
________________________________ From: Patel, Pragneshkumar B Sent: Thursday, November 17, 2011 12:18 PM To: Britton Smith Cc: Geoffrey So; s@skory.us Subject: RE: [yt-dev] Memory leak issue with ParallelHOP code Hi Britton, I have subscribed to both yt-users and yt-dev. It may possible my requests are pending. As far as dataset is concern, Geoffrey can give you better explanation about it. Dataset contains 0-64 regions. I tried to run ParallelHOP with all regions but because of memory issue, I could not able to complete all in once. Then I ran it with only 0-3 regions to debug code "parallel_hop_interface.py". Please also find attached script. Let me know, if you have more questions. Thanks Pragnesh ________________________________ From: Britton Smith [brittonsmith@gmail.com] Sent: Thursday, November 17, 2011 12:00 PM To: yt-dev@lists.spacepope.org Cc: Patel, Pragneshkumar B Subject: Re: [yt-dev] Memory leak issue with ParallelHOP code Hi again Pragnesh, I mistakenly asked you to post this to the enzo-users mailing when I meant to say that you should post this to the yt-users mailing list. Sorry about that, not enough coffee this morning. Britton On Thu, Nov 17, 2011 at 8:56 AM, Britton Smith <brittonsmith@gmail.com<mailto:brittonsmith@gmail.com>> wrote: Hi Pragnesh, You need to provide us with some more information. What do you mean when you say you ran for 0-3 regions? What kind of dataset are you trying to analyze? How big is it? Can you also please post the script you are using for this? Finally, could you please sign up for the enzo-users mailing list and post this there? You've posted this to the development list, which isn't the best forum for this question. Also, if you're not on the list you won't receive any of the responses to your post. Britton On Thu, Nov 17, 2011 at 7:29 AM, Patel, Pragneshkumar B <pragnesh@utk.edu<mailto:pragnesh@utk.edu>> wrote: Hi Stephen, I found memory leak issue, when I ran Parallel_HOP code. It may not be in python itself but may be in packages(e.g. kdtree etc..), which we call from"parallel_hop_interface.py". Please find attach file, in which you see memory keep increase in every region (I ran program with 32 processes for 0-3 regions.) I like to get your comments/suggestions to solve this issue. I am trying to find more about it using Valgrind. I will let you know. Thanks Pragnesh _______________________________________________ yt-dev mailing list yt-dev@lists.spacepope.org<mailto:yt-dev@lists.spacepope.org> http://lists.spacepope.org/listinfo.cgi/yt-dev-spacepope.org

Hello all, including Pragnesh, hope your request went through. I have since finished the troubling 3200 cube dataset, so good news on my part, but now I'm trying to track down what made it so difficult. Let me summarize the problem I had, Pragnesh was continuing a discussion we had off list: I was analyzing the 3200 cube, and due to peak memory constraints of Natuilus, I tried to analyze subvolumes 1/64 of the whole volume one at a time. The behavior we found was that if we do not end the python script after each subvolume is analyzed with parallelHF() call, and start analyzing the subsequent 1/64 of the subvolume, the peak memory will go up, as per the print statements. If we were to restart the script after each subvolume is analyzed, we can get the peak memory back to a level consistent with the first subvolume. Attached is the memory output plotted of parallelHF with 256 cores, so every 256 (in the x axis) it looks like a step function. Each step correspond to the peak memory used by parallelHF on a subvolume, and the numbers just go up, and if we were to end the calculation in the middle and restart at a particular subvolume, the numbers would drop back down. Since the numbers from each core varied, we were wondering if this is because the particle data remained on the core even after the calculation. hg tip gave: changeset: 4676:edd92d1eadf8 branch: yt tag: tip parent: 4671:85bc12462dff parent: 4675:5efc2462a321 user: Stephen Skory <s@skory.us> date: Wed Oct 19 13:44:33 2011 -0600 summary: Merging from mainline. This is the mod Stephen made to YT to help with this problem about a month ago. It definitely helped with the memory usage, but I just wanted to narrow this problem down to something more tangible besides "memory leak" inside YT. Hopefully others who ran into the same problem or are experts at parallelHF can help us out. These issues were found before the new optional KDtree was put in by Stephen, so that is definitely something we can try. If the problem goes away, then we can probably say that the memory issue is inside the Fortran KDtree. I might be the only one encountering this problem, which only occurs when using YT in unconventional way (I believe the subvolume feature was made for analyzing a single halo, not the whole volume in pieces), so I was wondering if anyone else has come across this phenomenon, maybe running parallelHF on several datasets and seeing a peak memory increase? From G.S. On Thu, Nov 17, 2011 at 9:49 AM, Patel, Pragneshkumar B <pragnesh@utk.edu>wrote:
------------------------------ *From:* Patel, Pragneshkumar B *Sent:* Thursday, November 17, 2011 12:18 PM *To:* Britton Smith *Cc:* Geoffrey So; s@skory.us *Subject:* RE: [yt-dev] Memory leak issue with ParallelHOP code
Hi Britton,
I have subscribed to both yt-users and yt-dev. It may possible my requests are pending. As far as dataset is concern, Geoffrey can give you better explanation about it.
Dataset contains 0-64 regions. I tried to run ParallelHOP with all regions but because of memory issue, I could not able to complete all in once. Then I ran it with only 0-3 regions to debug code "parallel_hop_interface.py".
Please also find attached script. Let me know, if you have more questions.
Thanks Pragnesh
------------------------------ *From:* Britton Smith [brittonsmith@gmail.com] *Sent:* Thursday, November 17, 2011 12:00 PM *To:* yt-dev@lists.spacepope.org *Cc:* Patel, Pragneshkumar B *Subject:* Re: [yt-dev] Memory leak issue with ParallelHOP code
Hi again Pragnesh,
I mistakenly asked you to post this to the enzo-users mailing when I meant to say that you should post this to the yt-users mailing list. Sorry about that, not enough coffee this morning.
Britton
On Thu, Nov 17, 2011 at 8:56 AM, Britton Smith <brittonsmith@gmail.com>wrote:
Hi Pragnesh,
You need to provide us with some more information. What do you mean when you say you ran for 0-3 regions? What kind of dataset are you trying to analyze? How big is it? Can you also please post the script you are using for this?
Finally, could you please sign up for the enzo-users mailing list and post this there? You've posted this to the development list, which isn't the best forum for this question. Also, if you're not on the list you won't receive any of the responses to your post.
Britton
On Thu, Nov 17, 2011 at 7:29 AM, Patel, Pragneshkumar B < pragnesh@utk.edu> wrote:
Hi Stephen,
I found memory leak issue, when I ran Parallel_HOP code. It may not be in python itself but may be in packages(e.g. kdtree etc..), which we call from"parallel_hop_interface.py". Please find attach file, in which you see memory keep increase in every region (I ran program with 32 processes for 0-3 regions.)
I like to get your comments/suggestions to solve this issue.
I am trying to find more about it using Valgrind. I will let you know.
Thanks Pragnesh
_______________________________________________ yt-dev mailing list yt-dev@lists.spacepope.org http://lists.spacepope.org/listinfo.cgi/yt-dev-spacepope.org
_______________________________________________ yt-dev mailing list yt-dev@lists.spacepope.org http://lists.spacepope.org/listinfo.cgi/yt-dev-spacepope.org
{kind=link}

Hi all,
Attached is the memory output plotted of parallelHF with 256 cores, so every 256 (in the x axis) it looks like a step function.
That is an unfortunate graph!
These issues were found before the new optional KDtree was put in by Stephen, so that is definitely something we can try.
If you do decide to test out the alternative kD tree for memory conservation, I would suggest trying a much smaller dataset to begin with. It is much slower than the Fortran one. I am very curious to find out what you discover! -- Stephen Skory s@skory.us http://stephenskory.com/ 510.621.3687 (google voice)
I'll try it over the weekend, have a DD from a 256 cube on my macbook air. Is there anything I need to do i.e. pull from a specific repo like last time, or using the dev install script would automatically give me the changes you've put in for the optional tree="C" ability? I think all I need is to run parallelHF several times in one script. If there is indeed leak in the Fortran kdtree, I should be able to run it on the same dataset multiple of times within the same python instance and see the memory increase. From G.S. On Fri, Nov 18, 2011 at 1:04 PM, Stephen Skory <s@skory.us> wrote:
Hi all,
Attached is the memory output plotted of parallelHF with 256 cores, so every 256 (in the x axis) it looks like a step function.
That is an unfortunate graph!
These issues were found before the new optional KDtree was put in by Stephen, so that is definitely something we can try.
If you do decide to test out the alternative kD tree for memory conservation, I would suggest trying a much smaller dataset to begin with. It is much slower than the Fortran one. I am very curious to find out what you discover!
-- Stephen Skory s@skory.us http://stephenskory.com/ 510.621.3687 (google voice) _______________________________________________ yt-dev mailing list yt-dev@lists.spacepope.org http://lists.spacepope.org/listinfo.cgi/yt-dev-spacepope.org
Geoffrey,
Is there anything I need to do i.e. pull from a specific repo like last time, or using the dev install script would automatically give me the changes you've put in for the optional tree="C" ability?
It's in the current tip of the development version of yt. That should do it! -- Stephen Skory s@skory.us http://stephenskory.com/ 510.621.3687 (google voice)
I must have missed something, because I'm re-running the 256 cube on my lappy but I kept getting the following: yt : [INFO ] 2011-11-19 11:03:51,866 All done! Max Memory = 0 MB from all the MPI tasks, ven though I clearly see that the 4 MPI tasks I launched was using close to 700MB each. I tried this using 1 core no MPI, on the entire dataset without splitting it into subvolume, and using multiple cores, keep getting Max Memory was 0MB. This is using the YT that produced the graph where the memory was going up for each additional subvolume. (stephen-yt)Geoffreys-MacBook-Air:yt-hg gso$ hg tip changeset: 4676:edd92d1eadf8 branch: yt tag: tip parent: 4671:85bc12462dff parent: 4675:5efc2462a321 user: Stephen Skory <s@skory.us> date: Wed Oct 19 13:44:33 2011 -0600 summary: Merging from mainline. Am I using the wrong tip? From G.S. On Fri, Nov 18, 2011 at 4:05 PM, Stephen Skory <s@skory.us> wrote:
Geoffrey,
Is there anything I need to do i.e. pull from a specific repo like last time, or using the dev install script would automatically give me the changes you've put in for the optional tree="C" ability?
It's in the current tip of the development version of yt. That should do it!
-- Stephen Skory s@skory.us http://stephenskory.com/ 510.621.3687 (google voice) _______________________________________________ yt-dev mailing list yt-dev@lists.spacepope.org http://lists.spacepope.org/listinfo.cgi/yt-dev-spacepope.org
Geoffrey,
I must have missed something, because I'm re-running the 256 cube on my lappy but I kept getting the following: yt : [INFO ] 2011-11-19 11:03:51,866 All done! Max Memory = 0 MB
Yes, I should have warned you. Sorry. The way memory is calculated on Linux doesn't work on Mac OS X. You are welcome to try to find a way that does! The pertinent code is here: http://hg.yt-project.org/yt/src/68227951f9b3/yt/funcs.py#cl-123 and google/yahoo/bing/ask jeeves/lycos/altavista/stackoverflow/etc.. are your friend. Good luck, and if you find success, make a pull request and we'll add it! -- Stephen Skory s@skory.us http://stephenskory.com/ 510.621.3687 (google voice)

Hey guys, I just issued a pull request to include more robust calculation of memory usage for when the /proc directory doesn't exist. This is why it doesn't work on macs. If someone wants to check that out and pull it in, then that should help Geoffrey. Britton On Sat, Nov 19, 2011 at 11:48 AM, Stephen Skory <s@skory.us> wrote:
Geoffrey,
I must have missed something, because I'm re-running the 256 cube on my lappy but I kept getting the following: yt : [INFO ] 2011-11-19 11:03:51,866 All done! Max Memory = 0 MB
Yes, I should have warned you. Sorry. The way memory is calculated on Linux doesn't work on Mac OS X. You are welcome to try to find a way that does! The pertinent code is here:
http://hg.yt-project.org/yt/src/68227951f9b3/yt/funcs.py#cl-123
and google/yahoo/bing/ask jeeves/lycos/altavista/stackoverflow/etc.. are your friend. Good luck, and if you find success, make a pull request and we'll add it!
-- Stephen Skory s@skory.us http://stephenskory.com/ 510.621.3687 (google voice) _______________________________________________ yt-dev mailing list yt-dev@lists.spacepope.org http://lists.spacepope.org/listinfo.cgi/yt-dev-spacepope.org
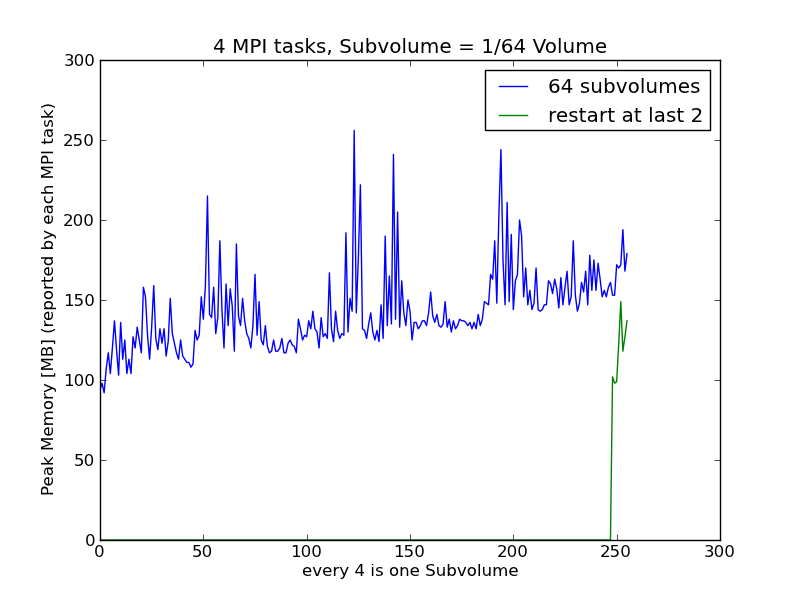
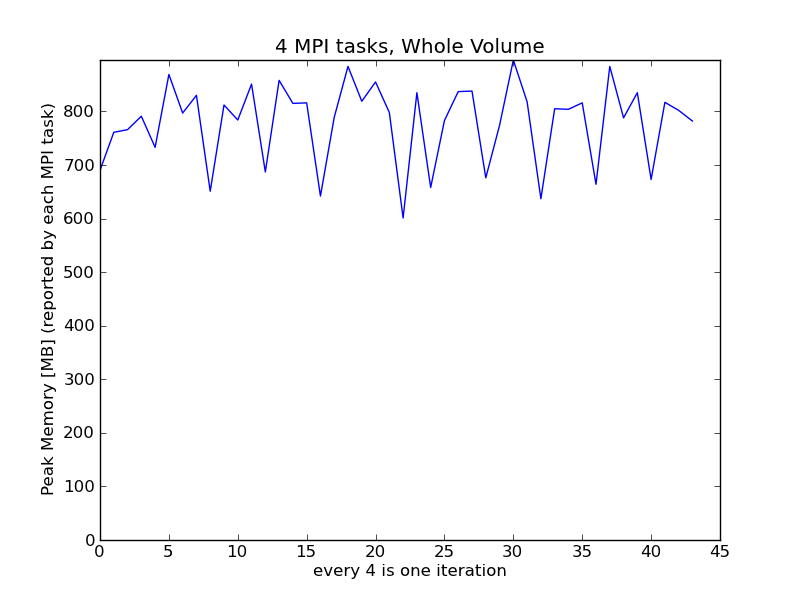
Thanks to Britton's addition to support memory output on macs, I was able to benchmark the different kd-tree options Stephen put in on a small dataset on my laptop. The runs were using the default Fortran kd-tree with the version of YT mentioned in my previous mail (pulling in the changeset of the memory output for mac), and the new one with the "C" kd-tree ran with the following tip: changeset: 4980:a9d0a3e89a59 branch: yt tag: tip user: Britton Smith <brittonsmith@gmail.com> date: Sun Nov 20 13:44:40 2011 -0500 summary: Put fallback method for getting memory usage inside the if tree so All the runs are on the 256 cube Enzo dataset with 4 mpi tasks Results: 1) WholeVol.png Running parallelHF on the whole volume multiple times in the same script, I see no noticeable peak memory increase after 11 runs, which is good. 2) RegionFtree.png Running parallelHF on subvolume 1/64th the size of the whole volume at a time, I see a steady increase in the minimum memory. Although there are peaks at different subvolumes due to the different distribution of particles at different spacial region, I would expect the minimum to fluctuate, but it seems to go up constantly. 3) RegionCtree.png Running paralllelHF on subvolume 1/64th the size of the whole volume, but with the "C" kd-tree. Memory seems to increase a bit like the Fortran case, but it just took way too long so I killed it after the 17th subvolume was done. 4) CompareF_Ctree.png This shows that the C kd-tree's memory savings is definitely noticeable. However, the cost in time is great. For the same 17 subvolumes, the Fortran kd-tree took 7 minutes according to the log, but it took the C kd-tree method 1 hour and 31 minutes! 5) CompareF_restart.png This is the Fortran kd-tree ran from subvolume 0 to 63 non-stop, compare to just starting at subvolume 62 to 63. I've shifted the restart with zeroes at the front so you can get a sense of the corresponding value if it were non-stop. There's a gap between the memory used, showing less memory at the same subvolume, but from a fresh restart of python. After looking at the graphs, I think the memory only builds up when doing parallelHF with the subvolume defined. And as long as the code doesn't crash on the first subvolume, it would probably be faster to just let the machine run out of memory and restart from where it stopped, than to use the C kd-tree. From G.S. On Sat, Nov 19, 2011 at 12:31 PM, Britton Smith <brittonsmith@gmail.com>wrote:
Hey guys,
I just issued a pull request to include more robust calculation of memory usage for when the /proc directory doesn't exist. This is why it doesn't work on macs. If someone wants to check that out and pull it in, then that should help Geoffrey.
Britton
On Sat, Nov 19, 2011 at 11:48 AM, Stephen Skory <s@skory.us> wrote:
Geoffrey,
I must have missed something, because I'm re-running the 256 cube on my lappy but I kept getting the following: yt : [INFO ] 2011-11-19 11:03:51,866 All done! Max Memory = 0 MB
Yes, I should have warned you. Sorry. The way memory is calculated on Linux doesn't work on Mac OS X. You are welcome to try to find a way that does! The pertinent code is here:
http://hg.yt-project.org/yt/src/68227951f9b3/yt/funcs.py#cl-123
and google/yahoo/bing/ask jeeves/lycos/altavista/stackoverflow/etc.. are your friend. Good luck, and if you find success, make a pull request and we'll add it!
-- Stephen Skory s@skory.us http://stephenskory.com/ 510.621.3687 (google voice) _______________________________________________ yt-dev mailing list yt-dev@lists.spacepope.org http://lists.spacepope.org/listinfo.cgi/yt-dev-spacepope.org
_______________________________________________ yt-dev mailing list yt-dev@lists.spacepope.org http://lists.spacepope.org/listinfo.cgi/yt-dev-spacepope.org
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Geoffrey,
After looking at the graphs, I think the memory only builds up when doing parallelHF with the subvolume defined.
First, thank you very much for doing all this work! This is very interesting. I will take a look at how subvolumes are done and see if I can find something amiss in how memory is dealt with. I will also think about this more. Stay tuned! -- Stephen Skory s@skory.us http://stephenskory.com/ 510.621.3687 (google voice)
participants (4)
-
 Britton Smith
Britton Smith -
 Geoffrey So
Geoffrey So -
 Patel, Pragneshkumar B
Patel, Pragneshkumar B -
 Stephen Skory
Stephen Skory