Finding pairs of images (homologous chromosomes)

Dear All, I am trying to make pairs of images from the following set of images (chromosomes sorted by size after rotation). The idea is to make a feature vector for unsupervised classification (kmeans with 19 clusters)
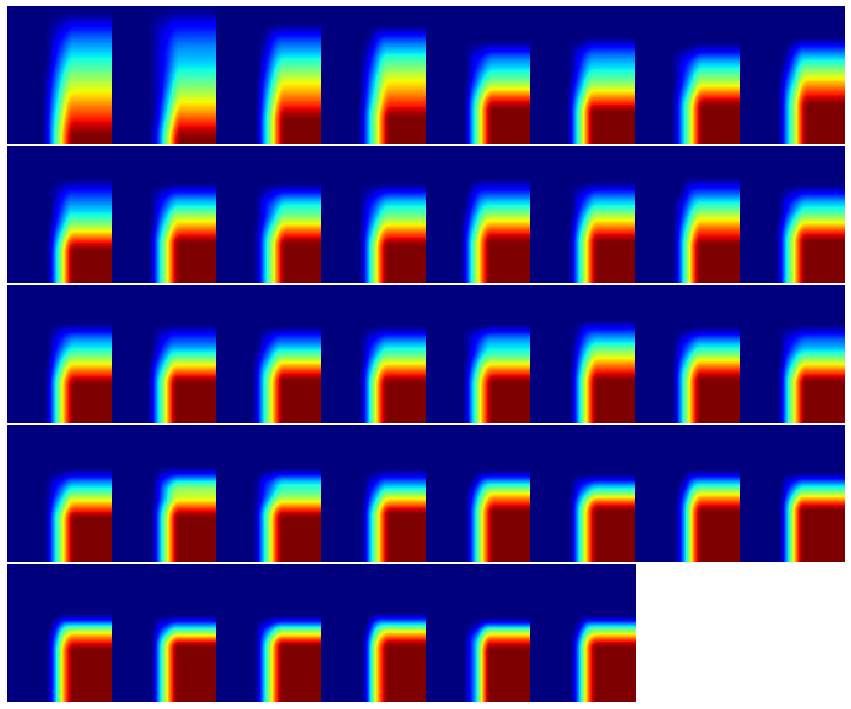
From each chromosome an integral image was calculated:
plt.figure(figsize = (15,15)) gs1 = gridspec.GridSpec(6,8) gs1.update(wspace=0.0, hspace=0.0) # set the spacing between axes. for i in range(38): # i = i + 1 # grid spec indexes from 0 ax1 = plt.subplot(gs1[i]) plt.axis('off') ax1.set_xticklabels([]) ax1.set_yticklabels([]) ax1.set_aspect('equal') image = sk.transform.integral_image(reallysorted[i][:,:,2]) imshow(image , interpolation='nearest') Then each integral image was flatten and combined with the others: Features =[] for i in range(38): Feat = np.ndarray.flatten(sk.transform.integral_image(reallysorted[i][:,:,2])) Features.append(Feat) X = np.asarray(Features) print X.shape The X array contains *38* lines and 9718 features, which is not good. However, I trried to submit these raw features to kmeans classification with sklearn using a direct example <http://scikit-learn.org/stable/modules/neighbors.html> : from sklearn.neighbors import NearestNeighbors nbrs = NearestNeighbors(n_neighbors=*19*, algorithm='ball_tree').fit(X) distances, indices = nbrs.kneighbors(X) connection = nbrs.kneighbors_graph(X).toarray() Ploting the connection graph shows that a chromosomes is similar to more than one ... - Do you think that integral images can be used to discriminate the chromosomes pairs? - If so, how to reduce the number of features to 10~20? (to get a better discrimination) Thanks for your advices. Jean-Patrick
{kind=link}
{kind=link}
{kind=link}

Neat problem! For feature extraction, `skimage.feature` is probably your friend. Nothing against integral images, but I'm not sure they are going to give you an ideal feature set for discrimination (you can see that visually). Also, attempting to normalize your input data might be worth looking into at some point as it appears exposure is not uniform. As a first pass, you could feed raw grayscale values straight into e.g. a Bernoulli Restricted Boltzmann machine <http://scikit-learn.org/stable/modules/neural_networks.html#bernoulli-restri...>, or check out scikit-learn's excellent tutorial on digit recognition <http://scikit-learn.org/stable/auto_examples/plot_digits_classification.html...>. Though for both of those options, the performance is going to be strongly dependent on the quality and - especially - quantity of the training set. Beyond that, thresholding and a skeletonization with `skimage.morphology.skeletonize` might give you informative morphology data to feed in to a classifier. Best of luck, Josh On Tuesday, February 24, 2015 at 10:21:10 AM UTC-6, Jean-Patrick Pommier wrote:
Dear All,
I am trying to make pairs of images from the following set of images (chromosomes sorted by size after rotation). The idea is to make a feature vector for unsupervised classification (kmeans with 19 clusters)
From each chromosome an integral image was calculated:
plt.figure(figsize = (15,15)) gs1 = gridspec.GridSpec(6,8) gs1.update(wspace=0.0, hspace=0.0) # set the spacing between axes. for i in range(38): # i = i + 1 # grid spec indexes from 0 ax1 = plt.subplot(gs1[i]) plt.axis('off') ax1.set_xticklabels([]) ax1.set_yticklabels([]) ax1.set_aspect('equal') image = sk.transform.integral_image(reallysorted[i][:,:,2]) imshow(image , interpolation='nearest')
Then each integral image was flatten and combined with the others:
Features =[]
for i in range(38): Feat = np.ndarray.flatten(sk.transform.integral_image(reallysorted[i][:,:,2])) Features.append(Feat) X = np.asarray(Features) print X.shape
The X array contains *38* lines and 9718 features, which is not good. However, I trried to submit these raw features to kmeans classification with sklearn using a direct example <http://scikit-learn.org/stable/modules/neighbors.html> :
from sklearn.neighbors import NearestNeighbors nbrs = NearestNeighbors(n_neighbors=*19*, algorithm='ball_tree').fit(X) distances, indices = nbrs.kneighbors(X) connection = nbrs.kneighbors_graph(X).toarray() Ploting the connection graph shows that a chromosomes is similar to more than one ...
- Do you think that integral images can be used to discriminate the chromosomes pairs? - If so, how to reduce the number of features to 10~20? (to get a better discrimination)
Thanks for your advices.
Jean-Patrick
Thanks you for the links. Regarding the rbm classifier in the following example <http://scikit-learn.org/stable/auto_examples/plot_rbm_logistic_classificatio...>. At first sight I don't understand what is Y array (X array seems to be the set of images). Jean-Patrick Le mardi 24 février 2015 17:21:10 UTC+1, Jean-Patrick Pommier a écrit :
Dear All,
I am trying to make pairs of images from the following set of images (chromosomes sorted by size after rotation). The idea is to make a feature vector for unsupervised classification (kmeans with 19 clusters)
From each chromosome an integral image was calculated:
plt.figure(figsize = (15,15)) gs1 = gridspec.GridSpec(6,8) gs1.update(wspace=0.0, hspace=0.0) # set the spacing between axes. for i in range(38): # i = i + 1 # grid spec indexes from 0 ax1 = plt.subplot(gs1[i]) plt.axis('off') ax1.set_xticklabels([]) ax1.set_yticklabels([]) ax1.set_aspect('equal') image = sk.transform.integral_image(reallysorted[i][:,:,2]) imshow(image , interpolation='nearest')
Then each integral image was flatten and combined with the others:
Features =[]
for i in range(38): Feat = np.ndarray.flatten(sk.transform.integral_image(reallysorted[i][:,:,2])) Features.append(Feat) X = np.asarray(Features) print X.shape
The X array contains *38* lines and 9718 features, which is not good. However, I trried to submit these raw features to kmeans classification with sklearn using a direct example <http://scikit-learn.org/stable/modules/neighbors.html> :
from sklearn.neighbors import NearestNeighbors nbrs = NearestNeighbors(n_neighbors=*19*, algorithm='ball_tree').fit(X) distances, indices = nbrs.kneighbors(X) connection = nbrs.kneighbors_graph(X).toarray() Ploting the connection graph shows that a chromosomes is similar to more than one ...
- Do you think that integral images can be used to discriminate the chromosomes pairs? - If so, how to reduce the number of features to 10~20? (to get a better discrimination)
Thanks for your advices.
Jean-Patrick
Hi Jean-Patrick, Y is the known corresponding digit identity. The function to "jitter" the digit images around a bit just takes digits.target as Y and concatenates it with itself five times, so the expanded dataset has known identities to compare against. Regards, Josh On Wednesday, February 25, 2015 at 7:09:39 AM UTC-6, Jean-Patrick Pommier wrote:
Thanks you for the links.
Regarding the rbm classifier in the following example <http://scikit-learn.org/stable/auto_examples/plot_rbm_logistic_classificatio...>. At first sight I don't understand what is Y array (X array seems to be the set of images).
Jean-Patrick
Le mardi 24 février 2015 17:21:10 UTC+1, Jean-Patrick Pommier a écrit :
Dear All,
I am trying to make pairs of images from the following set of images (chromosomes sorted by size after rotation). The idea is to make a feature vector for unsupervised classification (kmeans with 19 clusters)
From each chromosome an integral image was calculated:
plt.figure(figsize = (15,15)) gs1 = gridspec.GridSpec(6,8) gs1.update(wspace=0.0, hspace=0.0) # set the spacing between axes. for i in range(38): # i = i + 1 # grid spec indexes from 0 ax1 = plt.subplot(gs1[i]) plt.axis('off') ax1.set_xticklabels([]) ax1.set_yticklabels([]) ax1.set_aspect('equal') image = sk.transform.integral_image(reallysorted[i][:,:,2]) imshow(image , interpolation='nearest')
Then each integral image was flatten and combined with the others:
Features =[]
for i in range(38): Feat = np.ndarray.flatten(sk.transform.integral_image(reallysorted[i][:,:,2])) Features.append(Feat) X = np.asarray(Features) print X.shape
The X array contains *38* lines and 9718 features, which is not good. However, I trried to submit these raw features to kmeans classification with sklearn using a direct example <http://scikit-learn.org/stable/modules/neighbors.html> :
from sklearn.neighbors import NearestNeighbors nbrs = NearestNeighbors(n_neighbors=*19*, algorithm='ball_tree').fit(X) distances, indices = nbrs.kneighbors(X) connection = nbrs.kneighbors_graph(X).toarray() Ploting the connection graph shows that a chromosomes is similar to more than one ...
- Do you think that integral images can be used to discriminate the chromosomes pairs? - If so, how to reduce the number of features to 10~20? (to get a better discrimination)
Thanks for your advices.
Jean-Patrick

Hi Jean-Patrick On 2015-02-24 08:21:10, Jean-Patrick Pommier <jeanpatrick.pommier@gmail.com> wrote:
I am trying to make pairs of images from the following set of images (chromosomes sorted by size after rotation). The idea is to make a feature vector for unsupervised classification (kmeans with 19 clusters)
This is a *very* late reply, but I thought I'd mention that François Boulogne & Gaël Varoquaux has included a digit classifier in the skimage-demos repository, which may be helpful. Best regards Stéfan
Thank you anyway, Jean-pat 2015-11-14 23:35 GMT+01:00 Stefan van der Walt <stefanv@berkeley.edu>:
Hi Jean-Patrick
On 2015-02-24 08:21:10, Jean-Patrick Pommier < jeanpatrick.pommier@gmail.com> wrote:
I am trying to make pairs of images from the following set of images (chromosomes sorted by size after rotation). The idea is to make a feature vector for unsupervised classification (kmeans with 19 clusters)
This is a *very* late reply, but I thought I'd mention that François Boulogne & Gaël Varoquaux has included a digit classifier in the skimage-demos repository, which may be helpful.
Best regards Stéfan
-- You received this message because you are subscribed to a topic in the Google Groups "scikit-image" group. To unsubscribe from this topic, visit https://groups.google.com/d/topic/scikit-image/vYft2c3uFlk/unsubscribe. To unsubscribe from this group and all its topics, send an email to scikit-image+unsubscribe@googlegroups.com. For more options, visit https://groups.google.com/d/optout.
-- http://dip4fish.blogspot.fr/ Dedicated to Digital Image Processing for FISH, QFISH and other things about the telomeres.
participants (3)
-
 Jean-Patrick Pommier
Jean-Patrick Pommier -
 Josh Warner
Josh Warner -
 Stefan van der Walt
Stefan van der Walt