
Dear All, I am trying to make pairs of images from the following set of images (chromosomes sorted by size after rotation). The idea is to make a feature vector for unsupervised classification (kmeans with 19 clusters)
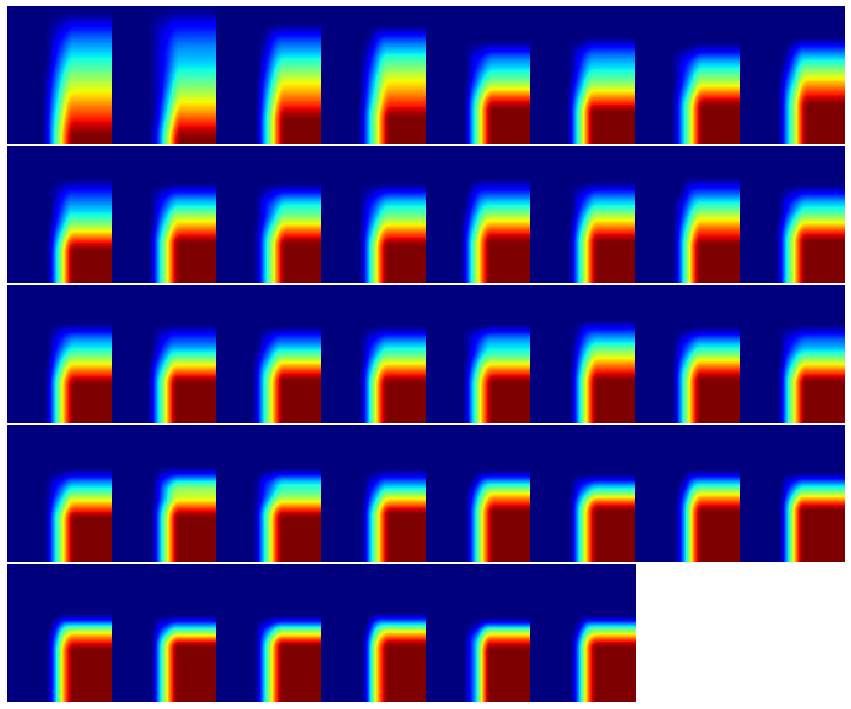
From each chromosome an integral image was calculated:
plt.figure(figsize = (15,15)) gs1 = gridspec.GridSpec(6,8) gs1.update(wspace=0.0, hspace=0.0) # set the spacing between axes. for i in range(38): # i = i + 1 # grid spec indexes from 0 ax1 = plt.subplot(gs1[i]) plt.axis('off') ax1.set_xticklabels([]) ax1.set_yticklabels([]) ax1.set_aspect('equal') image = sk.transform.integral_image(reallysorted[i][:,:,2]) imshow(image , interpolation='nearest') Then each integral image was flatten and combined with the others: Features =[] for i in range(38): Feat = np.ndarray.flatten(sk.transform.integral_image(reallysorted[i][:,:,2])) Features.append(Feat) X = np.asarray(Features) print X.shape The X array contains *38* lines and 9718 features, which is not good. However, I trried to submit these raw features to kmeans classification with sklearn using a direct example http://scikit-learn.org/stable/modules/neighbors.html : from sklearn.neighbors import NearestNeighbors nbrs = NearestNeighbors(n_neighbors=*19*, algorithm='ball_tree').fit(X) distances, indices = nbrs.kneighbors(X) connection = nbrs.kneighbors_graph(X).toarray() Ploting the connection graph shows that a chromosomes is similar to more than one ... - Do you think that integral images can be used to discriminate the chromosomes pairs? - If so, how to reduce the number of features to 10~20? (to get a better discrimination) Thanks for your advices. Jean-Patrick
{kind=link}
{kind=link}
{kind=link}