Improve handling of Unicode quotes and hyphens

Hi All, Apologies if this has already been discussed to death. Python 3 allows Unicode characters in strings and identifiers but the actual quotation marks are only accepted in plain ASCII, i.e. the following all successfully initialise strings: ``` S1 = "Double Quoted" # Opened and closed with chr(34)0x22 S2 = 'Single Quoted' # Opened and closed with chr(39)0x27 ``` But the following all result in an error - "SyntaxError: invalid character in identifier": ``` S1 = "Double Quoted" # Opened with \u201c and closed with \u201d S2 = 'Single Quoted' # Opened with \u2018 and closed with \u2019 ``` To the experienced eye, and depending on the character font used, it is "obvious" what the problem is! The wrong quotation marks were used. The big problem, especially for beginners, is that the same keys were typed, just in the "wrong" editor or even the wrong editor mode or context I have found that in Outlook if the font is FixSys or I am replying to a plain text email it is fine but otherwise it is "helpful" - unfortunately, especially on Windows, "wrong" editors abound and include, but are not limited to, MS-Outlook, MS-Word, some online editing environments such as Quora. On top of that is the helpful substitution of a m-hyphen for minus when you press space a word later so: A = 3 - 2 # With a space syntax error due to \u2013 A = 3 - 2 # No Space or CR after I last typed it is OK as 0x2d Use cases that catch people out: 1. Sending a code snipped by email using Outlook 2. User manuals written in MS-Word - (many peoples work environment) 3. Articles published on Quora - people expect to be able to copy and paste the code for some reason. I am sure that many us have encountered these issues or similar. What can be done? 1. Persuade Microsoft, and others, to stop being so helpful by default - good luck with that! 2. Tell all users that they need to use a "proper" editor or IDE - This seems like adding an additional barrier to new & casual users. 3. Better yet tell them to use a "proper" OS like .... - At the very least many of us have to use Windows at work. 4. Start accepting hyphens as minus & Unicode quotation marks - this would be the ideal answer for pasted code but has a lot of possible things to iron out such as do we require that the quotes match and are in the typographically correct order. It is also quite a big & complex change to the python interpreter. 5. Normalise the input to the python interpreter (at least for these characters and possibly a few others) so that entering or reading from a file S1 = "Double Quoted" becomes S1 = "Double Quoted", etc. - this should be a easier change to the interpreter but, from a purist point of view, could be said to make us as bad as the others because we are not honouring what the user entered. 6. Change the error message "SyntaxError: invalid character in identifier" to include which character and it's Unicode value so that it becomes "SyntaxError: invalid character 0x201c " in identifier" - this is almost certainly the easiest change and fits well with explicit is better than implicit but still leaves it to the user to correct the erroneous input (which could be argued is both good and bad). I would like to suggest that an incremental approach might be the best - clarifying the existing error message being the thing that should not break anything and either substituting for problem characters or processing them "properly" as a later enhancement. Steve Barnes

On Sun, May 10, 2020 at 07:09:15AM +0000, Steve Barnes wrote about Unicode dashes and quotes sneaking into code:
No, I think that in the broader picture, they are doing the correct thing by using nicer typographical quotes and dashes for non-source code. Even if they would listen, we should not ask :-)
2. Tell all users that they need to use a "proper" editor or IDE - This seems like adding an additional barrier to new & casual users.
When people decide to learn, say, wood working, or carpentry, and try to make holes in timber by gauging the wood with a screwdriver^1 but are told to get themselves a drill instead, is this seen as "an additional barrier" or just part of the process of learning a new skill set? A cheap drill costs about AUD$50 and another $25 for a set of drill bits. A cheap IDE or programmers editor costs nothing but a bit of time and hard disk space. I think we can expect would-be programmers to *not* use MS Word to write Python code. If they aren't willing to invest the time and energy to install, then they probably won't invest the time and energy to learn how to program either.
3. Better yet tell them to use a "proper" OS like .... - At the very least many of us have to use Windows at work.
It's perfectly possible to write code on Windows without paying lots of money for expensive commercial IDEs.
Python already accepts hyphens as minus -- only *one* kind though, the so-called ASCII "HYPHEN-MINUS". What it doesn't accept is actual minus signs, '\N{MINUS SIGN}', as minus signs. I don't mind seeing rich unicode in strings, or even comments, but I wouldn't (yet!) want to see it in executable code, I don't think the state of the art of editing tooling and font support is quite ready for it yet. I still see far too many "Missing Character Glyphs" and supposed monospaced text where there's always *one* character that is a single pixel short of the consistent spacing. And I still don't know how to type − in my editor, I have to copy and paste it from elsewhere.
I think people should experiment with preprocessors to get a feel for how well they work before moving it into the interpreter. I think that David(?) may have a Vim or Emacs mode that allows him to use Unicode chars as syntax?
More informative error messages are good :-) ^1 I have literally done that, when I was too lazy to go into the garage and get the drill. So I stabbed at the timber enough to make an indentation so the screw would bite. It actually works! Just not well. -- Steven

On Sun, May 10, 2020 at 4:03 AM Steven D'Aprano <steve@pearwood.info> wrote:
I think that David(?) may have a Vim or Emacs mode that allows him to use Unicode chars as syntax?
I use the vim-conceal plugin: https://github.com/khzaw/vim-conceal. I know that something similar exists for Emacs, but don't remember the name. What this does though is not change anything about the underlying ASCII characters in the code, but rather it substitutes particular character sequences (perhaps in regex context) with other things, such as fancy Unicode characters. So as typing goes, I still type e.g. the letter 'i' followed by the letter 'n' and a space, and the screen simply displayed the U+2208 (∈) character. But on disk, and for Python, it's only still just 'in'. On my own system, I've learned the Unicode code points for the common things like n-dashes and m-dashes that I use. I actually don't know the vim shortcuts for other special things, although I probably should. Still, the vim digraphs are always going to be fewer than all the Unicode code points, even if some useful ones are included (and somewhat mnemonic). But indeed, entry of all those special characters is going to be more work than the characters directly on my keyboard, in any event.
I wouldn't mind messages that actually looked specifically for some of those common annoying auto-substitutions. E.g.: % python ~/tmp/wrongchar.py File "/home/dmertz/tmp/wrongchar.py", line 1 x = 2014 – 2013 ^ SyntaxError: invalid character in identifier The hyphen really does look a lot like the n-dash that is on screen. And I think that's one of those substitutions that word processors and email clients often do. Maybe a collection of the top 20 such common substitutions with some fitting message. I dunno "SyntaxError: invalid character U+2013 may be substitution of ASCII dash". -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.

A lot of this reminds me of a story told by a programming instructor in the 70's, he submitted a FORTRAN program deck to the machine, the complier gave him a warning on a statement which read INTEGER misspelled, it than ran the program, but IGNORED the statement, even though it clearly understood what he meant, and got wrong answers because the compiler just used the default REAL type for the variable, which took him a while to figure out what the error was. (Computer time was limited enough then that you didn't want to just rerun fixing the typo that it pointed out). He was confused about how the program obviously knew what he meant by the message, but didn't process the program right. An error like character (whatever) is not a quote (or is not a minus sign) seems similar. It is one thing to not recognize a funny character in the language, but to actually parse it well enough to give a message that says in effect, that may look like a quote to you, but I am not going to treat is as one, sounds perverse in the language. If we are going to go to the effort to detect that particular character, it makes more sense to make it actually DO the obvious thing. If not, the the current error seems fine, especially if we could include more details. An 'invalid character' message, that doesn't tell you WHICH character is invalid seems like it is holding back, If it included the bad character, or pointed to it, then the error becomes a lot more clear.
On Sun, May 10, 2020 at 2:17 PM Richard Damon <Richard@damon-family.org> wrote:
There are, I think, 28 quote-like characters in Unicode ( https://unicode-table.com/en/sets/quotation-marks/). Actually, probably more; I think U-0060, backtick/grave is not included, for example. Some of those are really supposed to be in particular pairs, others are interchangeably left or right. Which pairs combine is specific to the human language you write in, and also to the style guide you are following. I very much want NOT to make a set of rules for what quotes are allowed when. But simply detecting "that's a quote character, but not the kind Python likes" is much easier than that. Obviously, all of these fancy-quotes are perfectly fine inside of generic Python quotes, as strings. "Doing the obvious thing" is throwing a SyntaxError, but ideally one that is a little more descriptive than currently, as Ned and others have stated. -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.

On Sun, 10 May 2020 14:13:37 -0400 Richard Damon <Richard@Damon-Family.org> wrote:
“In the face of ambiguity, refuse the temptation to guess.” There should be one-- and preferably only one --obvious way to do it. Your argument is that it's not ambiguous. My argument is that it's not within the Python grammar, and therefore it is ambiguous. Also, that forever precludes using those other quotation characters for something else in the future.
Agreed. -- “Atoms are not things.” – Werner Heisenberg Dan Sommers, http://www.tombstonezero.net/dan
On Sun, May 10, 2020 at 02:13:37PM -0400, Richard Damon wrote:
How did the compiler understand what he meant? If INTEGER was misspelled, how is the compiler supposed to know that ITEGER or INREGER or whatever misspelling he used was actually supposed to mean INTEGER?
Yes, programming was harder in the 1970s. The tooling was limited and inconvenient.
It might *sound* perverse, but what is genuinely perverse is Do What I Mean systems that try to *guess* what you mean rather than allowing the user to correct their own mistake. Only the user truly knows what they intended. http://www.catb.org/jargon/html/D/DWIM.html DWIM will just train beginners to be lazy, sloppy, thoughtless coders, since "the interpreter knows what I meant" -- until it doesn't. Even if the DWIM gets it right 9 times out of 10, the pain and difficulty in that remaining case will outweigh the convenience of the other 9 times.
Is `x‒y` meant to be an identifier with a hyphen, or the subtraction x−y? How about `x‐y` or `x‑y` or `x–y` or `xーy`? (All of the above are distinct Unicode dash-like characters. Only one of them is an actual minus sign.) In 2020 we don't have to wait two weeks for our next share of computer time. Correcting an error and re-running the code is easy, there is no real advantage in having the interpreter try to guess what the user probably meant to write, instead of running what they actually wrote and failing if it is not legal code.
The SyntaxError already points at, or just after, the invalid character. py> x−y File "<stdin>", line 1 x−y ^ SyntaxError: invalid character in identifier -- Steven
My personal experience of the most common problematic substitutions by tools such as Outlook, Word & some web tools: 1. Double Quotes \u201c & \u201d “” 2. Single Quotes \u2018 & \u2019 ‘’ 3. The m-hyphen \2013 – 4. Copyright © \xa9 and others, Registered ® \xae and trademark ™ \u2122 5. Some fractions e.g. ½ ¼ 6. Non-breaking spaces From: David Mertz <mertz@gnosis.cx> Sent: 10 May 2020 18:33 To: Steven D'Aprano <steve@pearwood.info> Cc: python-ideas <python-ideas@python.org> Subject: [Python-ideas] Re: Improve handling of Unicode quotes and hyphens On Sun, May 10, 2020 at 4:03 AM Steven D'Aprano <steve@pearwood.info<mailto:steve@pearwood.info>> wrote: I think that David(?) may have a Vim or Emacs mode that allows him to use Unicode chars as syntax? I use the vim-conceal plugin: https://github.com/khzaw/vim-conceal. I know that something similar exists for Emacs, but don't remember the name. What this does though is not change anything about the underlying ASCII characters in the code, but rather it substitutes particular character sequences (perhaps in regex context) with other things, such as fancy Unicode characters. So as typing goes, I still type e.g. the letter 'i' followed by the letter 'n' and a space, and the screen simply displayed the U+2208 (∈) character. But on disk, and for Python, it's only still just 'in'. On my own system, I've learned the Unicode code points for the common things like n-dashes and m-dashes that I use. I actually don't know the vim shortcuts for other special things, although I probably should. Still, the vim digraphs are always going to be fewer than all the Unicode code points, even if some useful ones are included (and somewhat mnemonic). But indeed, entry of all those special characters is going to be more work than the characters directly on my keyboard, in any event.
I wouldn't mind messages that actually looked specifically for some of those common annoying auto-substitutions. E.g.: % python ~/tmp/wrongchar.py File "/home/dmertz/tmp/wrongchar.py", line 1 x = 2014 – 2013 ^ SyntaxError: invalid character in identifier The hyphen really does look a lot like the n-dash that is on screen. And I think that's one of those substitutions that word processors and email clients often do. Maybe a collection of the top 20 such common substitutions with some fitting message. I dunno "SyntaxError: invalid character U+2013 may be substitution of ASCII dash". -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.

Reviving (briefly an old thread) On Mon, May 11, 2020 at 2:13 AM Steve Barnes <GadgetSteve@live.co.uk> wrote:
SNIP As part of this discussion, it was suggested that it would be useful if some more useful messages could be given about the use of some unicode "fancy quotes". Just in case some people were considering "wasting" time on this: = = = = $ python -m friendly_traceback scratch.py Python exception: SyntaxError: invalid character in identifier A SyntaxError occurs when Python cannot understand your code. Python could not understand the code in the file 'scratch.py' beyond the location indicated below by --> and ^. 1: def squares(n): -->2: print(“Squares:”) ^ Likely cause based on the information given by Python: Did you use copy-paste? Python indicates that you used some unicode characters not allowed as part of a variable name; this includes many emojis. However, I suspect that you used a fancy unicode quotation mark instead of a normal single or double quote for a string. = = = This is just one of many cases now correctly identified by friendly-traceback. André Roberge
Like it! Sent from Samsung Mobile on O2 Get Outlook for Android<https://aka.ms/ghei36> ________________________________ From: André Roberge <andre.roberge@gmail.com> Sent: Wednesday, August 5, 2020 7:54:06 PM To: Steve Barnes <GadgetSteve@live.co.uk> Cc: python-ideas@python.org <python-ideas@python.org> Subject: Re: [Python-ideas] Re: Improve handling of Unicode quotes and hyphens Reviving (briefly an old thread) On Mon, May 11, 2020 at 2:13 AM Steve Barnes <GadgetSteve@live.co.uk<mailto:GadgetSteve@live.co.uk>> wrote: My personal experience of the most common problematic substitutions by tools such as Outlook, Word & some web tools: 1. Double Quotes \u201c & \u201d “” 2. Single Quotes \u2018 & \u2019 ‘’ 3. The m-hyphen \2013 – 4. Copyright © \xa9 and others, Registered ® \xae and trademark ™ \u2122 5. Some fractions e.g. ½ ¼ 6. Non-breaking spaces SNIP As part of this discussion, it was suggested that it would be useful if some more useful messages could be given about the use of some unicode "fancy quotes". Just in case some people were considering "wasting" time on this: = = = = $ python -m friendly_traceback scratch.py Python exception: SyntaxError: invalid character in identifier A SyntaxError occurs when Python cannot understand your code. Python could not understand the code in the file 'scratch.py' beyond the location indicated below by --> and ^. 1: def squares(n): -->2: print(“Squares:”) ^ Likely cause based on the information given by Python: Did you use copy-paste? Python indicates that you used some unicode characters not allowed as part of a variable name; this includes many emojis. However, I suspect that you used a fancy unicode quotation mark instead of a normal single or double quote for a string. = = = This is just one of many cases now correctly identified by friendly-traceback. André Roberge

I'm all for clear and helpful error messages, but this feels a tad too verbose (and even a bit patronizing) to me. But the highlighting of character look-alikes is very helpful. Perhaps something like: """ SyntaxError: invalid character in identifier -->2: print(“Squares:”) ^ An identifier contains one or more unallowed Unicode characters. It is likely the "curly quote" unicode quotation mark, rather than the required ASCII single or double quote was used for a string. """ I'm assuming that this would detect some of the common "look alikes" and give a specific suggestion as above. Keep in mind that anyone coding Python is going to see a LOT of SyntaxErrors -- we don't need to present a message as though they've never seen such an error before. But it IS helpful to point out errors that are hard to see with a glance at the code. -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
On Thu, Aug 6, 2020 at 3:40 AM Christopher Barker <pythonchb@gmail.com> wrote:
You raise some very good points. Here's a different output from the same program, followed by some explanation for context. = = = $ python -im friendly_traceback --verbosity 8 raise_syntax_error75 SyntaxError: invalid character in identifier 1: """Should raise SyntaxError: invalid character in identifier for Python <=3.8 2: and SyntaxError: invalid character '«' (U+00AB) in Python 3.9""" -->3: a = « hello » ^ Python indicates that you used some unicode characters not allowed as part of a variable name; this includes many emojis. However, I suspect that you used a fancy unicode quotation mark instead of a normal single or double quote for a string. This can happen if you copy-pasted code. = = = Comments: 1. Friendly-traceback is primarily intended for beginners who do not know what a SyntaxError or a NameError means. This is why it normally includes, by default, [quote] a message as though they've never seen such an error before [/quote]. They also might not know what "an identifier" means, but likely have seen "variable name". 2. Friendly-traceback is designed to support translation. Currently, all the explanations provided are available in French and English, and someone is working on a Chinese translation. Thus there might be a bit of duplication between the message provided by Python ("invalid character in identifier") always shown "as is", and the longer explanation given by friendly-traceback. 3. It allows one to select a "verbosity level". Up until a few minutes ago, the available verbosity levels were 0 to 9 - but did not include a level 8 (for historical reasons), each level providing a subset of all possible information. (The default level leaves out the normal Python traceback). Thanks to your comment, I finally filled a slot for level 8, which is what you see above. (This addition will be part of the next release on pypi). Note that the location of the ^ might be messed up in this email. 4. The original discussion mentioned that using the wrong types of quotes most often occurred when beginners copy-pasted some code from an ebook or a website. This is why the message mentions it ... but I've modified it so that it is, hopefully, less patronizing. Thanks again for your comments. Hopefully, the changes I have made are an acceptable compromise between what you suggested and what might be useful for a complete beginner. André Roberge
Thanks to your comment, I finally filled a slot for level 8, which is what you see above. (This addition will be part of the next release on
As this is a third party package, you, of course, can do what you want :-), But I would likew to see more communicative error messages in standard Python as well, and I think your package could be a great prototype -- thanks! On Thu, Aug 6, 2020 at 2:57 AM André Roberge <andre.roberge@gmail.com> wrote: 3. It allows one to select a "verbosity level". This is great! Sorry I neglected to dig deeper earlier and see that option. Given there are choices, I take it all back :-) Nice work! pypi). This looks good to me, thanks. Hmm -- I may start recommending this package to my newbie students :-) -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython

On Sun, May 10, 2020 at 4:00 AM Steven D'Aprano <steve@pearwood.info> wrote:
Sometimes people are forced to use Word to type code. One example is creating user manuals. Another example: As a current computer science college student, last fall I had an operating systems professor who gave exams by posting the questions online and giving us 24 hours to write and upload our answers (with the exam being closed-book and on a 2-hour time limit "on the honor system"). Several of the questions required us to write Bash scripts or Python functions, and we were required to write all of that code, along with all of our other exam answers, several of which were essay questions, in Microsoft Word and then export the whole mess as a single PDF file to be uploaded. We were not allowed to submit multiple files, or zip files, or anything at all except one single PDF file containing all of our answers and code. So no, sometimes people don't get a choice of what to type code in. I would have much rather typed my code in VS Code or Notepad++ and submitted a zip file with the scripts in individual files and the essay responses in a separate Word or PDF file, but that would have earned me a grade of zero on the exams. And yes, several students lost points for syntax errors because Word "helpfully" converted their quotation marks. I'm happy that professor retired after fall semester and that I'll never have to take another class with him.
Why would you use Word? LaTeX exists, and will export to PDF. Heck, the PDF export from Jupyter is quite good (by way of LaTeX). On Sun, May 10, 2020, 7:40 PM Jonathan Goble < Several of the questions required us to write Bash scripts or Python functions, and we were required to write all of that code, along with all of our other exam answers, several of which were essay questions, in Microsoft Word and then export the whole mess as a single PDF file to be uploaded. We were not allowed to submit multiple files, or zip files, or anything at all except one single PDF file containing all of our answers and code.
On Sun, May 10, 2020 at 8:08 PM David Mertz <mertz@gnosis.cx> wrote:
This exam format was dropped on us with short notice before the midterm and we didn't have time to set up and learn brand-new tooling. Also, this was a freshman-level course, and I highly doubt more than a tiny fraction of the class had even heard of LaTeX, much less knew how to use it (I've definitely heard of it, but haven't the slightest clue how to use it myself). And as the course was many students' first introduction to Python (we only covered the bare basics of the language), Jupyter was again something most students in the class had probably never heard of. The course's primary focus was on introducing students to the usage of the command line interface and to the usage of Linux in general, and Python was a one-week side note to that. Most of the course centered on Bash and on general OS concepts (processes, virtual memory, etc.).
On Sun, May 10, 2020 at 07:39:32PM -0400, Jonathan Goble wrote:
Sometimes people are forced to use Word to type code. One example is creating user manuals.
MS Word is not the only word processor capable of creating user manuals. The LibreOffice people, and others, would like a word :-) If you are a professional writing and formatting an entire book in Word or LibreOffice or some other application, then you can be expected to solve this problem for yourself. (Turn Smart Quotes off.) There are a couple of professionally published Python books written using Restructed Text, Sphinx and Python. So people do have a choice, or at least a technical choice.
How would your professor know that you did the actually typing in Word, instead of doing the sensible thing and typing your code in a text editor and then copying and pasting it into the Word after turning Smart Quotes off?
So no, sometimes people don't get a choice of what to type code in.
Here is an actual example where the people writing actually had no choice, rather than having choices but failed to take advantage of them. I know of a case a company that was called in to solve a problem with desktop PCs at a correctional institution. The PCs were locked down to only approved applications, which included Office but absolutely no plain text editors. Office was required so that the inmates could participate in educational programs. It also included Python. You can see where this is going, I'm sure. It turned out that one of the inmates had typed up a simple Python game in Word, saved it as plain text, and somehow managed to find a way to get access to the command prompt and run it as a script. Never underestimate the ingenuity of bored, intelligent people with a lot of time on their hands. So this was a case where the user *genuinely* had no choice but to use Office, not just because they didn't know better or couldn't be bothered. But the bottom line is, so what? Why should we care about such incredibly narrow niches? - writers who don't know how to turn Smart Quotes off in Word; - students sitting a very badly designed exam; - inmates with Office and Python but no text editor. I'm sorry to all those people, but they are not our core demographic and we aren't going to spend valuable time and energy making Python work for the code they write in Office with curly quote marks. [...]
And yes, several students lost points for syntax errors because Word "helpfully" converted their quotation marks.
A valuable lesson learned: the tools you use *do matter*. Tooling is important. Details matter. -- Steven

To reinforce what others have said a bit: It is absolutely OK to expect people to write code with a code editor. Period. And having more than the alread two quote characters would be a mess. But this IS an issue, not with people writing code with tools meant for writing text, but by people copying and pasting code examples from systems that have mangled the text in these ways. I've encountered this a fair bit, notably when I wrote a whole bunch of instructional slides for a Python course in LaTeX, and it replaced quotes with nifty curly quotes -- I think even in verbatim mode. So when I, or my students, copy and pasted code, it was broken. So yes to Ned's suggestion: More informative syntax Error messages. Note that it IS a bit of a trick with this kind of thing: there could be who knows how many characters that *could* look kinda like meaningful symbols in Python. But catching the most common ones would help folks out. It would be good for linters to catch these too -- but that's up to the linter authors -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython

On May 10, 2020, at 03:47, Ned Batchelder <ned@nedbatchelder.com> wrote:
Can the error message actually include the Unicode character itself? A novice isn’t going to know what U+201c means, they may not be entirely sure what fancy quote means or how to search for it, but they will know what “ means and can search for it by just copying and pasting from the error message to the Find box in their editor. (I think we do include Unicode characters in other error messages when they come directly from the user’s input text. For example, if I try to 2+Spám(), the error message will have á in the string.)
On Sun, May 10, 2020 at 12:57:11PM -0700, Andrew Barnert via Python-ideas wrote:
Can the error message actually include the Unicode character itself?
I can think of cases where that could be confusing, or mess up the display of the error message. E.g. if it were an invisible character, or swapped to right-to-left display, or similar. So one would have to be careful about just blindly displaying an arbitrary Unicode character.
A novice isn’t going to know what U+201c means
And that's why we have user forums, Stackoverflow, r/learnpython and Google. There's a temptation to fill the error messages with more and more detail, but we should remember: - The users who would most benefit from that extra detail don't read error messages; this isn't just folklore, people have done real studies and found that beginners and end-users don't read error message. - And the longer the error message, the more intimidating they are to the beginners we are trying to help. Error messages should be brief and to the point, without being too terse. They have no obligation to explain all the whys and wherefores of the error. And no matter what you say, a large proportion of beginners will pay no attention to it at all. We shouldn't only think about how useful that extra detail will be the first time we see it, but how useful it will be the ten thousandth time we see it. If you can imagine your eyes glazing over the details in the error message, then that's a hint that it should have been there in the first place. (That's a general observation, not specifically aimed at Andrew's request for the character to be displayed.) -- Steven
On May 10, 2020, at 00:11, Steve Barnes <GadgetSteve@live.co.uk> wrote:
What can be done?
I think there’s another option (in addition to improving SyntaxError, not instead of it): Add a defancier module to the stdlib. It has functions that take some text and turn smart quotes into plain ASCII quotes, dashes and minuses into ASCII hyphens, etc., or just detect them and produce useful objects and/or text. And it’s a runnable module that can either lint or fix source code. Then instead of telling people who get this SyntaxError “Use a proper editor, and all the code you wrote so far has to be rewritten or fixed manually, and that’ll show you”, we can tell them “Use a proper editor in the future, but meanwhile you can fix your existing script with `python -m defancier -f script.py`“. And a simple IDE or editor mode that doesn’t want to come up with something better could run defancier on SyntaxError or on open or whenever and show the output in a nice way and offer a single-click fix. There’s nothing in the stdlib quite like this, but textwrap, tabnanny, 2to3, etc. are vaguely similar precedents. And it seems like the kind of thing that will evolve on about the right scale for the stdlib—new problems to add to the list come up about once a decade, not every few months or anything. The place I’d _really_ like this is Pythonista, which does an admirable job fighting iOS text input for me, but it’s not so helpful for fixing up pasted code. (And needless to say, I can’t just get a better editor/IDE; it’s by far the best option for the platform.) (By the way, the reason I used -f rather than —fix is that I can’t figure out how to get the iPhone Mail.app to not replace double hyphens with an em-dash, or even how to fix it when it does. All of the other fancifier stuff can be worked around pretty easily, but apparently not that one…)
On Sun, May 10, 2020 at 1:17 PM Andrew Barnert via Python-ideas < python-ideas@python.org> wrote:
Totally OT -- but just the other day, I was using a Google Sheets, and it kept converting "4, 5, 6" or "4-5-6" into a date. I could NOT figure out how to turn it off -- infuriating! Back OT: The fact that there are many ways that our text may get mangled in other systems does not mean Python should tolerate ambiguity. Having a "tabnanny-like" function / module in the stdlib would be nice, though I'd think a stand alone module in PyPi would be almost as good, and a good way to see if it gains traction. BTW -- there are a whole lot of Syntax Errors that a semi smart algorithm could provide meaningful suggestions about about. I'm pretty sure that's come up before on this list, but maybe "helpful" mode you could run Python in that would do that for all Syntax errors that it could. We could even have a way for folks to extend it with additional checks. Kind of like how git makes suggestions if you type something almost like a command. -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
I wonder if The Fuck could be customize to handle these improved error messages envisioned: https://github.com/nvbn/thefuck It's a lovely tool. I don't mind the minor profanity, but when I teach I add an alias of 'fix' for students to see instead. On Sun, May 10, 2020 at 5:34 PM Christopher Barker <pythonchb@gmail.com> wrote:
-- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On May 10, 2020, at 14:33, Christopher Barker <pythonchb@gmail.com> wrote:
Having a "tabnanny-like" function / module in the stdlib would be nice, though I'd think a stand alone module in PyPi would be almost as good, and a good way to see if it gains traction.
Good point. Plus, it might well turn out that, say, the right thing for most Windows users and the right thing for most iOS Pythonista users is sufficiently different that two separate defancier packages are better than a one-size-fits-all could be, which we’d find out a lot more easily if people go out and use it in the field than if we try to design it here.
BTW -- there are a whole lot of Syntax Errors that a semi smart algorithm could provide meaningful suggestions about about. I'm pretty sure that's come up before on this list, but maybe "helpful" mode you could run Python in that would do that for all Syntax errors that it could. We could even have a way for folks to extend it with additional checks.
This already exists on PyPI. Actually, there are a few different ones. One of them (I think friendly-tracebacks?) is very detailed. One of the authors sometimes posts about it here, when we’re talking about how some exception should be improved, with an example showing that they’ve already thought of it and done something better than is being proposed in the list.:) That one may already be a category killer. I looked over some of the others and the only thing that jumped out at me was that one of them (better-errors?) integrates really nicely into iPython and Jupyter (using iPython’s syntax coloring settings, making more use of line-drawing and box characters, etc.) But that doesn’t mean the category killer should be in the stdlib; I suspect they’re still improving it at a much faster pace than the stdlib could handle. But maybe the docs should link to it. The only problem is that the obvious places (like Interface Options section in the Usage docs) are things almost nobody reads…
On Sun, May 10, 2020 at 7:34 PM Andrew Barnert via Python-ideas < python-ideas@python.org> wrote:
Yes, please do contribute to support more cases (see below). :-)
Somebody called me?
Well, that's kind of you to say. I definitely had not thought of that one. Barebone ssue filed: https://github.com/aroberge/friendly-traceback/issues/45 ; I (or anyone else) will need to add more details. I really need to find the time ro resume work on friendly-traceback.... I do need to find a way to have friendly-traceback available as a plugin for VS Code, PyCharm, SublimeText and perhaps Jupyter notebooks. It can already work with Mu and Thonny. ( Due to the way Idle runs code and deals with exceptions, it is impossible to add it as a simple plugin to Idle, most unfortunately.) For anyone interested, even if you do not want to add support for other cases, feel free to file issues and suggest additions to friendly-traceback. André Roberge
On Sun, May 10, 2020 at 01:17:17PM -0700, Andrew Barnert via Python-ideas wrote:
I don't know anything about Mail.app, but in LibreOffice you can Ctrl-Z to underdo autocorrect without undoing the characters you typed. In my experience, autocorrect often is activated when you type a space or newline, and only looks back a single word at a time. So with a bit of extra work, you might be able to avoid triggering the autocorrect on the hyphens. Perhaps something like this? type: space hyphen space hyphen space f i x space backspace to delete the spaces forward arrow past the "fix" before typing another space I have found that variations of this seems to work with autocorrect on some systems. (Or just wait until you're back on a computer with a less annoying mail client before replying :-) -- Steven
On Sun, May 10, 2020 at 9:05 PM Steven D'Aprano <steve@pearwood.info> wrote:
I don't know anything about Mail.app, but in LibreOffice you can Ctrl-Z to underdo autocorrect without undoing the characters you typed.
I don't use iPhone, but I'm pretty sure it doesn't have a Ctrl-Z key on it :-) -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
Andrew, I already have a module that I include in a couple of widely used utilities at work that I called cmd_line_fixup (but I think that I like defancier better) it is used on the command line options prior to processing to fix several of these issues. This was written in response to the frequency of me getting emails saying "how do I get the utility to do X?" to which I would dash off a quick reply and get back "that doesn't work" - the users of these utilities include developers (who use other languages) and electrical test technicians and many of them are based in other countries where English is not their native tongue so explaining "You need to type what I sent you rather than paste it" was challenging. Potentially such a module could be smarter than my current one in that I currently just use a series of replaces to swap out everything but potentially user code could be using these characters legitimately inside of strings or comments e.g. the copywrite symbol. Steve Barnes -----Original Message----- From: Andrew Barnert <abarnert@yahoo.com> Sent: 10 May 2020 21:17 To: Steve Barnes <GadgetSteve@live.co.uk> Cc: python-ideas@python.org Subject: Re: [Python-ideas] Improve handling of Unicode quotes and hyphens On May 10, 2020, at 00:11, Steve Barnes <GadgetSteve@live.co.uk> wrote:
What can be done?
I think there’s another option (in addition to improving SyntaxError, not instead of it): Add a defancier module to the stdlib. It has functions that take some text and turn smart quotes into plain ASCII quotes, dashes and minuses into ASCII hyphens, etc., or just detect them and produce useful objects and/or text. And it’s a runnable module that can either lint or fix source code. Then instead of telling people who get this SyntaxError “Use a proper editor, and all the code you wrote so far has to be rewritten or fixed manually, and that’ll show you”, we can tell them “Use a proper editor in the future, but meanwhile you can fix your existing script with `python -m defancier -f script.py`“. And a simple IDE or editor mode that doesn’t want to come up with something better could run defancier on SyntaxError or on open or whenever and show the output in a nice way and offer a single-click fix. There’s nothing in the stdlib quite like this, but textwrap, tabnanny, 2to3, etc. are vaguely similar precedents. And it seems like the kind of thing that will evolve on about the right scale for the stdlib—new problems to add to the list come up about once a decade, not every few months or anything. The place I’d _really_ like this is Pythonista, which does an admirable job fighting iOS text input for me, but it’s not so helpful for fixing up pasted code. (And needless to say, I can’t just get a better editor/IDE; it’s by far the best option for the platform.) (By the way, the reason I used -f rather than —fix is that I can’t figure out how to get the iPhone Mail.app to not replace double hyphens with an em-dash, or even how to fix it when it does. All of the other fancifier stuff can be worked around pretty easily, but apparently not that one…)
By the way, did anyone else notice the irony that's Steve's examples of invalid code is actually perfectly valid? Copying and pasting into the interpreter shows that they are valid strings. On Sun, May 10, 2020 at 07:09:15AM +0000, Steve Barnes wrote:
When I first read this, I thought it was because the display font used by mail client doesn't distinguish the fancy Unicode quote marks from the ASCII quotes. But it does: Double: " vs “ ” Single: ' vs ‘ ’ (Obviously you can't see the glyphs as they are displayed in my editor, but trust me, they are visually distinct :-) But testing in the interpreter proves that they are regular ASCII quotes, not just look-alikes. So I thought that Steve made the opposite mistake, accidentally using regular ASCII quotes when he intended to use Unicode quotes. But it turns out that Steve's mail client sends emails with a HTML part and a plain text part, and the plain text part substitutes the ASCII quotes for smart quotes. Very clever! My mail client prefers the plain text part when it is available, which is usually exactly what I would want. But in this case, it confused me for a bit. -- Steven
So I thought that Steve made the opposite mistake, accidentally using regular ASCII quotes when he intended to use Unicode quotes. But it turns out that Steve's mail client sends emails with a HTML part and a plain text part, and the plain text part substitutes the ASCII quotes for smart quotes. Very clever! My mail client prefers the plain text part when it is available, which is usually exactly what I would want. But in this case, it confused me for a bit. -- Steven [Steve Barnes] So we currently have a situation where not only does whether code works or not depends on who typed it, in what environment, with what settings but also on the same factors for who received it - so I could use Outlook or Word to send a code fragment to 100 people and 5 say that is great it works and the other 95 end up thinking that there is something wrong with their installation. Personally I don't think this fits in with the pythonic way of thinking! Steve

On Mon, May 11, 2020 at 2:29 PM Steve Barnes <GadgetSteve@live.co.uk> wrote:
I agree, it doesn't. So the solution is: Don't send code via something that mangles it. It might discard your indentation, mutate your quotes, convert it to HTML and then insert newlines when it converts back to text at the other end, or helpfully translate all the language keywords into French (okay, I haven't seen THAT happen, but I've seen all the others). Code is text but it is not English text, and anything that tries to parse it as English will be just as wrong as something that tries to parse it as Fortran. If you can't stop your tool from misparsing your code, get a better tool. It's not like they're expensive or hard to obtain. ChrisA
On Mon, May 11, 2020 at 04:28:38AM +0000, Steve Barnes wrote:
You say "currently", but that has always been the case, and the further back you go, the worse it was.
While the actual problem is that you are sending code via a non-WYSIWYG medium that may modify what you type. If you want to send code via email, the most reliable method is to attach it as a .py file.
Personally I don't think this fits in with the pythonic way of thinking!
The Zen says differently: "Errors should never pass silently." It's not Python's responsibility to make up for lossy transmission methods such as mail servers which strip the high bit off every octet, or faulty hardware that randomly corrupts one byte in a thousand. And nor is it the interpreter's responsibility to guess what the user intended to type, or *should have* intended to type, in the face of editors which substitute characters. -- Steven
-----Original Message----- From: Steven D'Aprano <steve@pearwood.info> Sent: 11 May 2020 06:02 To: python-ideas@python.org Subject: [Python-ideas] Re: Improve handling of Unicode quotes and hyphens On Mon, May 11, 2020 at 04:28:38AM +0000, Steve Barnes wrote:
You say "currently", but that has always been the case, and the further back you go, the worse it was. [Steve Barnes] True - apart from the older email clients being less "helpful".
While the actual problem is that you are sending code via a non-WYSIWYG medium that may modify what you type. If you want to send code via email, the most reliable method is to attach it as a .py file. [Steve Barnes] My employer mandates the communication method(s) (as do many others). They also block unsafe "attachments" such as .py & .bat files (even when zipped). In any case I am often trying to tell the end user how to invoke existing code that they already have from the command line, (especially when they have stored files in folders with spaces, ampersands, hyphens, etc., in the path).
Personally I don't think this fits in with the pythonic way of thinking!
The Zen says differently: "Errors should never pass silently." It's not Python's responsibility to make up for lossy transmission methods such as mail servers which strip the high bit off every octet, or faulty hardware that randomly corrupts one byte in a thousand. And nor is it the interpreter's responsibility to guess what the user intended to type, or *should have* intended to type, in the face of editors which substitute characters. [Steve Barnes] What I would prefer is an error message that actually tells the end user which specific character(s) they have got wrong rather than something is wrong after all "Explicit is better than implicit" would suggest that "illegal character x (Unicode u)" would be more pythonic than the current error message. -- Steven _______________________________________________ Python-ideas mailing list -- python-ideas@python.org To unsubscribe send an email to python-ideas-leave@python.org https://mail.python.org/mailman3/lists/python-ideas.python.org/ Message archived at https://mail.python.org/archives/list/python-ideas@python.org/message/3AO3MP... Code of Conduct: http://python.org/psf/codeofconduct/
A third-party module on PyPI for "fix-the-horrible-things-Outlook-does" could be useful. There is no way the standard library can or should keep up with the newest mangling techniques mail handlers employ in this week's version. I don't understand what you mean by the current interpreter not telling you which character is bad. It puts a pointer right under the problem character in the error message. Nothing is being hidden, even if the code-manglers can do pretty insidious things... different in every version, for every sender, and for every recipient. On Mon, May 11, 2020 at 3:24 AM Steve Barnes <GadgetSteve@live.co.uk> wrote:
-- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
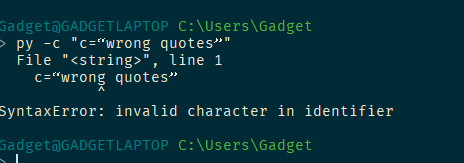
From: David Mertz <mertz@gnosis.cx> Sent: 11 May 2020 08:34 To: Steve Barnes <GadgetSteve@live.co.uk> Cc: python-ideas@python.org Subject: Re: [Python-ideas] Re: Improve handling of Unicode quotes and hyphens A third-party module on PyPI for "fix-the-horrible-things-Outlook-does" could be useful. There is no way the standard library can or should keep up with the newest mangling techniques mail handlers employ in this week's version. I don't understand what you mean by the current interpreter not telling you which character is bad. It puts a pointer right under the problem character in the error message. Nothing is being hidden, even if the code-manglers can do pretty insidious things... different in every version, for every sender, and for every recipient. [Steve Barnes] Actually, in the case of the “wrong quotes” it puts the pointer under the character before the space character or at the end of the line (if you have a fixed spacing font – worse if you don’t) – it still doesn’t tell you which character is invalid. [cid:image001.png@01D62773.50D55990][cid:image002.png@01D62773.73A95D90]
On Mon, May 11, 2020 at 6:09 PM Steve Barnes <GadgetSteve@live.co.uk> wrote:
Actually, in the case of the “wrong quotes” it puts the pointer under the character before the space character or at the end of the line (if you have a fixed spacing font – worse if you don’t) – it still doesn’t tell you which character is invalid.
This is actually a good point. Having an invalid character in an identifier shows the caret at the end of the identifier, regardless of where in the identifier the error is. That's something that could be improved on, regardless of the quote issue. There's a new parser on its way (PEP 617), so it'd be something to consider on that basis. ChrisA

{kind=link}
{kind=link}

MRAB writes:
On 2020-05-11 09:21, Chris Angelico wrote:
On Mon, May 11, 2020 at 6:09 PM Steve Barnes <GadgetSteve@live.co.uk> wrote:
This is actually a good point.
But it's a different point:
This isn't a parsing problem as such. I am not an expert on the parser, but what's going is something like this: the parser (tokenizer) sees the character "=" and expects an operator. Next, it sees something that is not "=" and not whitespace, so it expects a literal or an identifier. " “" is not parsable as the start of a literal, so the parser consumes up to the next boundary character (whitespace or operator). Now it checks for the different types of barewords: keywords and identifiers, and neither one works. Here's the critical point: identifier fails because the tokenizer tries to match a sequence of Unicode word constitituents, and " “" isn't one. So it fails the sequence of non-whitespace characters, and points to the end of the last thing it saw. So I see no reason why we need to transition to the new parser to fix this. (And the new parser (as of the last comment I saw from Guido) probably doesn't help: he kept the tokenizer.) We just need to make a second pass over the invalid identifier and identify the invalid characters it contains and their positions.
As a permanent resident of Japan, I DEMAND that YOU PERSONALLY implement the SAME TEST for all the Japanese "full-width" operator characters. :-) (This is actually a very common user error, and it's very hard to tell the difference by sight in many fonts, same as directed quotes vs. ASCII quotes in English, but for the whole ASCII repertoire.) This could get really ridiculous. I think the suggestion that whatever test it is that identified the "invalid character in identifier" defect be fixed to report both the position of the first such character and the list of all such characters is appropriate. The "wrong kind of quote" stuff belongs elsewhere, and in particular in a linter. Here's an quasi-algorithmic suggestion for that: use the Unicode confusables list (and I think there are many properties such as "related" and "paired" characters that can be indicative). Haven't looked at it in a while; it may not catch all the issues here. But it would be a good start, and quite comprehensive. It might suggest other things linters could be doing, too. Steve

Wow - a lot going on this thread - despite what to do seemingly really obvious: of course showing which character triggered the error along with a proper plain English phrase is enough. The Fortran anecdote in the beginning of the thread is a false analogy, since the program _will_ _not_ run with unexpected results in Python, and, being in a PC or submitting code in a testing pipeline it takes seconds to retry. Fixing spurious characters back to their ASCII could be placed in a popular code-formatting tool like Black. js -><- On Wed, 13 May 2020 at 09:31, Richard Damon <Richard@damon-family.org> wrote:
On May 13, 2020, at 05:31, Richard Damon <Richard@damon-family.org> wrote:
Isn’t this what already happens? >>> import tokenize, io >>> def tok(s): return list(tokenize.tokenize(io.BytesIO(x.encode()).readline)) >>> tok('spam(“Abc”)') When I run this in 3.7, the fourth token is an ERRORTOKEN with string ”, then there’s a NAME with Abc, then another ERRORTOKEN with “. And reading the Lexical Analysis chapter of the docs, this seems correct. The smart quote is not a possible xid_start, or any other start of any token terminal, so it should immediately fail as an error.(The fact that the tokenizer eats it, generates an ERRORTOKEN, and then lexes the Abc as a NAME, rather than throwing an exception or otherwise punting, is a pretty nice error-recovery attempt, and seems perfectly reasonable.) Is that not true for the internal C tokenizer? Or is it true, but the parser or the error generating code isn’t taking advantage of it? (By the way. I’m pretty sure this behavior isn’t specific to 3.7, but has been that way back into the mists of whenever you could first write old-style import hooks, even up to the way error recovery works. I’ve taken advantage of this behavior in experimenting with new syntax. If your new syntax is not just unambiguous at the parser level, but even at the lexical level, you can just scan the token stream for your matching ERRORTOKEN.)
Executive summary: AFAICT, my guess at what's going on in the C tokenizer was exactly right. It greedily consumes as many non-operator, non-whitespace characters as possible, then validates. It does this because it is tokenizing a stream of bytes encoding characters as UTF-8. Andrew Barnert via Python-ideas writes:
It would be bizarre if true. Why would the error reporting randomly take an invalid character and glom it on to the following characters to create an invalid identifier, then report that? I suspect that the Python version is a tiny bit smarter than the C version because it naturally processes (Unicode) characters while the C code processes (UTF-8) bytes by design (from the now-ancient PEP 263), but the Python code is left as an exercise for the interested reader. ;-) Here's the relevant part of tokenizer.c:tok_get from Python 3.8 (all comments are mine, except for part of the comment about processing bfru strings): /* Note note note: "character" seems to mean C char, ie, byte! This is just from the declaration in struct tok_state, I haven't carefully confirmed that the program text being tokenized is UTF-8 bytes but that's what PEP 263 says to do, and it looks like that's what the I/O code is doing. Which is true doesn't matter to my analysis because a UTF-8 byte c is part of a non-ASCII character if and only if c >= 128, while a Unicode character c is non-ASCII if and only if c >= 128. Identifier consumption stops only when c is ASCII, or EOF; it can only stop on a UTF-8 character boundary. So this algorithm works exactly the same whether you use UTF-8-encoded bytes or Unicode characters. is_potential_identifier_start includes letters, underscore, and ALL non-ASCII. is_potential_identifier_char includes all of those, plus digits. */ /* I suspect the Python code uses an accurate test here, rather than these accurate-for-ASCII-not-so-for-non-ASCII tests. */ /* l. 24 */ #define is_potential_identifier_start(c) (\ (c >= 'a' && c <= 'z')\ || (c >= 'A' && c <= 'Z')\ || c == '_'\ || (c >= 128)) #define is_potential_identifier_char(c) (\ (c >= 'a' && c <= 'z')\ || (c >= 'A' && c <= 'Z')\ || (c >= '0' && c <= '9')\ || c == '_'\ || (c >= 128)) /* Skip 1000+ lines of I/O code. */ /* l. 1368 */ static int tok_get(struct tok_state *tok, char **p_start, char **p_end) { /* Skip initialization and handling of indentation, whitespace, and comments. */ /* We attempt to parse an identifier as the first guess. We start with code that handles string prefixes "bfru". Otherwise we just consume potential identifier characters until we run into a character (byte) that is not a potential identifier character. If any character is not ASCII, set nonascii flag. */ /* l. 1492 */ nonascii = 0; if (is_potential_identifier_start(c)) { while (1) { /* Process the various legal combinations of b"", r"", u"", and f"". Complicated multibranch if-else-if ... statement omitted. If none, break out of while before getting next c. */ c = tok_nextc(tok); if (c == '"' || c == '\'') { goto letter_quote; } } /* If we get here, we may have seen some of bfru, but it's not legal string syntax, so continue trying to extract an identifier. In particular, if the first character c was non-ASCII, we broke out of the while loop doing nothing, so c is still that non-ASCII character. */ while (is_potential_identifier_char(c)) { if (c >= 128) { nonascii = 1; } c = tok_nextc(tok); } /* Last thing we saw was not part of the potential identifier. Unget it. */ tok_backup(tok, c); /* If this is a PGEN build, verify_identifier always returns true, because PGEN doesn't have access to Python's Unicode routines. That would necessarily have to check valid identifier after returning the token stream. Otherwise verify_identifier validates the string using PyUnicode_IsIdentifier. */ if (nonascii && !verify_identifier(tok)) { return ERRORTOKEN; } So there you are.
(By the way. I’m pretty sure this behavior isn’t specific to 3.7,
As mentioned above, this code is from 3.8, and the algorithm (transcode program text to UTF-8 and process bytewise, using the fact that all characters Python has special knowledge of are ASCII) is specified in PEP 263. Steve
On May 14, 2020, at 20:01, Stephen J. Turnbull <turnbull.stephen.fw@u.tsukuba.ac.jp> wrote:
Well, it like like it’s not quite “non-operator, non-whitespace characters”, but rather “ASCII identifier or non-ASCII characters”:
(That’s the initial char rule; the continuing char rule is similar but of course allows digits.) So it won’t treat a $ or a ^G as potentially part of an identifier, so the caret will show up in the right place for one of those, but it will treat an emoji as potentially part of an identifier, so (if that emoji is immediately followed by legal identifier characters, ASCII or otherwise) the caret will show up too far to the right. I’m still glad the Python tokenizer doesn’t do this (because, as I said, I’ve relied on the documented behavior in import hooks for playing around with Python, and they use the Python tokenizer), but that doesn’t matter for the C tokenizer, because its output is not public, it’s only seen by the parser. And I think you can prove that the error caret placement is the only thing that could be affected by this shortcut.[1] And if it makes the tokenizer faster, or just simpler to maintain, that could easily be worth it. (At least until one of those periodic “Python should add this Unicode operator” proposals actually gets some traction, but I don’t see that as likely any time soon.) —- [1] Python only allows non-ASCII characters in identifiers, strings, and comments. Therefore, any string of characters that should be tokenized as a sequence of 1 ERRORTOKEN followed by 0 or more NAME and ERRORTOKEN tokens by the documented rule (and the Python code) will still give you a sequence of 1 ERRORTOKEN followed by 0 or more NAME and ERRORTOKEN tokens by the C code, just not necessarily the same such sequence. And any such sequence will be parsed as a SyntaxError pointing at the end of the initial ERRORTOKEN. So, the caret might be somewhere else within that block of identifier and non-ASCII characters, but it will be somewhere within that block.

10.05.20 10:09, Steve Barnes пише:
Two consequent hyphens can look as a dash, and can be replaced with a dash by "typographer", but they have different meaning that a single minus.
It is ambiguous. For example, in Ukraine we use pairs of quotation marks « and » or „ and “. But “ is used as an opening quotation mark in English, and » and « are used with opposite meaning in Swedish. Single low-9 quotation mark ‚ can be confused with a comma, single angle quotation marks ‹ and ❮ can be confused with <.
https://bugs.python.org/issue40593 Also, "in identifier" is incorrect in most cases, because the invalid character does not look like a part of identifier in most cases.
On Sun, May 10, 2020 at 07:09:15AM +0000, Steve Barnes wrote about Unicode dashes and quotes sneaking into code:
No, I think that in the broader picture, they are doing the correct thing by using nicer typographical quotes and dashes for non-source code. Even if they would listen, we should not ask :-)
2. Tell all users that they need to use a "proper" editor or IDE - This seems like adding an additional barrier to new & casual users.
When people decide to learn, say, wood working, or carpentry, and try to make holes in timber by gauging the wood with a screwdriver^1 but are told to get themselves a drill instead, is this seen as "an additional barrier" or just part of the process of learning a new skill set? A cheap drill costs about AUD$50 and another $25 for a set of drill bits. A cheap IDE or programmers editor costs nothing but a bit of time and hard disk space. I think we can expect would-be programmers to *not* use MS Word to write Python code. If they aren't willing to invest the time and energy to install, then they probably won't invest the time and energy to learn how to program either.
3. Better yet tell them to use a "proper" OS like .... - At the very least many of us have to use Windows at work.
It's perfectly possible to write code on Windows without paying lots of money for expensive commercial IDEs.
Python already accepts hyphens as minus -- only *one* kind though, the so-called ASCII "HYPHEN-MINUS". What it doesn't accept is actual minus signs, '\N{MINUS SIGN}', as minus signs. I don't mind seeing rich unicode in strings, or even comments, but I wouldn't (yet!) want to see it in executable code, I don't think the state of the art of editing tooling and font support is quite ready for it yet. I still see far too many "Missing Character Glyphs" and supposed monospaced text where there's always *one* character that is a single pixel short of the consistent spacing. And I still don't know how to type − in my editor, I have to copy and paste it from elsewhere.
I think people should experiment with preprocessors to get a feel for how well they work before moving it into the interpreter. I think that David(?) may have a Vim or Emacs mode that allows him to use Unicode chars as syntax?
More informative error messages are good :-) ^1 I have literally done that, when I was too lazy to go into the garage and get the drill. So I stabbed at the timber enough to make an indentation so the screw would bite. It actually works! Just not well. -- Steven
On Sun, May 10, 2020 at 4:03 AM Steven D'Aprano <steve@pearwood.info> wrote:
I think that David(?) may have a Vim or Emacs mode that allows him to use Unicode chars as syntax?
I use the vim-conceal plugin: https://github.com/khzaw/vim-conceal. I know that something similar exists for Emacs, but don't remember the name. What this does though is not change anything about the underlying ASCII characters in the code, but rather it substitutes particular character sequences (perhaps in regex context) with other things, such as fancy Unicode characters. So as typing goes, I still type e.g. the letter 'i' followed by the letter 'n' and a space, and the screen simply displayed the U+2208 (∈) character. But on disk, and for Python, it's only still just 'in'. On my own system, I've learned the Unicode code points for the common things like n-dashes and m-dashes that I use. I actually don't know the vim shortcuts for other special things, although I probably should. Still, the vim digraphs are always going to be fewer than all the Unicode code points, even if some useful ones are included (and somewhat mnemonic). But indeed, entry of all those special characters is going to be more work than the characters directly on my keyboard, in any event.
I wouldn't mind messages that actually looked specifically for some of those common annoying auto-substitutions. E.g.: % python ~/tmp/wrongchar.py File "/home/dmertz/tmp/wrongchar.py", line 1 x = 2014 – 2013 ^ SyntaxError: invalid character in identifier The hyphen really does look a lot like the n-dash that is on screen. And I think that's one of those substitutions that word processors and email clients often do. Maybe a collection of the top 20 such common substitutions with some fitting message. I dunno "SyntaxError: invalid character U+2013 may be substitution of ASCII dash". -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
A lot of this reminds me of a story told by a programming instructor in the 70's, he submitted a FORTRAN program deck to the machine, the complier gave him a warning on a statement which read INTEGER misspelled, it than ran the program, but IGNORED the statement, even though it clearly understood what he meant, and got wrong answers because the compiler just used the default REAL type for the variable, which took him a while to figure out what the error was. (Computer time was limited enough then that you didn't want to just rerun fixing the typo that it pointed out). He was confused about how the program obviously knew what he meant by the message, but didn't process the program right. An error like character (whatever) is not a quote (or is not a minus sign) seems similar. It is one thing to not recognize a funny character in the language, but to actually parse it well enough to give a message that says in effect, that may look like a quote to you, but I am not going to treat is as one, sounds perverse in the language. If we are going to go to the effort to detect that particular character, it makes more sense to make it actually DO the obvious thing. If not, the the current error seems fine, especially if we could include more details. An 'invalid character' message, that doesn't tell you WHICH character is invalid seems like it is holding back, If it included the bad character, or pointed to it, then the error becomes a lot more clear.
On Sun, May 10, 2020 at 2:17 PM Richard Damon <Richard@damon-family.org> wrote:
There are, I think, 28 quote-like characters in Unicode ( https://unicode-table.com/en/sets/quotation-marks/). Actually, probably more; I think U-0060, backtick/grave is not included, for example. Some of those are really supposed to be in particular pairs, others are interchangeably left or right. Which pairs combine is specific to the human language you write in, and also to the style guide you are following. I very much want NOT to make a set of rules for what quotes are allowed when. But simply detecting "that's a quote character, but not the kind Python likes" is much easier than that. Obviously, all of these fancy-quotes are perfectly fine inside of generic Python quotes, as strings. "Doing the obvious thing" is throwing a SyntaxError, but ideally one that is a little more descriptive than currently, as Ned and others have stated. -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On Sun, 10 May 2020 14:13:37 -0400 Richard Damon <Richard@Damon-Family.org> wrote:
“In the face of ambiguity, refuse the temptation to guess.” There should be one-- and preferably only one --obvious way to do it. Your argument is that it's not ambiguous. My argument is that it's not within the Python grammar, and therefore it is ambiguous. Also, that forever precludes using those other quotation characters for something else in the future.
Agreed. -- “Atoms are not things.” – Werner Heisenberg Dan Sommers, http://www.tombstonezero.net/dan
On Sun, May 10, 2020 at 02:13:37PM -0400, Richard Damon wrote:
How did the compiler understand what he meant? If INTEGER was misspelled, how is the compiler supposed to know that ITEGER or INREGER or whatever misspelling he used was actually supposed to mean INTEGER?
Yes, programming was harder in the 1970s. The tooling was limited and inconvenient.
It might *sound* perverse, but what is genuinely perverse is Do What I Mean systems that try to *guess* what you mean rather than allowing the user to correct their own mistake. Only the user truly knows what they intended. http://www.catb.org/jargon/html/D/DWIM.html DWIM will just train beginners to be lazy, sloppy, thoughtless coders, since "the interpreter knows what I meant" -- until it doesn't. Even if the DWIM gets it right 9 times out of 10, the pain and difficulty in that remaining case will outweigh the convenience of the other 9 times.
Is `x‒y` meant to be an identifier with a hyphen, or the subtraction x−y? How about `x‐y` or `x‑y` or `x–y` or `xーy`? (All of the above are distinct Unicode dash-like characters. Only one of them is an actual minus sign.) In 2020 we don't have to wait two weeks for our next share of computer time. Correcting an error and re-running the code is easy, there is no real advantage in having the interpreter try to guess what the user probably meant to write, instead of running what they actually wrote and failing if it is not legal code.
The SyntaxError already points at, or just after, the invalid character. py> x−y File "<stdin>", line 1 x−y ^ SyntaxError: invalid character in identifier -- Steven
My personal experience of the most common problematic substitutions by tools such as Outlook, Word & some web tools: 1. Double Quotes \u201c & \u201d “” 2. Single Quotes \u2018 & \u2019 ‘’ 3. The m-hyphen \2013 – 4. Copyright © \xa9 and others, Registered ® \xae and trademark ™ \u2122 5. Some fractions e.g. ½ ¼ 6. Non-breaking spaces From: David Mertz <mertz@gnosis.cx> Sent: 10 May 2020 18:33 To: Steven D'Aprano <steve@pearwood.info> Cc: python-ideas <python-ideas@python.org> Subject: [Python-ideas] Re: Improve handling of Unicode quotes and hyphens On Sun, May 10, 2020 at 4:03 AM Steven D'Aprano <steve@pearwood.info<mailto:steve@pearwood.info>> wrote: I think that David(?) may have a Vim or Emacs mode that allows him to use Unicode chars as syntax? I use the vim-conceal plugin: https://github.com/khzaw/vim-conceal. I know that something similar exists for Emacs, but don't remember the name. What this does though is not change anything about the underlying ASCII characters in the code, but rather it substitutes particular character sequences (perhaps in regex context) with other things, such as fancy Unicode characters. So as typing goes, I still type e.g. the letter 'i' followed by the letter 'n' and a space, and the screen simply displayed the U+2208 (∈) character. But on disk, and for Python, it's only still just 'in'. On my own system, I've learned the Unicode code points for the common things like n-dashes and m-dashes that I use. I actually don't know the vim shortcuts for other special things, although I probably should. Still, the vim digraphs are always going to be fewer than all the Unicode code points, even if some useful ones are included (and somewhat mnemonic). But indeed, entry of all those special characters is going to be more work than the characters directly on my keyboard, in any event.
I wouldn't mind messages that actually looked specifically for some of those common annoying auto-substitutions. E.g.: % python ~/tmp/wrongchar.py File "/home/dmertz/tmp/wrongchar.py", line 1 x = 2014 – 2013 ^ SyntaxError: invalid character in identifier The hyphen really does look a lot like the n-dash that is on screen. And I think that's one of those substitutions that word processors and email clients often do. Maybe a collection of the top 20 such common substitutions with some fitting message. I dunno "SyntaxError: invalid character U+2013 may be substitution of ASCII dash". -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
Reviving (briefly an old thread) On Mon, May 11, 2020 at 2:13 AM Steve Barnes <GadgetSteve@live.co.uk> wrote:
SNIP As part of this discussion, it was suggested that it would be useful if some more useful messages could be given about the use of some unicode "fancy quotes". Just in case some people were considering "wasting" time on this: = = = = $ python -m friendly_traceback scratch.py Python exception: SyntaxError: invalid character in identifier A SyntaxError occurs when Python cannot understand your code. Python could not understand the code in the file 'scratch.py' beyond the location indicated below by --> and ^. 1: def squares(n): -->2: print(“Squares:”) ^ Likely cause based on the information given by Python: Did you use copy-paste? Python indicates that you used some unicode characters not allowed as part of a variable name; this includes many emojis. However, I suspect that you used a fancy unicode quotation mark instead of a normal single or double quote for a string. = = = This is just one of many cases now correctly identified by friendly-traceback. André Roberge
Like it! Sent from Samsung Mobile on O2 Get Outlook for Android<https://aka.ms/ghei36> ________________________________ From: André Roberge <andre.roberge@gmail.com> Sent: Wednesday, August 5, 2020 7:54:06 PM To: Steve Barnes <GadgetSteve@live.co.uk> Cc: python-ideas@python.org <python-ideas@python.org> Subject: Re: [Python-ideas] Re: Improve handling of Unicode quotes and hyphens Reviving (briefly an old thread) On Mon, May 11, 2020 at 2:13 AM Steve Barnes <GadgetSteve@live.co.uk<mailto:GadgetSteve@live.co.uk>> wrote: My personal experience of the most common problematic substitutions by tools such as Outlook, Word & some web tools: 1. Double Quotes \u201c & \u201d “” 2. Single Quotes \u2018 & \u2019 ‘’ 3. The m-hyphen \2013 – 4. Copyright © \xa9 and others, Registered ® \xae and trademark ™ \u2122 5. Some fractions e.g. ½ ¼ 6. Non-breaking spaces SNIP As part of this discussion, it was suggested that it would be useful if some more useful messages could be given about the use of some unicode "fancy quotes". Just in case some people were considering "wasting" time on this: = = = = $ python -m friendly_traceback scratch.py Python exception: SyntaxError: invalid character in identifier A SyntaxError occurs when Python cannot understand your code. Python could not understand the code in the file 'scratch.py' beyond the location indicated below by --> and ^. 1: def squares(n): -->2: print(“Squares:”) ^ Likely cause based on the information given by Python: Did you use copy-paste? Python indicates that you used some unicode characters not allowed as part of a variable name; this includes many emojis. However, I suspect that you used a fancy unicode quotation mark instead of a normal single or double quote for a string. = = = This is just one of many cases now correctly identified by friendly-traceback. André Roberge
I'm all for clear and helpful error messages, but this feels a tad too verbose (and even a bit patronizing) to me. But the highlighting of character look-alikes is very helpful. Perhaps something like: """ SyntaxError: invalid character in identifier -->2: print(“Squares:”) ^ An identifier contains one or more unallowed Unicode characters. It is likely the "curly quote" unicode quotation mark, rather than the required ASCII single or double quote was used for a string. """ I'm assuming that this would detect some of the common "look alikes" and give a specific suggestion as above. Keep in mind that anyone coding Python is going to see a LOT of SyntaxErrors -- we don't need to present a message as though they've never seen such an error before. But it IS helpful to point out errors that are hard to see with a glance at the code. -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
On Thu, Aug 6, 2020 at 3:40 AM Christopher Barker <pythonchb@gmail.com> wrote:
You raise some very good points. Here's a different output from the same program, followed by some explanation for context. = = = $ python -im friendly_traceback --verbosity 8 raise_syntax_error75 SyntaxError: invalid character in identifier 1: """Should raise SyntaxError: invalid character in identifier for Python <=3.8 2: and SyntaxError: invalid character '«' (U+00AB) in Python 3.9""" -->3: a = « hello » ^ Python indicates that you used some unicode characters not allowed as part of a variable name; this includes many emojis. However, I suspect that you used a fancy unicode quotation mark instead of a normal single or double quote for a string. This can happen if you copy-pasted code. = = = Comments: 1. Friendly-traceback is primarily intended for beginners who do not know what a SyntaxError or a NameError means. This is why it normally includes, by default, [quote] a message as though they've never seen such an error before [/quote]. They also might not know what "an identifier" means, but likely have seen "variable name". 2. Friendly-traceback is designed to support translation. Currently, all the explanations provided are available in French and English, and someone is working on a Chinese translation. Thus there might be a bit of duplication between the message provided by Python ("invalid character in identifier") always shown "as is", and the longer explanation given by friendly-traceback. 3. It allows one to select a "verbosity level". Up until a few minutes ago, the available verbosity levels were 0 to 9 - but did not include a level 8 (for historical reasons), each level providing a subset of all possible information. (The default level leaves out the normal Python traceback). Thanks to your comment, I finally filled a slot for level 8, which is what you see above. (This addition will be part of the next release on pypi). Note that the location of the ^ might be messed up in this email. 4. The original discussion mentioned that using the wrong types of quotes most often occurred when beginners copy-pasted some code from an ebook or a website. This is why the message mentions it ... but I've modified it so that it is, hopefully, less patronizing. Thanks again for your comments. Hopefully, the changes I have made are an acceptable compromise between what you suggested and what might be useful for a complete beginner. André Roberge
Thanks to your comment, I finally filled a slot for level 8, which is what you see above. (This addition will be part of the next release on
As this is a third party package, you, of course, can do what you want :-), But I would likew to see more communicative error messages in standard Python as well, and I think your package could be a great prototype -- thanks! On Thu, Aug 6, 2020 at 2:57 AM André Roberge <andre.roberge@gmail.com> wrote: 3. It allows one to select a "verbosity level". This is great! Sorry I neglected to dig deeper earlier and see that option. Given there are choices, I take it all back :-) Nice work! pypi). This looks good to me, thanks. Hmm -- I may start recommending this package to my newbie students :-) -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
On Sun, May 10, 2020 at 4:00 AM Steven D'Aprano <steve@pearwood.info> wrote:
Sometimes people are forced to use Word to type code. One example is creating user manuals. Another example: As a current computer science college student, last fall I had an operating systems professor who gave exams by posting the questions online and giving us 24 hours to write and upload our answers (with the exam being closed-book and on a 2-hour time limit "on the honor system"). Several of the questions required us to write Bash scripts or Python functions, and we were required to write all of that code, along with all of our other exam answers, several of which were essay questions, in Microsoft Word and then export the whole mess as a single PDF file to be uploaded. We were not allowed to submit multiple files, or zip files, or anything at all except one single PDF file containing all of our answers and code. So no, sometimes people don't get a choice of what to type code in. I would have much rather typed my code in VS Code or Notepad++ and submitted a zip file with the scripts in individual files and the essay responses in a separate Word or PDF file, but that would have earned me a grade of zero on the exams. And yes, several students lost points for syntax errors because Word "helpfully" converted their quotation marks. I'm happy that professor retired after fall semester and that I'll never have to take another class with him.
Why would you use Word? LaTeX exists, and will export to PDF. Heck, the PDF export from Jupyter is quite good (by way of LaTeX). On Sun, May 10, 2020, 7:40 PM Jonathan Goble < Several of the questions required us to write Bash scripts or Python functions, and we were required to write all of that code, along with all of our other exam answers, several of which were essay questions, in Microsoft Word and then export the whole mess as a single PDF file to be uploaded. We were not allowed to submit multiple files, or zip files, or anything at all except one single PDF file containing all of our answers and code.
On Sun, May 10, 2020 at 8:08 PM David Mertz <mertz@gnosis.cx> wrote:
This exam format was dropped on us with short notice before the midterm and we didn't have time to set up and learn brand-new tooling. Also, this was a freshman-level course, and I highly doubt more than a tiny fraction of the class had even heard of LaTeX, much less knew how to use it (I've definitely heard of it, but haven't the slightest clue how to use it myself). And as the course was many students' first introduction to Python (we only covered the bare basics of the language), Jupyter was again something most students in the class had probably never heard of. The course's primary focus was on introducing students to the usage of the command line interface and to the usage of Linux in general, and Python was a one-week side note to that. Most of the course centered on Bash and on general OS concepts (processes, virtual memory, etc.).
On Sun, May 10, 2020 at 07:39:32PM -0400, Jonathan Goble wrote:
Sometimes people are forced to use Word to type code. One example is creating user manuals.
MS Word is not the only word processor capable of creating user manuals. The LibreOffice people, and others, would like a word :-) If you are a professional writing and formatting an entire book in Word or LibreOffice or some other application, then you can be expected to solve this problem for yourself. (Turn Smart Quotes off.) There are a couple of professionally published Python books written using Restructed Text, Sphinx and Python. So people do have a choice, or at least a technical choice.
How would your professor know that you did the actually typing in Word, instead of doing the sensible thing and typing your code in a text editor and then copying and pasting it into the Word after turning Smart Quotes off?
So no, sometimes people don't get a choice of what to type code in.
Here is an actual example where the people writing actually had no choice, rather than having choices but failed to take advantage of them. I know of a case a company that was called in to solve a problem with desktop PCs at a correctional institution. The PCs were locked down to only approved applications, which included Office but absolutely no plain text editors. Office was required so that the inmates could participate in educational programs. It also included Python. You can see where this is going, I'm sure. It turned out that one of the inmates had typed up a simple Python game in Word, saved it as plain text, and somehow managed to find a way to get access to the command prompt and run it as a script. Never underestimate the ingenuity of bored, intelligent people with a lot of time on their hands. So this was a case where the user *genuinely* had no choice but to use Office, not just because they didn't know better or couldn't be bothered. But the bottom line is, so what? Why should we care about such incredibly narrow niches? - writers who don't know how to turn Smart Quotes off in Word; - students sitting a very badly designed exam; - inmates with Office and Python but no text editor. I'm sorry to all those people, but they are not our core demographic and we aren't going to spend valuable time and energy making Python work for the code they write in Office with curly quote marks. [...]
And yes, several students lost points for syntax errors because Word "helpfully" converted their quotation marks.
A valuable lesson learned: the tools you use *do matter*. Tooling is important. Details matter. -- Steven
To reinforce what others have said a bit: It is absolutely OK to expect people to write code with a code editor. Period. And having more than the alread two quote characters would be a mess. But this IS an issue, not with people writing code with tools meant for writing text, but by people copying and pasting code examples from systems that have mangled the text in these ways. I've encountered this a fair bit, notably when I wrote a whole bunch of instructional slides for a Python course in LaTeX, and it replaced quotes with nifty curly quotes -- I think even in verbatim mode. So when I, or my students, copy and pasted code, it was broken. So yes to Ned's suggestion: More informative syntax Error messages. Note that it IS a bit of a trick with this kind of thing: there could be who knows how many characters that *could* look kinda like meaningful symbols in Python. But catching the most common ones would help folks out. It would be good for linters to catch these too -- but that's up to the linter authors -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
On May 10, 2020, at 03:47, Ned Batchelder <ned@nedbatchelder.com> wrote:
Can the error message actually include the Unicode character itself? A novice isn’t going to know what U+201c means, they may not be entirely sure what fancy quote means or how to search for it, but they will know what “ means and can search for it by just copying and pasting from the error message to the Find box in their editor. (I think we do include Unicode characters in other error messages when they come directly from the user’s input text. For example, if I try to 2+Spám(), the error message will have á in the string.)
On Sun, May 10, 2020 at 12:57:11PM -0700, Andrew Barnert via Python-ideas wrote:
Can the error message actually include the Unicode character itself?
I can think of cases where that could be confusing, or mess up the display of the error message. E.g. if it were an invisible character, or swapped to right-to-left display, or similar. So one would have to be careful about just blindly displaying an arbitrary Unicode character.
A novice isn’t going to know what U+201c means
And that's why we have user forums, Stackoverflow, r/learnpython and Google. There's a temptation to fill the error messages with more and more detail, but we should remember: - The users who would most benefit from that extra detail don't read error messages; this isn't just folklore, people have done real studies and found that beginners and end-users don't read error message. - And the longer the error message, the more intimidating they are to the beginners we are trying to help. Error messages should be brief and to the point, without being too terse. They have no obligation to explain all the whys and wherefores of the error. And no matter what you say, a large proportion of beginners will pay no attention to it at all. We shouldn't only think about how useful that extra detail will be the first time we see it, but how useful it will be the ten thousandth time we see it. If you can imagine your eyes glazing over the details in the error message, then that's a hint that it should have been there in the first place. (That's a general observation, not specifically aimed at Andrew's request for the character to be displayed.) -- Steven
On May 10, 2020, at 00:11, Steve Barnes <GadgetSteve@live.co.uk> wrote:
What can be done?
I think there’s another option (in addition to improving SyntaxError, not instead of it): Add a defancier module to the stdlib. It has functions that take some text and turn smart quotes into plain ASCII quotes, dashes and minuses into ASCII hyphens, etc., or just detect them and produce useful objects and/or text. And it’s a runnable module that can either lint or fix source code. Then instead of telling people who get this SyntaxError “Use a proper editor, and all the code you wrote so far has to be rewritten or fixed manually, and that’ll show you”, we can tell them “Use a proper editor in the future, but meanwhile you can fix your existing script with `python -m defancier -f script.py`“. And a simple IDE or editor mode that doesn’t want to come up with something better could run defancier on SyntaxError or on open or whenever and show the output in a nice way and offer a single-click fix. There’s nothing in the stdlib quite like this, but textwrap, tabnanny, 2to3, etc. are vaguely similar precedents. And it seems like the kind of thing that will evolve on about the right scale for the stdlib—new problems to add to the list come up about once a decade, not every few months or anything. The place I’d _really_ like this is Pythonista, which does an admirable job fighting iOS text input for me, but it’s not so helpful for fixing up pasted code. (And needless to say, I can’t just get a better editor/IDE; it’s by far the best option for the platform.) (By the way, the reason I used -f rather than —fix is that I can’t figure out how to get the iPhone Mail.app to not replace double hyphens with an em-dash, or even how to fix it when it does. All of the other fancifier stuff can be worked around pretty easily, but apparently not that one…)
On Sun, May 10, 2020 at 1:17 PM Andrew Barnert via Python-ideas < python-ideas@python.org> wrote:
Totally OT -- but just the other day, I was using a Google Sheets, and it kept converting "4, 5, 6" or "4-5-6" into a date. I could NOT figure out how to turn it off -- infuriating! Back OT: The fact that there are many ways that our text may get mangled in other systems does not mean Python should tolerate ambiguity. Having a "tabnanny-like" function / module in the stdlib would be nice, though I'd think a stand alone module in PyPi would be almost as good, and a good way to see if it gains traction. BTW -- there are a whole lot of Syntax Errors that a semi smart algorithm could provide meaningful suggestions about about. I'm pretty sure that's come up before on this list, but maybe "helpful" mode you could run Python in that would do that for all Syntax errors that it could. We could even have a way for folks to extend it with additional checks. Kind of like how git makes suggestions if you type something almost like a command. -CHB -- Christopher Barker, PhD Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
I wonder if The Fuck could be customize to handle these improved error messages envisioned: https://github.com/nvbn/thefuck It's a lovely tool. I don't mind the minor profanity, but when I teach I add an alias of 'fix' for students to see instead. On Sun, May 10, 2020 at 5:34 PM Christopher Barker <pythonchb@gmail.com> wrote:
-- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
On May 10, 2020, at 14:33, Christopher Barker <pythonchb@gmail.com> wrote:
Having a "tabnanny-like" function / module in the stdlib would be nice, though I'd think a stand alone module in PyPi would be almost as good, and a good way to see if it gains traction.
Good point. Plus, it might well turn out that, say, the right thing for most Windows users and the right thing for most iOS Pythonista users is sufficiently different that two separate defancier packages are better than a one-size-fits-all could be, which we’d find out a lot more easily if people go out and use it in the field than if we try to design it here.
BTW -- there are a whole lot of Syntax Errors that a semi smart algorithm could provide meaningful suggestions about about. I'm pretty sure that's come up before on this list, but maybe "helpful" mode you could run Python in that would do that for all Syntax errors that it could. We could even have a way for folks to extend it with additional checks.
This already exists on PyPI. Actually, there are a few different ones. One of them (I think friendly-tracebacks?) is very detailed. One of the authors sometimes posts about it here, when we’re talking about how some exception should be improved, with an example showing that they’ve already thought of it and done something better than is being proposed in the list.:) That one may already be a category killer. I looked over some of the others and the only thing that jumped out at me was that one of them (better-errors?) integrates really nicely into iPython and Jupyter (using iPython’s syntax coloring settings, making more use of line-drawing and box characters, etc.) But that doesn’t mean the category killer should be in the stdlib; I suspect they’re still improving it at a much faster pace than the stdlib could handle. But maybe the docs should link to it. The only problem is that the obvious places (like Interface Options section in the Usage docs) are things almost nobody reads…
On Sun, May 10, 2020 at 7:34 PM Andrew Barnert via Python-ideas < python-ideas@python.org> wrote:
Yes, please do contribute to support more cases (see below). :-)
Somebody called me?
Well, that's kind of you to say. I definitely had not thought of that one. Barebone ssue filed: https://github.com/aroberge/friendly-traceback/issues/45 ; I (or anyone else) will need to add more details. I really need to find the time ro resume work on friendly-traceback.... I do need to find a way to have friendly-traceback available as a plugin for VS Code, PyCharm, SublimeText and perhaps Jupyter notebooks. It can already work with Mu and Thonny. ( Due to the way Idle runs code and deals with exceptions, it is impossible to add it as a simple plugin to Idle, most unfortunately.) For anyone interested, even if you do not want to add support for other cases, feel free to file issues and suggest additions to friendly-traceback. André Roberge
On Sun, May 10, 2020 at 01:17:17PM -0700, Andrew Barnert via Python-ideas wrote:
I don't know anything about Mail.app, but in LibreOffice you can Ctrl-Z to underdo autocorrect without undoing the characters you typed. In my experience, autocorrect often is activated when you type a space or newline, and only looks back a single word at a time. So with a bit of extra work, you might be able to avoid triggering the autocorrect on the hyphens. Perhaps something like this? type: space hyphen space hyphen space f i x space backspace to delete the spaces forward arrow past the "fix" before typing another space I have found that variations of this seems to work with autocorrect on some systems. (Or just wait until you're back on a computer with a less annoying mail client before replying :-) -- Steven
On Sun, May 10, 2020 at 9:05 PM Steven D'Aprano <steve@pearwood.info> wrote:
I don't know anything about Mail.app, but in LibreOffice you can Ctrl-Z to underdo autocorrect without undoing the characters you typed.
I don't use iPhone, but I'm pretty sure it doesn't have a Ctrl-Z key on it :-) -- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
Andrew, I already have a module that I include in a couple of widely used utilities at work that I called cmd_line_fixup (but I think that I like defancier better) it is used on the command line options prior to processing to fix several of these issues. This was written in response to the frequency of me getting emails saying "how do I get the utility to do X?" to which I would dash off a quick reply and get back "that doesn't work" - the users of these utilities include developers (who use other languages) and electrical test technicians and many of them are based in other countries where English is not their native tongue so explaining "You need to type what I sent you rather than paste it" was challenging. Potentially such a module could be smarter than my current one in that I currently just use a series of replaces to swap out everything but potentially user code could be using these characters legitimately inside of strings or comments e.g. the copywrite symbol. Steve Barnes -----Original Message----- From: Andrew Barnert <abarnert@yahoo.com> Sent: 10 May 2020 21:17 To: Steve Barnes <GadgetSteve@live.co.uk> Cc: python-ideas@python.org Subject: Re: [Python-ideas] Improve handling of Unicode quotes and hyphens On May 10, 2020, at 00:11, Steve Barnes <GadgetSteve@live.co.uk> wrote:
What can be done?
I think there’s another option (in addition to improving SyntaxError, not instead of it): Add a defancier module to the stdlib. It has functions that take some text and turn smart quotes into plain ASCII quotes, dashes and minuses into ASCII hyphens, etc., or just detect them and produce useful objects and/or text. And it’s a runnable module that can either lint or fix source code. Then instead of telling people who get this SyntaxError “Use a proper editor, and all the code you wrote so far has to be rewritten or fixed manually, and that’ll show you”, we can tell them “Use a proper editor in the future, but meanwhile you can fix your existing script with `python -m defancier -f script.py`“. And a simple IDE or editor mode that doesn’t want to come up with something better could run defancier on SyntaxError or on open or whenever and show the output in a nice way and offer a single-click fix. There’s nothing in the stdlib quite like this, but textwrap, tabnanny, 2to3, etc. are vaguely similar precedents. And it seems like the kind of thing that will evolve on about the right scale for the stdlib—new problems to add to the list come up about once a decade, not every few months or anything. The place I’d _really_ like this is Pythonista, which does an admirable job fighting iOS text input for me, but it’s not so helpful for fixing up pasted code. (And needless to say, I can’t just get a better editor/IDE; it’s by far the best option for the platform.) (By the way, the reason I used -f rather than —fix is that I can’t figure out how to get the iPhone Mail.app to not replace double hyphens with an em-dash, or even how to fix it when it does. All of the other fancifier stuff can be worked around pretty easily, but apparently not that one…)
By the way, did anyone else notice the irony that's Steve's examples of invalid code is actually perfectly valid? Copying and pasting into the interpreter shows that they are valid strings. On Sun, May 10, 2020 at 07:09:15AM +0000, Steve Barnes wrote:
When I first read this, I thought it was because the display font used by mail client doesn't distinguish the fancy Unicode quote marks from the ASCII quotes. But it does: Double: " vs “ ” Single: ' vs ‘ ’ (Obviously you can't see the glyphs as they are displayed in my editor, but trust me, they are visually distinct :-) But testing in the interpreter proves that they are regular ASCII quotes, not just look-alikes. So I thought that Steve made the opposite mistake, accidentally using regular ASCII quotes when he intended to use Unicode quotes. But it turns out that Steve's mail client sends emails with a HTML part and a plain text part, and the plain text part substitutes the ASCII quotes for smart quotes. Very clever! My mail client prefers the plain text part when it is available, which is usually exactly what I would want. But in this case, it confused me for a bit. -- Steven
So I thought that Steve made the opposite mistake, accidentally using regular ASCII quotes when he intended to use Unicode quotes. But it turns out that Steve's mail client sends emails with a HTML part and a plain text part, and the plain text part substitutes the ASCII quotes for smart quotes. Very clever! My mail client prefers the plain text part when it is available, which is usually exactly what I would want. But in this case, it confused me for a bit. -- Steven [Steve Barnes] So we currently have a situation where not only does whether code works or not depends on who typed it, in what environment, with what settings but also on the same factors for who received it - so I could use Outlook or Word to send a code fragment to 100 people and 5 say that is great it works and the other 95 end up thinking that there is something wrong with their installation. Personally I don't think this fits in with the pythonic way of thinking! Steve
On Mon, May 11, 2020 at 2:29 PM Steve Barnes <GadgetSteve@live.co.uk> wrote:
I agree, it doesn't. So the solution is: Don't send code via something that mangles it. It might discard your indentation, mutate your quotes, convert it to HTML and then insert newlines when it converts back to text at the other end, or helpfully translate all the language keywords into French (okay, I haven't seen THAT happen, but I've seen all the others). Code is text but it is not English text, and anything that tries to parse it as English will be just as wrong as something that tries to parse it as Fortran. If you can't stop your tool from misparsing your code, get a better tool. It's not like they're expensive or hard to obtain. ChrisA
On Mon, May 11, 2020 at 04:28:38AM +0000, Steve Barnes wrote:
You say "currently", but that has always been the case, and the further back you go, the worse it was.
While the actual problem is that you are sending code via a non-WYSIWYG medium that may modify what you type. If you want to send code via email, the most reliable method is to attach it as a .py file.
Personally I don't think this fits in with the pythonic way of thinking!
The Zen says differently: "Errors should never pass silently." It's not Python's responsibility to make up for lossy transmission methods such as mail servers which strip the high bit off every octet, or faulty hardware that randomly corrupts one byte in a thousand. And nor is it the interpreter's responsibility to guess what the user intended to type, or *should have* intended to type, in the face of editors which substitute characters. -- Steven
-----Original Message----- From: Steven D'Aprano <steve@pearwood.info> Sent: 11 May 2020 06:02 To: python-ideas@python.org Subject: [Python-ideas] Re: Improve handling of Unicode quotes and hyphens On Mon, May 11, 2020 at 04:28:38AM +0000, Steve Barnes wrote:
You say "currently", but that has always been the case, and the further back you go, the worse it was. [Steve Barnes] True - apart from the older email clients being less "helpful".
While the actual problem is that you are sending code via a non-WYSIWYG medium that may modify what you type. If you want to send code via email, the most reliable method is to attach it as a .py file. [Steve Barnes] My employer mandates the communication method(s) (as do many others). They also block unsafe "attachments" such as .py & .bat files (even when zipped). In any case I am often trying to tell the end user how to invoke existing code that they already have from the command line, (especially when they have stored files in folders with spaces, ampersands, hyphens, etc., in the path).
Personally I don't think this fits in with the pythonic way of thinking!
The Zen says differently: "Errors should never pass silently." It's not Python's responsibility to make up for lossy transmission methods such as mail servers which strip the high bit off every octet, or faulty hardware that randomly corrupts one byte in a thousand. And nor is it the interpreter's responsibility to guess what the user intended to type, or *should have* intended to type, in the face of editors which substitute characters. [Steve Barnes] What I would prefer is an error message that actually tells the end user which specific character(s) they have got wrong rather than something is wrong after all "Explicit is better than implicit" would suggest that "illegal character x (Unicode u)" would be more pythonic than the current error message. -- Steven _______________________________________________ Python-ideas mailing list -- python-ideas@python.org To unsubscribe send an email to python-ideas-leave@python.org https://mail.python.org/mailman3/lists/python-ideas.python.org/ Message archived at https://mail.python.org/archives/list/python-ideas@python.org/message/3AO3MP... Code of Conduct: http://python.org/psf/codeofconduct/
A third-party module on PyPI for "fix-the-horrible-things-Outlook-does" could be useful. There is no way the standard library can or should keep up with the newest mangling techniques mail handlers employ in this week's version. I don't understand what you mean by the current interpreter not telling you which character is bad. It puts a pointer right under the problem character in the error message. Nothing is being hidden, even if the code-manglers can do pretty insidious things... different in every version, for every sender, and for every recipient. On Mon, May 11, 2020 at 3:24 AM Steve Barnes <GadgetSteve@live.co.uk> wrote:
-- The dead increasingly dominate and strangle both the living and the not-yet born. Vampiric capital and undead corporate persons abuse the lives and control the thoughts of homo faber. Ideas, once born, become abortifacients against new conceptions.
From: David Mertz <mertz@gnosis.cx> Sent: 11 May 2020 08:34 To: Steve Barnes <GadgetSteve@live.co.uk> Cc: python-ideas@python.org Subject: Re: [Python-ideas] Re: Improve handling of Unicode quotes and hyphens A third-party module on PyPI for "fix-the-horrible-things-Outlook-does" could be useful. There is no way the standard library can or should keep up with the newest mangling techniques mail handlers employ in this week's version. I don't understand what you mean by the current interpreter not telling you which character is bad. It puts a pointer right under the problem character in the error message. Nothing is being hidden, even if the code-manglers can do pretty insidious things... different in every version, for every sender, and for every recipient. [Steve Barnes] Actually, in the case of the “wrong quotes” it puts the pointer under the character before the space character or at the end of the line (if you have a fixed spacing font – worse if you don’t) – it still doesn’t tell you which character is invalid. [cid:image001.png@01D62773.50D55990][cid:image002.png@01D62773.73A95D90]
On Mon, May 11, 2020 at 6:09 PM Steve Barnes <GadgetSteve@live.co.uk> wrote:
Actually, in the case of the “wrong quotes” it puts the pointer under the character before the space character or at the end of the line (if you have a fixed spacing font – worse if you don’t) – it still doesn’t tell you which character is invalid.
This is actually a good point. Having an invalid character in an identifier shows the caret at the end of the identifier, regardless of where in the identifier the error is. That's something that could be improved on, regardless of the quote issue. There's a new parser on its way (PEP 617), so it'd be something to consider on that basis. ChrisA
MRAB writes:
On 2020-05-11 09:21, Chris Angelico wrote:
On Mon, May 11, 2020 at 6:09 PM Steve Barnes <GadgetSteve@live.co.uk> wrote:
This is actually a good point.
But it's a different point:
This isn't a parsing problem as such. I am not an expert on the parser, but what's going is something like this: the parser (tokenizer) sees the character "=" and expects an operator. Next, it sees something that is not "=" and not whitespace, so it expects a literal or an identifier. " “" is not parsable as the start of a literal, so the parser consumes up to the next boundary character (whitespace or operator). Now it checks for the different types of barewords: keywords and identifiers, and neither one works. Here's the critical point: identifier fails because the tokenizer tries to match a sequence of Unicode word constitituents, and " “" isn't one. So it fails the sequence of non-whitespace characters, and points to the end of the last thing it saw. So I see no reason why we need to transition to the new parser to fix this. (And the new parser (as of the last comment I saw from Guido) probably doesn't help: he kept the tokenizer.) We just need to make a second pass over the invalid identifier and identify the invalid characters it contains and their positions.
As a permanent resident of Japan, I DEMAND that YOU PERSONALLY implement the SAME TEST for all the Japanese "full-width" operator characters. :-) (This is actually a very common user error, and it's very hard to tell the difference by sight in many fonts, same as directed quotes vs. ASCII quotes in English, but for the whole ASCII repertoire.) This could get really ridiculous. I think the suggestion that whatever test it is that identified the "invalid character in identifier" defect be fixed to report both the position of the first such character and the list of all such characters is appropriate. The "wrong kind of quote" stuff belongs elsewhere, and in particular in a linter. Here's an quasi-algorithmic suggestion for that: use the Unicode confusables list (and I think there are many properties such as "related" and "paired" characters that can be indicative). Haven't looked at it in a while; it may not catch all the issues here. But it would be a good start, and quite comprehensive. It might suggest other things linters could be doing, too. Steve
Wow - a lot going on this thread - despite what to do seemingly really obvious: of course showing which character triggered the error along with a proper plain English phrase is enough. The Fortran anecdote in the beginning of the thread is a false analogy, since the program _will_ _not_ run with unexpected results in Python, and, being in a PC or submitting code in a testing pipeline it takes seconds to retry. Fixing spurious characters back to their ASCII could be placed in a popular code-formatting tool like Black. js -><- On Wed, 13 May 2020 at 09:31, Richard Damon <Richard@damon-family.org> wrote:
On May 13, 2020, at 05:31, Richard Damon <Richard@damon-family.org> wrote:
Isn’t this what already happens? >>> import tokenize, io >>> def tok(s): return list(tokenize.tokenize(io.BytesIO(x.encode()).readline)) >>> tok('spam(“Abc”)') When I run this in 3.7, the fourth token is an ERRORTOKEN with string ”, then there’s a NAME with Abc, then another ERRORTOKEN with “. And reading the Lexical Analysis chapter of the docs, this seems correct. The smart quote is not a possible xid_start, or any other start of any token terminal, so it should immediately fail as an error.(The fact that the tokenizer eats it, generates an ERRORTOKEN, and then lexes the Abc as a NAME, rather than throwing an exception or otherwise punting, is a pretty nice error-recovery attempt, and seems perfectly reasonable.) Is that not true for the internal C tokenizer? Or is it true, but the parser or the error generating code isn’t taking advantage of it? (By the way. I’m pretty sure this behavior isn’t specific to 3.7, but has been that way back into the mists of whenever you could first write old-style import hooks, even up to the way error recovery works. I’ve taken advantage of this behavior in experimenting with new syntax. If your new syntax is not just unambiguous at the parser level, but even at the lexical level, you can just scan the token stream for your matching ERRORTOKEN.)
Executive summary: AFAICT, my guess at what's going on in the C tokenizer was exactly right. It greedily consumes as many non-operator, non-whitespace characters as possible, then validates. It does this because it is tokenizing a stream of bytes encoding characters as UTF-8. Andrew Barnert via Python-ideas writes:
It would be bizarre if true. Why would the error reporting randomly take an invalid character and glom it on to the following characters to create an invalid identifier, then report that? I suspect that the Python version is a tiny bit smarter than the C version because it naturally processes (Unicode) characters while the C code processes (UTF-8) bytes by design (from the now-ancient PEP 263), but the Python code is left as an exercise for the interested reader. ;-) Here's the relevant part of tokenizer.c:tok_get from Python 3.8 (all comments are mine, except for part of the comment about processing bfru strings): /* Note note note: "character" seems to mean C char, ie, byte! This is just from the declaration in struct tok_state, I haven't carefully confirmed that the program text being tokenized is UTF-8 bytes but that's what PEP 263 says to do, and it looks like that's what the I/O code is doing. Which is true doesn't matter to my analysis because a UTF-8 byte c is part of a non-ASCII character if and only if c >= 128, while a Unicode character c is non-ASCII if and only if c >= 128. Identifier consumption stops only when c is ASCII, or EOF; it can only stop on a UTF-8 character boundary. So this algorithm works exactly the same whether you use UTF-8-encoded bytes or Unicode characters. is_potential_identifier_start includes letters, underscore, and ALL non-ASCII. is_potential_identifier_char includes all of those, plus digits. */ /* I suspect the Python code uses an accurate test here, rather than these accurate-for-ASCII-not-so-for-non-ASCII tests. */ /* l. 24 */ #define is_potential_identifier_start(c) (\ (c >= 'a' && c <= 'z')\ || (c >= 'A' && c <= 'Z')\ || c == '_'\ || (c >= 128)) #define is_potential_identifier_char(c) (\ (c >= 'a' && c <= 'z')\ || (c >= 'A' && c <= 'Z')\ || (c >= '0' && c <= '9')\ || c == '_'\ || (c >= 128)) /* Skip 1000+ lines of I/O code. */ /* l. 1368 */ static int tok_get(struct tok_state *tok, char **p_start, char **p_end) { /* Skip initialization and handling of indentation, whitespace, and comments. */ /* We attempt to parse an identifier as the first guess. We start with code that handles string prefixes "bfru". Otherwise we just consume potential identifier characters until we run into a character (byte) that is not a potential identifier character. If any character is not ASCII, set nonascii flag. */ /* l. 1492 */ nonascii = 0; if (is_potential_identifier_start(c)) { while (1) { /* Process the various legal combinations of b"", r"", u"", and f"". Complicated multibranch if-else-if ... statement omitted. If none, break out of while before getting next c. */ c = tok_nextc(tok); if (c == '"' || c == '\'') { goto letter_quote; } } /* If we get here, we may have seen some of bfru, but it's not legal string syntax, so continue trying to extract an identifier. In particular, if the first character c was non-ASCII, we broke out of the while loop doing nothing, so c is still that non-ASCII character. */ while (is_potential_identifier_char(c)) { if (c >= 128) { nonascii = 1; } c = tok_nextc(tok); } /* Last thing we saw was not part of the potential identifier. Unget it. */ tok_backup(tok, c); /* If this is a PGEN build, verify_identifier always returns true, because PGEN doesn't have access to Python's Unicode routines. That would necessarily have to check valid identifier after returning the token stream. Otherwise verify_identifier validates the string using PyUnicode_IsIdentifier. */ if (nonascii && !verify_identifier(tok)) { return ERRORTOKEN; } So there you are.
(By the way. I’m pretty sure this behavior isn’t specific to 3.7,
As mentioned above, this code is from 3.8, and the algorithm (transcode program text to UTF-8 and process bytewise, using the fact that all characters Python has special knowledge of are ASCII) is specified in PEP 263. Steve
On May 14, 2020, at 20:01, Stephen J. Turnbull <turnbull.stephen.fw@u.tsukuba.ac.jp> wrote:
Well, it like like it’s not quite “non-operator, non-whitespace characters”, but rather “ASCII identifier or non-ASCII characters”:
(That’s the initial char rule; the continuing char rule is similar but of course allows digits.) So it won’t treat a $ or a ^G as potentially part of an identifier, so the caret will show up in the right place for one of those, but it will treat an emoji as potentially part of an identifier, so (if that emoji is immediately followed by legal identifier characters, ASCII or otherwise) the caret will show up too far to the right. I’m still glad the Python tokenizer doesn’t do this (because, as I said, I’ve relied on the documented behavior in import hooks for playing around with Python, and they use the Python tokenizer), but that doesn’t matter for the C tokenizer, because its output is not public, it’s only seen by the parser. And I think you can prove that the error caret placement is the only thing that could be affected by this shortcut.[1] And if it makes the tokenizer faster, or just simpler to maintain, that could easily be worth it. (At least until one of those periodic “Python should add this Unicode operator” proposals actually gets some traction, but I don’t see that as likely any time soon.) —- [1] Python only allows non-ASCII characters in identifiers, strings, and comments. Therefore, any string of characters that should be tokenized as a sequence of 1 ERRORTOKEN followed by 0 or more NAME and ERRORTOKEN tokens by the documented rule (and the Python code) will still give you a sequence of 1 ERRORTOKEN followed by 0 or more NAME and ERRORTOKEN tokens by the C code, just not necessarily the same such sequence. And any such sequence will be parsed as a SyntaxError pointing at the end of the initial ERRORTOKEN. So, the caret might be somewhere else within that block of identifier and non-ASCII characters, but it will be somewhere within that block.
10.05.20 10:09, Steve Barnes пише:
Two consequent hyphens can look as a dash, and can be replaced with a dash by "typographer", but they have different meaning that a single minus.
It is ambiguous. For example, in Ukraine we use pairs of quotation marks « and » or „ and “. But “ is used as an opening quotation mark in English, and » and « are used with opposite meaning in Swedish. Single low-9 quotation mark ‚ can be confused with a comma, single angle quotation marks ‹ and ❮ can be confused with <.
https://bugs.python.org/issue40593 Also, "in identifier" is incorrect in most cases, because the invalid character does not look like a part of identifier in most cases.
participants (16)
-
 Andrew Barnert
Andrew Barnert -
 André Roberge
André Roberge -
 Chris Angelico
Chris Angelico -
 Christopher Barker
Christopher Barker -
 Dan Sommers
Dan Sommers -
 David Mertz
David Mertz -
 Joao S. O. Bueno
Joao S. O. Bueno -
 Jonathan Goble
Jonathan Goble -
 MRAB
MRAB -
 Ned Batchelder
Ned Batchelder -
 Richard Damon
Richard Damon -
 Serhiy Storchaka
Serhiy Storchaka -
 Stephen J. Turnbull
Stephen J. Turnbull -
 Steve Barnes
Steve Barnes -
Steve Barnes
-
 Steven D'Aprano
Steven D'Aprano