Python multithreading without the GIL

Hi, I've been working on changes to CPython to allow it to run without the global interpreter lock. I'd like to share a working proof-of-concept that can run without the GIL. The proof-of-concept involves substantial changes to CPython internals, but relatively few changes to the C-API. It is compatible with many C extensions: extensions must be rebuilt, but usually require small or no modifications to source code. I've built compatible versions of packages from the scientific Python ecosystem, and they are installable through the bundled "pip". Source code: https://github.com/colesbury/nogil Design overview: https://docs.google.com/document/d/18CXhDb1ygxg-YXNBJNzfzZsDFosB5e6BfnXLlejd... My goal with the proof-of-concept is to demonstrate that removing the GIL is feasible and worthwhile, and that the technical ideas of the project could serve as a basis of such an effort. I'd like to start a discussion about these ideas and gauge the community's interest in this approach to removing the GIL. Regards, Sam Gross colesbury@gmail.com / sgross@fb.com

On Fri, Oct 8, 2021 at 1:51 PM Sam Gross <colesbury@gmail.com> wrote:
Thanks for doing this, and thanks for the detailed writeup! I'd like to offer a perspective from observing the ongoing project of a brother of mine; he does not have the concurrency experience that I have, and it's been instructive to see what he has trouble with. For reference, the project involves GTK (which only works on the main thread), multiple threads for I/O (eg a socket read/parse/process thread), and one thread managed by asyncio using async/await functions. At no point has he ever had a problem with performance, because the project is heavily I/O based, spending most of its time waiting for events. So this is not going to touch on the question of single-threaded vs multi-threaded performance. To him, an async function and a thread function are exactly equivalent. He doesn't think in terms of yield points or anything; they are simply two ways of doing parallelism and are, to his code, equivalent. Mutable shared state is something to get your head around with *any* sort of parallelism, and nothing will change that. Whether it's asyncio, GUI callbacks, or actual threads, the considerations have been exactly the same. Threads neither gain nor lose compared to other options. Not being a low-level programmer, he has, I believe, an inherent assumption that any operation on a built-in type will be atomic. He's never stated this but I suspect he's assuming that. It's an assumption that Python is never going to violate. Concurrency is *hard*. There's no getting around it, there's no sugar-coating it. There are concepts that simply have to be learned, and the failures can be extremely hard to track down. Instantiating an object on the wrong thread can crash GTK, but maybe not immediately. Failing to sleep in one thread results in other threads stalling. I don't think any of this is changed by different modes (with the exception of process-based parallelism, which fixes a lot of concurrency at the cost of explicit IPC), and the more work programmers want their code to do, the more likely that they'll run into this. Glib.idle_add is really just a magic incantation to make the GUI work. :) Spawning a thread for asyncio isn't too hard as long as you don't have to support older Python versions.... sadly, not every device updated at the same time. But in a few years, we will be able to ignore Python versions pre-3.7. Most likely, none of his code would be affected by the removal of the GIL, since (as I understand it) the guarantees as seen in Python code won't change. Will there be impact on lower-memory systems? As small devices go, the Raspberry Pi is one of the largest, but it's still a lot smaller than a full PC, and adding overhead to every object would be costly (I'm not sure what the cost of local reference counting is, but it can't be none). Threading is perfectly acceptable for a project like this, so I'm hoping that GIL removal won't unnecessarily penalize this kind of thread usage. Speaking of local refcounting, how does that affect objects that get passed as thread arguments? Initially, an object is owned by the creating thread, which can relinquish ownership if its local refcount drops to zero; does another thread then take it over? I'm excited by anything that helps parallelism in Python, and very curious to see where this effort will go. If you need a hand with testing, I'd be happy to help out. ChrisA

On Thu, Oct 7, 2021 at 9:10 PM Chris Angelico <rosuav@gmail.com> wrote:
I'd like to encourage folks not to give up on looking for new, simpler parallelism/concurrency formalisms. They're out there - consider how well bash does with its parallelism in pipelines. The truly general ones may end up looking like Java, but I don't think they have to be fully general to be useful.
On Sun, Oct 10, 2021 at 2:31 PM Dan Stromberg <drsalists@gmail.com> wrote:
That's process-based parallelism with unidirectional byte-stream IPC. It's incredibly specific, but also incredibly useful in its place :) Simpler parallelism techniques are always possible if you don't need much interaction between the processes. The challenge isn't making the simple cases work, but making the harder ones efficient. ChrisA

Hi Sam, On Thu, Oct 07, 2021 at 03:52:56PM -0400, Sam Gross wrote:
Getting Python to run without the GIL has never been a major problem for CPython (and of course some other Python interpreters don't have a GIL at all). I think the first attempt was in 1999, a mere handful of years after Python was released. https://www.artima.com/weblogs/viewpost.jsp?thread=214235 The problem has been removing the GIL without seriously degrading performance. How does your GIL-less CPython fork perform? Especially for single-threaded code. Have you been following progress of the GILectomy? https://pythoncapi.readthedocs.io/gilectomy.html Single threaded code is still, and always will be, an important part of Python's ecosystem. A lot of people would be annoyed if the cost of speeding up heavily threaded Python by a small percentage would be to slow down single-threaded Python by a large percentage. -- Steve


To be clear, Sam’s basic approach is a bit slower for single-threaded code, and he admits that. But to sweeten the pot he has also applied a bunch of unrelated speedups that make it faster in general, so that overall it’s always a win. But presumably we could upstream the latter easily, separately from the GIL-freeing part. On Fri, Oct 8, 2021 at 07:42 Łukasz Langa <lukasz@langa.pl> wrote:
-- --Guido (mobile)

On Fri, Oct 8, 2021 at 8:11 AM Guido van Rossum <guido@python.org> wrote:
To be clear, Sam’s basic approach is a bit slower for single-threaded code, and he admits that.
Is it also slower even when running with PYTHONGIL=1? If it could be made the same speed for single-threaded code when running in GIL-enabled mode, that might be an easier intermediate target while still adding value. —Chris But to sweeten the pot he has also applied a bunch of unrelated speedups
On Fri, Oct 8, 2021 at 11:35 AM Chris Jerdonek <chris.jerdonek@gmail.com> wrote:
Running with PYTHONGIL=1 is a bit less than 1% faster (on pyperformance) than with PYTHONGIL=0. It might be possible to improve PYTHONGIL=1 by another 1-2% by adding runtime checks for the GIL before attempting to lock dicts and lists during mutations. I think further optimizations specific to the PYTHONGIL=1 use case would be tricky.

I'm suspicious of pyperformance testing for this reason: The point of Python is operating OK despite GIL because "most of the time is spent in 'external' libraries." Pyperformance tests "typical" python performance where supposedly most tests are "ok" despite GIL. You need multithreading in atypical situations which may involve a lot of raw-python-object "thrashing," with high ref-counting, locks, etc. How do we know that pyperformance actually tests these cases well?

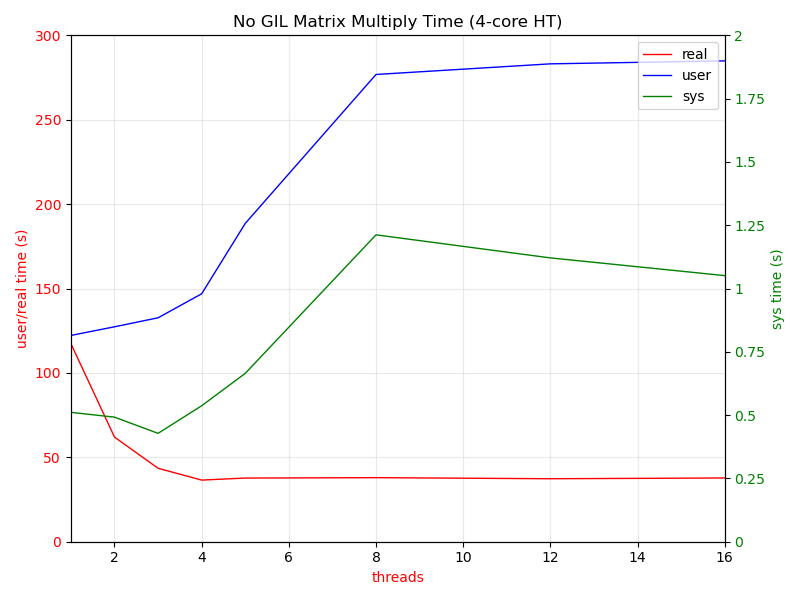
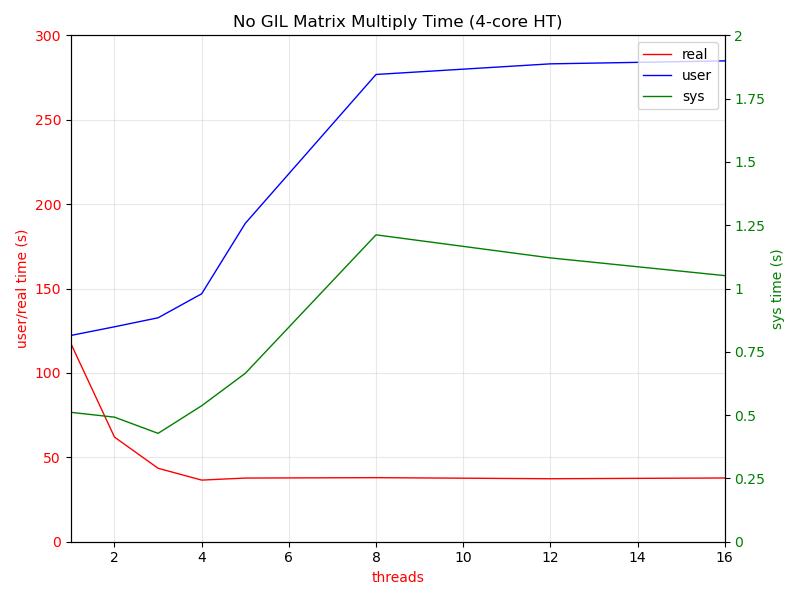
Guido> To be clear, Sam’s basic approach is a bit slower for single-threaded code, and he admits that. But to sweeten the pot he has also applied a bunch of unrelated speedups that make it faster in general, so that overall it’s always a win. But presumably we could upstream the latter easily, separately from the GIL-freeing part. Something just occurred to me. If you upstream all the other goodies (register VM, etc), when the time comes to upstream the no-GIL parts won't the complaint then be (again), "but it's slower for single-threaded code!" ? ;-) Onto other things. For about as long as I can remember, the biggest knock against Python was, "You can never do any serious multi-threaded programming with it. It has this f**king GIL!" I know that attempts to remove it have been made multiple times, beginning with (I think) Greg Smith in the 1.4 timeframe. In my opinion, Sam's work finally solves the problem. Not being a serious parallel programming person (I have used multi-threading a bit in Python, but only for obviously I/O-bound tasks), I thought it might be instructive — for me, at least — to kick the no-GIL tires a bit. Not having any obvious application in mind, I decided to implement a straightforward parallel matrix multiply. (I think I wrote something similar back in the mid-80s in a now defunct Smalltalk-inspired language while at GE.) Note that this was just for my own edification. I have no intention of trying to supplant numpy.matmul() or anything like that. It splits up the computation in the most straightforward (to me) way, handing off the individual vector multiplications to a variable sized thread pool. The code is here: https://gist.github.com/smontanaro/80f788a506d2f41156dae779562fd08d Here is a graph of some timings. My machine is a now decidedly long-in-the-tooth Dell Precision 5520 with a 7th Gen Core i7 processor (four cores + hyperthreading). The data for the graph come from the built-in bash time(1) command. As expected, wall clock time drops as you increase the number of cores until you reach four. After that, nothing improves, since the logical HT cores don't actually have their own ALU (just instruction fetch/decode I think). The slope of the real time improvement from two cores to four isn't as great as one to two, probably because I wasn't careful about keeping the rest of the system quiet. It was running my normal mix, Brave with many open tabs + Emacs. I believe I used A=240x3125, B=3125x480, giving a 240x480 result, so 15200 vector multiplies. . [image: matmul.png] All-in-all, I think Sam's effort is quite impressive. I got things going in fits and starts, needing a bit of help from Sam and Vadym Stupakov to get the modified numpy implementation (crosstalk between my usual Conda environment and the no-GIL stuff). I'm sure there are plenty of problems yet to be solved related to extension modules, but I trust smarter people than me can solve them without a lot of fuss. Once nogil is up-to-date with the latest 3.9 release I hope these changes can start filtering into main. Hopefully that means a 3.11 release. In fact, I'd vote for pushing back the usual release cycle to accommodate inclusion. Sam has gotten this so close it would be a huge disappointment to abandon it now. The problems faced at this point would have been amortized over years of development if the GIL had been removed 20 years ago. I say go for it. Skip

Thanks Skip — nice to see some examples. Did you try running the same code with stock Python? One reason I ask is the IIUC, you are using numpy for the individual vector operations, and numpy already releases the GIL in some circumstances. It would also be fun to see David Beezley’s example from his seminal talk: https://youtu.be/ph374fJqFPE -CHB On Thu, Oct 28, 2021 at 3:55 AM Skip Montanaro <skip.montanaro@gmail.com> wrote:
-- Christopher Barker, PhD (Chris) Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
I had not run the same code with stock Python (but see below). Also, I only used numpy for two bits: 1. I use numpy arrays filled with random values, and the output array is also a numpy array. The vector multiplication is done in a simple for loop in my vecmul() function. 2. Early on I compared my results with the result of numpy.matmul just to make sure I had things right. That said, I have now run my example code using both PYTHONGIL=0 and PYTHONGIL=1 of Sam's nogil branch as well as the following other Python3 versions: * Conda Python3 (3.9.7) * /usr/bin/python3 (3.9.1 in my case) * 3.9 branch tip (3.9.7+) The results were confusing, so I dredged up a copy of pystone to make sure I wasn't missing anything w.r.t. basic execution performance. I'm still confused, so will keep digging. It would also be fun to see David Beezley’s example from his seminal talk:
Thanks, I'll take a look when I get a chance. Might give me the excuse I need to wake up extra early and tag along with Dave on an early morning bike ride. Skip
On Fri, Oct 29, 2021 at 6:10 AM Skip Montanaro <skip.montanaro@gmail.com> wrote:
probably doesn't make a difference for this exercise, but numpy arrays make lousy replacements for a regular list -- i.e. as a container alone. The issue is that floats need to be "boxed" and "unboxed" as you put them in and pull them out of an array. whereas with lists, they float objects themselves are already there. OK, maybe not as bad as I remember. but not great: In [61]: def multiply(vect, scalar, out): ...: """ ...: multiply all the elements in vect by a scalar in place ...: """ ...: for i, val in enumerate(vect): ...: out[i] = val * scalar ...: In [62]: arr = np.random.random((100000,)) In [63]: arrout = np.zeros_like(arr) In [64]: l = list(arr) In [65]: lout = [None] * len(l) In [66]: %timeit multiply(arr, 1.1, arrout) 19.3 ms ± 125 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) In [67]: %timeit multiply(l, 1.1, lout) 12.8 ms ± 83.9 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
* Conda Python3 (3.9.7) * /usr/bin/python3 (3.9.1 in my case) * 3.9 branch tip (3.9.7+) The results were confusing, so I dredged up a copy of pystone to make sure I wasn't missing anything w.r.t. basic execution performance. I'm still confused, so will keep digging. I'll be interested to see what you find out :-) It would also be fun to see David Beezley’s example from his seminal talk:
Thanks, I'll take a look when I get a chance That may not be the best source of the talk -- just the one I found first :-) -CHB -- Christopher Barker, PhD (Chris) Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
Skip> 1. I use numpy arrays filled with random values, and the output array is also a numpy array. The vector multiplication is done in a simple for loop in my vecmul() function. CHB> probably doesn't make a difference for this exercise, but numpy arrays make lousy replacements for a regular list ... Yeah, I don't think it should matter here. Both versions should be similarly penalized. Skip> The results were confusing, so I dredged up a copy of pystone to make sure I wasn't missing anything w.r.t. basic execution performance. I'm still confused, so will keep digging. CHB> I'll be interested to see what you find out :-) I'm still scratching my head. I was thinking there was something about the messaging between the main and worker threads, so I tweaked matmul.py to accept 0 as a number of threads. That means it would call matmul which would call vecmul directly. The original queue-using versions were simply renamed to matmul_t and vecmul_t. I am still confused. Here are the pystone numbers, nogil first, then the 3.9 git tip: (base) nogil_build% ./bin/python3 ~/cmd/pystone.py Pystone(1.1.1) time for 50000 passes = 0.137658 This machine benchmarks at 363218 pystones/second (base) 3.9_build% ./bin/python3 ~/cmd/pystone.py Pystone(1.1.1) time for 50000 passes = 0.207102 This machine benchmarks at 241427 pystones/second That suggests nogil is indeed a definite improvement over vanilla 3.9. However, here's a quick nogil v 3.9 timing run of my matrix multiplication, again, nogil followed by 3.9 tip: (base) nogil_build% time ./bin/python3 ~/tmp/matmul.py 0 100000 a: (160, 625) b: (625, 320) result: (160, 320) -> 51200 real 0m9.314s user 0m9.302s sys 0m0.012s (base) 3.9_build% time ./bin/python3 ~/tmp/matmul.py 0 100000 a: (160, 625) b: (625, 320) result: (160, 320) -> 51200 real 0m4.918s user 0m5.180s sys 0m0.380s What's up with that? Suddenly nogil is much slower than 3.9 tip. No threads are in use. I thought perhaps the nogil run somehow didn't use Sam's VM improvements, so I disassembled the two versions of vecmul. I won't bore you with the entire dis.dis output, but suffice it to say that Sam's instruction set appears to be in play: (base) nogil_build% PYTHONPATH=$HOME/tmp ./bin/python3/python3 Python 3.9.0a4+ (heads/nogil:b0ee2c4740, Oct 30 2021, 16:23:03) [GCC 9.3.0] on linux Type "help", "copyright", "credits" or "license" for more information.
28 2 LOAD_CONST 2 (0.0) 4 STORE_FAST 2 (result) 29 6 LOAD_GLOBAL 3 254 ('len'; 254) 9 STORE_FAST 8 (.t3) 11 COPY 9 0 (.t4 <- a) 14 CALL_FUNCTION 9 1 (.t4 to .t5) 18 STORE_FAST 5 (.t0) ... So I unboxed the two numpy arrays once and used lists of lists for the actual work. The nogil version still performs worse by about a factor of two: (base) nogil_build% time ./bin/python3 ~/tmp/matmul.py 0 100000 a: (160, 625) b: (625, 320) result: (160, 320) -> 51200 real 0m9.537s user 0m9.525s sys 0m0.012s (base) 3.9_build% time ./bin/python3 ~/tmp/matmul.py 0 100000 a: (160, 625) b: (625, 320) result: (160, 320) -> 51200 real 0m4.836s user 0m5.109s sys 0m0.365s Still scratching my head and am open to suggestions about what to try next. If anyone is playing along from home, I've updated my script: https://gist.github.com/smontanaro/80f788a506d2f41156dae779562fd08d I'm sure there are things I could have done more efficiently, but I would think both Python versions would be similarly penalized by dumb s**t I've done. Skip Skip
Remember that py stone is a terrible benchmark. It only exercises a few byte codes and a modern CPU’s caching and branch prediction make minced meat of those. Sam wrote a whole new register-based VM so perhaps that exercises different byte codes. On Sun, Oct 31, 2021 at 05:19 Skip Montanaro <skip.montanaro@gmail.com> wrote:
-- --Guido (mobile)
Remember that py stone is a terrible benchmark.
I understand that. I was only using it as a spot check. I was surprised at how much slower my (threaded or unthreaded) matrix multiply was on nogil vs 3.9+. I went into it thinking I would see an improvement. The Performance section of Sam's design document starts: As mentioned above, the no-GIL proof-of-concept interpreter is about 10% faster than CPython 3.9 (and 3.10) on the pyperformance benchmark suite. so it didn't occur to me that I'd be looking at a slowdown, much less by as much as I'm seeing. Maybe I've somehow stumbled on some instruction mix for which the nogil VM is much worse than the stock VM. For now, I prefer to think I'm just doing something stupid. It certainly wouldn't be the first time. Skip P.S. I suppose I should have cc'd Sam when I first replied to this thread, but I'm doing so now. I figured my mistake would reveal itself early on. Sam, here's my first post about my little "project." https://mail.python.org/archives/list/python-dev@python.org/message/WBLU6PZ2...
Hi Skip, I think the performance difference is because of different versions of NumPy. Python 3.9 installs NumPy 1.21.3 by default for "pip install numpy". I've only built and packaged NumPy 1.19.4 for "nogil" Python. There are substantial performance differences between the two NumPy builds for this matmul script. With NumPy 1.19.4, I get practically the same results for both Python 3.9.2 and "nogil" Python for "time python3 matmul.py 0 100000". I'll update the version of NumPy for "nogil" Python if I have some time this week. Best, Sam On Sun, Oct 31, 2021 at 5:46 PM Skip Montanaro <skip.montanaro@gmail.com> wrote:
I think the performance difference is because of different versions of NumPy.
Good reason to leave numpy completely out of it. Unless you want to test nogil’s performance effects on numpy code — an interesting exercise in itself. Also — sorry I didn’t look at your code before, but you really want to keep the generation of large random arrays out of your benchmark if you can. I suspect that’s what’s changed in numpy versions. In any case, do time the random number generation… -CHB Python 3.9 installs NumPy 1.21.3 by default for "pip install numpy". I've
Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
Sam> I think the performance difference is because of different versions of NumPy. Thanks all for the help/input/advice. It never occurred to me that two relatively recent versions of numpy would differ so much for the simple tasks in my script (array creation & transform). I confirmed this by removing 1.21.3 and installing 1.19.4 in my 3.9 build. I also got a little bit familiar with pyperf, and as a "stretch" goal completely removed random numbers and numpy from my script. (Took me a couple tries to get my array init and transposition correct. Let's just say that it's been awhile. Numpy *was* a nice crutch...) With no trace of numpyleft I now get identical results for single-threaded matrix multiply (a size==10000, b size==20000): 3.9: matmul: Mean +- std dev: 102 ms +- 1 ms nogil: matmul: Mean +- std dev: 103 ms +- 2 ms and a nice speedup for multi-threaded (a size==30000, b size=60000, nthreads=3): 3.9: matmul_t: Mean +- std dev: 290 ms +- 13 ms nogil: matmul_t: Mean +- std dev: 102 ms +- 3 ms Sam> I'll update the version of NumPy for "nogil" Python if I have some time this week. I think it would be sufficient to alert users to the 1.19/1.21 performance differences and recommend they force install 1.19 in non-nogil builds for testing purposes. Hopefully adding a simple note to your README will take less time than porting your changes to numpy 1.21 and adjusting your build configs/scripts. Skip

On Thu, Oct 7, 2021 at 7:54 PM Sam Gross <colesbury@gmail.com> wrote:
Design overview: https://docs.google.com/document/d/18CXhDb1ygxg-YXNBJNzfzZsDFosB5e6BfnXLlejd...
Whoa, this is impressive work. I notice the fb.com address -- is this a personal project or something facebook is working on? what's the relationship to Cinder, if any? Regarding the tricky lock-free dict/list reads: I guess the more straightforward approach would be to use a plain ol' mutex that's optimized for this kind of fine-grained per-object lock with short critical sections and minimal contention, like WTF::Lock. Did you try alternatives like that? If so, I assume they didn't work well -- can you give more details? -n -- Nathaniel J. Smith -- https://vorpus.org
On Fri, Oct 8, 2021 at 12:04 PM Nathaniel Smith <njs@pobox.com> wrote:
I notice the fb.com address -- is this a personal project or something facebook is working on? what's the relationship to Cinder, if any?
It is a Facebook project, at least in the important sense that I work on it as an employee at Facebook. (I'm currently the only person working on it.) I keep in touch with some of the Cinder devs regularly and they've advised on the project, but otherwise the two projects are unrelated.
I'm using WTF::Lock style locks for dict/list mutations. I did an experiment early on where I included locking around reads as well. I think it slowed down the pyperformance benchmarks by ~10% on average, but I can't find my notes so I plan to re-run the experiment. Additionally, because dicts are used for things like global variables, I'd expect that locks around reads prevent efficient scaling, but I haven't measured this.

Is D1.update(D2) still atomic with this implementation? https://docs.python.org/3.11/faq/library.html#what-kinds-of-global-value-mut... On Mon, 11 Oct 2021, 17:54 Sam Gross, <colesbury@gmail.com> wrote:

For dict.update to be atomic I’d expect that with two threads performing an update on the same keys you’d end up the update of either thread, but not a mix. That is: Thread 1: d.update({“a”: 1, “b”: 1}) Thread 2: d.update({“a”: 2, “b”: 2}) The result should have d[“a”] == d[“b”]. This can already end up with a mix of the two when “d” has keys that are objects that implement __eq__ in Python, because the interpreter could switch threads while interpreting __eq__. A pathological example: # — start of script — import threading import time stop = False trigger = False def runfunc(): while not stop: if trigger: d.update({"a": 2, "b": 2 }) print(d) break t = threading.Thread(target=runfunc) t.start() class X(str): def __eq__(self, other): if threading.current_thread() is t: return str.__eq__(self, other) global trigger trigger = True t.join() return str.__eq__(self, other) def __hash__(self): return str.__hash__(self) d = {X("b"):0} print("before", d) d.update({"a":1, "b": 1}) print("after", d) stop = True t.join() # — end of script — This prints "after {'b': 1, 'a': 2}” on my machine. Ronald
— Twitter / micro.blog: @ronaldoussoren Blog: https://blog.ronaldoussoren.net/
On Mon, Oct 11, 2021 at 12:58 PM Thomas Grainger <tagrain@gmail.com> wrote:
Is D1.update(D2) still atomic with this implementation? https://docs.python.org/3.11/faq/library.html#what-kinds-of-global-value-mut...
No. For example, another thread reading from the dict concurrently may observe a partial update. As Ronald Oussoren points out, dict.update isn't atomic in the general case. CPython even includes some checks for concurrent modifications: https://github.com/python/cpython/blob/2f92e2a590f0e5d2d3093549f5af9a4a1889e...

The optimized function calls have about an order of magnitude less overhead
than the current CPython implementation.
The change also simplifies the use of deferred reference counting with the
Congrats Sam! This is incredible work! One quick question after reading the design doc: When you mean "an order of magnitude less overhead than the current CPython implementation" do you mean compared with the main branch? We recently implemented already almost everything is listed in this paragraph: https://github.com/python/cpython/pull/27077 We also pack some extra similar optimizations in this other PR, including stealing the frame arguments from python to python calls: https://github.com/python/cpython/pull/28488 This could explain why the performance is closer to the current master branch as you indicate: It gets about the same average performance as the “main” branch of CPython
3.11 as of early September 2021.
Cheers from cloudy London, Pablo Galindo Salgado On Fri, 8 Oct 2021 at 03:49, Sam Gross <colesbury@gmail.com> wrote:
On Fri, Oct 8, 2021 at 12:24 PM Pablo Galindo Salgado <pablogsal@gmail.com> wrote:
I think I wrote that in August when "current CPython" meant something different from today :) I'll update it. Thanks for the links to the PRs. I'll need to look at them more closely, but one I think one remaining difference is that the "nogil" interpreter stays within the same interpreter loop for many Python function calls, while upstream CPython recursively calls into _PyEval_EvalFrameDefault. I've been using this mini-benchmark to measure the overhead of Python function calls for various numbers of arguments and keywords: https://github.com/colesbury/nogil/blob/fb6aabede5f7f1936a21c2f48ec7fcc0848d... For zero, two, and four argument functions, I get: nogil (nogil/fb6aabed): 10ns, 14ns, 18ns 3.11 (main/b108db63): 47ns, 54ns, 63ns
On Fri, Oct 8, 2021 at 8:55 PM Sam Gross <colesbury@gmail.com> wrote:
Not for much longer though. https://github.com/python/cpython/pull/28488 -- --Guido van Rossum (python.org/~guido) *Pronouns: he/him **(why is my pronoun here?)* <http://feministing.com/2015/02/03/how-using-they-as-a-singular-pronoun-can-c...>

When you mean "an order of magnitude less overhead than the current CPython implementation" do you mean compared with the main branch? We recently implemented already almost everything is listed in this paragraph: https://github.com/python/cpython/pull/27077 We also pack some extra similar optimizations in this other PR, including stealing the frame arguments from python to python calls: https://github.com/python/cpython/pull/28488 This could explain why the performance is closer to the current master branch as you indicate: This means that if we remove the GIL + add the 3.11 improvements we should get some more speed? (or if those are integrated in the POC?) Kind Regards, Abdur-Rahmaan Janhangeer about <https://compileralchemy.github.io/> | blog <https://www.pythonkitchen.com> github <https://github.com/Abdur-RahmaanJ> Mauritius
As far as I understand we should get a smaller improvement on single thread because some of the optimizations listed in this work are partially or totally implemented. This is excluding any non linear behaviour between the different optimizations of course, and assuming that both versions yield the same numbers. On Mon, 11 Oct 2021, 20:28 Abdur-Rahmaan Janhangeer, <arj.python@gmail.com> wrote:

On Fri, 8 Oct 2021 at 03:50, Sam Gross <colesbury@gmail.com> wrote:
My goal with the proof-of-concept is to demonstrate that removing the GIL is feasible and worthwhile, and that the technical ideas of the project could serve as a basis of such an effort.
I'm a novice C programmer, but I'm unsure about the safety of your thread-safe collections description. You describe an algorithm for lock-free read access to list items as 1. Load the version counter from the collection 2. Load the “backing array” from the collection 3. Load the address of the item (from the “backing array”) 4. Increment the reference count of the item, if it is non-zero (otherwise retry) 5. Verify that the item still exists at the same location in the collection (otherwise retry) 6. Verify that the version counter did not change (otherwise retry) 7. Return the address of the item But you do the bounds check for the index before this, here[1]. If the thread is suspended after this and before you read the address of the backing array [2], the list could have been resized (shrunk), and the backing array reallocated from a new memory block. So the pointer you read at 3 could be from uninitialized memory that is beyond the size of the array (or within the array but larger than the current number of items). And then you write to it at 4 which is then a write into a random memory location. [1] https://github.com/colesbury/nogil/blob/fb6aabede5f7f1936a21c2f48ec7fcc0848d... [2] https://github.com/colesbury/nogil/blob/fb6aabede5f7f1936a21c2f48ec7fcc0848d...
On Fri, Oct 8, 2021 at 12:55 PM Daniel Pope <lord.mauve@gmail.com> wrote:
I'm a novice C programmer, but I'm unsure about the safety of your thread-safe collections description.
The "list" class uses a slightly different strategy than "dict", which I forgot about when writing the design overview. List relies on the property that the backing array of a given list can only grow (never shrink) [1]. This is different from upstream CPython. Dict stores the capacity inside PyDictKeysObject (the backing array). The capacity never changes, so if you have a valid pointer to the PyDictKeysObject you load the correct capacity. I've been meaning to change "list" to use the same strategy as "dict". I think that would simplify the overall design and let "list" shrink the backing array again. [1] https://github.com/colesbury/nogil/blob/fb6aabede5f7f1936a21c2f48ec7fcc0848d... (

On 10/7/21 8:52 PM, Sam Gross wrote:
I've been working on changes to CPython to allow it to run without the global interpreter lock.
Before anybody asks: Sam contacted me privately some time ago to pick my brain a little. But honestly, Sam didn't need any help--he'd already taken the project further than I'd ever taken the Gilectomy. I have every confidence in Sam and his work, and I'm excited he's revealed it to the world! Best wishes, //arry/

Congrats on this impressive work Sam. I enjoyed the thorough write up of the design. There’s one aspect that I don’t quite understand. Maybe I missed the explanation. For example: ``` • Load the address of the item • Increment the reference count of the item, if it is non-zero (otherwise retry) • Return the address of the item (We typically acquire the per-collection mutex when retrying operations to avoid potential livelock issues.) ``` I’m unclear what is actually retried. You use this note throughout the document, so I think it would help to clarify exactly what is retried and why that solves the particular problem. I’m confused because, is it the refcount increment that’s retried or the entire sequence of steps (i.e. do you go back and reload the address of the item)? Is there some kind of waiting period before the retry? I would infer that if you’re retrying the refcount incrementing, it’s because you expect subsequent retries to transition from zero to non-zero, but is that guaranteed? Are there possibilities of deadlocks or race conditions? Can you go into some more detail (here or in the document) about how this works? Cheers, -Barry
The entire operation is retried (not just the refcount). For "dict", this means going back to step 1 and reloading the version tag and PyDictKeysObject. The operation can fail (and need to be retried) only when some other thread is concurrently modifying the dict. The reader needs to perform the checks (and retry) to avoid returning inconsistent data, such as an object that was never in the dict. With the checks and retry, returning inconsistent or garbage data is not possible. The retry is performed after locking the dict, so the operation is retried at most once -- the read operation can't fail when it holds the dict's lock because the lock prevents concurrent modifications. It would have also been possible to retry the operation in a loop without locking the dict, but I was concerned about reader starvation. (In the doc I wrote "livelock", but "reader starvation" is more accurate.) In particular, I was concerned that a thread repeatedly modifying a dict might prevent other threads reading the dict from making progress. I hadn't seen this in practice, but I'm aware that reader starvation can be an issue for similar designs like Linux's seqlock. Acquiring the dict's lock when retrying avoids the reader starvation issue. Deadlock isn't possible because the code does not acquire any other locks while holding the dict's lock. For example, the code releases the dict's lock before calling Py_DECREF or PyObject_RichCompareBool. The race condition question is a bit harder to answer precisely. Concurrent reads and modifications of a dict won't cause the program to segfault, return garbage data, or items that were never in the dict. Regards, Sam

On Thu, 7 Oct 2021 15:52:56 -0400 Sam Gross <colesbury@gmail.com> wrote:
Impressive work! Just for the record: """ It’s harder to measure aggregate multi-threaded performance because there aren’t any standard multi-threaded Python benchmarks, but the new interpreter addresses many of the use cases that failed to scale efficiently. """ It's crude, but you can take a look at `ccbench` in the Tools directory. Regards Antoine.
On Mon, Oct 11, 2021 at 7:04 AM Antoine Pitrou <antoine@python.org> wrote:
It's crude, but you can take a look at `ccbench` in the Tools directory.
Thanks, I wasn't familiar with this. The ccbench results look pretty good: about 18.1x speed-up on "pi calculation" and 19.8x speed-up on "regular expression" with 20 threads (turbo off). The latency and throughput results look good too. With the GIL enabled (3.11), the compute intensive background task increases latency and dramatically decreases throughput. With the GIL disabled, latency remains low and throughput high. Here are the full results for 20 threads without the GIL: https://gist.github.com/colesbury/8479ee0246558fa1ab0f49e4c01caeed (nogil, 20 threads) Here are the results for 4 threads (the default) for comparison with upstream: https://gist.github.com/colesbury/8479ee0246558fa1ab0f49e4c01caeed (nogil, 4 threads) https://gist.github.com/colesbury/c0b89f82e51779670265fb7c7cd37114 (3.11/b108db63e0, 4 threads)
I've updated the linked gists with the results from interpreters compiled with PGO, so the numbers have slightly changed.

{kind=link}
{kind=link}

I love everything about this - but I expect some hesitancy due to this "Multithreaded programs are prone to concurrency bugs.". If there is significant pushback, I have one suggestion: Would it be helpful to think of the python concurrency mode as a property of interpreters? `interp = interpreters.create(concurrency_mode=interpreters.GIL)` or `interp = interpreters.create(concurrency_mode=interpreters.NOGIL)` and subsequently python _environments_ can make different choices about what to use for the 0th interpreter, via some kind of configuration. Python modules can declare which concurrency modes they supports. Future concurrency modes that address specific use cases could be added. This would allow python environments who would rather not audit their code for concurrency isuses to opt out, and allow incremental adoption. I can't intuit whether this indirection would cause a performance problem in the C implementation or if there is some clever way to have different variants of relevant objects at compile time and switch between them based on the interpreter concurrency mode.

The way I see it, the concurrency model to be used is selected by developers. They can choose between multi-threading, multi-process, or asyncio, or even a hybrid. If developers select multithreading, then they carry the burden of ensuring mutual exclusion and avoiding race conditions, dead locks, live locks, etc. On Mon, 2021-10-18 at 13:17 +0000, Mohamed Koubaa wrote:
Mohamed> I love everything about this - but I expect some hesitancy due to this "Multithreaded programs are prone to concurrency bugs.". Paul> The way I see it, the concurrency model to be used is selected by developers. They can choose between ... I think the real intent of the statement Mohamed quoted is that just because your program works in a version of Python with the GIL doesn't mean it will work unchanged in a GIL-free world. As we all know, the GIL can hide a multitude of sins. I could be paraphrasing Tim Peters here without realizing it explicitly. It kinda sounds like something he might say. Skip

Hello all, I am very excited about a future multithreaded Python. I managed to postpone some rewrites in the company I work for Rust/Go, precisely because of the potential to have a Python solution in the medium term. I was wondering. Is Sam Gross' nogil merge being seriously considered by the core Python team?

On Sat, Apr 23, 2022 at 8:31 AM <brataodream@gmail.com> wrote:
Yes, although we have no timeline as to when we will make a decision about whether we will accept it or not. The last update we had on the work was Sam was upstreaming the performance improvements he made that were not nogil-specific. The nogil work was also being updated for the `main` branch. Once that's all done we will probably start a serious discussion as to whether we want to accept it.
On Mon, Apr 25, 2022 at 2:33 PM Brett Cannon <brett@python.org> wrote:
We haven't even discussed a *process* for how to decide. OTOH, in two days at the Language Summit at PyCon, Sam will give a presentation to the core devs present (which is far from all of us, alas).
It's possible that I've missed those code reviews, but I haven't seen a single PR from Sam, nor have there been any messages from him in this forum or in any other forums I'm monitoring. I'm hoping that the Language Summit will change this, but I suspect that there aren't that many perf improvements in Sam's work that are easily separated from the nogil work. (To be sure, Christian Heimes seems to have made progress with introducing mimalloc, which is one of Sam's dependencies, but AFAIK that work hasn't been finished yet.) -- --Guido van Rossum (python.org/~guido) *Pronouns: he/him **(why is my pronoun here?)* <http://feministing.com/2015/02/03/how-using-they-as-a-singular-pronoun-can-c...>
On Fri, Oct 8, 2021 at 1:51 PM Sam Gross <colesbury@gmail.com> wrote:
Thanks for doing this, and thanks for the detailed writeup! I'd like to offer a perspective from observing the ongoing project of a brother of mine; he does not have the concurrency experience that I have, and it's been instructive to see what he has trouble with. For reference, the project involves GTK (which only works on the main thread), multiple threads for I/O (eg a socket read/parse/process thread), and one thread managed by asyncio using async/await functions. At no point has he ever had a problem with performance, because the project is heavily I/O based, spending most of its time waiting for events. So this is not going to touch on the question of single-threaded vs multi-threaded performance. To him, an async function and a thread function are exactly equivalent. He doesn't think in terms of yield points or anything; they are simply two ways of doing parallelism and are, to his code, equivalent. Mutable shared state is something to get your head around with *any* sort of parallelism, and nothing will change that. Whether it's asyncio, GUI callbacks, or actual threads, the considerations have been exactly the same. Threads neither gain nor lose compared to other options. Not being a low-level programmer, he has, I believe, an inherent assumption that any operation on a built-in type will be atomic. He's never stated this but I suspect he's assuming that. It's an assumption that Python is never going to violate. Concurrency is *hard*. There's no getting around it, there's no sugar-coating it. There are concepts that simply have to be learned, and the failures can be extremely hard to track down. Instantiating an object on the wrong thread can crash GTK, but maybe not immediately. Failing to sleep in one thread results in other threads stalling. I don't think any of this is changed by different modes (with the exception of process-based parallelism, which fixes a lot of concurrency at the cost of explicit IPC), and the more work programmers want their code to do, the more likely that they'll run into this. Glib.idle_add is really just a magic incantation to make the GUI work. :) Spawning a thread for asyncio isn't too hard as long as you don't have to support older Python versions.... sadly, not every device updated at the same time. But in a few years, we will be able to ignore Python versions pre-3.7. Most likely, none of his code would be affected by the removal of the GIL, since (as I understand it) the guarantees as seen in Python code won't change. Will there be impact on lower-memory systems? As small devices go, the Raspberry Pi is one of the largest, but it's still a lot smaller than a full PC, and adding overhead to every object would be costly (I'm not sure what the cost of local reference counting is, but it can't be none). Threading is perfectly acceptable for a project like this, so I'm hoping that GIL removal won't unnecessarily penalize this kind of thread usage. Speaking of local refcounting, how does that affect objects that get passed as thread arguments? Initially, an object is owned by the creating thread, which can relinquish ownership if its local refcount drops to zero; does another thread then take it over? I'm excited by anything that helps parallelism in Python, and very curious to see where this effort will go. If you need a hand with testing, I'd be happy to help out. ChrisA
On Thu, Oct 7, 2021 at 9:10 PM Chris Angelico <rosuav@gmail.com> wrote:
I'd like to encourage folks not to give up on looking for new, simpler parallelism/concurrency formalisms. They're out there - consider how well bash does with its parallelism in pipelines. The truly general ones may end up looking like Java, but I don't think they have to be fully general to be useful.
On Sun, Oct 10, 2021 at 2:31 PM Dan Stromberg <drsalists@gmail.com> wrote:
That's process-based parallelism with unidirectional byte-stream IPC. It's incredibly specific, but also incredibly useful in its place :) Simpler parallelism techniques are always possible if you don't need much interaction between the processes. The challenge isn't making the simple cases work, but making the harder ones efficient. ChrisA
Hi Sam, On Thu, Oct 07, 2021 at 03:52:56PM -0400, Sam Gross wrote:
Getting Python to run without the GIL has never been a major problem for CPython (and of course some other Python interpreters don't have a GIL at all). I think the first attempt was in 1999, a mere handful of years after Python was released. https://www.artima.com/weblogs/viewpost.jsp?thread=214235 The problem has been removing the GIL without seriously degrading performance. How does your GIL-less CPython fork perform? Especially for single-threaded code. Have you been following progress of the GILectomy? https://pythoncapi.readthedocs.io/gilectomy.html Single threaded code is still, and always will be, an important part of Python's ecosystem. A lot of people would be annoyed if the cost of speeding up heavily threaded Python by a small percentage would be to slow down single-threaded Python by a large percentage. -- Steve
To be clear, Sam’s basic approach is a bit slower for single-threaded code, and he admits that. But to sweeten the pot he has also applied a bunch of unrelated speedups that make it faster in general, so that overall it’s always a win. But presumably we could upstream the latter easily, separately from the GIL-freeing part. On Fri, Oct 8, 2021 at 07:42 Łukasz Langa <lukasz@langa.pl> wrote:
-- --Guido (mobile)
On Fri, Oct 8, 2021 at 8:11 AM Guido van Rossum <guido@python.org> wrote:
To be clear, Sam’s basic approach is a bit slower for single-threaded code, and he admits that.
Is it also slower even when running with PYTHONGIL=1? If it could be made the same speed for single-threaded code when running in GIL-enabled mode, that might be an easier intermediate target while still adding value. —Chris But to sweeten the pot he has also applied a bunch of unrelated speedups
On Fri, Oct 8, 2021 at 11:35 AM Chris Jerdonek <chris.jerdonek@gmail.com> wrote:
Running with PYTHONGIL=1 is a bit less than 1% faster (on pyperformance) than with PYTHONGIL=0. It might be possible to improve PYTHONGIL=1 by another 1-2% by adding runtime checks for the GIL before attempting to lock dicts and lists during mutations. I think further optimizations specific to the PYTHONGIL=1 use case would be tricky.
I'm suspicious of pyperformance testing for this reason: The point of Python is operating OK despite GIL because "most of the time is spent in 'external' libraries." Pyperformance tests "typical" python performance where supposedly most tests are "ok" despite GIL. You need multithreading in atypical situations which may involve a lot of raw-python-object "thrashing," with high ref-counting, locks, etc. How do we know that pyperformance actually tests these cases well?
Guido> To be clear, Sam’s basic approach is a bit slower for single-threaded code, and he admits that. But to sweeten the pot he has also applied a bunch of unrelated speedups that make it faster in general, so that overall it’s always a win. But presumably we could upstream the latter easily, separately from the GIL-freeing part. Something just occurred to me. If you upstream all the other goodies (register VM, etc), when the time comes to upstream the no-GIL parts won't the complaint then be (again), "but it's slower for single-threaded code!" ? ;-) Onto other things. For about as long as I can remember, the biggest knock against Python was, "You can never do any serious multi-threaded programming with it. It has this f**king GIL!" I know that attempts to remove it have been made multiple times, beginning with (I think) Greg Smith in the 1.4 timeframe. In my opinion, Sam's work finally solves the problem. Not being a serious parallel programming person (I have used multi-threading a bit in Python, but only for obviously I/O-bound tasks), I thought it might be instructive — for me, at least — to kick the no-GIL tires a bit. Not having any obvious application in mind, I decided to implement a straightforward parallel matrix multiply. (I think I wrote something similar back in the mid-80s in a now defunct Smalltalk-inspired language while at GE.) Note that this was just for my own edification. I have no intention of trying to supplant numpy.matmul() or anything like that. It splits up the computation in the most straightforward (to me) way, handing off the individual vector multiplications to a variable sized thread pool. The code is here: https://gist.github.com/smontanaro/80f788a506d2f41156dae779562fd08d Here is a graph of some timings. My machine is a now decidedly long-in-the-tooth Dell Precision 5520 with a 7th Gen Core i7 processor (four cores + hyperthreading). The data for the graph come from the built-in bash time(1) command. As expected, wall clock time drops as you increase the number of cores until you reach four. After that, nothing improves, since the logical HT cores don't actually have their own ALU (just instruction fetch/decode I think). The slope of the real time improvement from two cores to four isn't as great as one to two, probably because I wasn't careful about keeping the rest of the system quiet. It was running my normal mix, Brave with many open tabs + Emacs. I believe I used A=240x3125, B=3125x480, giving a 240x480 result, so 15200 vector multiplies. . [image: matmul.png] All-in-all, I think Sam's effort is quite impressive. I got things going in fits and starts, needing a bit of help from Sam and Vadym Stupakov to get the modified numpy implementation (crosstalk between my usual Conda environment and the no-GIL stuff). I'm sure there are plenty of problems yet to be solved related to extension modules, but I trust smarter people than me can solve them without a lot of fuss. Once nogil is up-to-date with the latest 3.9 release I hope these changes can start filtering into main. Hopefully that means a 3.11 release. In fact, I'd vote for pushing back the usual release cycle to accommodate inclusion. Sam has gotten this so close it would be a huge disappointment to abandon it now. The problems faced at this point would have been amortized over years of development if the GIL had been removed 20 years ago. I say go for it. Skip
Thanks Skip — nice to see some examples. Did you try running the same code with stock Python? One reason I ask is the IIUC, you are using numpy for the individual vector operations, and numpy already releases the GIL in some circumstances. It would also be fun to see David Beezley’s example from his seminal talk: https://youtu.be/ph374fJqFPE -CHB On Thu, Oct 28, 2021 at 3:55 AM Skip Montanaro <skip.montanaro@gmail.com> wrote:
-- Christopher Barker, PhD (Chris) Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
I had not run the same code with stock Python (but see below). Also, I only used numpy for two bits: 1. I use numpy arrays filled with random values, and the output array is also a numpy array. The vector multiplication is done in a simple for loop in my vecmul() function. 2. Early on I compared my results with the result of numpy.matmul just to make sure I had things right. That said, I have now run my example code using both PYTHONGIL=0 and PYTHONGIL=1 of Sam's nogil branch as well as the following other Python3 versions: * Conda Python3 (3.9.7) * /usr/bin/python3 (3.9.1 in my case) * 3.9 branch tip (3.9.7+) The results were confusing, so I dredged up a copy of pystone to make sure I wasn't missing anything w.r.t. basic execution performance. I'm still confused, so will keep digging. It would also be fun to see David Beezley’s example from his seminal talk:
Thanks, I'll take a look when I get a chance. Might give me the excuse I need to wake up extra early and tag along with Dave on an early morning bike ride. Skip
On Fri, Oct 29, 2021 at 6:10 AM Skip Montanaro <skip.montanaro@gmail.com> wrote:
probably doesn't make a difference for this exercise, but numpy arrays make lousy replacements for a regular list -- i.e. as a container alone. The issue is that floats need to be "boxed" and "unboxed" as you put them in and pull them out of an array. whereas with lists, they float objects themselves are already there. OK, maybe not as bad as I remember. but not great: In [61]: def multiply(vect, scalar, out): ...: """ ...: multiply all the elements in vect by a scalar in place ...: """ ...: for i, val in enumerate(vect): ...: out[i] = val * scalar ...: In [62]: arr = np.random.random((100000,)) In [63]: arrout = np.zeros_like(arr) In [64]: l = list(arr) In [65]: lout = [None] * len(l) In [66]: %timeit multiply(arr, 1.1, arrout) 19.3 ms ± 125 µs per loop (mean ± std. dev. of 7 runs, 100 loops each) In [67]: %timeit multiply(l, 1.1, lout) 12.8 ms ± 83.9 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
* Conda Python3 (3.9.7) * /usr/bin/python3 (3.9.1 in my case) * 3.9 branch tip (3.9.7+) The results were confusing, so I dredged up a copy of pystone to make sure I wasn't missing anything w.r.t. basic execution performance. I'm still confused, so will keep digging. I'll be interested to see what you find out :-) It would also be fun to see David Beezley’s example from his seminal talk:
Thanks, I'll take a look when I get a chance That may not be the best source of the talk -- just the one I found first :-) -CHB -- Christopher Barker, PhD (Chris) Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
Skip> 1. I use numpy arrays filled with random values, and the output array is also a numpy array. The vector multiplication is done in a simple for loop in my vecmul() function. CHB> probably doesn't make a difference for this exercise, but numpy arrays make lousy replacements for a regular list ... Yeah, I don't think it should matter here. Both versions should be similarly penalized. Skip> The results were confusing, so I dredged up a copy of pystone to make sure I wasn't missing anything w.r.t. basic execution performance. I'm still confused, so will keep digging. CHB> I'll be interested to see what you find out :-) I'm still scratching my head. I was thinking there was something about the messaging between the main and worker threads, so I tweaked matmul.py to accept 0 as a number of threads. That means it would call matmul which would call vecmul directly. The original queue-using versions were simply renamed to matmul_t and vecmul_t. I am still confused. Here are the pystone numbers, nogil first, then the 3.9 git tip: (base) nogil_build% ./bin/python3 ~/cmd/pystone.py Pystone(1.1.1) time for 50000 passes = 0.137658 This machine benchmarks at 363218 pystones/second (base) 3.9_build% ./bin/python3 ~/cmd/pystone.py Pystone(1.1.1) time for 50000 passes = 0.207102 This machine benchmarks at 241427 pystones/second That suggests nogil is indeed a definite improvement over vanilla 3.9. However, here's a quick nogil v 3.9 timing run of my matrix multiplication, again, nogil followed by 3.9 tip: (base) nogil_build% time ./bin/python3 ~/tmp/matmul.py 0 100000 a: (160, 625) b: (625, 320) result: (160, 320) -> 51200 real 0m9.314s user 0m9.302s sys 0m0.012s (base) 3.9_build% time ./bin/python3 ~/tmp/matmul.py 0 100000 a: (160, 625) b: (625, 320) result: (160, 320) -> 51200 real 0m4.918s user 0m5.180s sys 0m0.380s What's up with that? Suddenly nogil is much slower than 3.9 tip. No threads are in use. I thought perhaps the nogil run somehow didn't use Sam's VM improvements, so I disassembled the two versions of vecmul. I won't bore you with the entire dis.dis output, but suffice it to say that Sam's instruction set appears to be in play: (base) nogil_build% PYTHONPATH=$HOME/tmp ./bin/python3/python3 Python 3.9.0a4+ (heads/nogil:b0ee2c4740, Oct 30 2021, 16:23:03) [GCC 9.3.0] on linux Type "help", "copyright", "credits" or "license" for more information.
28 2 LOAD_CONST 2 (0.0) 4 STORE_FAST 2 (result) 29 6 LOAD_GLOBAL 3 254 ('len'; 254) 9 STORE_FAST 8 (.t3) 11 COPY 9 0 (.t4 <- a) 14 CALL_FUNCTION 9 1 (.t4 to .t5) 18 STORE_FAST 5 (.t0) ... So I unboxed the two numpy arrays once and used lists of lists for the actual work. The nogil version still performs worse by about a factor of two: (base) nogil_build% time ./bin/python3 ~/tmp/matmul.py 0 100000 a: (160, 625) b: (625, 320) result: (160, 320) -> 51200 real 0m9.537s user 0m9.525s sys 0m0.012s (base) 3.9_build% time ./bin/python3 ~/tmp/matmul.py 0 100000 a: (160, 625) b: (625, 320) result: (160, 320) -> 51200 real 0m4.836s user 0m5.109s sys 0m0.365s Still scratching my head and am open to suggestions about what to try next. If anyone is playing along from home, I've updated my script: https://gist.github.com/smontanaro/80f788a506d2f41156dae779562fd08d I'm sure there are things I could have done more efficiently, but I would think both Python versions would be similarly penalized by dumb s**t I've done. Skip Skip
Remember that py stone is a terrible benchmark. It only exercises a few byte codes and a modern CPU’s caching and branch prediction make minced meat of those. Sam wrote a whole new register-based VM so perhaps that exercises different byte codes. On Sun, Oct 31, 2021 at 05:19 Skip Montanaro <skip.montanaro@gmail.com> wrote:
-- --Guido (mobile)
Remember that py stone is a terrible benchmark.
I understand that. I was only using it as a spot check. I was surprised at how much slower my (threaded or unthreaded) matrix multiply was on nogil vs 3.9+. I went into it thinking I would see an improvement. The Performance section of Sam's design document starts: As mentioned above, the no-GIL proof-of-concept interpreter is about 10% faster than CPython 3.9 (and 3.10) on the pyperformance benchmark suite. so it didn't occur to me that I'd be looking at a slowdown, much less by as much as I'm seeing. Maybe I've somehow stumbled on some instruction mix for which the nogil VM is much worse than the stock VM. For now, I prefer to think I'm just doing something stupid. It certainly wouldn't be the first time. Skip P.S. I suppose I should have cc'd Sam when I first replied to this thread, but I'm doing so now. I figured my mistake would reveal itself early on. Sam, here's my first post about my little "project." https://mail.python.org/archives/list/python-dev@python.org/message/WBLU6PZ2...
Hi Skip, I think the performance difference is because of different versions of NumPy. Python 3.9 installs NumPy 1.21.3 by default for "pip install numpy". I've only built and packaged NumPy 1.19.4 for "nogil" Python. There are substantial performance differences between the two NumPy builds for this matmul script. With NumPy 1.19.4, I get practically the same results for both Python 3.9.2 and "nogil" Python for "time python3 matmul.py 0 100000". I'll update the version of NumPy for "nogil" Python if I have some time this week. Best, Sam On Sun, Oct 31, 2021 at 5:46 PM Skip Montanaro <skip.montanaro@gmail.com> wrote:
I think the performance difference is because of different versions of NumPy.
Good reason to leave numpy completely out of it. Unless you want to test nogil’s performance effects on numpy code — an interesting exercise in itself. Also — sorry I didn’t look at your code before, but you really want to keep the generation of large random arrays out of your benchmark if you can. I suspect that’s what’s changed in numpy versions. In any case, do time the random number generation… -CHB Python 3.9 installs NumPy 1.21.3 by default for "pip install numpy". I've
Python Language Consulting - Teaching - Scientific Software Development - Desktop GUI and Web Development - wxPython, numpy, scipy, Cython
Sam> I think the performance difference is because of different versions of NumPy. Thanks all for the help/input/advice. It never occurred to me that two relatively recent versions of numpy would differ so much for the simple tasks in my script (array creation & transform). I confirmed this by removing 1.21.3 and installing 1.19.4 in my 3.9 build. I also got a little bit familiar with pyperf, and as a "stretch" goal completely removed random numbers and numpy from my script. (Took me a couple tries to get my array init and transposition correct. Let's just say that it's been awhile. Numpy *was* a nice crutch...) With no trace of numpyleft I now get identical results for single-threaded matrix multiply (a size==10000, b size==20000): 3.9: matmul: Mean +- std dev: 102 ms +- 1 ms nogil: matmul: Mean +- std dev: 103 ms +- 2 ms and a nice speedup for multi-threaded (a size==30000, b size=60000, nthreads=3): 3.9: matmul_t: Mean +- std dev: 290 ms +- 13 ms nogil: matmul_t: Mean +- std dev: 102 ms +- 3 ms Sam> I'll update the version of NumPy for "nogil" Python if I have some time this week. I think it would be sufficient to alert users to the 1.19/1.21 performance differences and recommend they force install 1.19 in non-nogil builds for testing purposes. Hopefully adding a simple note to your README will take less time than porting your changes to numpy 1.21 and adjusting your build configs/scripts. Skip
On Thu, Oct 7, 2021 at 7:54 PM Sam Gross <colesbury@gmail.com> wrote:
Design overview: https://docs.google.com/document/d/18CXhDb1ygxg-YXNBJNzfzZsDFosB5e6BfnXLlejd...
Whoa, this is impressive work. I notice the fb.com address -- is this a personal project or something facebook is working on? what's the relationship to Cinder, if any? Regarding the tricky lock-free dict/list reads: I guess the more straightforward approach would be to use a plain ol' mutex that's optimized for this kind of fine-grained per-object lock with short critical sections and minimal contention, like WTF::Lock. Did you try alternatives like that? If so, I assume they didn't work well -- can you give more details? -n -- Nathaniel J. Smith -- https://vorpus.org
On Fri, Oct 8, 2021 at 12:04 PM Nathaniel Smith <njs@pobox.com> wrote:
I notice the fb.com address -- is this a personal project or something facebook is working on? what's the relationship to Cinder, if any?
It is a Facebook project, at least in the important sense that I work on it as an employee at Facebook. (I'm currently the only person working on it.) I keep in touch with some of the Cinder devs regularly and they've advised on the project, but otherwise the two projects are unrelated.
I'm using WTF::Lock style locks for dict/list mutations. I did an experiment early on where I included locking around reads as well. I think it slowed down the pyperformance benchmarks by ~10% on average, but I can't find my notes so I plan to re-run the experiment. Additionally, because dicts are used for things like global variables, I'd expect that locks around reads prevent efficient scaling, but I haven't measured this.
Is D1.update(D2) still atomic with this implementation? https://docs.python.org/3.11/faq/library.html#what-kinds-of-global-value-mut... On Mon, 11 Oct 2021, 17:54 Sam Gross, <colesbury@gmail.com> wrote:
For dict.update to be atomic I’d expect that with two threads performing an update on the same keys you’d end up the update of either thread, but not a mix. That is: Thread 1: d.update({“a”: 1, “b”: 1}) Thread 2: d.update({“a”: 2, “b”: 2}) The result should have d[“a”] == d[“b”]. This can already end up with a mix of the two when “d” has keys that are objects that implement __eq__ in Python, because the interpreter could switch threads while interpreting __eq__. A pathological example: # — start of script — import threading import time stop = False trigger = False def runfunc(): while not stop: if trigger: d.update({"a": 2, "b": 2 }) print(d) break t = threading.Thread(target=runfunc) t.start() class X(str): def __eq__(self, other): if threading.current_thread() is t: return str.__eq__(self, other) global trigger trigger = True t.join() return str.__eq__(self, other) def __hash__(self): return str.__hash__(self) d = {X("b"):0} print("before", d) d.update({"a":1, "b": 1}) print("after", d) stop = True t.join() # — end of script — This prints "after {'b': 1, 'a': 2}” on my machine. Ronald
— Twitter / micro.blog: @ronaldoussoren Blog: https://blog.ronaldoussoren.net/
On Mon, Oct 11, 2021 at 12:58 PM Thomas Grainger <tagrain@gmail.com> wrote:
Is D1.update(D2) still atomic with this implementation? https://docs.python.org/3.11/faq/library.html#what-kinds-of-global-value-mut...
No. For example, another thread reading from the dict concurrently may observe a partial update. As Ronald Oussoren points out, dict.update isn't atomic in the general case. CPython even includes some checks for concurrent modifications: https://github.com/python/cpython/blob/2f92e2a590f0e5d2d3093549f5af9a4a1889e...
I have a PR to remove this FAQ entry: https://github.com/python/cpython/pull/28886
The optimized function calls have about an order of magnitude less overhead
than the current CPython implementation.
The change also simplifies the use of deferred reference counting with the
Congrats Sam! This is incredible work! One quick question after reading the design doc: When you mean "an order of magnitude less overhead than the current CPython implementation" do you mean compared with the main branch? We recently implemented already almost everything is listed in this paragraph: https://github.com/python/cpython/pull/27077 We also pack some extra similar optimizations in this other PR, including stealing the frame arguments from python to python calls: https://github.com/python/cpython/pull/28488 This could explain why the performance is closer to the current master branch as you indicate: It gets about the same average performance as the “main” branch of CPython
3.11 as of early September 2021.
Cheers from cloudy London, Pablo Galindo Salgado On Fri, 8 Oct 2021 at 03:49, Sam Gross <colesbury@gmail.com> wrote:
On Fri, Oct 8, 2021 at 12:24 PM Pablo Galindo Salgado <pablogsal@gmail.com> wrote:
I think I wrote that in August when "current CPython" meant something different from today :) I'll update it. Thanks for the links to the PRs. I'll need to look at them more closely, but one I think one remaining difference is that the "nogil" interpreter stays within the same interpreter loop for many Python function calls, while upstream CPython recursively calls into _PyEval_EvalFrameDefault. I've been using this mini-benchmark to measure the overhead of Python function calls for various numbers of arguments and keywords: https://github.com/colesbury/nogil/blob/fb6aabede5f7f1936a21c2f48ec7fcc0848d... For zero, two, and four argument functions, I get: nogil (nogil/fb6aabed): 10ns, 14ns, 18ns 3.11 (main/b108db63): 47ns, 54ns, 63ns
On Fri, Oct 8, 2021 at 8:55 PM Sam Gross <colesbury@gmail.com> wrote:
Not for much longer though. https://github.com/python/cpython/pull/28488 -- --Guido van Rossum (python.org/~guido) *Pronouns: he/him **(why is my pronoun here?)* <http://feministing.com/2015/02/03/how-using-they-as-a-singular-pronoun-can-c...>
When you mean "an order of magnitude less overhead than the current CPython implementation" do you mean compared with the main branch? We recently implemented already almost everything is listed in this paragraph: https://github.com/python/cpython/pull/27077 We also pack some extra similar optimizations in this other PR, including stealing the frame arguments from python to python calls: https://github.com/python/cpython/pull/28488 This could explain why the performance is closer to the current master branch as you indicate: This means that if we remove the GIL + add the 3.11 improvements we should get some more speed? (or if those are integrated in the POC?) Kind Regards, Abdur-Rahmaan Janhangeer about <https://compileralchemy.github.io/> | blog <https://www.pythonkitchen.com> github <https://github.com/Abdur-RahmaanJ> Mauritius
As far as I understand we should get a smaller improvement on single thread because some of the optimizations listed in this work are partially or totally implemented. This is excluding any non linear behaviour between the different optimizations of course, and assuming that both versions yield the same numbers. On Mon, 11 Oct 2021, 20:28 Abdur-Rahmaan Janhangeer, <arj.python@gmail.com> wrote:
On Fri, 8 Oct 2021 at 03:50, Sam Gross <colesbury@gmail.com> wrote:
My goal with the proof-of-concept is to demonstrate that removing the GIL is feasible and worthwhile, and that the technical ideas of the project could serve as a basis of such an effort.
I'm a novice C programmer, but I'm unsure about the safety of your thread-safe collections description. You describe an algorithm for lock-free read access to list items as 1. Load the version counter from the collection 2. Load the “backing array” from the collection 3. Load the address of the item (from the “backing array”) 4. Increment the reference count of the item, if it is non-zero (otherwise retry) 5. Verify that the item still exists at the same location in the collection (otherwise retry) 6. Verify that the version counter did not change (otherwise retry) 7. Return the address of the item But you do the bounds check for the index before this, here[1]. If the thread is suspended after this and before you read the address of the backing array [2], the list could have been resized (shrunk), and the backing array reallocated from a new memory block. So the pointer you read at 3 could be from uninitialized memory that is beyond the size of the array (or within the array but larger than the current number of items). And then you write to it at 4 which is then a write into a random memory location. [1] https://github.com/colesbury/nogil/blob/fb6aabede5f7f1936a21c2f48ec7fcc0848d... [2] https://github.com/colesbury/nogil/blob/fb6aabede5f7f1936a21c2f48ec7fcc0848d...
On Fri, Oct 8, 2021 at 12:55 PM Daniel Pope <lord.mauve@gmail.com> wrote:
I'm a novice C programmer, but I'm unsure about the safety of your thread-safe collections description.
The "list" class uses a slightly different strategy than "dict", which I forgot about when writing the design overview. List relies on the property that the backing array of a given list can only grow (never shrink) [1]. This is different from upstream CPython. Dict stores the capacity inside PyDictKeysObject (the backing array). The capacity never changes, so if you have a valid pointer to the PyDictKeysObject you load the correct capacity. I've been meaning to change "list" to use the same strategy as "dict". I think that would simplify the overall design and let "list" shrink the backing array again. [1] https://github.com/colesbury/nogil/blob/fb6aabede5f7f1936a21c2f48ec7fcc0848d... (
On 10/7/21 8:52 PM, Sam Gross wrote:
I've been working on changes to CPython to allow it to run without the global interpreter lock.
Before anybody asks: Sam contacted me privately some time ago to pick my brain a little. But honestly, Sam didn't need any help--he'd already taken the project further than I'd ever taken the Gilectomy. I have every confidence in Sam and his work, and I'm excited he's revealed it to the world! Best wishes, //arry/
Congrats on this impressive work Sam. I enjoyed the thorough write up of the design. There’s one aspect that I don’t quite understand. Maybe I missed the explanation. For example: ``` • Load the address of the item • Increment the reference count of the item, if it is non-zero (otherwise retry) • Return the address of the item (We typically acquire the per-collection mutex when retrying operations to avoid potential livelock issues.) ``` I’m unclear what is actually retried. You use this note throughout the document, so I think it would help to clarify exactly what is retried and why that solves the particular problem. I’m confused because, is it the refcount increment that’s retried or the entire sequence of steps (i.e. do you go back and reload the address of the item)? Is there some kind of waiting period before the retry? I would infer that if you’re retrying the refcount incrementing, it’s because you expect subsequent retries to transition from zero to non-zero, but is that guaranteed? Are there possibilities of deadlocks or race conditions? Can you go into some more detail (here or in the document) about how this works? Cheers, -Barry
The entire operation is retried (not just the refcount). For "dict", this means going back to step 1 and reloading the version tag and PyDictKeysObject. The operation can fail (and need to be retried) only when some other thread is concurrently modifying the dict. The reader needs to perform the checks (and retry) to avoid returning inconsistent data, such as an object that was never in the dict. With the checks and retry, returning inconsistent or garbage data is not possible. The retry is performed after locking the dict, so the operation is retried at most once -- the read operation can't fail when it holds the dict's lock because the lock prevents concurrent modifications. It would have also been possible to retry the operation in a loop without locking the dict, but I was concerned about reader starvation. (In the doc I wrote "livelock", but "reader starvation" is more accurate.) In particular, I was concerned that a thread repeatedly modifying a dict might prevent other threads reading the dict from making progress. I hadn't seen this in practice, but I'm aware that reader starvation can be an issue for similar designs like Linux's seqlock. Acquiring the dict's lock when retrying avoids the reader starvation issue. Deadlock isn't possible because the code does not acquire any other locks while holding the dict's lock. For example, the code releases the dict's lock before calling Py_DECREF or PyObject_RichCompareBool. The race condition question is a bit harder to answer precisely. Concurrent reads and modifications of a dict won't cause the program to segfault, return garbage data, or items that were never in the dict. Regards, Sam
On Thu, 7 Oct 2021 15:52:56 -0400 Sam Gross <colesbury@gmail.com> wrote:
Impressive work! Just for the record: """ It’s harder to measure aggregate multi-threaded performance because there aren’t any standard multi-threaded Python benchmarks, but the new interpreter addresses many of the use cases that failed to scale efficiently. """ It's crude, but you can take a look at `ccbench` in the Tools directory. Regards Antoine.
On Mon, Oct 11, 2021 at 7:04 AM Antoine Pitrou <antoine@python.org> wrote:
It's crude, but you can take a look at `ccbench` in the Tools directory.
Thanks, I wasn't familiar with this. The ccbench results look pretty good: about 18.1x speed-up on "pi calculation" and 19.8x speed-up on "regular expression" with 20 threads (turbo off). The latency and throughput results look good too. With the GIL enabled (3.11), the compute intensive background task increases latency and dramatically decreases throughput. With the GIL disabled, latency remains low and throughput high. Here are the full results for 20 threads without the GIL: https://gist.github.com/colesbury/8479ee0246558fa1ab0f49e4c01caeed (nogil, 20 threads) Here are the results for 4 threads (the default) for comparison with upstream: https://gist.github.com/colesbury/8479ee0246558fa1ab0f49e4c01caeed (nogil, 4 threads) https://gist.github.com/colesbury/c0b89f82e51779670265fb7c7cd37114 (3.11/b108db63e0, 4 threads)
I've updated the linked gists with the results from interpreters compiled with PGO, so the numbers have slightly changed.
I love everything about this - but I expect some hesitancy due to this "Multithreaded programs are prone to concurrency bugs.". If there is significant pushback, I have one suggestion: Would it be helpful to think of the python concurrency mode as a property of interpreters? `interp = interpreters.create(concurrency_mode=interpreters.GIL)` or `interp = interpreters.create(concurrency_mode=interpreters.NOGIL)` and subsequently python _environments_ can make different choices about what to use for the 0th interpreter, via some kind of configuration. Python modules can declare which concurrency modes they supports. Future concurrency modes that address specific use cases could be added. This would allow python environments who would rather not audit their code for concurrency isuses to opt out, and allow incremental adoption. I can't intuit whether this indirection would cause a performance problem in the C implementation or if there is some clever way to have different variants of relevant objects at compile time and switch between them based on the interpreter concurrency mode.
The way I see it, the concurrency model to be used is selected by developers. They can choose between multi-threading, multi-process, or asyncio, or even a hybrid. If developers select multithreading, then they carry the burden of ensuring mutual exclusion and avoiding race conditions, dead locks, live locks, etc. On Mon, 2021-10-18 at 13:17 +0000, Mohamed Koubaa wrote:
Mohamed> I love everything about this - but I expect some hesitancy due to this "Multithreaded programs are prone to concurrency bugs.". Paul> The way I see it, the concurrency model to be used is selected by developers. They can choose between ... I think the real intent of the statement Mohamed quoted is that just because your program works in a version of Python with the GIL doesn't mean it will work unchanged in a GIL-free world. As we all know, the GIL can hide a multitude of sins. I could be paraphrasing Tim Peters here without realizing it explicitly. It kinda sounds like something he might say. Skip
Hello all, I am very excited about a future multithreaded Python. I managed to postpone some rewrites in the company I work for Rust/Go, precisely because of the potential to have a Python solution in the medium term. I was wondering. Is Sam Gross' nogil merge being seriously considered by the core Python team?
On Sat, Apr 23, 2022 at 8:31 AM <brataodream@gmail.com> wrote:
Yes, although we have no timeline as to when we will make a decision about whether we will accept it or not. The last update we had on the work was Sam was upstreaming the performance improvements he made that were not nogil-specific. The nogil work was also being updated for the `main` branch. Once that's all done we will probably start a serious discussion as to whether we want to accept it.
On Mon, Apr 25, 2022 at 2:33 PM Brett Cannon <brett@python.org> wrote:
We haven't even discussed a *process* for how to decide. OTOH, in two days at the Language Summit at PyCon, Sam will give a presentation to the core devs present (which is far from all of us, alas).
It's possible that I've missed those code reviews, but I haven't seen a single PR from Sam, nor have there been any messages from him in this forum or in any other forums I'm monitoring. I'm hoping that the Language Summit will change this, but I suspect that there aren't that many perf improvements in Sam's work that are easily separated from the nogil work. (To be sure, Christian Heimes seems to have made progress with introducing mimalloc, which is one of Sam's dependencies, but AFAIK that work hasn't been finished yet.) -- --Guido van Rossum (python.org/~guido) *Pronouns: he/him **(why is my pronoun here?)* <http://feministing.com/2015/02/03/how-using-they-as-a-singular-pronoun-can-c...>
participants (24)
-
 Abdur-Rahmaan Janhangeer
Abdur-Rahmaan Janhangeer -
 Antoine Pitrou
Antoine Pitrou -
 Barry Warsaw
Barry Warsaw -
 brataodream@gmail.com
brataodream@gmail.com -
 Brett Cannon
Brett Cannon -
 Chris Angelico
Chris Angelico -
 Chris Jerdonek
Chris Jerdonek -
 Christopher Barker
Christopher Barker -
 Dan Stromberg
Dan Stromberg -
 Daniel Pope
Daniel Pope -
 Guido van Rossum
Guido van Rossum -
 Larry Hastings
Larry Hastings -
 Mohamed Koubaa
Mohamed Koubaa -
 Nathaniel Smith
Nathaniel Smith -
 Pablo Galindo Salgado
Pablo Galindo Salgado -
 Paul Bryan
Paul Bryan -
 Reza Roboubi
Reza Roboubi -
 Ronald Oussoren
Ronald Oussoren -
 Sam Gross
Sam Gross -
 Simon Cross
Simon Cross -
 Skip Montanaro
Skip Montanaro -
 Steven D'Aprano
Steven D'Aprano -
 Thomas Grainger
Thomas Grainger -
 Łukasz Langa
Łukasz Langa