the 20th century just because everything is not yet perfect in a non-purely ASCII world ?
Hello, On Thu, 21 May 2020 13:26:32 +0200 Thierry Parmentelat <thierry.parmentelat@inria.fr> wrote: []
Do we want to get stuck in the 20th century just because everything is not yet perfect in a non-purely ASCII world ?
Short answer: yes. Long answer: ASCII was defined in 1963 and hasn't won over yet, e.g. EBCDIC is alive and kicking: https://en.wikipedia.org/wiki/EBCDIC . Ergo, 50 years isn't enough for a character encoding to become truly pervasive. I suggest we wait and see whether 100 years makes a difference, which in the case of Unicode means: let's talk again closer to 22th century. [] -- Best regards, Paul mailto:pmiscml@gmail.com
On 2020-05-20 14:56, Steven D'Aprano wrote:
Not everyone is programming in a GUI environment all the time
Well, I gave a number of examples to show there are many ways to do it. Not every example will work well for everyone. The best that works for your platform and tools should be chosen. There are numerous others I didn't bother to mention.
- Code formatters such as "go fmt", yapf, black, etc could update them.
I think this is the choice with the least effort required, a code formatter. For example, a tip was given to me that you can save keystrokes writing Python by using single-quotes exclusively (which I do) then let black change them to double later. I still come across
monospaced fonts where certain symbols have annoying "off by one pixel" display bugs, or are missing the exact symbol you need.
I use "Source code pro" often and Symbola occasionally and they work well. Full math notation is problematic and likely farther than anyone is proposing. I do use box-drawing occasionally and don't have any alignment problems with them even cross-platform.
It's true that I did take a few moments to configure things to make it easier for me. Once done however, easy. But, the majority is now using emoji everywhere, in defiance of curmudgeons. I've never heard anyone complain it's "too hard." -Mike
On Wed, 20 May 2020 at 17:17, Mike Miller <python-ideas@mgmiller.net> wrote:
Input _is_ hard or rare. Deal with it. Even the font is not uniformily configured across systems, and a glyph one does see here may not show properly on the terminal, or other editing environment. I see absolutely no gain of using optional arcane symbols in soruce code. Of course documentation derived from annotations can be as prettified as one want. It seems that the only sane thing to do is to use a baseline of well established symbols on source code, and anyone can have a customized editor to render (or input) those as they see fit - and even thought that always have been a possibility, very few people does so. (I had a coleague once which did set a special VIM config to display "!=" as "[can't type, math 'different' sign from here]" and even that was mostly a toy than anything really useful.
I guess that is my point exactly: the main reason why this person has been unable to make anything useful out of that otherwise perfectly sound idea is that it is not allowed in the language, so people need to mess with solutions on the outside sphere - editors, IDE’s, documentation post-processing - that essentially have no chance to be sustainable, and/as it causes extra burden for everybody We should allow code to be natively pretty, and not rely on other tools to do the prettifying job - or not
On Thu, 21 May 2020 at 10:06, Thierry Parmentelat <thierry.parmentelat@inria.fr> wrote:
And then, suppose you can "solve" this chicken and egg problem by allowing it on the language. Get 2 or 3 years for people to catch on the language version that accepts it (how much code out there using 1_000_000 numric spacing already?) - then, supposing tools evolve along with it, ok, maybe in 4 years I can fire-up a "visual studio code" with a setup that allows me to hold a modifier key and pops-up a floating virtual keyboard with the unicode operators and type it almost seamlessly - how would that help me to type code snippets in e-mails or web-forms??? That is effectivelly locking people out of the language unless they have a "proper coding tool" - which likely would also be needed to display code properly. (may I remind you that some of these symbols are not even on the basic BMP so it is not feasible to use them in idle. That is, if you answered the question about which right arrow to use, asked above) Whereas the same effort for a 'magic symbol palette' plugin for vscode, pycharm or whatever is the IDE of the moment can support displaying the ASCII operators as unicode, in the way it is already possible with VI - while keeping the source code editable when I ssh into a docker container with misconfigured keyboard settings.
that’s an easy one, see the OP In [1]: print("\u2192”) → for all the rest, I am sorry, all the arguments about people having trouble inputing those characters are not relevant, it’s not as if using unicode characters was mandatory arguments about some people not seeing such code properly are of course much more valid but you seem to forget that using unicode characters is already possible in strings, and identifiers even so somebody else opened that box already … And if IDLE can’t do it, it’s a problem already I am convinced this will happen, one day or another, with or without Python, only question is when, not if
You are SERIOUSLY suggesting that typing 'Ctrl-Shift-U 2 1 9 2 <enter>' is easier for me than typing '->' as I do now!? And it remains easier if I use a different computer where I have to figure out or remember some different way of getting the Unicode code point into the editor? The goal of this being to wind up with source code that will render gray boxes for unknown character if I don't have the right font or the right display context? Even if *I* don't start using that special character (or others), I wind up having to edit and view code that other people have written, which means I need to deal with a tool stack to handle things that are hard to enter on most keyboards. As is... my editor looks like this. I don't type all those special things, except once in a configuration file. But the "prettification" is handled transparently when I type some ASCII sequences. -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On 21 May 2020, at 23:03, David Mertz <mertz@gnosis.cx> wrote:
You are SERIOUSLY suggesting that typing 'Ctrl-Shift-U 2 1 9 2 <enter>' is easier for me than typing '->' as I do now!?
that’s not how I’d do it; and I dont think I said or suggested anything to that effect
this thread seems to be obsessing on entering with the keyboard; that is not my point at all
As is... my editor looks like this. I don't type all those special things, except once in a configuration file. But the "prettification" is handled transparently when I type some ASCII sequences.
that’s nice ! it’s a real shame though, and a bit of a waste honestly, that everybody needs to cook their own brew of an editor to get there and primarily all I’m trying to say is that, one day, this will be a legal piece of code, so that we can share and enjoy exactly like this instead of in poor work-it-out-yourself ascii
On Thu, May 21, 2020, 5:51 PM Thierry Parmentelat < thierry.parmentelat@inria.fr> wrote:
I don't know how'd you'd do it on you particular OS, certain, operating system, editor, etc. But I very much doubt that's a key on your keyboard, so you'd have to do something akin to this. Maybe you have an old APL keyboard, but most people don't. The reason everyone is "obsessing" about how someone would actually make your symbol appear is that it won't happen magically by thinking it. So you are proposing and huge hit to ergonomics for everyone for no discernable benefit. that’s nice ! it’s a real shame though, and a bit of a waste honestly, that
everybody needs to cook their own brew of an editor to get there
I'm more than happy to share my vim conceal config. There plugin comes with something similar, but I've customized it to my liking. But other people would probably prefer something different... Which they can have. and primarily all I’m trying to say is that, one day, this will be a legal
piece of code,
I very much hope that will never happen. I'm 99% sure my hope will be realized. I will never be able to use a keyboard with 100k keys on it... Admittedly, I don't really understand Chinese character entry methods.
On 5/21/2020 5:51 PM, Thierry Parmentelat wrote:
I believe I speak for a significant majority of professional programmers when I say that eye-candy like this adds no value to the language for me. It gives me no new capabilities, I don't see it making me more productive, and we have syntax that works quite well already. What if I want to use a font in my editor that doesn't support →? Does that mean that I won't be able to edit some random bit of code I download? --Edwin
As is... my editor looks like this. I don't type all those special things, except once in a configuration file. But the "prettification" is handled transparently when I type some ASCII sequences. [image: Python-arrow.png]
The first screenshot (of completely pointless code I just typed to use a few symbols or sequences) used vim conceal plugin; also my particular configuration of what to substitute visually on screen. That approach lets entire patterns get replaced by... whatever you want. E.g. I replace `set()` with the empty-set symbol, but no one else is required to by the plugin if they don't want to (or the script Z/R for int/float, likewise). For comparison, I changed my system text editor to use JetBrains Mono Medium. The editor is called "Text Editor" on my system, but it's a rebranded gEdit, which is a pretty reasonable code editor. Someone else in the thread pointed to that font which uses ligatures to make composed characters. So it's not a substitution but simply another way of drawing some letter pairs. The result is in the attached screenshot. This approach is somewhat less flexible in that it gets exactly those ligatures that JetBrains decides you want. In concept, there is no reason this couldn't create a 'float' ligature that renders as a script R, for example. But that is not a combo JetBrains decided to use. The main point of this, is that the code is still just plain ASCII, it just happens to look "fancier." It requires no plugins, and it does not require a JetBrains IDE or editor. I haven't tried every editor, but I believe that most or all that use GUI fonts will work fine. Not sure about ligatures and Linux terminal, someone can try it. -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On Fri, May 22, 2020 at 11:21 AM David Mertz <mertz@gnosis.cx> wrote:
The ability to pretty-ify code in this way is inspiring; I'm going to have to look into it. There could be many other IMO more useful/helpful pretty-fication ideas out there that could not be accomplished with unicode, or simple "replace these symbols with another one" configurations. Couple of examples: 1. I've often thought it would be nice if the parameter type-hints sort of floated underneath (or maybe above? underneath makes more sense to me) the parameter names, rather than using the colon at all. Or, perhaps using colors to specify types - Indigo for ints, scarlet for strings, fuchsia for floats, perhaps italics for optionals, that sort of thing. 2. Another really nice improvement, so that I could share raw, copy-and-pasted pretty-ified code with my professional engineering coworkers (as a set of engineering calculations), would be for the editor to detect mathematical equations and display them that way. Like: from scipy.integrate import quad def f(x, i, j, a, b): return quad(a*x**2 + b , 0, 1, args=(a,b)) ...would be displayed *automatically* (without having to muck about with sympy), and able to be copied, as: [image: image.png] ( latex code: $f=\int_{i}^{j} a x^2 + b \,dx$ ) *BACK ON TOPIC:* The point of giving the examples above is not to rabbit trail, but to agree with others who have basically said going down this particular road-- putting a lot of effort into including fancy unicode symbols as part of the syntax-- would be a mistake. IMO, a big reason it would be a mistake is, it doesn't bring *ENOUGH* to the table for making things look nicer-- there is so much more that could be done to make reading python an even more pleasurable experience beyond using unicode symbols. And not only that, make it useful to more people beyond the circle of those who actually even *KNOW* they are reading "python" (as opposed to just English pseudocode describing mathematical/algorithmic processes). --- Ricky. "I've never met a Kentucky man who wasn't either thinking about going home or actually going home." - Happy Chandler
On Thu, May 21, 2020 at 04:04:20PM +0200, Thierry Parmentelat wrote:
If we still have to come up with a good looking, unambiguous per ASCII digraph or trigraph symbol, then what does the Unicode symbol grant us? The moment we say "why bother with the ASCII digraph, everyone can use the Unicode symbol?" then we are proposing that it be mandatory. Even if it is not mandatory, people will want to use the same symbol throughout a project. Once somebody allows → in a module, they're probably going to require → and reject patches using -> Now of course people can *work around this* by copying and pasting, symbol palettes, etc but it does add to the friction of using Python. If the benefit isn't greater than the amount of friction, the overall experience is worse. Allowing Unicode symbols expands the range of operators and special symbols we can use, and potentially makes it easier to add new language features. But if we have ASCII fallbacks for every one of those, then it doesn't add any extra power or functionality to the language, it just adds complexity for minimal benefit.
Indeed, this is true, but neither identifiers nor strings carry syntactic meaning. We don't has to ask what the identifier straß means to understand the code, at worst we could treat it as an obfuscated name like xyz. Likewise for string constants. Mandatory or not, giving syntactic meaning to Unicode symbols (as opposed to merely allowing them in indentifiers and strings) will lead to a massive increase in community questions: "What's the meaning of that curly less than sign ⊰ in Python?" or more likely: "What's with all the small boxes '' in Python code?" (assuming they even display at all, in my mail client the above symbol displays as a space; they could easily also display as �). So unless you're volunteering to personally seek out and answer all those questions, this can only increase the amount of community support needed for not very much benefit at all. We have had non-ASCII identifiers for, oh, 15 or 20 years now, but still the vast bulk of identifiers use nothing but ASCII, even when not written in English. At least for projects which have much visibility in the public, English-speaking internet :-) (I expect that people and companies use a lot more non-ASCII in their private code. And there is an interesting little project called ChinesePython that translates the language into Chinese, but I don't know how successful it is or if it is even still maintained.) So the cost of allowing non-ASCII identifers is much lower than the cost of non-ASCII symbols; even if the benefit is low, it can still be a win for non-ASCII identifiers and strings, while the cost:benefit ratio end up negative for non-ASCII symbols.
I am convinced this will happen, one day or another, with or without Python, only question is when, not if
*shrug* If you are serious about persuing this, you could start by doing a survey of what other languages allow non-ASCII symbols, and report on their experience and popularity. You might also check out Coconut, which is superset of Python that compiles down to Python. Another option might be to provide a pre-processor that translates (say) → into -> for example. We might have .pyu files (u for unicode) translate into .py files before being compiled or run. A good practical project for someone seriously interested in advancing this idea would be a translator that goes in both directions, from pure ASCII to non-ASCII. (Remember that string literals, docstrings and comments shouldn't be touched.) -- Steven
On Thursday, May 21, 2020 9:20 AM Joao S. O. Bueno [mailto:jsbueno@python.org.br] wrote
It wouldn't. No matter how slick of a Unicode operator insertion setup you have, it still is quicker and easier to type ->. I fail to understand how suggesting that all new python programmers use a slower, more complex entry method can be perceived as more "user-friendly". Especially since they have to learn what -> means anyway. Not only that, not all fonts support all Unicode characters. There would need to be a FAQ section in the docs on fonts that work with Python. --Edwin
Executive summary: I'd like to make three points. 1. Accessibility matters, and I think this change would be inaccessible to users of screen readers. 2. Yes, a variety of tools imposes a burden, but also confers benefits. 3. There's no such thing as "pretty source code." There are only tools that display source code beautifully. Down and dirty details: The first is new to this discussion: Let's not make life more annoying for the accessibility developers and the people who *need* accessibility accommodations. Not all visual puns are audible puns. "→" looks like "->", but "Unicode U+2192 RIGHTWARDS ARROW" sounds nothing like "HYPHEN GREATER-THAN". (I'm guessing at the pronunciation, I don't use a screen reader myself. OK, probably the reader just says "RIGHTWARDS ARROW" or even "RIGHTARROW", but it's still not close to the same.) At the very least, we should do a case-by-case check when we want to pun this way, and also ask an accessibility expert (better three) about whether screen readers make this connection, and if not, whether their users would be able to. Second, about Tower-of-Babelonian tool proliferation: Thierry Parmentelat writes:
This situation that has no chance to be sustainable obviously *is* sustainable. It's been this way for as long as I've been using computers (daily use for work or study since 1979). I very much doubt it is going to change, ever, because tools are personal. Yes, it causes a certain amount of burden for everybody, but it also provides great benefits for everybody, or network externalities would impel us to accept a common set of tools.
We should allow code to be natively pretty, and not rely on other tools to do the prettifying job - or not
There's no such thing as code being "natively pretty". Code (source code) is a sequence of bits grouped into bytes grouped into characters grouped into statements grouped into a file. I can't see the pits on a BD or the microwaves in a wireless connection, and I doubt you can. There are software tools doing a prettifying job every time source code is displayed, printed, or read out loud, and a mass audience language like Python needs to adapt to the tools of the mass audience. Yes, we humans can help relatively "dumb" tools do a better job of displaying pretty code (for example, "significant whitespace"), but it's the quality of tool that matters most. Fred Brooks had a good essay on "sharp tools", slightly off-point, in *The Mythical Man-Month*. (I'm pretty sure of the citation but unfortunately my copies of MMM are all at school for access by my students. :-) He advocated having a tool-building specialist on his "surgical team" of (proprietary) developers, but in the open source world, we all publish our tools, which is both the glory and the disaster of something like Emacs. There are also habits that won't change -- even if *you* habitually use one of the many right arrows in Unicode instead of "->", most of us will continue to touch-type "->", and you're going to have to read it. And code is eternal: 20 years from now, somebody's going to be upset about some misfeature in the stdlib, and they're going to have to read it. (Well, maybe not "->", depends on whether they need to look at the stub files, which is a "probably not", stub files are more useful to the Python compiler than to humans most of the time.) If you want all your Python code to use non-ASCII characters in the syntax whether you wrote it or not, *your tools will have to do it for you*. Steve
On Thursday, May 21, 2020, at 8:48, Joao S. O. Bueno wrote:
Input _is_ hard or rare. Deal with it.
[...]
It seems that the only sane thing to do is to use a baseline of well established symbols on source code [...]
According to https://en.wikipedia.org/wiki/Digraphs_and_trigraphs, Python is already on thin ice by using the full set of ASCII characters. I wonder how many non-native English speakers have given up on Python because of that. I'm old enough to remember terminals that didn't support lower case letters, let alone "curly braces," and to have used dozens of different keybpards with all sorts of "common" symbols (e.g., [, {, /, \, <) in all sorts of different places. I had a customer who was old enough to use upper case letter O for zero and lower case letter l for 1 because she was old enough to have learned to type before typewriters had number keys; that made a real mess of sorting street addresses. But I digress. Sort of. Yes, some characters are harder to enter for some people at some times. We're all different, and so are our computing tools. Imagine that. When I studied Koine Greek in school (c. 2003 or 2004), I learned what I had to to type up my homework. Was I fast? No, not really. Was I fast enough? Yep. I'm not for full blown, use every Unicode character we can, but I'm not against using characters outside the ISO 646 invariant character set, either. Using π or ϖ as an alias for math.pi? Not too bad. Matched pairs of left/right quotation marks? Maybe, but not without a lot more thought. Different right arrows for different operations? That's asking for trouble. -- “Atoms are not things.” – Werner Heisenberg Dan Sommers, http://www.tombstonezero.net/dan
On Thu, May 21, 2020 at 09:43:33AM -0400, Dan Sommers wrote:
How old was your customer? The Hansen Writing Ball, first commercially sold in 1870, had digit keys: https://historythings.com/life-changing-invention-typewriters/ The first recognisable typewriter, the Sholdes and Glidden Type-writer (note the hyphen!), was sold in 1864. Here's a photo of one: https://historythings.com/wp-content/uploads/2016/07/9999006136-l.jpg The photo isn't clear enough to see the keys, but there are 44 of them. Since the Sholdes typewriter didn't have lowercase letters, it's hard to imagine what the remaining keys after the uppercase letters and punctuation marks were if they weren't digits. (44 keys would nicely match 26 letters, 10 digits, space and seven punctuation marks.) And this 1903 Olympia typewriter clearly has digits: https://historythings.com/wp-content/uploads/2016/07/SAM_2381_clipped_rev_1.... It is certainly true that many people of a certain age used to interchange 0 and O, and 1 and l, but I don't think it had anything to do with learning to type on typewriters without digits. What did they use when they needed the digits 2 through 9? -- Steven
On Friday, May 22, 2020, at 8:28, Steven D'Aprano wrote:
https://historythings.com/life-changing-invention-typewriters/
I can see 0, 2, 3, 4, 5, and 6 clearly. I can't see a 1, although it appears that the key between the 0 and the Q is missing its label.
The photo is not clear, but I can convince myself that the keys on the top row start at 2 and run through 9 and 0. Still no 1.
And this 1903 Olympia typewriter clearly has digits:
https://historythings.com/wp-content/uploads/2016/07/SAM_2381_clipped_rev_1....
Still no 1.
Okay, "before typewriters had number keys" is obviously wrong. Those pictures support "before typewriters had 1 keys." -- “Atoms are not things.” – Werner Heisenberg Dan Sommers, http://www.tombstonezero.net/dan
The old images I find lack the '1', but not the '0'. What model was this you had? On Sun, May 24, 2020 at 1:48 PM Rob Cliffe via Python-ideas < python-ideas@python.org> wrote:
-- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On 2020-05-21 05:48, Joao S. O. Bueno wrote:
Maybe long ago. My terminals support even color emoji, have for years, and are all free. The only thing I've seen recently that doesn't is the Linux console, which I use rarely for admin tasks. (Oddly enough, it does handle right arrow properly.) fbterm is an option there for those wanting more. Even Windows 10 has gotten in on the act terminal-wise. If you're still on XP or 7, it's way past time to upgrade. -Mike
On Thu, 21 May 2020 at 18:15, Mike Miller <python-ideas@mgmiller.net> wrote:
If you format all your computers from a single image, maybe. My pet project over the last year is a unicode art library, I use a Ubuntu 2018 and a Fedora system daily - on my personal machine, which is the Fedora, I've installed all available font packages an their kitchen sink. Still, emoji support varies wildly across terminal programs and even across the same terminal program in Ubuntu and on Fedora. Although, yes, it is likely that "older" glyphs like unicode mathematic symbols will be present in all of then and render . However, that does not mean it will render ok as a single-cell character in a mono-spaced font - as the character "east asian width" property is marked as "A" (Ambiguous), and may vary according to the installed font - even Qt5, perhaps the most sophisticated windowing toolkit available in the World, is severely bugged when displaying non single-width characters in a monospaced cell character environment such as coding space. (Of course, it may be that native Windows character and widget engines or Mac OS's are better in this particular requisite)
I consider this thread to be moot at this time - I am just answering this e-mail because you answered me directly - but I had seem no strong support, I had seem you not answering direct questioning about how this will make things harder to learn and use but for writting down your own rationalizations on it. I'd suggest you'd just pause for a bit, and read carefully some of the other e-mails, if mine, focused mainly technical infeasibility of even typing or displaying that character, and consider these questionings for real - not with the ready made answers you have ready in your mind. I am recording a video series trying to present Python programing to absolute beginners - and to keep things timely, the ambiguity between two valid quote types is already a _pain_ - which I simply try to avoid by making consistent use of just one quote type. But after a 4 hour crash course, no one that is not already familiar with coding, could come up comfortable with using both ' or " interchangibly unless I spend 30 minutes focusing ont that.
On Fri, May 22, 2020 at 11:02 PM Joao S. O. Bueno <jsbueno@python.org.br> wrote:
Seriously? In primary school English class I learned that you can nest quotations by using different quote characters. Maybe we need to consider that first-grade English (or whatever your native language is) should be considered a prerequisite for coding, and just teach those kinds of concepts (including words like "singular" and "plural", since they're so helpful for diagnosing bugs). ChrisA
On 2020-05-22 05:57, Joao S. O. Bueno wrote:
Yes, though I'm sure no one is seriously proposing using wide, or combining chars, or other obscure things. Just some useful symbols from around the 0x2000 range of the BMP, which are widely/universally supported by now. To be honest, keyboard entry is the least interesting aspect of this. To reiterate, we found a zero-ongoing-effort entry method, typing and leaving " -> " in the source, and "upgrading it" to " → " with a formatter or other tool when desired. That's assuming you already have tools set up. I recommend them, but they would not be required obviously and neither would the upgraded character for compatibility reasons. More importantly, does it help readability? I think it does, however not strongly. I'm perhaps +0.5 on a few of these characters. Word processors do upgrades to hyphens, for example, to make the resulting doc more readable. Is that kind of thing useful for Python? -Mike
On 22/05/2020 18:21, Mike Miller wrote:
Generally speaking, no. Editors that do things for you behind your back are an open invitation to bugs. I find that for most word processing that I do, I have to turn off the automatic translation/correction/whatever to prevent them from incorrectly rewriting my input. Prettifying code so that it no longer runs when you cut and paste is one example; more often I find they mangle the capitalisation of company names, product ID and so forth. I would hate to find an editor starting to do similar things for me. Sometimes even basic things like "electric modes" (auto-indentation after you hit RETURN) can make more work for you! -- Rhodri James *-* Kynesim Ltd
On Wed, May 20, 2020 at 8:36 AM Thierry Parmentelat < thierry.parmentelat@inria.fr> wrote:
= might be an improvement because that's a symbol learned in school, but
This seems to be the main (only?) argument beyond it being pretty - that it's somehow easier for beginners to deal with. I think it's the opposite. Many (probably most) people are going to come across a unicode symbol having previously only encountered ASCII symbols and probably thinking that was the only option. That includes all currently experienced Python programmers who aren't up to date on the latest news, and all beginners who learned using anything but the most up to date material. Even after this feature has been around for a while, many (most?) new learning materials will not include unicode symbols because authors don't want to go through the extra effort to write those symbols. And if you think Python is ASCII only, then when you see unicode, you'll think something is wrong. Someone's editor magically transformed `->` or the website has some overly clever rendering or something. That would be my reaction if I saw such code now. Indeed, if I copied the code and ran it with the wrong version of Python, I'd get the expected SyntaxError. Overall it just creates confusion. If you try to teach people from the beginning that both options exist, then that just slows down learning. Learning coding is hard enough for most people without being distracted by minor details about syntax. If someone thinks that special unicode symbols are the only option, or if they know they're optional but get the impression that they're preferred and feel pressure to use them, then typing code becomes a pain. In particular beginners often start coding with a basic editor such as notepad so that they aren't distracted by unneeded features or reliant on tools which do too much work for them that they need to learn on their own ( https://cseducators.stackexchange.com/a/634). So they won't have fancy IDEs to insert symbols for them, and must rely on their OS. Finally, in what way does it make it easier for beginners? `->` is pretty clearly meant to represent an arrow, but beyond that an arrow is not particularly informative. The student would still need to learn that → in that particular context is a type hint for the return value, which is not immediately obvious. Whatever difficulties they may have learning that concept, the symbol used is not going to make much difference. ≥ instead of ultimately the student still needs to learn what `>=` means as it will be used most of the time.
On 21 May 2020, at 15:45, Alex Hall <alex.mojaki@gmail.com> wrote:
Many (probably most) people are going to come across a unicode symbol having previously only encountered ASCII symbols and probably thinking that was the only option. That includes all currently experienced Python programmers who aren't up to date on the latest news, and all beginners who learned using anything but the most up to date material. Even after this feature has been around for a while, many (most?) new learning materials will not include unicode symbols because authors don't want to go through the extra effort to write those symbols.
I’m having a hard time with statements like
Many (probably most) people are going to come across a unicode symbol having previously only encountered ASCII symbols
clearly the experienced Python programmers are not the main target here our 7-year old schoolboys are used to typing é's and ç and ü’s and À’s, and this is Europe, not China, so... what was the point of defining unicode in the first place then ?
On 21/05/2020 15:09, Thierry Parmentelat wrote:
clearly the experienced Python programmers are not the main target here our 7-year old schoolboys are used to typing é's and ç and ü’s and À’s, and this is Europe, not China, so...
You say that, but it is a source of endless annoyance to me that the Linux UK Keyboard doesn't offer AltGr shortcuts for a c-cedilla. It makes addressing my colleague François quite a pain :-/ -- Rhodri James *-* Kynesim Ltd
Yeah well, if the whole english-speaking keyboard industry shares the feelings expressed on this thread, it’s no wonder ;-) I suggest you take a look at the US-international (not sure there is a UK-international) input method, that I think is available on all 3 OSes in one form or another, and that is cool for that sort of things (the keyboard I am using right now is a regular qwerty keyboard with no alt-gr modifier) and the other way around I can assure you that coding with a regular French keyboard - the infamous AZERTY thingy - is something you don’t want to have to do; you’d need alt-gr to enter a mere { - and digits come through shift- !
On Thu, May 21, 2020 at 4:09 PM Thierry Parmentelat < thierry.parmentelat@inria.fr> wrote:
What I mean is that they would only have seen ASCII symbols used for Python syntax i.e. not counting the contents of strings. Currently that's the experience of 100% of all Python coders. That percentage will drop a little if and when this feature is announced, but not much, and from there it can only decrease gradually. Again, if I saw a unicode arrow used as syntax on GitHub or something in the wild right now, I would think it's an error, which incidentally would be correct. Wouldn't you? That will be the experience of anyone who sees this before learning about it, and that will always include some beginners.
On 21 May 2020, at 16:18, Alex Hall <alex.mojaki@gmail.com> wrote:
What I mean is that they would only have seen ASCII symbols used for Python syntax i.e. not counting the contents of strings.
and identifiers
Currently that's the experience of 100% of all Python coders. That percentage will drop a little if and when this feature is announced, but not much, and from there it can only decrease gradually.
Again, if I saw a unicode arrow used as syntax on GitHub or something in the wild right now, I would think it's an error, which incidentally would be correct. Wouldn't you?
yes, like I would have taken a walrus operator for a syntax error just a couple years ago maybe; things change..
That will be the experience of anyone who sees this before learning about it, and that will always include some beginners.
the only thing that beginners know is: they don’t know much, I don’t see them necessarily jumping to conclusions
On Thu, May 21, 2020 at 4:36 PM Thierry Parmentelat < thierry.parmentelat@inria.fr> wrote:
I think you make a good point, but it's not quite the same. If I see: ``` if (match := re.match(...)): x = match.group(1) ``` and I don't know what `:=` means, I pretty much have to Google it, guess, or otherwise learn. I'm not going to think that a colon was accidentally added to `match = re.match(...)` because that's not valid syntax either. I *might* think it's supposed to be `match == re.match(...)`, but that would just raise more questions - `match` is an undefined variable, and you don't compare match objects. Besides, how did this mistake happen? Didn't this person run their code? If I see: ``` def foo() → Bar: ``` I'm going to think that either: 1. Some fancy rendering is going on, like the ligatures some have been talking about. Right *now*, that's probably the most likely hypothesis, considering that some people do this in their editors. If it was actually valid syntax, I'd be surprised when that reasonable guess turned out wrong, especially if I paste it somewhere and get a SyntaxError with my slightly outdated Python. Which leads me to the next guess... 2. In the process of transferring from the editor to a blog/email/document/etc the code has been mangled. I don't know exactly how, but someone was complaining on this list recently that plain ASCII quotes had turned into fancy matching quotes which lead to a confusing error message. So it seems plausible that `->` got transformed somehow. It's not similarly plausible that `==` randomly became `:=`.
21.05.20 16:45, Alex Hall пише:
But in my school I learned ⩾, not ≥. It was used in USSR and I believe in other European countries (maybe it is French or Germany tradition?). If Python will become accepting ≥ as an alias of >=, I insist that it should accept also ⩾. And ⊃, because it is the symbol used for superset relations for sets (currently written as >= in Python). And maybe other national or domain specific mathematical symbols. Imagine confusion when
=, ≥, ⩾ and ⊃ are occurred in the same program.
On Thu, May 21, 2020 at 06:48:55PM +0300, Serhiy Storchaka wrote:
As far as I am aware, there is no mathematical difference between the two greater-than-or-equal operators ⩾ and ≥ it is a purely stylistic issue, just as some fonts use two lines in dollar signs and some only one. I don't know why Unicode gives them two different code points, but if I were a betting man, I would put money on it being because some legacy character set provided them both. (One of the motivations of Unicode is to allow the round-tripping from every common legacy charset without loss.)
An annoying thing about superset and subset operators is that mathematicians don't agree on whether the superset symbol ⊃ is strict or not. This is why we also have unambiguous symbols ⊇ (superset-or-equal) and ⊋ (strict superset not equal).
Imagine the confusion if somebody had variables spam, Spam, sPAM, SPam, sPAm. Or worse, SPΑM, SPАM and SPAM. *wink* Let's not worry too much encouraging people's bad habits. People can write obfuscated code in any language. I am sure that before this is a problem, linters and code formatters like black will keep it under control. -- Steven
On 22/05/2020 20:40, Steven D'Aprano wrote:
Imagine the confusion if somebody had variables spam, Spam, sPAM, SPam, sPAm. Or worse, SPΑM, SPАM and SPAM.
Randall is way ahead of you. https://xkcd.com/2309/ :-) -- Rhodri James *-* Kynesim Ltd
Hello, On Mon, 18 May 2020 02:39:27 +0100 MRAB <python@mrabarnett.plus.com> wrote: []
To make it clear, the talk is about "better", not "existing" annotation syntax, which is a square (literally) peg in a round hole. With PEP 0563, there's totally no need to wrap everything in square brackets, and atrocities like __class_getitem__ can be treated like an implementation detail of a particular Python implementation (CPython, that is). With PEP 0563, while evaluating annotations, one can just pass to eval() a suitably constructed "globals" dict, to enable any operators on any symbols (which would be represented by objects, not classes), or just operate on AST with even finer level of control. -- Best regards, Paul mailto:pmiscml@gmail.com
Hello, On Mon, 18 May 2020 13:25:50 +1200 Greg Ewing <greg.ewing@canterbury.ac.nz> wrote:
Well, I don't say "ideal", I say "better". The point is that the world learned long ago that any type of information can be represented with just recursive parens: (foo (bar 1 (2) 3)), but some variety in punctuation helps mere humans among us.
With the idea that someone may confuse ":=" for "<-", so we can swap result and argument types comparing to their natural/intuitive order? Well, I guess that's not what I'm talking about. But we indeed can treat ":=" as a function operator in annotations, and write: (int) := str Actually, we don't have to use funky novelties, and mere "-" looks better as a lookalike for "->" than ":=". The following works as expected: ========= from __future__ import annotations def foo(f: (str, int) - int = map, seq: list = None): pass print(foo.__annotations__) import ast print(ast.dump(ast.parse(foo.__annotations__["f"]).body[0])) ========= I'd still consider it a better idea to just make "->" an operator on the AST level. Can stop there, because realistically (or sanely) PEP-0563 annotations would be parsed via an AST (example above). But if there's desire to assign some semantics to it, it can be that of making a tuple, with precedence just above "," operator, so "foo -> bar, 1 -> 2" would evaluate to ((foo, bar), (1, 2)). Worst-case, can add a __rarrow__ dunder.
-- Greg
-- Best regards, Paul mailto:pmiscml@gmail.com
On 24/05/20 10:26 am, Paul Sokolovsky wrote:
No, with the idea of making use of an already-legal expression and not introducing any new syntax into the grammar.
But that would be backwards with respect to the flow of data when := is used for assignment. Also, it is not currently legal syntax when there is more than one argument, because := doesn't support unpacking. -- Greg
IMHO, if `->` becomes an operator with semantics, then `[t1, ..., tn] -> tr` should mean `typing.Callable[[t1, ..., tn], tr]`.
I would like to comment that the graphical presentation, at least in IDEs/where the font can be controlled, can be achieved using fonts: https://stackoverflow.com/questions/41774046/enabling-intellijs-fancy-%E2%89... On Sun, 17 May 2020 at 13:26, Thierry Parmentelat < thierry.parmentelat@inria.fr> wrote:
I would like to comment that the graphical presentation, at least in IDEs/where the font can be controlled, can be achieved using fonts:
Precisely. Nicer than the arrow symbol, it would be to type "-" + ">" and get an arrow visually. The same can be done about getting >= as a single symbol and == and === and <=> as single symbols. It seems like a matter of code presentation, not code itself.
Wouldn't it be better implemented on an editor as a display option instead of changing python? Because, as I understand, it's an issue of appearing nice on screen, rather than storing (and parsing) `'\u2192'` as an alias to `'->'` on type hints. It *would* look nice, though
participants (24)
-
 Alex Hall
Alex Hall -
 Bernardo Sulzbach
Bernardo Sulzbach -
 Brett Cannon
Brett Cannon -
 Chris Angelico
Chris Angelico -
 Christopher Barker
Christopher Barker -
 Dan Sommers
Dan Sommers -
 David Mertz
David Mertz -
 Edwin Zimmerman
Edwin Zimmerman -
 Ethan Furman
Ethan Furman -
 Greg Ewing
Greg Ewing -
 Henk-Jaap Wagenaar
Henk-Jaap Wagenaar -
 Holly Short
Holly Short -
 Joao S. O. Bueno
Joao S. O. Bueno -
 Mike Miller
Mike Miller -
 MRAB
MRAB -
 Paul Sokolovsky
Paul Sokolovsky -
 Rhodri James
Rhodri James -
 Ricky Teachey
Ricky Teachey -
 Rob Cliffe
Rob Cliffe -
 Serhiy Storchaka
Serhiy Storchaka -
 Stephen J. Turnbull
Stephen J. Turnbull -
 Steven D'Aprano
Steven D'Aprano -
 Thierry Parmentelat
Thierry Parmentelat -
 Tiago Illipronti Girardi
Tiago Illipronti Girardi